原文链接
如果打不开,也可以复制链接到https://nbviewer.jupyter.org中打开。
循环序列模型 Character level language model-Dinosaurus Island 字符级语言模型-恐龙岛
欢迎来到恐龙岛!6500万年前,恐龙就存在了,在这次任务中它们又回来了。
你负责一项特殊任务。生物学研究人员正在创造新的恐龙品种,并将它们带到地球上,而你的工作就是给这些恐龙命名。如果一只恐龙不喜欢它的名字,它可能会发疯,所以明智地选择!

幸运的是,你学到了一些DL的知识,你将用它来避免起错名字。你的助手收集了一份他们能找到的所有恐龙名字的列表,并将它们汇编到这个数据集中。(点击前面的链接可以随意查看。)要创建新的恐龙名称,你将构建一个字符级语言模型来生成新名称。你的算法将学习不同的名称模式,并随机生成新名称。希望这个算法能让你和你的团队远离恐龙的愤怒!
完成本练习,你将学到
- 如何存储文本数据以便使用RNN进行处理。
- 如何通过在每个时间步对预测进行采样并将其传递给下一个RNN单元来合成数据
- 如何构建字符级文本生成RNN
- 为什么梯度修剪很重要?
我们将首先加载在rnn_utils中为你提供的一些函数。具体来说,您可以访问诸如rnn_forward和rnn_backward 之类的函数,这些函数等同于你在上一个任务中实现的函数。
import numpy as np
from utils import *
import random
from random import shuffle
1 问题描述
1.1 数据集和预处理
运行以下代码以读取恐龙名称的数据集,创建唯一字符(如a-z)的列表,并计算数据集和词汇表大小。
data = open('dinos.txt', 'r').read()
data= data.lower()
chars = list(set(data))
data_size, vocab_size = len(data), len(chars)
print('There are %d total characters and %d unique characters in your data.' % (data_size, vocab_size))
结果
There are 19909 total characters and 27 unique characters in your data.
字符是a-z(26个字符)加上“\n”(或换行符),在本作业中,它起着类似于我们在课程中讨论的(或“句尾”)标记的作用,只是在这里它表示恐龙名称的结尾,而不是句子的结尾。
在下面的代码中,我们创建一个python字典(即哈希表),将每个字符映射到0-26之间的索引。
我们还创建了第二个python字典,将每个索引映射回相应的字符。
这将帮助你找出哪个索引对应于softmax层的概率分布输出中的哪个字符。
在下面,char_to_ix和ix_to_char是python字典。
char_to_ix = {
ch:i for i,ch in enumerate(sorted(chars)) }
ix_to_char = {
i:ch for i,ch in enumerate(sorted(chars)) }
print(ix_to_char)
结果
{
