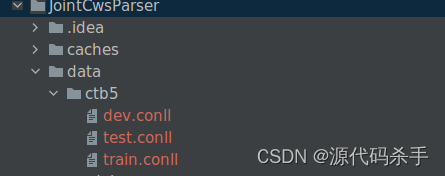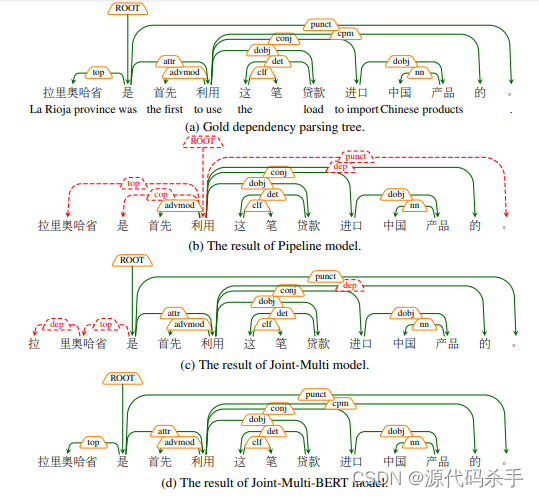
论文摘要:中文分词和依存解析是中文自然语言处理的两个基本任务。依赖解析是在单词级别定义的。因此分词是依赖解析的前提条件,这使得依赖解析遭受错误传播,无法直接利用字符级预训练的语言模型(如BERT)。在本文中,我们提出了一种基于图的模型来集成中文分词和依赖解析。与以前基于转换的联合模型不同,我们提出的模型更简洁,从而减少了特征工程的工作量。我们的基于图的联合模型比以前的联合模型具有更好的性能,并且在中文分词和依赖解析方面取得了最先进的结果。此外,当结合BERT时,我们的模型可以大大减少联合模型和基于词的黄金分割模型之间依赖解析的性能差距。
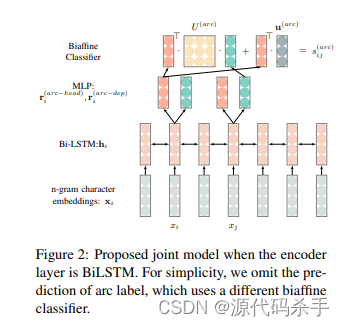
论文:A Graph-based Model for Joint Chinese Word Segmentation and Dependency Parsing
源码地址:https://github.com/KangChou/JointCwsParser
训练CTB5数据集下载地址:https://download.csdn.net/download/weixin_41194129/85448924?spm=1001.2014.3001.5503
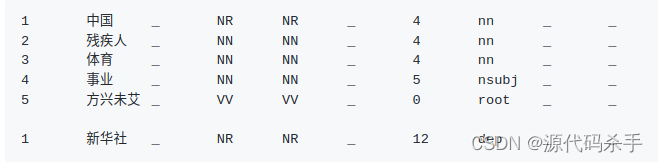
数据存放路径: