K-Net:《K-Net: Towards Unified Image Segmentation》
发布于2021 。

论文地址:K-Net: Towards Unified Image Segmentation
本文将包含以下内容:
- K-Net实现原理。
- 动态内核如何实现。
- K-Net如何应用于语义分割。
- K-Net如何实现NMS-Free与Box-Free的实例分割。
- K-Net如何实现全景分割。
前言
语义分割、实例分割和全景分割存在着潜在的链接,但现有的分割方法往往将其割裂开来,譬如最经典的FCN用于语义分割,而在实例分割中,Mask-RCNN则是较为经典的网络。而全景分割则是语义和实例两者的结合,要求在分割实例的情况下提供更全面的场景理解。
-
语义(Semantic)分割模型可以直接根据图像像素进行分组,转换为密集的分类问题,如FCN中,根据分类类别来学习一组卷积核来将像素进行分类,即可简单而优雅地完成语义分割任务,而以后的众多语义分割方法均基于FCN,无论是DeepLab系列的扩展卷积和ASPP,还是PSPNet,以及Non-Local(Self-Attention)形式的多数网络。
-
但是,考虑到图像之间的不同实例,将语义分割扩展到实例(Instance)分割是很不错的思路。当然,实例分割需要更加复杂的模型构成和后处理机制,诸如NMS和Box。实例分割一般可分为两个传统框架,“自上而下” 和 “自下而上”。自上而下的框架是先计算实例的检测框,在检测框内进行分割;相反,自下而上的框架则是先进行语义分割,在分割结果上对实例对象进行检测。直觉上而言,自上而下的方法会相对更为准确,事实上结果也如此。如经典的实例分割网络Mask-RCNN即采用自上而下的方法,在Faster R-CNN中加上了一个FCN语义分割模块。当然,现在涌现出了更多的实例分割方法,包括一阶段的YoloAct、BlendMask、EmbedMask等;还有一些更加骚的操作,基于Contour的PolarMask还有发在2022CVPR的E2EC;以及基于Transformer的Query-based的QueryInst、SOLQ、Mask2Former等。
-
全景(Panoptic)分割结合了实例和语义分割,以提供对场景的更丰富的理解。主流框架在实例分割框架上添加语义分割分支,或基于语义分割方法采用不同的像素分组策略。
-
Dynamic Kernel:卷积核通常是静态的,但由于输入是不可知的(即输入往往与训练数据有差异),因此模型的效果十分受限。在一些工作中,如Dynamic filter networks、Deformable convolutional networks(DCN)的可变形卷积等等,通过核的动态变形来提高模型的灵活性和性能。一些语义分割方法也应用动态内核来通过扩大的接收场(LS-DFN)或多尺度上下文(DMNet)来改善模型表示。
-
K-Net:针对以上三个任务,K-Net提出了一种基于动态内核的分割模型,为每个任务分配不同的核来实现多任务统一(图1)。
原文中有如下表述:Instead of generated from dense grids, the kernels in K-Net are a set of learnable parameters updated by their corresponding contents in the image. K-Net does not need to handle duplicated kernels because its kernels learn to focus on different regions of the image in training, constrained by the bipartite matching strategy that builds a one-to-one mapping between the kernels and instances.
