摘要
非自回归神经机器翻译(NAT)同时预测整个目标序列,并显著加速了推理过程。但是,NAT丢弃了句子中的依赖项信息,因此不可避免地会遭受多模式问题:目标字符可能由不同的可能翻译提供,通常会导致字符重复或丢失。为了缓解这个问题,我们在这项工作中提出了一种新的半自回归模型RecoverSAT,该模型将翻译生成为一系列片段。这些段是同时生成的,而每个段都是逐个令牌预测的。通过动态确定段长度并删除重复段,RecoverSAT能够从重复和丢失的令牌错误中恢复。在三个广泛使用的基准数据集上的实验结果表明,与相应的自回归模型相比,我们提出的模型可实现4倍以上的加速,同时保持可比的性能。
1.介绍

尽管近年来神经机器翻译(NMT)取得了显著的性能,但大多数NMT模型仍然由于它们的自回归特性,导致解码速度较慢,这是因为目标字符的生成取决于所有先前生成的目标字符,从而使解码过程本质上不可并行化。
最近,已经研究了非自回归神经机器翻译(NAT)模型以通过并行生成所有目标字符来缓解解码速度缓慢的问题,从而显着加快了解码过程。不幸的是,这些模型存在多模式问题,与自回归NMT相比,NAT模型翻译质量较差。具体而言,源语句可以具有多个可行翻译,并且可以针对不同的可行翻译生成相应目标字符,这是因为NAT模型丢弃了目标字符之间的依赖性。这通常在翻译中表现为字符的重复或丢失。表1显示了一个示例。德语短语“viele Farmer”可以翻译为“ lots of farmers \colorbox{yellow}{lots of farmers} lots of farmers”或“ a lot of farmers \colorbox{springgreen}{a lot of farmers} a lot of farmers”。在第一个翻译(翻译1)中,产生了两个“of”。同样,第二个翻译(翻译2)中缺少“ of”。直观上,多模式问题对NAT的翻译质量有很大的负面影响。
许多工作已经致力于减轻上述问题,可以将其大致分为两类。第一类工作利用迭代解码框架打破独立性假设,该假设首先生成初始翻译,然后通过将源句子和最后一次迭代的翻译都作为输入来迭代地优化翻译。然而,为了获得更好的翻译质量,它需要多次优化翻译,这严重损害了解码速度。第二类工作是通过利用解码器中的额外自回归层来改进NAT模型,以更好地捕获目标端依赖性,这通过引入潜在变量和更多强大的概率框架来建模更复杂的分布,或以自回归模型指导训练过程等。但是,这些模型一旦生成就无法更改目标字符,这意味着这些模型无法从多模态问题引起的错误中恢复。
为了缓解多模式问题,同时保持合理的解码速度,我们在这项工作中提出了一种新的半自回归模型RecoverSAT。RecoverSAT在三个方面具有以下特点:
(1)为了提高解码速度,我们假定翻译可以分为几个段,这些段可以同时生成。
(2)为了更好地捕获目标端依赖性,段内的字符不仅以该段中先前生成的字符为条件,还以其他段中的字符为条件来自回归生成。一方面,我们观察到重复字符更可能在短的上下文内出现。因此,自回归生成段对于减少重复字符是有益的。另一方面,通过以其他段中先前生成的字符为条件,该模型能够猜测每个段已经选择了哪些可行的翻译候选者,并相应地进行适配,例如从丢失的字符错误中恢复。结果,我们的模型捕获了更多的目标端依赖性,从而可以自然缓解多模式问题。
(3)为了使模型能够从重复的字符错误中恢复,我们在模型中引入了段删除机制。非正式地讲,一旦发现某段内容已被翻译成其他片段相同的内容,我们的模型就会将其标记为要删除的片段。
我们在三个基准数据集上进行了机器翻译实验,以评估该方法。实验结果表明,RecoverSAT的解码速度比自回归算法快4倍以上,同时保持了相当的性能。这项工作的源代码已在https://github.com/ranqiu92/RecoverSAT上发布。
2.背景
2.1 自回归神经机器翻译
自回归神经机器翻译(AT)会根据翻译历史逐个字符地生成翻译。AT将源句子表示为 x = { x i } i = 1 T ′ \textbf x=\{x_i\}^{T'}_{i=1} x={
