第7章 Boosting
集成方法是机器学习中的一种通用技术,可以去结合多个预测器来创建一个更准确的预测器。本章研究了一个被称为增强的重要集成方法家族,这个方法具体来说就是AdaBoost算法。该算法在某些场景中已经被实践证明是非常有效的,并且是基于丰富的理论分析。我们首先来介绍AdaBoost,展示下它如何通过快速减少轮数增强的经验误差,并指出它与一些著名算法的关系。接下来,我们来呈现出一种基于AdaBoost假设集的vc维数,并对AdaBoost的推广性质进行了理论分析,然后基于边际的概念,对其泛化性质进行了理论分析。在这种情况下发展的边际理论可以应用于其他类似的集成算法。而AdaBoost的博弈论可以进一步有助于分析其性质,揭示了弱学习假设与可分条件的等价性。
7.1 Introduction
这通常是困难的,对于一个不平凡的学习任务,去直接设计出一种满足第
2章强PAC学习要求的精确算法。但是,还是有很大的希望去找到仅能保证表现比随机稍好一些的简单预测器。下面给出了这种弱学习者的正式定义。正如在PAC学习的章节中一样,我们设
n为一个数字,表示任何元素
x∈
X的计算代价最多为
O(
n),并用大小(
c)表示
c
∈C计算表示的最大代价。
定义7.1(Weak learning)
如果存在一个概念类
∈C据说是弱PAC可学习的一个算法
A,
γ>0,和一个多项式函数多聚(·,·,·),这样对于任何
δ>
0,对于
X上的所有分布
∈D和任何目标概念
c∈
C,
AdaBoost(
∈S= ((
x1,y1),...,(xm,
ym)
for i
←to m do
D1(i)
←
m1
for t
← 1 to T do
ht
← 基础分类器
H 误差小
ϵt =
pi~
Dt[
ht(
xi)
=
yi]
at
←
21 log
ϵt1−ϵt
Zt
← [
ϵt(1-
ϵt)]
21
⊳ 归一化[标准化]因数
for i
←
1 to m do
Dt(
i)
←
ZtDt(i)exp(−atyiht(xt))
f
←
∑
t=1T
at
ht
return f
图7.1基本分类器集
H⊆{−1,+1}
x的AdaBoost算法。以下算法适用于任何样本大小的
m≥
poly(
1/
δ,
n,
size(
c)):
其中
hS是算法
A在样本
S上训练时返回的假设。当这样的算法
A存在时,它被称为C的弱学习算法或弱学习者的算法。弱学习算法返回的假设称为基础分类器。 增强技术背后的关键思想是使用一个弱学习算法来建立一个强的学习者,也就是说,一个精确的PAC学习算法。要做到这一点,提升技术采用了一种集成方法:它们结合了弱学习者返回的不同基础分类器,以创建一个更准确的预测器。但是应该使用哪些基础分类器以及如何组合呢?下一节来通过详细描述一种最普遍和最成功的增强算法,AdaBoost来解决这些问题。
我们用
H 表示从中选择基本分类器的假设集,我们有时会称之为基分类器集。图7.1给出 图7.2
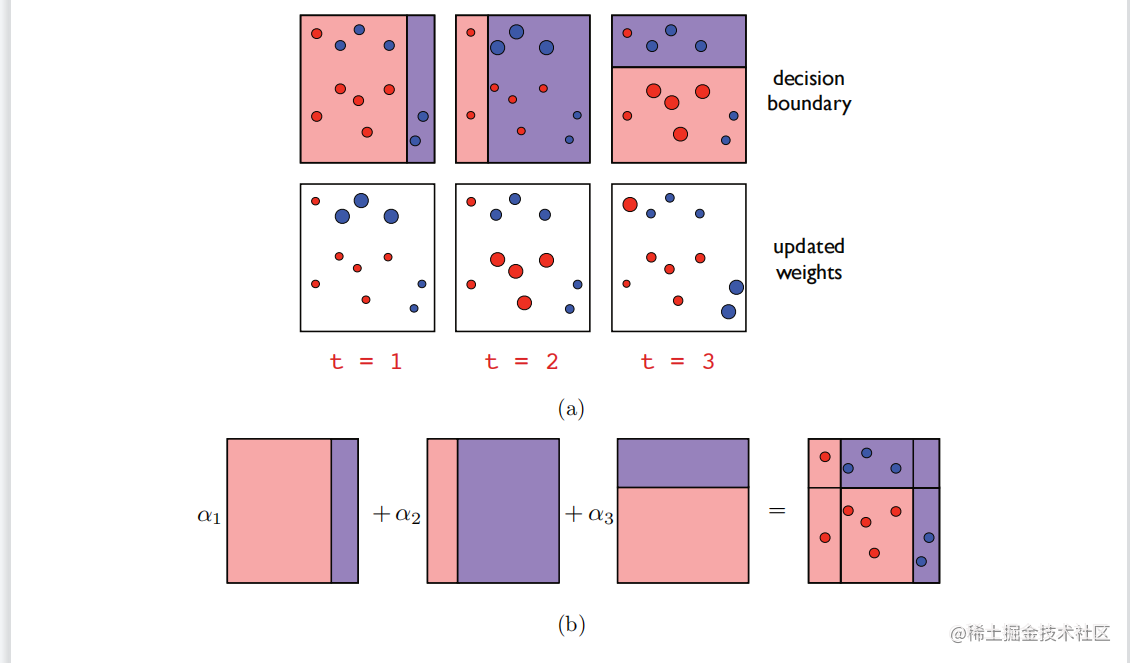 以轴对齐的超平面作为基础分类器的AdaBoost示例。(
a)最上面的一行显示了每一轮推进时的决策边界。下面一行显示了每一轮如何更新权重,给出错误(正确)权重增加(减少)。(
b)最终分类器的可视化,构造为基分类器的非负线性组合。 在基分类器是从
X映射到{
−1,
+1}的函数时,AdaBoost的伪代码,因此
H⊆{
−1,
+1}
X。 该算法以一个标记的样本S=((
x1,
y1),…,(
xm,
ym))作为输入,其中,(
xi,
yi)∈X×{−1,+1}为所有的i∈{m},并在索引{
1,…,
m}上保持一个分布。最初(第
1至
2行),分布是均匀的(
D1)。在每一轮增强
h时,即循环
3-
8的每次迭代
t∈{
i},选择一个新的基分类器
t∈
H,使由分布
