传统的可变形配准需要大量的计算时间,基于学习的配准方法可以减少训练时间但是需要标签值(比较少)或者没有保证微分同胚特性。本文提出一个概率生成模型并推导一个基于无监督学习的推理算法,不仅保证了微分同胚特性,还提供了不确定估计。
1.简介
可变形配准计算出两幅图像间的密集对应关系,是许多医疗图像分析任务的基础。传统的方法解决空间形变的优化问题,例如:弹性模型、B样条、密集矢量场和离散方法(discrete methods)。将变形限制为微分同胚会保留某些理想的特性,已经有比较成熟的方法实现微分同胚(LDDMM,DARTEL,SyN等),但是这些方法需要大量时间与资源来运行。有些方法训练神经网络将输入图像对映射输出一个变形场,这通常需要标准图像(从更传统的配准方法获取),由此引入偏差,所以需要更合理的预处理方法。此前的一些文章探索空间形变网络的无监督变换策略仅仅在仿射变换和小位移场上,并且只在3D补丁和2D切片上进行验证。
本文提出了一个配准公式推导概率生成模型的变分形式。使用的是带有直接代价函数的卷积神经网络,并且使用微分同胚层与变换层实现了端到端的微分同胚配准。可以实现较为理想的配准,同时保持微分特性,减少了运行时间并且估计了配准的不确定性。
1.1微分同胚配准
微分同胚变换时可微和可逆的,因此保持了拓扑特性。形变场定义为常微分方程: ∂ ϕ ( t ) ∂ t = v ( ϕ ( t ) ) \frac{\partial\phi^{(t)}}{\partial{t}}=\mathcal{v}(\phi^{(t)}) ∂t∂ϕ(t)=v(ϕ(t)),其中 ϕ ( 0 ) = I d \phi^{(0)}=\mathit{I}\mathcal{d} ϕ(0)=Id 是恒等变换(ODE),t 是时间,对静止速度场 v \mathcal{v} v在 t = [0, 1] 上积分获得最终配准场 ϕ ( t ) \phi^{(t)} ϕ(t) 。使用缩放和平方计算积分,平稳的ODE表示微分同胚的单参数子集,在群论中, v \mathcal{v} v是李代数的一员,求幂得到 ϕ ( 1 ) \phi^{(1)} ϕ(1), ϕ ( 1 ) \phi^{(1)} ϕ(1)是李群: ϕ ( 1 ) = e v \phi^{(1)}=e^{\mathcal{v}} ϕ(1)=ev,(李代数是李群的正切空间) 由子单参数子空间的性质可知,对于标量 t t t和 t ′ t' t′, e ( t + t ′ ) v = e t v ∘ e t ′ v e^{\mathcal{(t+t')v}}=e^{\mathcal{tv}}\circ{e^{\mathcal{t'v}}} e(t+t′)v=etv∘et′v,其中 ∘ \circ ∘表示与李群相关的组成图(composition map )。 ϕ ( 1 / 2 T ) = p + v ( p ) \phi^{(1/2^{T})}=\mathcal{p}+\mathcal{v(p)} ϕ(1/2T)=p+v(p),其中 p \mathcal{p} p是空间位置图,循环计算 ϕ ( 1 / 2 t − 1 ) = ϕ ( 1 / 2 t ) ∘ ϕ ( 1 / 2 t ) \phi^{(1/2^{t-1})}=\phi^{(1/2^{t})}\circ\phi^{(1/2^{t})} ϕ(1/2t−1)=ϕ(1/2t)∘ϕ(1/2t)可以求得 ϕ 1 = ϕ ( 1 / 2 ) ∘ ϕ ( 1 / 2 ) \phi^{1}=\phi^{(1/2)}\circ\phi^{(1/2)} ϕ1=ϕ(1/2)∘ϕ(1/2),选择合适的T可以使 v ≈ 0 \mathcal{v} \approx 0 v≈0。
2.方法
提出了一种变分推理方法,使用卷积神经网络、微分同胚积分和空间变换层实现。在实现微分同胚的同时提供了不确定性估计。
2.1生成模型