xi}i=1T′,将目标句子表示为 y = { y j } j = 1 T \textbf y=\{y_j\}^{T}_{j=1} y={
yj}j=1T,AT将联合概率建模为:
P ( y ∣ x ) = ∏ t = 1 T P ( y t ∣ y < t , x ) . (1) P(\textbf y|\textbf x)=\prod^T_{t=1}P(y_t|\textbf y_{\lt t},\textbf x).\tag{1} P(y∣x)=t=1∏TP(yt∣y<t,x).(1)
其中 y < t \textbf y_{<t} y<t表示在 y t y_t yt之前生成的字符。
在解码期间,翻译历史依赖性使AT模型在生成所有先前的字符后预测后续每个字符,这使解码过程很耗时。
2.2 非自回归神经机器翻译
非自回归神经机器翻译(NAT)旨在加速解码过程,该过程摒弃了翻译历史的依赖性,并将 P ( y ∣ x ) P(\textbf y|\textbf x) P(y∣x)建模为每个字符的条件独立概率的乘积 :
P ( y ∣ x ) = ∏ t = 1 T P ( y t ∣ x ) . (2) P(\textbf y|\textbf x)=\prod^{T}_{t=1}P(y_t|\textbf x).\tag{2} P(y∣x)=t=1∏TP(yt∣x).(2)
条件独立性使NAT模型能够并行生成所有目标字符。
但是,独立预测所有目标字符具有挑战性,因为自然语言通常会在上下文之间表现出很强的相关性。由于该模型几乎不了解有关周围目标令字符的信息,因此在预测不同的目标字符时可能会考虑不同的可能翻译。该问题被称为多模式问题,并严重降低了NAT模型的性能。
3.方法
3.1 概述
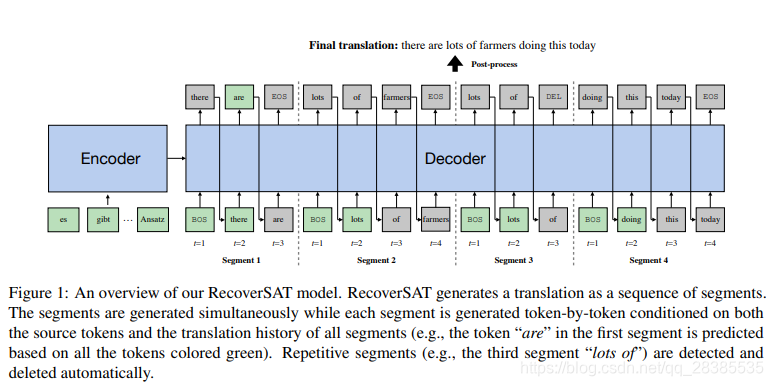
RecoverSAT扩展了原始的Transformer,以使解码器可以局部自回归生成,而在全局非自回归生成。我们的RecoverSAT模型的架构概述如图1所示。如图所示,RecoverSAT可以同时预测所有片段,包括“there are EOS”,“lots of farmers EOS”,“a lot DEL”和“doing this today EOS”。并且在每个时刻,它为每个不完整的段生成一个字符。特殊字符DEL表示应删除该段,而EOS表示该段的结尾。结合所有片段,我们得到最终翻译“there are lots of farmers doing this today”。
形式上,假设翻译 y \textbf y y的生成被分为 K K K个片段 S 1 , S 2 , . . . , S K \textbf S^1,\textbf S^2,...,\textbf S^K S1,S2,...,SK,其中 S i \textbf S^i Si是翻译的子序列。为了简化描述,我们假设所有片段的长度相同。RecoverSAT以每个生成步骤中所有先前生成的字符为条件,为每个片段预测一个字符,其公式可表示为:
P ( y ∣ x ) = ∏ t = 1 L ∏ i = 1 K P ( S t i ∣ S < t 1 ⋯ S < t K ; x ) , (3) P(\textbf y|\textbf x)=\prod^L_{t=1}\prod^{K}_{i=1}P(\textbf S^i_t|\textbf S^1_{\lt t}\cdots \textbf S^K_{\lt t};\textbf x),\tag{3} P(y∣x)=t=1∏Li=1∏KP(Sti∣S<t1⋯S<tK;x),(3)
其中 S t i \textbf S^i_t Sti表示第 i i i个片段中的第 t t t个字符, S < t i = { S 1 i , . . . , S t − 1 i } \textbf S^i_{<t}= \{\textbf S^i_1,...,\textbf S^i_{t-1}\} S<ti={
S1i,...,St−1i}表示第 i i i个片段中的翻译历史, L L L为片段长度。
在这里,解码过程自然而然地产生了两个问题:
- 如何确定段的长度?