0: '\n', 1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e', 6: 'f', 7: 'g', 8: 'h', 9: 'i', 10: 'j', 11: 'k', 12: 'l', 13: 'm', 14: 'n', 15: 'o', 16: 'p', 17: 'q', 18: 'r', 19: 's', 20: 't', 21: 'u', 22: 'v', 23: 'w', 24: 'x', 25: 'y', 26: 'z'}
1.2 模型概述
你的模型将具有以下结构:
- 初始化参数
- 运行优化循环
- 前向传播计算损失
- 反向传播计算关于损失的梯度
- 修剪梯度以免梯度爆炸
- 用梯度下降更新规则更新参数
- 返回学习好的参数
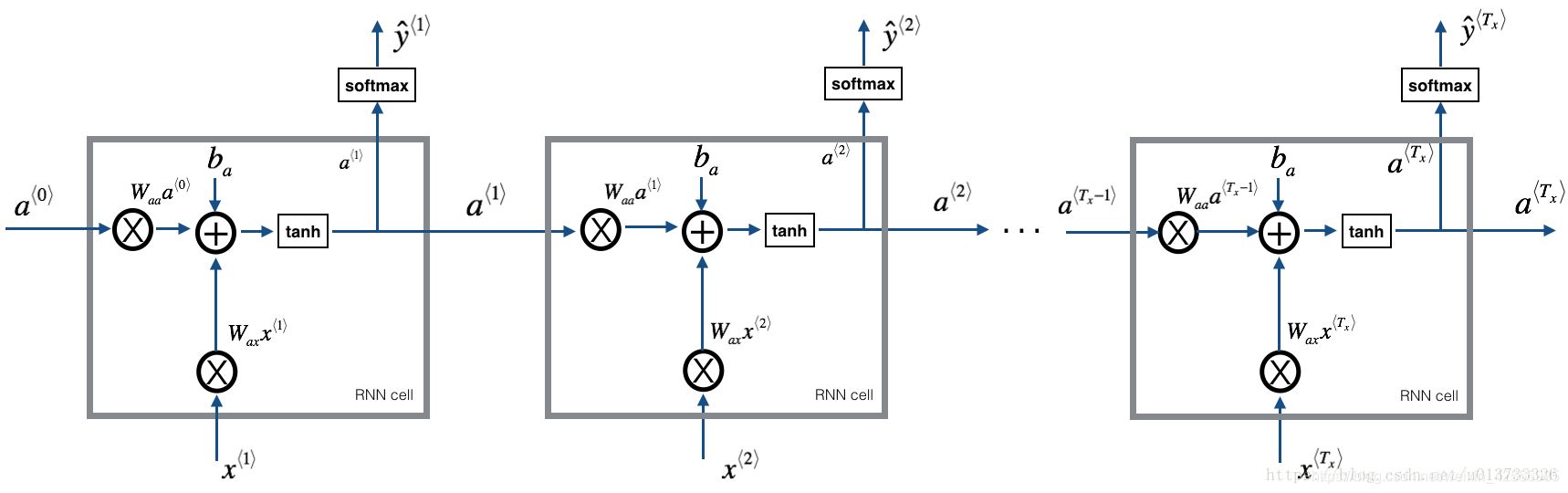
在每一个时间步,RNN都试图预测给定一个字符的下一个字符是什么。
数据集 X = ( x ⟨ 1 ⟩ , x ⟨ 2 ⟩ , . . . , x ⟨ T x ⟩ ) X = (x^{\langle 1 \rangle}, x^{\langle 2 \rangle}, ..., x^{\langle T_x \rangle}) X=(x⟨1⟩,x⟨2⟩,...,x⟨Tx⟩)是一个列表类型的字符训练集,同时 Y = ( y ⟨ 1 ⟩ , y ⟨ 2 ⟩ , . . . , y ⟨ T x ⟩ ) Y = (y^{\langle 1 \rangle}, y^{\langle 2 \rangle}, ..., y^{\langle T_x \rangle}) Y=(y⟨1⟩,y⟨2⟩,...,y⟨Tx⟩)在每个时间步 t t t亦是如此,因此, y ⟨ t ⟩ = x ⟨ t + 1 ⟩ y^{\langle t \rangle} = x^{\langle t+1 \rangle} y⟨t⟩=x⟨t+1⟩。
2 构建模型中的模块
在本部分中,你将构建整个模型的两个重要模块
- 梯度修剪:避免梯度爆炸
- 取采样:一种用来产生字符的技术
然后应用这两个函数来构建模型。
2.1 梯度修剪
本节中你将实现一个clip函数,它将在优化循环中被调用。回想一下,你的整个循环结构通常由前向传播、成本计算、反向传博和参数更新组成。在更新参数之前,你将在需要时执行梯度剪裁,以确保梯度不会“爆炸”,这意味着使用过大的值。
在下面的练习中,你将实现一个函数clip,它输入梯度字典,并在需要时输出梯度的剪裁版本。有不同的方法来剪裁梯度;我们将使用一个简单的按元素剪裁的过程,其中梯度向量的每个元素都被剪裁到某个范围[-N,N]之间。一般来说,你将提供一个maxValue(比如10)。在本例中,
- 如果梯度向量的任何分量大于10,则将其设置为10;
- 如果梯度向量的任何分量小于-10,则将其设置为-10。
- 如果它在-10和10之间,它不变。
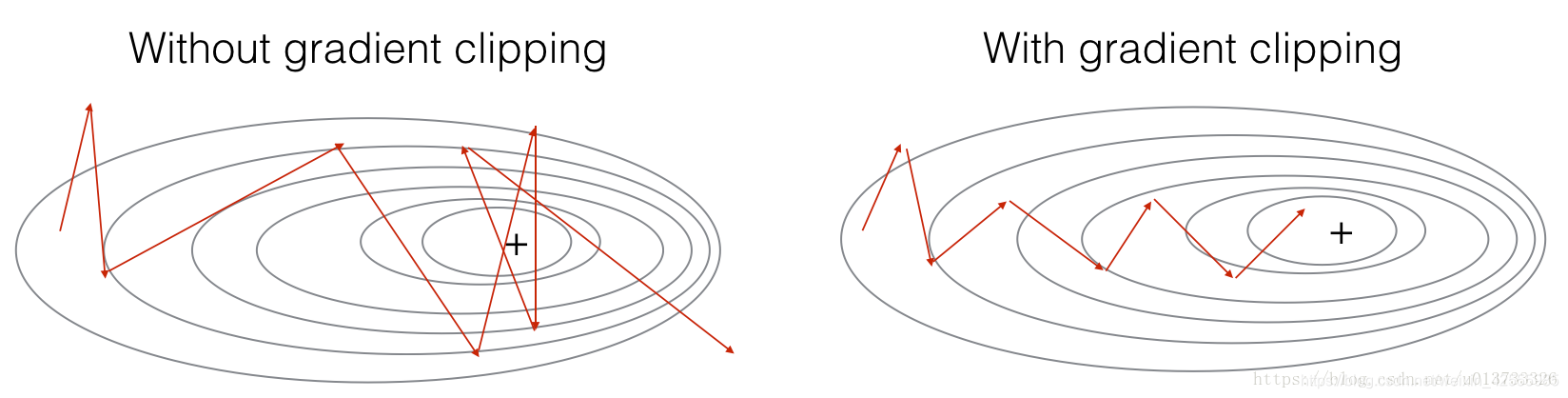
练习:实现下面的函数返回你的裁剪后的梯度字典gradients。你的函数接受最大阈值并返回梯度的剪裁版本。你可以查看这个提示,了解如何在numpy中进行剪辑的示例
实现代码
### GRADED FUNCTION: clip
def clip(gradients, maxValue):
'''
Clips the gradients' values between minimum and maximum.