假设 x \mathcal{x} x, y \mathcal{y} y分别表示两幅MRI图像, z \mathcal{z} z表示变换函数的隐变量,关于 z \mathcal{z} z的先验概率是: p ( z ) = N ( z ; 0 , Σ z ) \mathcal{p}(\mathcal{z})=\mathcal{N}(\mathcal{z};0,\mathcal{\Sigma_{\mathcal{z}}}) p(z)=N(z;0,Σz)其中, N ( ⋅ ; μ , Σ ) \mathcal{N}(\cdot;\mu,\mathcal{\Sigma}) N(⋅;μ,Σ)服从多元正态分布且 ∼ ( μ , Σ ) \sim(\mu,\Sigma) ∼(μ,Σ), z \mathcal{z} z有很宽泛的表示范围,既可以表示密集位移场的低维嵌入,也可以表示位移场本身。在此, z \mathcal{z} z代表静态速度场,它通过ODE指定一个微分同胚映射,取 L = D − A \mathit{L=D-A} L=D−A表示在体素网格上定义的邻域图的拉普拉斯算子,其中 D \mathit{D} D表示图的度矩阵(度矩阵是对角阵,对角上的元素为各个顶点的度。)
A \mathit{A} A表示体素相邻矩阵。使用 Σ z − 1 = Λ z = λ L \Sigma_{\mathcal{z}}^{-1}=\Lambda_{\mathcal{z}}=\lambda\mathit{L} Σz−1=Λz=λL,对 z \mathcal{z} z进行空间平滑,其中 Λ z \Lambda_{\mathcal{z}} Λz是精密矩阵 λ \lambda λ控制速度场 z \mathcal{z} z的尺度。
让 x \mathcal{x} x是扭曲图像 y \mathcal{y} y的噪声观测: p ( x ∣ z ; y ) = N ( x ; y ∘ ϕ z , σ 2 Ⅱ ) \mathcal{p(x|z;y)}=\mathcal{N}(\mathcal{x;y\circ\phi_{z}},\sigma^{2}Ⅱ) p(x∣z;y)=N(x;y∘ϕz,σ2Ⅱ)
其中, σ 2 \sigma^2 σ2表示图像加性噪声的方差。
目标是估计后验配准概率 p ( z ∣ x ; y ) \mathit{p(z|x;y)} p(z∣x;y),通过MAP估计(最大后验概率)获得新图像对 ( x , y ) (\mathit{x,y}) (x,y)的最可能的配准场 ϕ z \phi_{\mathit{z}} ϕz,以及配准的不确定性估计。
2.2学习
使用变分方法,引入近似后验概率 q ψ ( z ∣ x ; y ) \mathit{q_{\psi}(z|x;y)} qψ(z∣x;y),使用 ψ \psi ψ进行参数化,通过最小化KL散度(变分下界的相反数,相对熵)
m i n ψ K L [ q ψ ( z ∣ x ; y ∣ ∣ p ( z ∣ x ; y ) ) ] = m i n ψ E q [ log q ψ ( z ∣ x ; y ) − log p ( z ∣ x ; y ) ] = m i n ψ E q [ log q ψ ( z ∣ x ; y ) − log p ( z , x , y ) ] + log p ( x ; y ) = m i n ψ K L [ q ψ ( z ∣ x ; y ) ∣ ∣ p ( z ) − E q [ log p ( x ∣ z ; y ) ] min_{\psi}KL[q_{\psi}(\mathcal{z|x;y||p(z|x;y)})]\\ =min_{\psi}\mathbf{E}_{q}[\log\mathcal{q_{\psi}(z|x;y)}-\log\mathcal{p(z|x;y)}]\\ =min_{\psi}\mathbf{E}_{q}[\log\mathcal{q_{\psi}(z|x;y)}-\log\mathcal{p(z,x,y)}]+\log\mathcal{p(x;y)}\\ =min_{\psi}KL[\mathcal{q_{\psi}(z|x;y)||p(z)}-\mathbf{E}_{q}[\log\mathcal{p(x|z;y)}] minψKL[qψ(z∣x;y∣∣p(z∣x;y))]=minψEq[logqψ(z∣x;y)−logp(z∣x;y)]=minψEq[logqψ(z∣x;y)−logp(z,x,y)]+logp(x;y)=minψKL[qψ(z∣x;y)∣∣p(z)−Eq[logp(x∣z;y)]