翻译一下就是:K-Net的kernels是一组科学系的参数,根据图像对应的内容动态更新。同时,K-NET不需要处理重复的内核,因为其内核学会专注于图像的不同区域,受到双方匹配的约束策略,该策略在内核和实例之间建立了一对一的映射。

K-Net
K-Net的本质
对于所有细分的分割任务,其内核都是对有意义的像素进行分组,譬如语义分割,将不同的类别像素分组。理论上而言,分割任务的分组是有上限的,因此,可以把分组数量认为设置为N ,比如,有N个用于语义分割的预定义语义类或图像中最多有N个实例对象,对于全景分割,N是图像中的stuff类和Instance类的总数。
那么,可以使用N个Kernel将图像将图像划分为N组,每个Kernel都负责找到属于其相应组的像素(也就是先前讲的,Kernel与Content实现一对一映射)。具体而言,给定由深神经网络产生的B图像的输入特征映射 F ∈ R B × C × H × W F∈R^{B×C×H×W} F∈RB×C×H×W,我们只需要N个kernels K ∈ R N × C K∈R^{N×C} K∈RN×C即可用F执行卷积以获得相应的的预测结果 M ∈ R B × N × H × W M∈ R^{B×N×H×W} M∈RB×N×H×W。
M = σ ( K ∗ F ) M = \sigma(K*F) M=σ(K∗F)
使用 σ \sigma σ对结果进行激活,设置对应阈值后即可得到N个二进制掩码Mask(这也是语义分割长期以来的基本思想 (图1-a)。
但是,为了实现实例分割,需要对每一个Kernel进行限制,也就是每个Kernel最多只能处理图像中一个对象(图1-b),通过这种方式,K-NET可以区分实例并同时执行分割,从而在一个特征映射中实现实例分割,而无需额外的步骤(实现了NMS-Free和Box-Free)。
为简单起见,我们可以将这些内核称为本文中的语义内核和实例内核,分别用于语义和实例分割。
实例内核和语义内核的简单组合即可实现全景分割,该分割将像素分配给实例对象或一类东西 (图1-c)。
Group-Aware Kernels
虽然使用Kernel来区分语义类别是十分简单的,但是要区分实例对象就显得比较困难。因为实例内核需要区分图像内部和跨图像内外部的对象。不像语义类别具有共同和明确的特征,实例内核需要拥有比语义内核更强的判别能力。
因此作者这里提出了一个Kernel Update策略,来使每一个内核对应一个像素组。
Kernel Update Head f i f_{i} fi包含三个关键步骤:group feature assembling、adaptive kernel update 和 kernel interaction。
- group feature assembling:首先,通过Mask M i − 1 M_{i-1} Mi−1来计算聚合出一个组特征映射 F K F^{K} FK。其中,每一个组group都对应着一个语义类\实例对象。
- adaptive kernel update: 这个 F K F^{K} FK内的每一个组都将会被用来更新内核 K i − 1 K_{i-1} Ki−1 。
- kernel interaction:随后,这些内核 K i − 1 K_{i-1} Ki−1进行交互,互相能够提供上下文信息以对全局特征图进行建模,获得新的内核 K i K_{i} Ki 。
- 最后,使用 K i K_{i} Ki对特征图F进行卷积,得到预测结果更加精确的Mask M i M_{i} Mi 。
- 用公式表达就是:
K i , M i = f i ( M ( i − 1 ) , K ( i − 1 ) , F ) K_i, M_i = f_i(M_{(i-1)},K_{(i-1)}, F) Ki,Mi=fi(M(i−1),K(i−1),F)