使用maxValue来修剪梯度
Arguments:
gradients -- a dictionary containing the gradients "dWaa", "dWax", "dWya", "db", "dby"
字典类型,包含了以下参数:"dWaa", "dWax", "dWya", "db", "dby"
maxValue -- everything above this number is set to this number, and everything less than -maxValue is set to -maxValue
阈值,把梯度值限制在[-maxValue, maxValue]内
Returns:
gradients -- a dictionary with the clipped gradients. 修剪后的梯度
'''
# 获取参数
dWaa, dWax, dWya, db, dby = gradients['dWaa'], gradients['dWax'], gradients['dWya'], gradients['db'], gradients['dby']
### START CODE HERE ###
# clip to mitigate exploding gradients, loop over [dWax, dWaa, dWya, db, dby]. (≈2 lines)
# 梯度修剪
for gradient in [dWax, dWaa, dWya, db, dby]:
np.clip(gradient, -maxValue, maxValue, out=gradient)
### END CODE HERE ###
gradients = {
"dWaa": dWaa, "dWax": dWax, "dWya": dWya, "db": db, "dby": dby}
return gradients
测试一下
np.random.seed(3)
dWax = np.random.randn(5,3)*10
dWaa = np.random.randn(5,5)*10
dWya = np.random.randn(2,5)*10
db = np.random.randn(5,1)*10
dby = np.random.randn(2,1)*10
gradients = {
"dWax": dWax, "dWaa": dWaa, "dWya": dWya, "db": db, "dby": dby}
gradients = clip(gradients, 10)
print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
print("gradients[\"dWax\"][3][1] =", gradients["dWax"][3][1])
print("gradients[\"dWya\"][1][2] =", gradients["dWya"][1][2])
print("gradients[\"db\"][4] =", gradients["db"][4])
print("gradients[\"dby\"][1] =", gradients["dby"][1])
结果
gradients["dWaa"][1][2] = 10.0
gradients["dWax"][3][1] = -10.0
gradients["dWya"][1][2] = 0.2971381536101662
gradients["db"][4] = [10.]
gradients["dby"][1] = [8.45833407]
2.2 采样
现在假设你的模型已经训练过了。你想生成新文本(字符)。生成过程如下图所示:

练习:实现sample函数来采样字符。它由四步组成:
- 向网络传递第一个“伪”输入 x ⟨ 1 ⟩ = 0 ⃗ x^{\langle 1\rangle}=\vec{0} x⟨1⟩=0(零的向量)。这是生成任何字符之前的默认输入。同时我们还设置了 a ⟨ 0 ⟩ = 0 ⃗ a^{\langle 0\rangle}=\vec{0} a⟨0⟩=0
- 运行前向传播的一步以获得 a ⟨ 1 ⟩ a^{\langle 1\rangle} a⟨1⟩和 y ^ ⟨ 1 ⟩ \hat{y}^{\langle 1\rangle} y^⟨1⟩。公式如下:
a ⟨ t + 1 ⟩ = t a n h ( W a x x ⟨ t ⟩ + W a a a ⟨ t ⟩ + b ) (1) a^{⟨t+1⟩}=tanh(W_{ax}x^{⟨t⟩}+W_{aa}a^{⟨t⟩}+b)\tag 1 a⟨t+1⟩=tanh(Waxx⟨t⟩+Waaa⟨t⟩+b)(1)
z ⟨ t + 1 ⟩ = W y a a ⟨ t + 1 ⟩ + b y (2) z^{⟨t+1⟩}=W_{ya}a^{⟨t+1⟩}+b_y\tag 2 z⟨t+1⟩=Wyaa⟨t+1⟩+by(2)
y ⟨ t + 1 ⟩ = s o f t m a x ( z ⟨ t + 1 ⟩ ) (3) y^{⟨t+1⟩}=softmax(z^{⟨t+1⟩})\tag 3 y⟨t+1⟩=softmax(z⟨t+1⟩)(3)
请注意,
- y ^ ⟨ t + 1 ⟩ \hat{y}^{\langle t+1\rangle} y^⟨t+1⟩是一个(softmax)概率向量(其元素介于0和1之间,总和为1)。
- y ^ i ⟨ t + 1 ⟩ \hat{y}^{\langle t+1\rangle}_i y^i⟨t+1⟩表示索引“i”的字符是下一个字符的概率。
我们提供了一个softmax()函数,你可以使用它。
- 进行采样:根据 y ^ ⟨ t + 1 ⟩ \hat{y}^{\langle t+1\rangle} y^⟨t+1⟩指定的概率分布选择下一个字符的索引。意思是如果 y ^ i ⟨ t + 1 ⟩ = 0.16 \hat{y}^{\langle t+1\rangle}_i=0.16 y^i⟨t+1⟩=0.16,你将以16%的概率选择索引“i”。为了实现它,你可以使用np.random.choice函数。
下面是如何使用np.random.choice()的例子
np.random.seed(0)
p = np.array([0.1, 0.0, 0.7, 0.2])
index = np.random.choice([0, 1, 2, 3], p = p.ravel())