- 如何确定应删除的片段?
我们在这项工作中以统一的方式解决了这两个问题。假设原始字符词汇大小是 V V V,我们用两个额外的字符 E O S EOS EOS和 D E L DEL DEL对其进行扩展。然后,对于片段 S i \textbf S^i Si,在时刻 t t t处最可能的字符 S ^ t i \hat \textbf S^i_t S^ti为:
S ^ t i = a r g m a x S i i ∈ V ∪ { E O S , D E L } P ( S t i ∣ S < t 1 ⋯ S < t K ; x ) (4) \hat \textbf S^i_t=\mathop{argmax}\limits_{\textbf S^i_i\in V\cup \{EOS,DEL\}}P(\textbf S^i_t|\textbf S^1_{\lt t}\cdots \textbf S^K_{\lt t};\textbf x)\tag{4} S^ti=Sii∈V∪{
EOS,DEL}argmaxP(Sti∣S<t1⋯S<tK;x)(4)
这里有三种可能的输出:
(1) S ^ t i ∈ V \hat \textbf S^i_t\in V S^ti∈V:片段 S i \textbf S^i Si不完整,其解码过程应继续;
(2) S ^ t i = E O S \hat \textbf S^i_t=EOS S^ti=EOS:片段 S i \textbf S^i Si已完成,其解码过程应终止;
(3) S ^ t i = D E L \hat \textbf S^i_t=DEL S^ti=DEL:片段 S i \textbf S^i Si是重复的,应删除。因此,其解码过程应终止。
当所有片段均满足EOS/DEL或达到最大字符数时,整个解码过程将终止。应该注意的是,遇到DEL时,我们没有明确删除段,而是通过后期处理来删除它。换句话说,训练模型以忽略要隐式删除的段。
3.2 学习从错误中恢复
由于在解码过程的早期阶段几乎没有可用的目标端信息,因此由多模式问题引起的错误是不可避免的。在这项工作中,我们不是直接减少此类错误,而是提出了两种训练机制来指导我们的RecoverSAT模型从错误中恢复:
(1)动态终止机制:学习根据目标端上下文确定段长度;
(2)段删除机制:学习删除重复段。
3.2.1 动态终止机制
如第3.1节所示,我们无需预先指定段的长度,而是让模型通过预测EOS字符来确定长度。这种策略可通过两种方式帮助我们的模型从与多模式相关的错误中恢复:
1.前几个字符的选择更加灵活。以图1为例,如果解码器确定第二段的第一个字符是“of”而不是“lots”(即在第二段中没有生成“lots”)。则只需在第一段中的“EOS”之前生成“lots”即可,以从丢失的字符错误中恢复。相反,如果解码器确定第一个字符为“ are”,则可以通过在第一段中不生成“are”来避免重复的字符错误。
2.如方程式所示,以所有段中所有先前生成的字符为条件来生成当前时刻字符。因此,解码器具有更丰富的目标端信息以检测并从此类错误中恢复。
但是,训练模型以学习此类行为并同时保持合理的加速并非易事。一方面,由于我们的RecoverSAT模型的解码时间与片段的最大长度成比例,因此我们应该将训练实例的目标句子划分为等长片段,以鼓励模型生成相同长度的片段。另一方面,该模型应该暴露与多模式相关的错误,以增强其从此类错误中恢复的能力,这表明训练实例的目标语句应随机划分以模拟这些错误。
为了缓解该问题,我们提出了一种混合退火划分策略。具体而言,我们在每个训练步骤中随机决定是对目标句子进行平均划分还是随机划分,并在训练结束时逐步采用均等划分方法。形式上,给定目标句子 y \textbf y y和片段数目 K K K,我们如下定义片段划分集合 r \textbf r r:
s ∼ B e r n o u l l i ( p ) , (5) s\sim Bernoulli(p),\tag{5} s∼Bernoulli(p),(5)