可以细看一下Kernel Update Head中的三个步骤。
Group Feature Assembling
Kernel Update Head首先聚合每个group的特征,随后使用这些特征来实现核的group-aware,也就是每一个核能够对特征图正确感知。由于 M i − 1 M_{i-1} Mi−1中每个内核的掩码本质上定义了像素是否属于该内核的相关组,可以通过将特征映射 F F F乘 M i − 1 M_{i-1} Mi−1作为新的组装特征 F K F^K FK:
F K = ∑ u H ∑ v W M ( i − 1 ) ( u , v ) ⋅ F ( u , v ) , F K ∈ R B × N × C F^K = \sum_{u}^H\sum_{v}^W M_{(i-1)}(u,v) \cdot F(u,v), F^K\in R^{B×N×C} FK=u∑Hv∑WM(i−1)(u,v)⋅F(u,v),FK∈RB×N×C
Adaptive Feature Update
经过Group Feature Assembling之后,我们可以使用 F K F^K FK计算得到一组新的Kernels。但作者考虑到mask M i − 1 M_{i-1} Mi−1可能不够准确,可能包含了其他组被误分类进来的噪音,因此设计了一个自适应的内核更新策略,首先在 F K F^K FK和 K i − 1 K_{i-1} Ki−1之间执行元素乘法( ϕ 1 \phi_1 ϕ1、 ϕ 2 \phi_2 ϕ2为线性变换):
F G = ϕ 1 ( F K ) ⊗ ϕ 2 K i − 1 , F G ∈ R B × N × C F^G = \phi_1 (F^K) \otimes\phi_2 K_{i-1}, F^G \in R^{B×N×C} FG=ϕ1(FK)⊗ϕ2Ki−1,FG∈RB×N×C
随后,计算两个门控gates, G F G^F GF和 G K G^K GK:
G K = σ ( Φ 1 ( F G ) ) 、 G F = σ ( Φ 2 ( F G ) ) G^K =\sigma(\Phi_1 (F^G)) 、 G^F=\sigma(\Phi_2 (F^G)) GK=σ(Φ1(FG))、GF=σ(Φ2(FG))
再由这两个gates计算出一组新的kernels K ~ \tilde{K} K~
K ~ = G F ⊗ Φ 3 ( F K ) + G K ⊗ Φ 4 ( K i − 1 ) \tilde{K} = G^F \otimes \Phi_3 (F^K) +G^K\otimes\Phi_4 (K_{i-1}) K~=GF⊗Φ3(FK)+GK⊗Φ4(Ki−1)
其中, Φ n \Phi_n Φn函数均为Fully connected layers(全连接层)+ Layer Norm(层归一化)。计算结果 K ~ \tilde{K} K~则将用于Kernel Interaction中。
在这里作者提到,计算出来的两个gate, G F G^F GF和 G K G^K GK,可以看做是Transformer中的self-attention机制,本质上是计算一个权重对特征 F K F^K FK和核 K i − 1 K_{i-1} Ki−1做一个加权求和,当然,公式中所表达的含义也是如此,无非是对一些噪声信息做加权罢了。
Kernel Interaction
Kernel Interaction可以使不同的kernel之间互相信息流通,也就是能够提供上下文信息,这些信息允许kernel隐式利用图像group之间的关系。为了从上诉计算出来的 K ~ \tilde{K} K~中计算出一组新的kernels K i K_i Ki,作者这里采用了Multi-Head Self-Attention+Feed-Forward Neural Network的形式。也就是用 M S A − M L P MSA-MLP MSA−MLP的形式来输出一组新的 K i K_i Ki(其实这里有点类似于Transformer结构)。 K i K_i Ki将用来计算新的Mask: M i = g i ( K i ) ∗ F M_i=g_i(K_i)*F Mi=gi(Ki)∗F, 这里的 g i g_i gi 为 F C − L N − R e L U FC-LN-ReLU FC−LN−ReLU操作。