这意味着你将根据这个分布选择索引index: P ( i n d e x = 0 ) = 0.1 , P ( i n d e x = 1 ) = 0.0 , P ( i n d e x = 2 ) = 0.7 , P ( i n d e x = 3 ) = 0.2 P(index = 0) = 0.1, P(index = 1) = 0.0, P(index = 2) = 0.7, P(index = 3) = 0.2 P(index=0)=0.1,P(index=1)=0.0,P(index=2)=0.7,P(index=3)=0.2。
- 在sample()中实现的最后一步是用 x ⟨ t + 1 ⟩ x^{\langle t+1\rangle} x⟨t+1⟩覆盖变量x,x变量当前存储值为 x ⟨ t ⟩ x^{\langle t\rangle} x⟨t⟩。你将通过创建一个与你所选择的字符相对应的一个独热向量来表示 x ⟨ t + 1 ⟩ x^{\langle t+1\rangle} x⟨t+1⟩。然后,你将在步骤1中向前传播 x ⟨ t + 1 ⟩ x^{\langle t+1\rangle} x⟨t+1⟩,并不断重复此过程,直到获得一个“\n”字符,表示i已到达恐龙名称的末尾。
实现代码
# GRADED FUNCTION: sample
def sample(parameters, char_to_ix, seed):
"""
Sample a sequence of characters according to a sequence of probability distributions output of the RNN
根据RNN输出的概率分布序列对字符序列进行采样
Arguments:
parameters -- python dictionary containing the parameters Waa, Wax, Wya, by, and b.
包含了Waa, Wax, Wya, by, b的字典
char_to_ix -- python dictionary mapping each character to an index.
字符映射到索引的字典
seed -- used for grading purposes. Do not worry about it. 随机种子
Returns:
indices -- a list of length n containing the indices of the sampled characters.
包含采样字符索引的长度为n的列表。
"""
# Retrieve parameters and relevant shapes from "parameters" dictionary
# 从parameters 中获取参数
Waa, Wax, Wya, by, b = parameters['Waa'], parameters['Wax'], parameters['Wya'], parameters['by'], parameters['b']
vocab_size = by.shape[0]
n_a = Waa.shape[1]
### START CODE HERE ###
# Step 1: Create the one-hot vector x for the first character (initializing the sequence generation). (≈1 line)
# 步骤1 创建独热向量x
x = np.zeros((vocab_size, 1))
# Step 1': Initialize a_prev as zeros (≈1 line)## 使用0初始化a_prev
a_prev = np.zeros((n_a, 1))
# Create an empty list of indices, this is the list which will contain the list of indices of the characters to generate (≈1 line)
# 创建索引的空列表,这是包含要生成的字符的索引的列表。
indices = []
# Idx is a flag to detect a newline character, we initialize it to -1
# IDX是检测换行符的标志,我们将其初始化为-1。
idx = -1
# Loop over time-steps t. At each time-step, sample a character from a probability distribution and append
# its index to "indices". We'll stop if we reach 50 characters (which should be very unlikely with a well
# trained model), which helps debugging and prevents entering an infinite loop.
# 循环遍历时间步骤t。在每个时间步中,从概率分布中抽取一个字符,并将其索引附加到“indices”上。
# 如果我们达到50个字符(这在一个训练很好的模型中不太可能),我们将停止循环,这有助于调试并防止进入无限循环
counter = 0
newline_character = char_to_ix['\n']
while (idx != newline_character and counter != 50):
# Step 2: Forward propagate x using the equations (1), (2) and (3)
# 步骤2:使用公式1、2、3进行前向传播
a = np.tanh(np.dot(Wax, x) + np.dot(Waa, a_prev) + b)
z = np.dot(Wya, a) + by
y = softmax(z)
# for grading purposes # 设定随机种子
np.random.seed(counter+seed)
# Step 3: Sample the index of a character within the vocabulary from the probability distribution y
# 步骤3:从概率分布y中抽取词汇表中字符的索引
idx = np.random.choice(list(range(vocab_size)), p=y.ravel())
# Append the index to "indices" # 添加到索引中
indices.append(idx)
