声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
SEP-28k: A Dataset for Stuttering Event Detection From Podcasts With People Who Stutter
本文是apple在2021.02.24更新的文章,主要是发布了口吃语料集(sep-28k),为口吃事件的诊断提供数据,具体的文章链接
https://arxiv.org/pdf/2102.12394.pdf
(最近更新的晚了,主要我最近作息不好。我一直打算把阅读的文章由语音合成扩展到DSP,ASR,NLP等其它方面,但对于DSP,ASR,NLP这些方向的实验做的太少,缺乏实战经验,因此不好评断文章的好坏。计划慢慢做些实验再说)
1 研究背景
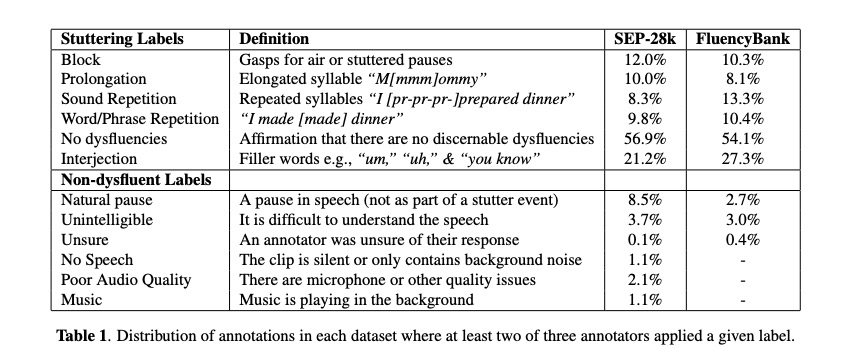
口吃语料可以用来医疗系统对口吃的诊断,也可以用来语音识别系统优化,但该语料十分稀少,能找到的一些语料FluencyBank也只有3.6k句数据。另外对于口吃语料的标注也是十分困难,其中图1展示了口吃语句的样例,针对口吃语料的标注,本文使用table 1列取的语句障碍类型,标注了28k的语句(10小时),以便相关人员使用。(目前网上找了一下,语料还没放出来)

2 详细设计和实验
本文使用的架构如图2所示,主要的本文使用ConvLstm代替LSTM,使用concordance correlation coefficient做损失函数。

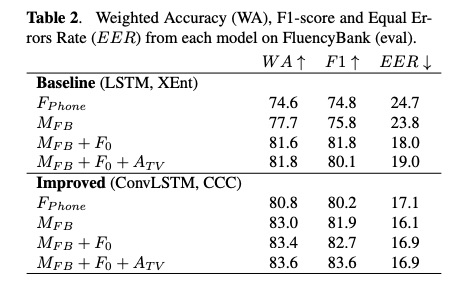
本文的实验先验证使用ConvLSTM, CCC结构的效果,table2显示可以提高准确度和f1-score,降低错误率。table3实现使用sep-28k和fluencyBank对比,sep-28k差一些,文章说sep-28k包含更多说话人和说话风格所致。图3展示使用sep-28k可以很好增加口吃事件的f1-score。

3 总结
本文主要提供口吃语料sep-28k,以便相关人员进行研究。