作者及单位:

发表会议:
KDD2019(
数据挖掘顶会
)
数据集:
PPI
、
Reddit
、
Amazon2M(
本文创建,比之前最大的
Reddit
数据集大
5
倍以上
)
GCN
存在的问题:
•
基于
Full-batch gradient descent
•
在每一个
epoch
中对所有节点进行计算,每个
epoch
只更新一次参数,参数更新慢,收敛速度慢,在计算梯度下降时需要保存所有节点的
embeddings
,内存需求大
•
基于
Mini-batch SGD
•
每次参数更新基于一个随机采样得到的
batch
,每个
epoch
可以进行多次参数更新。节点的数目减少,内存需求减少,但需要更新节点
embedding
,随着
GCN
层数增加,需要考虑的节点数目指数级增加,
neighborhood expansion problem,计算复杂度高
(Full-batch空间复杂度高,时间复杂度低(因为每个节点梯度计算时只计算一次),每个epoch的训练时间是有效的GCN计算损失时,一部分损失是通过有标签的节点计算的,但是大部分的损失是通过拉普拉斯矩阵的性质计算的,某个节点的损失同时依赖其他节点的损失)
•
Mini-batch SGD
VS Full-batch gradient descent
:内存需求减少,但网络层数加深后因
neighborhood expansion
训练速度慢

(
Neighborhood expansion
当前节点与其他节点存在链接的关系,
当考虑某个节点相关的梯度计算时,需要得到节点的
embedding
,当前节点的
embedding
取决于其邻居节点的
embeddings
,并且我们还需要邻居节点的邻居节点的
embeddings
,假设
GCN
有
L+1
层,为了得到节点的梯度,需要从许多节点中为一个节点聚合特征。
训练速度是由每个
epoch
的训练速度和
epoch
的收敛速度决定
)
本文改进方法
•
定义
embedding utilization:
计算第
l+1
层时第
l
层的
embeddings
被利用了
u
次,那么就说相应的
embedding utilization
是
u
•
基于
Mini-batch
,先形成
clusters(
常用的图聚类算法,如
metis)
,对节点所在的
cluster
进行采样,更新
cluster
内节点的
embeddings

Vanilla Cluster-GCN:
•
对于一个图,将节点、链接、邻接矩阵进行重组,分为


Stochastic Multiple Partitions:
•Vanilla Cluster-GCN存在的问题:
•[1]:graph被分成clusters后,一些节点之间的链接被消除,性能受到影响
•[2]:graph被分为clusters时将相似的节点聚集在一起,因此数据的分布情况不同于原始数据集,在执行SGD更新时对full gradient的有偏估计

Graph经过图聚类算法后其大多数标签分布的熵值明显比随机划分小,cluster的标签分布偏向于某些特定的标签,增加了不同batch之间的差异性
•随机多重聚类 Stochastic Multiple Partitions:
合并cluster间链接,首先将graph分为p个cluster,使用SGD更新时不仅考虑一个cluster,而是随机选择多个cluster,并将节点和链接加入到batch,cluster间的链接被重新合并,batch之间的差异减小
•原每层的输出表达:![]()
•(9)对所有节点使用相同的权重而不管其邻居节点的数目,当网络更深,数组不稳定
![]()
![]()
•
对比
(9)
和
(11)
:
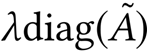 表示对角线增强
表示对角线增强
实验对比
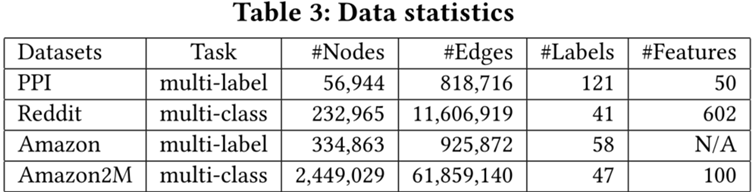
•数据集:Reddit数据集是GCN最大的公共数据集,Amazon2M是文章收集的(比Reddit大5倍以上)
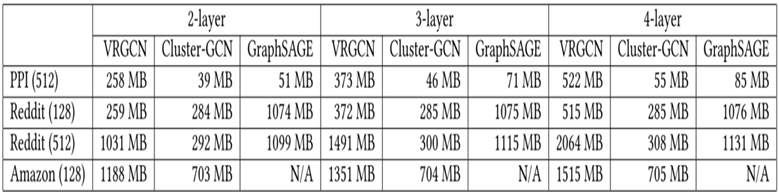
•
不同数据集上内存使用情况的比较
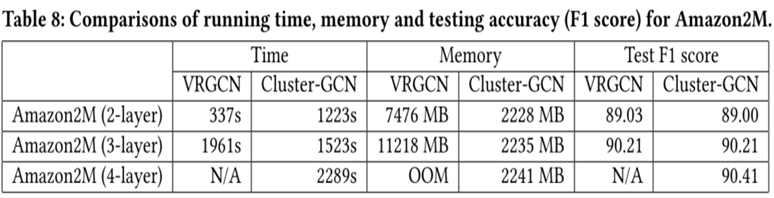
•
在
Amazon2M
上使用
VRGCN
和
Cluster-GCN
对比
•
在
PPI
数据集上使用
VRGCN
和
Cluster-GCN
运行时间对比
(200epochs)

使用不同数据集不同GCN方法的比较,x轴为训练时间,y轴为F1 score