# Step 4: Overwrite the input character as the one corresponding to the sampled index.
# 步骤4:将输入字符重写为与采样索引对应的字符。
x = np.zeros((vocab_size, 1))
x[idx] = 1
# Update "a_prev" to be "a" # 更新a_prev为a
a_prev = a
# for grading purposes # 累加器
seed += 1
counter +=1
### END CODE HERE ###
if (counter == 50):
indices.append(char_to_ix['\n'])
return indices
测试一下
np.random.seed(2)
n, n_a = 20, 100
a0 = np.random.randn(n_a, 1)
i0 = 1 # first character is ix_to_char[i0]
Wax, Waa, Wya = np.random.randn(n_a, vocab_size), np.random.randn(n_a, n_a), np.random.randn(vocab_size, n_a)
b, by = np.random.randn(n_a, 1), np.random.randn(vocab_size, 1)
parameters = {
"Wax": Wax, "Waa": Waa, "Wya": Wya, "b": b, "by": by}
indices = sample(parameters, char_to_ix, 0)
print("Sampling:")
print("list of sampled indices:", indices)
print("list of sampled characters:", [ix_to_char[i] for i in indices])
结果
Sampling:
list of sampled indices: [18, 2, 26, 0]
list of sampled characters: ['r', 'b', 'z', '\n']
3 构建语言模型
现在是时候构建字符级语言模型来生成文本。
3.1 梯度下降
在本节中,你将实现一个函数,该函数执行一步随机梯度下降(使用剪裁梯度)。你将一次训练一个样本,因此优化算法将是随机梯度下降。提醒一下,以下是RNN通用优化循环的步骤:
- 通过RNN进行前向传播计算损失
- 反向传播计算关于参数的梯度损失
- 如果需要,裁剪梯度
- 使用梯度下降更新参数
练习:实现此优化过程(单步随机梯度下降)
我们提供给你下面的函数
def rnn_forward(X, Y, a_prev, parameters):
""" Performs the forward propagation through the RNN and computes the cross-entropy loss.
通过RNN进行前向传播,计算交叉熵损失。
它返回损失的值以及存储在反向传播中使用的“缓存”值。
It returns the loss' value as well as a "cache" storing values to be used in the backpropagation."""
....
return loss, cache
def rnn_backward(X, Y, parameters, cache):
""" Performs the backward propagation through time to compute the gradients of the loss with respect
to the parameters. It returns also all the hidden states.
通过时间进行反向传播,计算相对于参数的梯度损失。它还返回所有隐藏的状态"""
...
return gradients, a
def update_parameters(parameters, gradients, learning_rate):
""" Updates parameters using the Gradient Descent Update Rule."""
...
return parameters
优化过程实现代码如下
# GRADED FUNCTION: optimize
def optimize(X, Y, a_prev, parameters, learning_rate = 0.01):
"""
Execute one step of the optimization to train the model.
执行训练模型的单步优化。
Arguments:
X -- list of integers, where each integer is a number that maps to a character in the vocabulary.
整数列表,其中每个整数映射到词汇表中的字符。
Y -- list of integers, exactly the same as X but shifted one index to the left.
整数列表,与X完全相同,但向左移动了一个索引。
a_prev -- previous hidden state.
上一个隐藏状态
parameters -- python dictionary containing:
Wax -- Weight matrix multiplying the input, numpy array of shape (n_a, n_x)
权重矩阵乘以输入,维度为(n_a, n_x)
Waa -- Weight matrix multiplying the hidden state, numpy array of shape (n_a, n_a)
权重矩阵乘以隐藏状态,维度为(n_a, n_a)
Wya -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a)
隐藏状态与输出相关的权重矩阵,维度为(n_y, n_a)
b -- Bias, numpy array of shape (n_a, 1)
偏置,维度为(n_a, 1)
by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1)
隐藏状态与输出相关的权重偏置,维度为(n_y, 1)
learning_rate -- learning rate for the model. 模型学习的速率
Returns:
loss -- value of the loss function (cross-entropy) 损失函数的值(交叉熵损失)
gradients -- python dictionary containing:
dWax -- Gradients of input-to-hidden weights, of shape (n_a, n_x)
输入到隐藏的权值的梯度,维度为(n_a, n_x)
dWaa -- Gradients of hidden-to-hidden weights, of shape (n_a, n_a)
隐藏到隐藏的权值的梯度,维度为(n_a, n_a)
dWya -- Gradients of hidden-to-output weights, of shape (n_y, n_a)
隐藏到输出的权值的梯度,维度为(n_y, n_a)
db -- Gradients of bias vector, of shape (n_a, 1)
偏置的梯度,维度为(n_a, 1)
dby -- Gradients of output bias vector, of shape (n_y, 1)
输出偏置向量的梯度,维度为(n_y, 1)
a[len(X)-1] -- the last hidden state, of shape (n_a, 1) 最后的隐藏状态,维度为(n_a, 1)
"""
### START CODE HERE ###
# Forward propagate through time (≈1 line) 前向传播
loss, cache = rnn_forward(X, Y, a_prev, parameters)
# Backpropagate through time (≈1 line) 反向传播
gradients, a = rnn_backward(X, Y, parameters, cache)
