前言

论文地址:https://aclanthology.org/2020.acl-main.148.pdf
代码地址:https://github.com/bzhangGo/zero
前人工作&存在问题
模型容量问题,前人工作:
- 要么共享模型的部分,剩下部分是语言特异的,限制了可拓展性;
- 要么借助一些表示翻译方向的信息,完成全共享,它们把不同语言编码到同一空间,忽略了语言的多样性;
- 保留语言多样性的一些工作:
- 重组参数共享( reorganizing parameter sharing)
- 设计语言特异的参数生成器
- 去耦(decouple)多语言单词编码
- 语言聚类
- 保留语言多样性的一些工作:
另外,multilingual NMT用于zero-shot translation时,会出现“off-target”的问题,对于此,先前的工作:
- 使用跨语言正则化(如对齐正则化、一致性正则化)
- 生成伪平行数据,或者pivot based translation
本文贡献
- 以一种更加便捷的、端到端的language specific方法,以及深化NMT网络来缓解模型容量问题;
- 采用随机在线backtranslation(ROBT)来缓解zero-shot translation中的off-target问题。
具体方法
-
Deep transformer:
使用作者之前提出的depth-scaled initialization method来训练一个deep transformer。 -
为每一种target语言定义一个layer normalization的参数(以source端输入的target language token为标识符):


- 为每一种target语言的encoder输出定义一个线性变换的参数(以source端输入的target language token为标识符):

- 在线随机backtranlation(ROBT):
训练得到NMT model之后,再进行ROBT的finetune。具体的,如图3.1所示,对于每一个step的每一个batch,遍历这个batch中的所有 x m x_m xm- y n y_n yn,对于每一个 x m x_m xm- y n y_n yn,随机选择一个target语种k(k≠n),并把 y n y_n ynback translation成 x k x_k xk,把 x k x_k xk- y n y_n yn加入到这个batch中。然后在这个batch上优化NMT model。注意:ROBT拥有一个参数T,表明需要考虑的target语种集合。

具体实验
使用OPUS-100,其加上english,总共包含了100种语言。由于是english-centric的,一共包含了99种language pair,一共有大约55M的训练样本,对于每一种language pair,都有2000条验证、测试数据。
另外,在zero-shot translation设置中,总共包含Arabic、Chinese、Dutch、French、German、Russian6个语种,15个语言对。
one2many实验结果
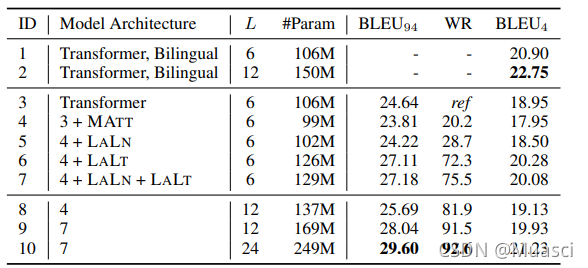
本文模型在99个english->X语言对上训练,结果如图4所示,可得以下结论:
- LALN\LALT有效
- deeper有效
many2many实验结果
本文模型在99*2个english<->X语言对上训练,分别统计了English->X的结果(图5)、X->English的结果(图6)。
如图5、6所示:
- 图5(①vs②)和图4(①vs②)相比,同样是one2many,经过many2many的训练,模型的容量问题更加明显。
- 相反的,经过many2many的训练,图6(①vs②)的many2one结果却比bilingual baseline来的好。说明multilingual的设置下,模型能获得很好的迁移能力。
- 另外,直接把图5和图6的①+⑦相比,发现经过many2many的训练,many2one的结果确实更好。可能的原因有两点:1. many2many的训练中,50%的target都是english,这让模型拥有很强的2english能力;2. many2many的训练使得模型有很强的迁移能力(该迁移能力重点体现在encoder端)。
- 然而,虽然many2one的整体性能更好,但many2one经过language-specific的加持,性能提升更小,因为本文的language-specific是针对target而言。
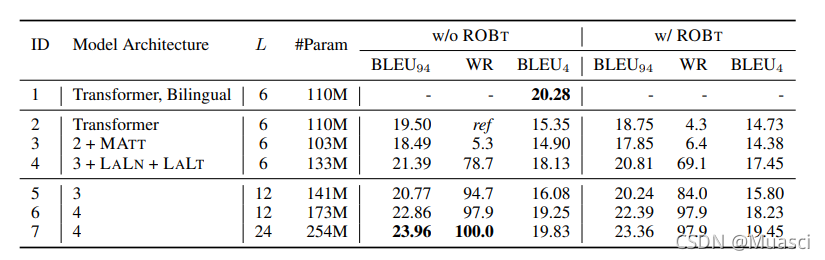

以上实验结果在不同规模的语言对上有什么不同
如图7所示,结论和上面差不多:
- one2many经过language-specific的收益最大,特别是在low-resource语言对上,many2one几乎没有收益;
- deep在不同规格语言对、不同方向上都有很大的增益。

zero-shot translation(不是模型容量的问题)
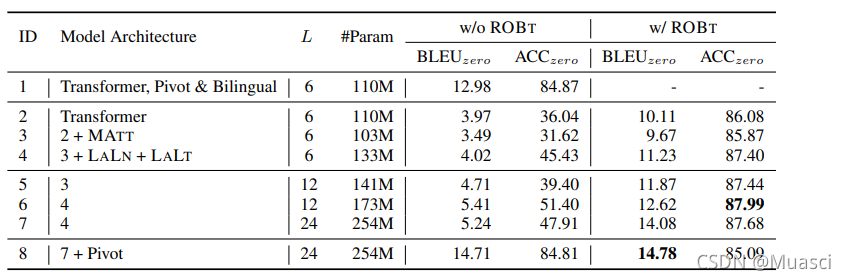
如图8所示:
- 单看w/o ROBT一栏,发现增大模型容量(不管是加入了language-specific,还是让模型更加deep),都不能彻底改善zero-shot translation效果差的问题;
- zero-shot translation效果差,主要是因为有off-target的存在;
- ROBT能有效改善off-target问题,带来更好的zero-shot translation结果;
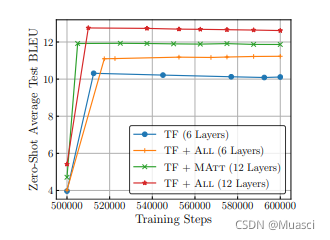
另外,图9表明,ROBT方法很容易收敛:
ROBT中的参数T影响(模型容量分配的集中度)
如图10所示:
- 在ROBT算法中,仅考虑zero-shot translation所要测试的语种,使得模型的容量分配更加集中,但效果提升幅度不大。

总结
本文使用target language specific parameter和让模型更加deep,来改善模型容量不足问题。缺点之一在于没有考虑source端的language specific构造。
另外,本文使用ROBT算法来缓解zero-shot中的off-target问题。