本文主要讲解 ClickHouse 的一些典型分析应用案例,重点就是告诉,一些大厂在做技术选型的时候,也就是因为 ClickHouse 的这些特点才使用的。 下面主要内容大致如下:
分组前几函数 TopK
窗口分析函数
同比环比
漏斗分析 windowFunnel
如何利用 clickhouse 实现去重
ClickHouse 整合 BitMap
ClickHouse 介绍和适用场景
ClickHouse 是“战斗民族”俄罗斯搜索巨头 Yandex 公司开源的一个极具"战斗力"的实时数据分析数据库,是面向 OLAP 的分布式列式 DBMS,圈内人戏称 为“喀秋莎数据库”。ClickHouse 有一个简称 "CK",与 Hadoop、Spark 这些巨无霸组件相比,ClickHouse 很轻量级,其特点包括:分布式、列式存储、 异步复制、线性扩展、支持数据压缩和最终数据一致性,其数据量级在 PB 级别。
ClickHouse 的适用场景:
01、绝大多数请求都是用于读访问,而且不是单点访问
02、数据需要以大批次(大于1000行)进行更新,而不是单行更新;或者根本没有更新操作
03、数据只是添加到数据库,没有必要修改
04、读取数据时,会从数据库中提取出大量的行,但只用到一小部分列
05、表很“宽”,即表中包含大量的列
06、查询频率相对较低(通常每台服务器每秒查询数百次或更少)
07、对于简单查询,允许大约50毫秒的延迟
08、列的值是比较小的数值和短字符串(例如,每个URL只有60个字节)
09、在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行)
10、不需要事务
11、数据一致性要求较低
12、每次查询中只会查询一个大表。除了一个大表,其余都是小表
13、查询结果显著小于数据源。即数据有过滤或聚合。返回结果不超过单个服务器内存大小2.2. ClickHouse 经典大厂分析案例
2.2.1. 分组前几函数 TopK
创建表
CREATE TABLE nx_topK_test ( a Int32,b Int32,c Int32) ENGINE = Memory;
插入数据
insert into nx_topK_test ( a,b,c) values (1,2,5),(1,2,4),(1,3,8),(1,3,2),(1,4,6),(2,3,3),(2,3,7),(2,3,8),(2,4,9),
(2,5,6),(3,3,4),(3,3,7),(3,3,5),(3,4,9),(3,5,6);
查看展示
SELECT * FROM nx_topK_test ORDER BY a ASC;
select a,b,c from nx_topK_test order by a asc,c desc;
查询 SQL:
-- 默认,topk 只取,这一组的前k个元素
SELECT a, topK(2)(c) FROM nx_topK_test group by a;
-- 所以,需要先按照要求,给数据进行排序,然后进行 topk 操作,就可以取到每组的前几个元素
SELECT a, topK(3)(c) FROM (select a,c from nx_topK_test order by a asc, c desc)
group by a order by a;
2.2.2. 窗口分析函数
Window Functions 在 clickhouse 的需求和呼声很高,早期的版本需要借助 array 函数,在 21.1 版本进行了开窗函数的初步支持。
查询版本:
select version();需要设置参数:
SET allow_experimental_window_functions = 1;
创建表:
create table nx_window_data_test(id String, score UInt8)
engine=MergeTree() order by id;生成测试数据:
insert into nx_window_data_test(id,score) values
('A', 90),
('A', 80),
('A', 88),
('A', 86),
('B', 91),
('B', 95),
('B', 90),
('C', 88),
('C', 89),
('C', 90);查询表数据
select * from nx_window_data_test;
select * from nx_window_data_test order by id, score desc;计算分组累加
select id, score, sum(score) over(partition by id order by score) sum from nx_window_data_test;
select id, score, max(score) over(partition by id order by score) max from nx_window_data_test;
select id, score, min(score) over(partition by id order by score) min from nx_window_data_test;
select id, score, avg(score) over(partition by id order by score) avg from nx_window_data_test;
select id, score, count(score) over(partition by id order by score) count from nx_window_data_test;目前已经支持 min,max,avg,count,sum 等分组函数。 看具体需求:每个用户截止到每月为止的最大单月访问次数和累计到该月的总访问次数 创建表:
create table exercise_pv(id String, month String, pv UInt32)
engine=MergeTree() order by id;
插入数据
insert into exercise_pv(id, month, pv) values
('A', '2015-01', 33),
('A', '2015-02', 10),
('A', '2015-03', 38),