# Clip your gradients between -5 (min) and 5 (max) (≈1 line) 梯度修剪,[-5 , 5]
gradients = clip(gradients, 5)
# Update parameters (≈1 line) 更新参数
parameters = update_parameters(parameters, gradients, learning_rate)
### END CODE HERE ###
return loss, gradients, a[len(X)-1]
测试一下
np.random.seed(1)
vocab_size, n_a = 27, 100
a_prev = np.random.randn(n_a, 1)
Wax, Waa, Wya = np.random.randn(n_a, vocab_size), np.random.randn(n_a, n_a), np.random.randn(vocab_size, n_a)
b, by = np.random.randn(n_a, 1), np.random.randn(vocab_size, 1)
parameters = {
"Wax": Wax, "Waa": Waa, "Wya": Wya, "b": b, "by": by}
X = [12,3,5,11,22,3]
Y = [4,14,11,22,25, 26]
loss, gradients, a_last = optimize(X, Y, a_prev, parameters, learning_rate = 0.01)
print("Loss =", loss)
print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
print("np.argmax(gradients[\"dWax\"]) =", np.argmax(gradients["dWax"]))
print("gradients[\"dWya\"][1][2] =", gradients["dWya"][1][2])
print("gradients[\"db\"][4] =", gradients["db"][4])
print("gradients[\"dby\"][1] =", gradients["dby"][1])
print("a_last[4] =", a_last[4])
结果
Loss = 126.50397572165345
gradients["dWaa"][1][2] = 0.19470931534725341
np.argmax(gradients["dWax"]) = 93
gradients["dWya"][1][2] = -0.007773876032004315
gradients["db"][4] = [-0.06809825]
gradients["dby"][1] = [0.01538192]
a_last[4] = [-1.]
3.2 训练模型
给定恐龙名称的数据集,我们使用数据集的每一行(一个名称)作为一个训练样本。每100步随机梯度下降,你将随机抽取10个名字,看看算法是如何做的。记住打乱数据集,以便随机梯度下降以随机顺序访问样本。
练习:根据下面的指导实现model()。examples[index]保存一个恐龙名称(字符串),你可以使用以下代码创建样本 (X, Y)
index = j % len(examples)
X = [None] + [char_to_ix[ch] for ch in examples[index]]
Y = X[1:] + [char_to_ix["\n"]]
注意,我们使用index= j % len(examples), 其中 j = 1....num_iterations,来确保examples[index]总是有效的(index比 len(examples)小)。rnn_forward()会将X的第一个值None解释为 x ⟨ 0 ⟩ = 0 ⃗ x^{\langle 0 \rangle} = \vec{0} x⟨0⟩=0
。此外,为了确保Y等于X,会向左移动一步,并添加一个附加的“\n”以表示恐龙名称的结束。
实现代码
# GRADED FUNCTION: model
def model(data, ix_to_char, char_to_ix, num_iterations = 35000, n_a = 50, dino_names = 7, vocab_size = 27):
"""
Trains the model and generates dinosaur names. 训练模型并生成恐龙名字
Arguments:
data -- text corpus 文本语料库
ix_to_char -- dictionary that maps the index to a character
索引映射字符字典
char_to_ix -- dictionary that maps a character to an index
字符映射索引字典
num_iterations -- number of iterations to train the model for
迭代次数
n_a -- number of units of the RNN cell RNN单元数量
dino_names -- number of dinosaur names you want to sample at each iteration.
每次迭代中要采样的恐龙名称数
vocab_size -- number of unique characters found in the text, size of the vocabulary
在文本中的唯一字符的数量
Returns:
parameters -- learned parameters 学习后了的参数
"""
# Retrieve n_x and n_y from vocab_size 从vocab_size中获取n_x、n_y
n_x, n_y = vocab_size, vocab_size
# Initialize parameters 初始化参数
parameters = initialize_parameters(n_a, n_x, n_y)
# Initialize loss (this is required because we want to smooth our loss, don't worry about it)
#初始化损失
loss = get_initial_loss(vocab_size, dino_names)
# Build list of all dinosaur names (training examples). # 构建恐龙名称列表
with open("dinos.txt") as f:
examples = f.readlines()
examples = [x.lower().strip() for x in examples]
# Shuffle list of all dinosaur names # 打乱全部的恐龙名称
shuffle(examples)
# Initialize the hidden state of your LSTM # 初始化LSTM隐藏状态
a_prev = np.zeros((n_a, 1))
# Optimization loop
for j in range(num_iterations):
### START CODE HERE ###
# Use the hint above to define one training example (X,Y) (≈ 2 lines)
# 定义一个训练样本
index = j % len(examples)
X = [None] + [char_to_ix[ch] for ch in examples[index]]
Y = X[1:] + [char_to_ix["\n"]]
# Perform one optimization step: Forward-prop -> Backward-prop -> Clip -> Update parameters
# 执行单步优化:前向传播 -> 反向传播 -> 梯度修剪 -> 更新参数
# Choose a learning rate of 0.01 # 选择学习率为0.01
curr_loss, gradients, a_prev = optimize(X, Y, a_prev, parameters)