## K-Net用于分割 ### 训练Instance Kernels的一些细节 1. 这一部分的损失函数选择了Dice Loss,原因是局部细节使用交叉熵的话容易导致不平衡问题。 2. 使用匈牙利算法(Mask-based Hungarian Assignment)来处理Mask配对问题。
全景分割
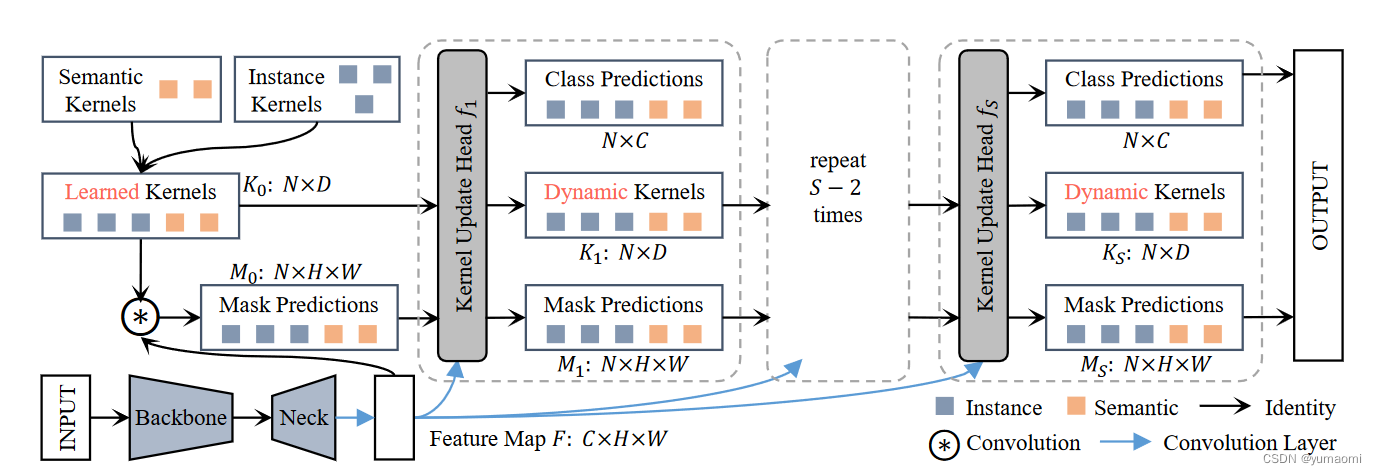
介绍完Kernel Update Head之后,K-Net的结构就比较简单了。通过一个BackBone和Neck(作者这里使用了FPN)来生成一组特征图F。由于语义分割和实例分割所要求的特征图有所差异,所以作者通过两个独立的卷积分支对F进行处理生成 F i n s F^{ins} Fins和 F s e g F^{seg} Fseg,当然,这里使用的卷积核为初始化的 K 0 i n s K_0^{ins} K0ins和 K 0 s e g K_0^{seg} K0seg,这样就生成了一组新的Mask: M 0 i n s M_0^{ins} M0ins、 M 0 s e g M_0^{seg} M0seg。
由于 M 0 s e g M_0^{seg} M0seg中自然而然的包括了全景分割中所需求的"things"和"stuff"(只不过没有区分实例),那么只需要从 M 0 s e g M_0^{seg} M0seg中将包含"stuff"的部分提取出来,再和 M 0 i n s M_0^{ins} M0ins(区分实例)直接进行通道相加,即可得到全景分割所需要的Mask: M 0 M_0 M0。同理,对于卷积核Kernel,也只需要提取对应的 K 0 i n s K_0^{ins} K0ins和 K 0 s e g K_0^{seg} K0seg组合成新的 K 0 K_0 K0。而对于特征图F,将 F i n s F^{ins} Fins和 F s e g F^{seg} Fseg简单通道相加即可(毕竟信息越多越好)。对于新得到的 K 0 K_0 K0、 M 0 M_0 M0和F,经过S次Kernel Update Head处理,可以得到最终的Output: M S M_S MS。
实例分割
与上述全景分割类似,在实例分割中,只需要删除内核和掩模的串联过程即可执行实例分割。在这一步并不需要删除语义分割分支,因为语义信息仍然是互补的(还是遵循信息越多越好的原则,毕竟实例信息可以从语义信息中提取)。不过,需要注意的是,在这种情况下,语义分割分支不使用额外的真实标签。语义结果的标签是通过将实例掩码转换为相应的类标签来构建的(这里其实在一定程度上起了一个监督的作用,也就是使用语义分支来监督实例分支)。
语义分割
对于语义分割的流程而言,结构是最为简单的,只需要简单地将Kernel Update Head附加到任何依赖语义内核的语义分割方法中即可执行语义分割,比如ASPP、UperNet、FCN、PPM均可。
总结
本文介绍了:
- K-Net的实现原理。
- K-Net如何根据不同的语义信息更新核Kernels。
- K-Net如何应用于语义分割、实例分割、全景分割。
除此之外,K-Net的实现代码可以参考mmcv官方的mmsegmentation和mmdetection,分别可实现语义分割和实例/全景分割。当然作者也给出了他的代码仓库,不过还得配合mmcv食用,K-Net代码链接。