('A', '2015-04', 20),
('B', '2015-01', 30),
('B', '2015-02', 15),
('B', '2015-03', 44),
('B', '2015-04', 35);查询数据
select * from exercise_pv;
实现需求
select
id,
month,
pv,
sum(pv) over(partition by id order by month) sum,
max(pv) over(partition by id order by month) max
from exercise_pv;
同比环比
先弄清楚这两对概念:
跟去年同期比:同比增长率 =(本期数 - 同期数) / 同期数 = (202105 - 202005)/ 202005
跟上个月比:环比增长率 =(本期数 - 上期数) / 上期数 = (202105 - 202004)/ 202004
构造数据
with toDate('2020-01-01') as start_date
select toStartOfMonth(start_date + (number*31)) month_start,
(number+20)*100 amount from numbers(24);同环比案例
WITH toDate('2020-01-01') AS start_date
SELECT
toStartOfMonth(start_date + (number * 31)) AS month_start,
(number + 20) * 100 AS amount,
neighbor(amount, -12) AS prev_year_amount,
neighbor(amount, -1) AS prev_month_amount
FROM numbers(24);
WITH toDate('2020-01-01') AS start_date
SELECT
toStartOfMonth(start_date + (number * 31)) AS month_start,
(number + 20) * 100 AS amount,
neighbor(amount, -12) AS prev_year_amount,
neighbor(amount, -1) AS prev_month_amount,
if(prev_year_amount = 0, -999, amount - prev_year_amount) as year_inc,
if(prev_year_amount = 0, -999, round((amount - prev_year_amount) / prev_year_amount, 4)) AS year_over_year,
if(prev_year_amount = 0, -999, amount - prev_month_amount) as month_inc,
if(prev_month_amount = 0, -999, round((amount - prev_month_amount) / prev_month_amount, 4)) AS month_over_month
FROM numbers(24);neighbor函数可以说是 lag() 与 lead() 的合体,它可以根据指定的 offset,向前或者向后获取到相应字段的值,其完整定义为:
neighbor(column, offset[, default_value])
漏斗分析
windowFunnel 漏斗模型:主要涉及到转化!
下单成交漏斗分析:
1、广告曝光 1000W
2、点击 20W
3、详情页 19W
4、加入购物车 2W
5、下单 1W
6、支付 8000
7、支付成功 7500
8、收货成功,结束订单 6000创建表:
CREATE TABLE nx_window_funnel_test
(uid String,
eventid String,
eventTime UInt64)
ENGINE = Memory;
插入数据:
insert into nx_window_funnel_test (uid,eventid,eventTime) values
('A','login',20200101),
('A','view',20200102),
('A','buy',20200103),
('B','login',20200101),
('B','view',20200102),
('C','login',20200101),
('C','buy',20200102),
('D','login',20200101),
('D','view',20200103),
('D','buy',20200102);
查询结果:
select * from nx_window_funnel_test order by uid;
查询 SQL:
SELECT
uid,
windowFunnel(2)(eventTime, eventid = 'login', eventid = 'view', eventid = 'buy') AS res
FROM nx_window_funnel_test
GROUP BY uid
order by uid;2.2.5. 如何利用 clickhouse 实现去重
1、非精确去重函数:uniq、uniqHLL12、uniqCombined、uniqCombined64
2、精确去重函数:uniqExact、groupBitmap
注意他们的用法:
1、整形值精确去重场景,groupBitmap 比 uniqExact 快很多
2、groupBitmap 仅支持整形值去重, uniqExact 支持任意类型(Tuple、Array、Date
、DateTime、String和数字类型)去重。
3、非精确去重场景,uniq 在精准度上有优势。
4、uniq是近似去重,千万级用户,精确度能达到99%以上,uniqExact是精确去重
,和mysql的count distinct功能相同,比如统计uv。
关注和了解:近似去重算法:HyperLogLog 算法 和 BitMap 算法相关。 准备数据:
在 MySQL 数据库中,有一个 nx_job 里面有一张表: job : 55875 条记录!