### END CODE HERE ###
# Use a latency trick to keep the loss smooth. It happens here to accelerate the training.
# 使用延迟来保持损失平滑,这是为了加速训练。
loss = smooth(loss, curr_loss)
# Every 2000 Iteration, generate "n" characters thanks to sample() to check if the model is learning properly
# 每2000次迭代,通过sample()生成“\n”字符,检查模型是否学习正确
if j % 2000 == 0:
print('Iteration: %d, Loss: %f' % (j, loss) + '\n')
# The number of dinosaur names to print
seed = 0
for name in range(dino_names):
# Sample indices and print them # 采样
sampled_indices = sample(parameters, char_to_ix, seed)
print_sample(sampled_indices, ix_to_char)
seed += 1 # To get the same result for grading purposed, increment the seed by one.
# 为了得到相同的效果,随机种子+1
print('\n')
return parameters
运行下面的代码,观察模型在第一次迭代时输出的随机字符。在几千次迭代之后,你的模型应该学会生成合理的名称。
parameters = model(data, ix_to_char, char_to_ix)
运行结果
Iteration: 0, Loss: 23.090632
Nkzxwtdmfqoeyhsqwasjkjvu
Kneb
Kzxwtdmfqoeyhsqwasjkjvu
Neb
Zxwtdmfqoeyhsqwasjkjvu
Eb
Xwtdmfqoeyhsqwasjkjvu
Iteration: 2000, Loss: 27.936742
Livtorapforavgortargherocisaxheandgta
Hidaaertecantisatlus
Hwsisaperievhoroconansabnthyjechaluhamanecdohus
Lda
Xusecigoraverntarcgisablpgylganaluh
Ba
Toranerkcurtos
Iteration: 4000, Loss: 25.926234
Livrosaurus
Hiceagosaurus
Ivtosaurus
Lecagosaurus
Wusocheoraunus
Ca
Tosaurus
Iteration: 6000, Loss: 24.697385
Niwusochisaurus
Indaaeus
Kussperasheuhusiarilitochusulhamaitan
Necaison
Wusmcherncsbrosaurus
Caaetopadouspheptngayalsradus
Trranchojunoscaraphus
Iteration: 8000, Loss: 24.079120
Meutrokelinater
Inca
Iusmlanchuaurus
Macagosaurus
Xusiamapteurus
Acalosaurus
Trodichohultes
Iteration: 10000, Loss: 23.806578
Nivushaleplius
Inecalosaurus
Kustraphor
Necalosaurus
Wurodon
Cabcosaurus
Strepgor
Iteration: 12000, Loss: 23.554363
Livrosaurus
Glecakotha
Hustraomos
Lecalotha
Wurochilolupscraptor
Acalotha
Stranatortatos
Iteration: 14000, Loss: 23.159173
Livosaurus
Hiecaistehanops
Iusspandosaurus
Lecalosaurus
Xusteolosaurus
Baacosaurus
Toraplor
Iteration: 16000, Loss: 23.181400
Nivustanesaurus
Kone
Lustrepeosaurus
Necanssanbloptenosaurus
Xustanisaurus
Eeamus
Trpeomoravetruinangus
Iteration: 18000, Loss: 23.002253
Nitrosaurus
Llecamsthabprosaurus
Lusaurus
Ngabdrta
Xusndrips
Deberte
Trodon
Iteration: 20000, Loss: 22.817971
Lixpsheratopterex
Inecalmus
Ivus
Lecaepton
Xusteodon
Cabbroia
Trocephodus
Iteration: 22000, Loss: 22.669242
Llutosaurus
Huacaltria
Ivustciasbeucorsaurus
Lebacosaurus
Xustenatopteravarcheroceratops
Cabatopdeptitan
Troceplocumstrarhoros
Iteration: 24000, Loss: 22.741355
Mitrosaurus
Inecalosaurus
Iustrimanorushorasaurus
Mhbalosaurus
Yusrangosaurus
Cabdosaurus
Trocenethykosaurus
Iteration: 26000, Loss: 22.770830
Lixosaurus
Ingaagosaurus
Iusosaurus
Leeakosaurus
Xospenasaurus
Ceahosaurus
Ssmangosaurus
Iteration: 28000, Loss: 22.593748
Lovosaurus
Ingbalosaurus
Jusus
Lebadosaurus
Yusmbicinaverateraptor
Cabdromaasoprelius
Trocelchiternochlhitlbisaurus
Iteration: 30000, Loss: 22.489676
Liusklangosaurus
Inga
Iustranchus
Leabaspegansaurus
Xosollasaurus
Caahosaurus
Tosaurus
Iteration: 32000, Loss: 22.487013
Livosaurus
Jidaaitosaurus
Kutrokichomus
Lecanstia
Yutiangosaurus
Cabcosaurus
Trodon
Iteration: 34000, Loss: 22.400439
Llyusaurus
Huga
Ixustengpidus
Lecagosaurus
Yustengropteryx
Cebator
Trodolosaurus
结论
你可以看到,你的算法在训练即将结束时已经开始生成合理的恐龙名称。
一开始,它会生成随机字符,但到最后你会看到恐龙的名字有很酷的结尾。你可以自由地运行算法,甚至更长的时间和发挥超参数,看看你是否可以得到更好的结果。
我们产生了一些非常酷的名字,比如maconucon、marloralus和macingsersaurus。你的模型也很有希望了解到恐龙的名字往往以saurus, don, aura, tor等结尾。
如果你的模型产生了一些不酷的名字,不要完全怪模型——不是所有的恐龙名字听起来都很酷。(例如,dromaeosauroides是一个实际的恐龙名称,并且在训练集中。)但是这个模型应该给你一组候选对象,你可以从中挑选最酷的!