( \big( (可能是水平原因我没看懂这个公式的第三步,下面我描述一下我的理解,后验概率公式: p ( x ) p ( ω ∣ x ) = p ( ω ) p ( x ∣ ω ) p(x)p(\omega|x)=p(\omega)p(x|\omega) p(x)p(ω∣x)=p(ω)p(x∣ω),其中 p ( x ) p(x) p(x)是已知的全概率, p ( ω ) p(\omega) p(ω)是先验概率, p ( ω ∣ x ) p(\omega|x) p(ω∣x)为后验概率, p ( x ∣ ω ) p(x|\omega) p(x∣ω)为类概率密度(顾名思义,就是某一类的概率),带入本公式得: p ( z ∣ x ; y ) = p ( z ) p ( x ∣ z ; y ) p ( x ) , y \mathcal{p(z|x;y)=\frac{p(z)p(x|z;y)}{p(x)}},y p(z∣x;y)=p(x)p(z)p(x∣z;y),y为浮动图像, x x x为固定图像,所以 p ( x ) p(x) p(x)已知为常数省略了。所以我修改上式如下:
m i n ψ K L [ q ψ ( z ∣ x ; y ∣ ∣ p ( z ∣ x ; y ) ) ] = m i n ψ E q [ log q ψ ( z ∣ x ; y ) − log p ( z ∣ x ; y ) ] = m i n ψ E q { log q ψ ( z ∣ x ; y ) − log [ p ( z ) p ( x ∣ z ; y ) ] } = m i n ψ E q [ log q ψ ( z ∣ x ; y ) − log p ( z ) − log p ( x ∣ z ; y ) ] = m i n ψ E q [ log q ψ ( z ∣ x ; y ) − log p ( z ) ] − m i n ψ E q [ log p ( x ∣ z ; y ) ] = m i n ψ K L [ q ψ ( z ∣ x ; y ) ∣ ∣ p ( z ) − E q [ log p ( x ∣ z ; y ) ] min_{\psi}KL[q_{\psi}(\mathcal{z|x;y||p(z|x;y)})]\\ =min_{\psi}\mathbf{E}_{q}[\log\mathcal{q_{\psi}(z|x;y)}-\log\mathcal{p(z|x;y)}]\\ =min_{\psi}\mathbf{E}_{q}\{\log\mathcal{q_{\psi}(z|x;y)}-\log\mathcal{[p(z)p(x|z;y)]}\} \\ =min_{\psi}\mathbf{E}_{q}[\log\mathcal{q_{\psi}(z|x;y)}-\log\mathcal{p(z)}-\log\mathcal{p(x|z;y)}] \\ =min_{\psi}\mathbf{E}_{q}[\log\mathcal{q_{\psi}(z|x;y)}-\log\mathcal{p(z)}]-min_{\psi}\mathbf{E}_{q}[\log\mathcal{p(x|z;y)}]\\ =min_{\psi}KL[\mathcal{q_{\psi}(z|x;y)||p(z)}-\mathbf{E}_{q}[\log\mathcal{p(x|z;y)}] minψKL[qψ(z∣x;y∣∣p(z∣x;y))]=minψEq[logqψ(z∣x;y)−logp(z∣x;y)]=minψEq{
logqψ(z∣x;y)−log[p(z)p(x∣z;y)]}=minψEq[logqψ(z∣x;y)−logp(z)−logp(x∣z;y)]=minψEq[logqψ(z∣x;y)−logp(z)]−minψEq[logp(x∣z;y)]=minψKL[qψ(z∣x;y)∣∣p(z)−Eq[logp(x∣z;y)]