创建库:
create database if not exists nx_job ENGINE = MySQL(
'bigdata02:3306', 'nx_job', 'root', 'QWer_1234');
创建表:
create database if not exists nx_job1;
use nx_job1;
create table job
(
id UInt32,
t_job String,
t_addr String,
t_tag String,
t_com String,
t_money String,
t_edu String,
t_exp String,
t_type String,
t_level String
) ENGINE = MergeTree() order by id;插入数据:
insert into job(id, t_job, t_addr, t_tag, t_com, t_money ,t_edu ,
t_exp ,t_type ,t_level)
select id, t_job, t_addr,
t_tag, t_com, t_money ,t_edu ,t_exp ,t_type ,t_level from nx_job.job;查询数据:
select * from job limit 3;
select count(*) as total from job;
测试:
-- 精确去重
select count(distinct id) as total from job;
select countDistinct(id) as total from job;
-- 精确去重
select uniqExact(id) from job;
select groupBitmap(id) from job;
-- 近似去重
select uniq(id) from job;
select uniqHLL12(id) from job;
比如,腾讯在进行 去重 方案选择的时候,其实对比了很多方案:
1、基于TDW临时表的方案,在 pysql 中循环对每个活动执行对应的 hiveSQL 来完成 T+1 时效的计算
2、基于实时计算+文件增量去重的方案,虽然可在 Storm 中进行 HLL 近似去重,但是内存资源有限,无法给出精确的结果和最终的号码包文件,而且导致每日新
增几十万小文件
3、基于实时计算+LevelDB增量去重方案,LevelDB是KV存储,key存文件名,value存储文件内容,可执行毫秒级去重,可在10s内导出千万量级的数据。但是扩
展性较差,数据回溯困难。
4、基于CLickHouse的解决方案,灵活,扩展性强,轻量级。最终选择了 ClickHouse,去重服务就变成了 SQL 查询,例如下面这条 SQL 就是查询 LOL 官网某个页面在 9 月 6 日这 1 天的 UV:
select uniqExact(uvid) from tbUv where date='2020-09-06' and url='http://lol.qq.com/main.shtml';2.2.6. ClickHouse 整合 BitMap
大表 join 的方案!
每个 bit 位表示一个数字 id,对于 40 亿个的用户 id,只需要 40 亿 bit 位,约 477m 大小 = (4 * 10^9 / 8 / 1024 / 1024)
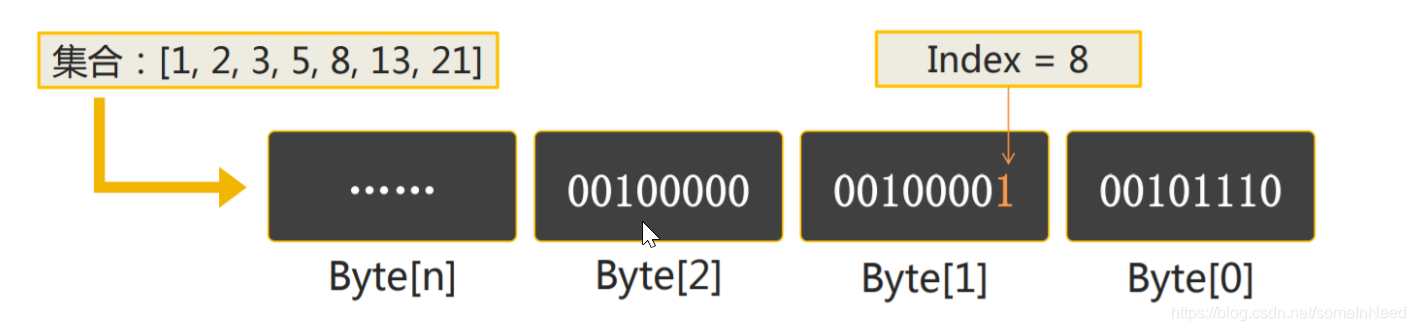
通过单个 bitmap 可以完成精确去重操作,通过多个 bitmap 的 and、or、xor、andnot 等位操作完成留存分析、漏斗分析、用户画像分析等场景的计 算。 关于 ClickHouse 的位图函数:https://clickhouse.tech/docs/zh/sql-reference/functions/bitmap-functions/
需求案例一:电信用户每个月的话费统计。
0100110101000101010100101010101 这串数字一共31位的,每一位代表某个月某一天,如电信的号码某一天有通话记录就置成1,没有为0
1101010101010101010100101010100 这串数字一共31位的,每一位代表某个月某一天,如电信的号码某一天有流量记录就置成1,没有为0
1101110101010101..只要打了电话,或者有流量记录,则记为1,则收取1块钱。 需求案例二:统计微信过去连续7天都发朋友圈的用户集。
每天的朋友圈信息,构建成一张表(110)经过 bitmap 的构建,每天的15E 用户是否发朋友圈的信息,就被构建成了一个 长度为 15E 的 二进制序列
1号用户发了3条朋友圈,就是3条信息
2号用户发了2条朋友圈,就是2条信息
3号用户没有发朋友圈7 张表做 join 链接 table1 1号 所有用户发朋友圈的信息的表 = bitmap = 101010101010110101010101011010101 = s1 table2 2号 所有用户发朋友圈的信息的表 = bitmap = 101010101010110101010101011010101 = s2 table3 2号 所有用户发朋友圈的信息的表 = bitmap = 101010101010110101010101011010101 = s3 ..... 最后的计算就变成了: s1 & s2 & s3 & s4 & s5 & s6 & s7 = result
最后的结论:ClickHouse 的优势,是适用于 大数据量级 的单张大宽表的 聚合查询分析。除此之外的需求,相对来,都不是 ClickHouse 擅长的事情。 在使用的时候,慎重。