Dt加权的训练样本的误差最小化:
以轴对齐的超平面作为基础分类器的AdaBoost示例。(
a)最上面的一行显示了每一轮推进时的决策边界。下面一行显示了每一轮如何更新权重,给出错误(正确)权重增加(减少)。(
b)最终分类器的可视化,构造为基分类器的非负线性组合。 在基分类器是从
X映射到{
−1,
+1}的函数时,AdaBoost的伪代码,因此
H⊆{
−1,
+1}
X。 该算法以一个标记的样本S=((
x1,
y1),…,(
xm,
ym))作为输入,其中,(
xi,
yi)∈X×{−1,+1}为所有的i∈{m},并在索引{
1,…,
m}上保持一个分布。最初(第
1至
2行),分布是均匀的(
D1)。在每一轮增强
h时,即循环
3-
8的每次迭代
t∈{
i},选择一个新的基分类器
t∈
H,使由分布
Dt加权的训练样本的误差最小化:
ht∈h∈Hargmini∼DiP[h(xi)=yi]=h∈Hargmini=1∑mDt(i)h(xi)=yi
zt只是一个归一化因子,以确保权重
Dt(
i)之和为
1。 定义系数
αt的确切原因将在稍后变得清楚。
目前,观察到,如果
ϵt基分类器的t的误差小于
21,这时
ϵt1−ϵt
> 1 and
at是积极的(
at
>
0).因此,新的分布
Dt+1是从
Dt通过大大增加它的重量
i如果点
xi是错误的分类(
yi
ht(
xi)<
0),相反,如果
xi是正确分类的。这样做的效果是更多地关注下一轮助推中错误分类的点,而不是那些正确分类的点
ht
经过
T轮增强后,AdaBoost返回的分类器是基于函数的符号进行的
f,这是一个基分类器的非负线性组合
ht。重量
at 被分配给
ht在这个和中是精度之比的对数函数
1-
ϵt和错误
ϵt
of
ht.因此,更准确的基分类器在这个总和中被分配了一个更大的权重。图7.2说明了AdaBoost算法。这些点的大小表示在每一轮推进时分配给它们的分布权重。任何
t
∈[
T],我们将用ft表示基分类器的线性组合
t轮升力:
ft=
∑
s=1t
as
hs。特别是,我们有
fT=
f分布
Dt+1可以用
ft归一化因素
Zs,
s∈[
t],如下:
∀
i∈[
m],
Dt+1(
i)=
m∏s=1tZse−yift(xi) (7.2)
我们将在以下章节的证明中多次使用这个恒等式。它可以通过重复扩展点上分布的定义来直接显示出来
xi:
Dt+1(
i)=
Zte−atyift(xi)=
Zt−1ZtDt−1(i)e−at−1yiht−1(xi)e−atyift(xi)
=
m∏s=1tZseyi∑s=1tashs(xi)
AdaBoost算法可以通过以下几种方式进行推广:
ht可以不是加权误差最小的假设,而是由训练过的弱学习算法返回的基本分类器
Dt;
基分类器的范围可以是[
−1,
+1],或者更一般地是一个有界的子集
R
系数
αt可以不同,甚至可能不允许封闭形式。一般来说,选择它们是为了最小化经验误差的上界,如下一节所述。当然,在这种一般情况下,假设
ht不是二进制分类器,但它们的符号可以定义标签,它们的大小可以被解释为置信度的度量。
在本章的其余部分中,
H中的基分类器的范围将被假设包含在[
−1,
+1]中。我们进一步分析AdaBoost的特性,并讨论其在实践中的典型应用。
7.2.1结合经验误差
我们首先证明了AdaBoost的经验误差随着助推轮数的函数呈指数快速减小.
定理7.2
AdaBoost返回的分类器的经验误差验证了:
Rs(f)
≤ exp
[
−2t=1∑T(21−ϵt)2]
(7.3) 此外,如果为所有人
t∈[T],
γ≤(
21-
ϵt),这时
Rs(
f)
≤exp(-2
γ2T).
证明:使用一般的不等式
1u≤0
≤exp(−u)对所有人都有效
u∈R和身份7.2,我们可以写道:
Rs(f)=
m1
i=1∑m