r = { E Q U A L ( T , K − 1 ) s = 0 R A N D ( T , K − 1 ) s = 1 , (6) \textbf r=\begin{cases} EQUAL(T,K-1) & s=0\\ RAND(T,K-1) & s=1 \end{cases},\tag{6} r={
EQUAL(T,K−1)RAND(T,K−1)s=0s=1,(6)
其中 B e r n o u l l i ( p ) Bernoulli(p) Bernoulli(p)是参数为 p p p的Bernoulli分布, E Q U A L ( n , m ) = { ⌈ n m + 1 ⌉ , ⌈ 2 n m + 1 ⌉ , ⋯ , ⌈ m n m + 1 ⌉ } EQUAL(n,m)=\{\lceil \frac{n}{m+1}\rceil,\lceil \frac{2n}{m+1}\rceil,\cdots,\lceil \frac{mn}{m+1}\rceil\} EQUAL(n,m)={
⌈m+1n⌉,⌈m+12n⌉,⋯,⌈m+1mn⌉}, R A N D ( n , m ) RAND(n,m) RAND(n,m)采样 m m m个 [ 1 , n ] [1,n] [1,n]内的非重复索引。 p p p的值越大,错误恢复的能力越强,而 p p p的值越小,则促使模型生成具有相同长度的段(换句话说,提高解码速度)。为了平衡这两个方面,我们在训练过程中将p从1逐渐退火到0,从而获得更好的性能(第4.5节)。
3.2.2 段删除机制
尽管动态终止机制使模型能够从丢失的字符错误中恢复并减少重复的字符,但是该模型仍然无法从已经生成的字符重复错误中恢复。我们发现模型的主要错误是在生成每个片段的第一个字符时发生的,因为它看不到任何历史和未来。在这种情况下,将生成两个重复的段。为了缓解此问题,我们提出了一种段删除策略,该策略使用特殊的字符 D E L DEL DEL来指示段是重复的并且应删除。
训练模型以学习删除段的一种直接方法是将伪重复段注入训练数据中。 以下是一个示例:

给定目标语句“there are lots of farmers doing this today”,我们首先将其分为“there are”,“lots of farmers”和“doing this today”三个部分。然后,我们复制第二段的前两个字符,并将特殊字符DEL附加到末尾,以构造伪重复段“lots of DEL”。最后,我们将重复的片段插入所选片段的右侧,从而得到4个片段。形式上,给定期望的片段数 K K K和目标句子 y y y,我们首先将 y y y分为 K − 1 K-1 K−1个片段 S 1 , S 2 , . . . , S K − 1 \textbf S^1,\textbf S^2,...,\textbf S^{K-1} S1,S2,...,SK−1,然后通过复制随机选择段 S i \textbf S^i Si的前 m m m个字符并将 D E L DEL DEL附加到末尾,来构建伪重复片段 S r e p i \textbf S^i_{rep} Srepi,其中 m m m从 [ 1 , ∣ S i ∣ ] [1,|\textbf S^i|] [1,∣Si∣]均匀采样。最后,将 S r e p i \textbf S^i_{rep} Srepi插入到 S i \textbf S^i Si的右侧。最后形成的 K K K个段是 S 1 , S 2 , ⋅ ⋅ ⋅ , S i , S r e p i , S i + 1 , ⋅ ⋅ ⋅ , S K − 1 \textbf S^1,\textbf S^2,···,\textbf S^i,\textbf S^i_{rep},\textbf S^{i+1},···,\textbf S^{K-1} S1,S2,⋅⋅⋅,Si,Srepi,Si+1,⋅⋅⋅,SK−1。
但是,将此类伪重复段注入所有训练实例将误导该模型,即生成然后删除重复段是必须具有的行为,这是不希望的。因此,在这项工作中,我们将伪重复段以概率 q q q注入到训练实例中。