关于AlexNet模型论文,网上很多地方都可以下载到;我在学习的过程中,也看到SnailTyan把论文的翻译放在了个人博客中,也供大家学习参考:http://noahsnail.com/2017/07/04/2017-07-04-AlexNet论文翻译/
一)简介
Alex在2012年提出的AlexNet网络结构模型赢得了2012年ImageNet竞赛的冠军,使得CNN成为在图像分类上的核心算法,并引爆了神经网络的应用热潮。在此之后,更多的更深的神经网路被提出,比如优秀的VGG,GoogleLeNet等。同时,作者也强调了一点,在AlexNet模型中移除任何一个卷积层都会使得性能会降低,可见深度对模型精度非常重要。
二)AlexNet模型介绍
AlexNet网络结构
AlexNet模型共有8层(不包含输入层),5个卷积层和3个全连接层,每一个卷积层中包含了激励函数ReLU、局部响应归一化(LRN)处理,以及池化(下采样)。模型结构如下图所示。
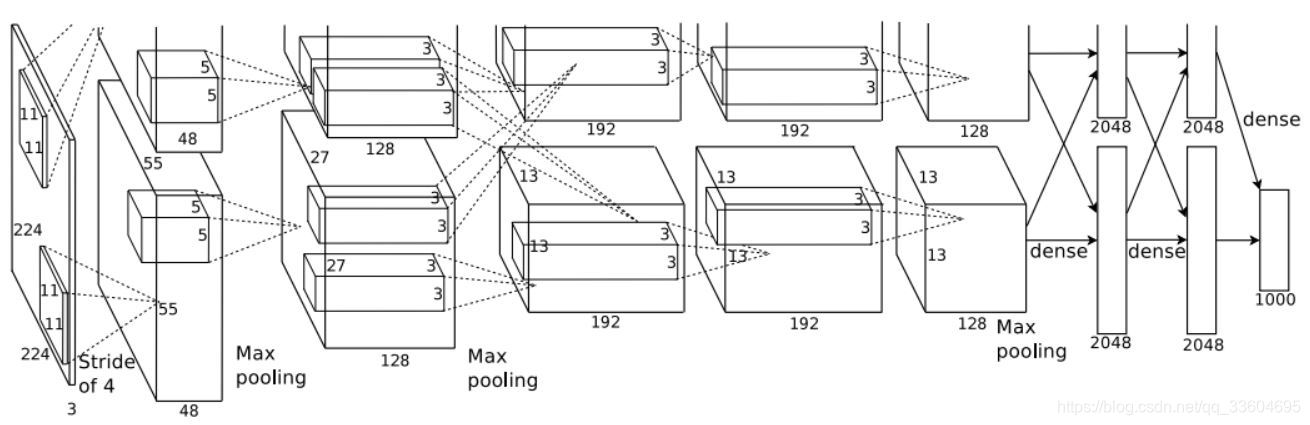
论文中的结构之所以分为上下两部分,是因为当时显卡容量有限,无法在一张显卡上操作网络中60M的网络参数,作者不得不在两张显卡上分别运算,并在特定的网络层进行交互。为了更方便的理解,我们可以假设全部在一块GPU计算,从稍微简化点的方向来分析这个网络结构。
2.1)输入图像
AlexNet的输入图像是227x227x3大小(论文中的224x224需要padding)。
2.2)卷积层C1
?卷积
卷积核的大小为11x11,stride为4,共48x2个卷积核
经过卷积处理后,输出的featuremap边长为(216-11)/4+1=55,特征图则为55x55x96
?激活
?池化
池化核大小为3x3,stride为2(论文表明重叠池化的训练效果更优)
池化处理后的featuremap边长为(55-3)/2+1=27,特征图则为27x27x96
?归一化
2.3)卷积层C2
?卷积
C1输出的featuremap需要在边缘扩充2个像素,变为31x31x96
卷积核的大小为5x5,stride为1,共128x2个卷积核
经过卷积处理后,输出的featuremap边长为(31-5)+1=27,特征图则为27x27x256
?激活
?池化
池化核大小为3x3,stride为2。
池化处理后的featuremap边长为(27-3)/2+1=13,特征图则为13x13x256
?归一化
2.4)卷积层C3
?卷积
C2输出的featuremap需要在边缘扩充1个像素,变为15x15x256
卷积核的大小为3x3,stride为1,共192x2个卷积核
经过卷积处理后,输出的featuremap边长为(15-3)+1=13,特征图则为13x13x384
?激活
2.5)卷积层C4
?卷积
C3输出的featuremap需要在边缘扩充1个像素,变为15x15x384
卷积核的大小为3x3,stride为1,共192x2个卷积核
经过卷积处理后,输出的featuremap边长为(15-3)+1=13,特征图则为13x13x384
?激活
2.6)卷积层C5
?卷积
C4输出的featuremap需要在边缘扩充1个像素,变为15x15x384
卷积核的大小为3x3,stride为1,共128x2个卷积核
经过卷积处理后,输出的featuremap边长为(15-3)+1=13,特征图则为13x13x256
?激活
?池化
池化核大小为3x3,stride为2
池化处理后的featuremap边长为(13-3)/2+1=6,特征图则为6x6x256
2.7)全连接层F6
?全连接
C5的输出为6x6x256尺寸的featuremap,利用4096个尺寸为6x6x256的卷积核对C5输出做卷积,得到4096个神经元的输出
?激活
?dropout
2.8)全连接层F7
?全连接
C7同样含有4096个神经元,与C6的神经元进行全连接
?激活
?dropout
2.9)全连接层F8
?全连接
C8含有1000个神经元(即分类数目),与C6的神经元进行全连接
三)ReLU、LRN、Dropout的说明
AlexNet模型中引入ReLU激活函数、LRN处理、Dropout处理,都对模型的训练效率和结果有着重要影响。
3.1)激活函数ReLU
什么是激活函数?
ReLU的特点
基于ReLU的深度卷积网络比基于tanh和sigmoid的网络训练快数倍。
3.2)局部相应归一化(Local Response Normalization)
AlexNet模型中首次提出了LRN。LRN对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
关于LRN的理解,大家可以阅读https://blog.csdn.net/program_developer/article/details/79430119
3.3)Dropout处理
Dropout是防止神经网络过拟合的有效手段。
以0.5的概率对每个隐层神经元的输出置0,这些神经元则不再进行前向传播,并且不参与反向传播。因此每次输入时,神经网络会采样一个不同的架构,但所有架构共享权重。这样减少了复杂的神经元互适应,因为一个神经元不能依赖特定的其它神经元的存在。因此,神经元被强迫学习更鲁棒的特征,它在与许多不同的其它神经元的随机子集结合时是有用的。
关于Dropout的理解,推荐大家阅读https://blog.csdn.net/stdcoutzyx/article/details/49022443
3.4)数据增强
数据增强是利用平移、旋转、翻转、缩放、颜色变换等方式,人工增大训练集样本的个数,从而获得更充足的训练数据,使模型训练的效果更好,减轻过拟合程度。
作者在文论中也描述了自己的图像增强方法:
1)从256×256图像上提取出5个224x224子图像(四个角及中心),并分别进行水平翻转,得到共10个子图像;
2)改变训练图像的RGB通道的强度,可以减小自然下光照颜色、强度对识别的影响。
参考:
1.https://blog.csdn.net/guoyunfei20/article/details/78122504
2.https://blog.csdn.net/Rasin_Wu/article/details/80017920