这个任务使用了一个相对较小的数据集,因此可以在CPU上快速地训练RNN。训练英语模型需要更大的数据集,通常需要更多的计算,并且可以在gpu上运行数小时。我们用恐龙这个名字已经有一段时间了,到目前为止,我们最喜欢的名字是伟大的、不可征服的、凶猛的:芒果龙!
4 像莎士比亚那样写作
下面部分是可选的,没有评分,但我们希望你无论如何都这样做,因为它是相当有趣和信息。
类似的(但更复杂的)任务是创作莎士比亚的诗歌。你可以用莎士比亚诗集来代替从恐龙名字的数据集中学习。使用LSTM,你可以了解文本中跨多个字符的长期依赖关系—例如,某个字符出现在某个序列的某个位置可能会影响该序列中稍后应该是另一个字符的内容。这些长期的依赖关系对于恐龙的名字来说不太重要,因为它们的名字很短。

我们用Keras实现了一个莎士比亚诗歌生成器。运行以下代码以加载所需的包和模型。这可能需要几分钟。
from __future__ import print_function
from keras.callbacks import LambdaCallback
from keras.models import Model, load_model, Sequential
from keras.layers import Dense, Activation, Dropout, Input, Masking
from keras.layers import LSTM
from keras.utils.data_utils import get_file
from keras.preprocessing.sequence import pad_sequences
from shakespeare_utils import *
import sys
import io
运行一下
Using TensorFlow backend.
Loading text data...
Creating training set...
number of training examples: 31412
Vectorizing training set...
Loading model...
2021-01-03 11:25:15.840663: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
C:\Users\toddc\Anaconda3\envs\tensorflow\lib\site-packages\keras\engine\saving.py:384: UserWarning: Error in loading the saved optimizer state. As a result, your model is starting with a freshly initialized optimizer.
warnings.warn('Error in loading the saved optimizer '
为了节省你的时间,我们已经为莎士比亚诗集《十四行诗》训练了一个1000个epochs的模型。
让我们再训练一次模型。当它完成一个epoch的训练时——这也需要几分钟——你可以运行generate_output,它会提示你输入(<40个字符)。这首诗将从你的句子开始,我们的RNN-Shakespeare将为你完成这首诗的其余部分!例如,尝试“Forsooth this maketh no sense”(不要输入引号)。根据是否在末尾包含空格,结果可能也会有所不同——两种方法都可以尝试,其他输入也可以尝试。
运行
print_callback = LambdaCallback(on_epoch_end=on_epoch_end)
model.fit(x, y, batch_size=128, epochs=1, callbacks=[print_callback])
结果
Epoch 1/1
31412/31412 [==============================] - 69s 2ms/step - loss: 2.7093
运行下面的代码尝试不同的输入,不需要重新训练
# Run this cell to try with different inputs without having to re-train the model
generate_output()
输入:lemon,结果
Write the beginning of your poem, the Shakespeare machine will complete it. Your input is: lemon
Here is your poem:
lemone,
which you beaution leaste my lackes wat is dond?
i se porture that heaving all my hay,
wor that thou lovsefles midar lavesed wo do,
thy self to bistulr of my sand commend,
who worling cime aud diest digh in my days,
from my do mesich of all behurte and ever:
torens to sumfuat no forgues thy love, and coums in his sain,
boto in the warly not wo whet,
your mady i have swill a such place would,
RNN-Shakespeare和你为恐龙取名字构建的模型非常相似。
不同的地方是
- 用LSTMs代替基本的RNN来捕获更大范围的依赖关系
- 该模型是一个更深层的LSTM模型(2层)。
- 使用keras而不是Python来简化代码
如果你想了解更多,还可以在GitHub上查看Keras团队的文本生成实现。