由 K L \mathbf{KL} KL散度公式我认为 E q \mathbf{E}_{q} Eq应该写成 ∑ q ( z ∣ x ; y ) \sum\mathcal{q(z|x;y)} ∑q(z∣x;y),但是上述公式也并未修改 ) \big) )
将后验建模为多元正态, q ψ ( z ∣ x ; y ) = N ( z ; μ z ∣ x , y , Σ z ∣ x , y ) \mathcal{q_{\psi}(z|x;y)}=\mathcal{N}(\mathcal{z;\mu_{z|x,y},\Sigma_{z|x,y}}) qψ(z∣x;y)=N(z;μz∣x,y,Σz∣x,y),其中 Σ z ∣ x , y \Sigma_{z|x,y} Σz∣x,y是对角矩阵。
使用参数为 ψ \psi ψ的卷积神经网络 d e f ψ ( x , y ) def_{\psi(x,y)} defψ(x,y)来估计 μ z ∣ x ; y \mu_{\mathcal{z|x;y}} μz∣x;y和 Σ z ∣ x ; y \Sigma_{\mathcal{z|x;y}} Σz∣x;y,使用随机梯度法优化变分下界,来学习参数 ψ \psi ψ。
对于输入图像对 ( x , y ) \mathcal{(x,y)} (x,y)和样例 z k ∼ q ψ ( z ∣ x ; y ) \mathcal{z_{k}\sim q_{\psi}(z|x;y)} zk∼qψ(z∣x;y),可以用以下损失函数计算 y ∘ ϕ z k y\circ \phi_{\mathcal{zk}} y∘ϕzk:
L ( ψ , x , y ) = − E q [ log p ( x ∣ z ; y ) ] + K L [ q ψ ( z ∣ x ; y ) ∣ ∣ p ( z ) ] = 1 2 δ 2 K ∑ k ∣ ∣ x − y ∘ ϕ z k ∣ ∣ 2 + 1 2 [ t r ( λ D Σ z ∣ x ; y − log ∣ Σ z ∣ x ; y ∣ ) + μ z ∣ x ; y T Λ z μ z ∣ x ; y ] + c o n s t \mathcal{L(\psi,x,y)}=-\mathbf{E}_{q}[\log\mathcal{p(x|z;y)}]+KL[\mathcal{q_{\psi}(z|x;y)||p(z)}]\\ =\frac{1}{2\delta^2K}\sum_{k}||x-y\circ \phi_{zk}||^2+\frac{1}{2}[tr(\lambda D\Sigma_{z|x;y}-\log|\Sigma_{z|x;y}|)+\mu^T_{z|x;y}\Lambda_z\mu_{z|x;y}]+const L(ψ,x,y)=−Eq[logp(x∣z;y)]+KL[qψ(z∣x;y)∣∣p(z)]=2δ2K1k∑∣∣x−y∘ϕzk∣∣2+21[tr(λDΣz∣x;y−log∣Σz∣x;y∣)+μz∣x;yTΛzμz∣x;y]+const
其中,分母上的K表示使用样本的数目,本实验只有一个样本(固定图像?)K=1,第一个平方项表示希望扭曲图像与 x x x相似;第二项表示希望后验概率尽可能的接近先验概率 p ( z ) p(z) p(z),变分协方差 log Σ z ∣ x ; y \log\Sigma_{z|x;y} logΣz∣x;y为对角阵;第三项为空间平滑均值 μ z ∣ x ; y T Λ z μ z ∣ x ; y = λ 2 ∑ ∑ j ∈ N ( I ) ( μ [ i ] − μ [ j ] ) 2 , N ( I ) \mu^T_{z|x;y}\Lambda_z\mu_{z|x;y}=\frac{\lambda}{2}\sum\sum_{j\in N(I)}(\mu[i]-\mu[j])^2,N(I) μz∣x;yTΛzμz∣x;y=2λ∑∑j∈N(I)(μ[i]−μ[j])2,N(I)表示体素 i i i的邻域体素;最后一项是常量,将 δ 2 \delta^2 δ2与 λ \lambda λ设置为固定超参数(待训练)。
2.3神经网络框架
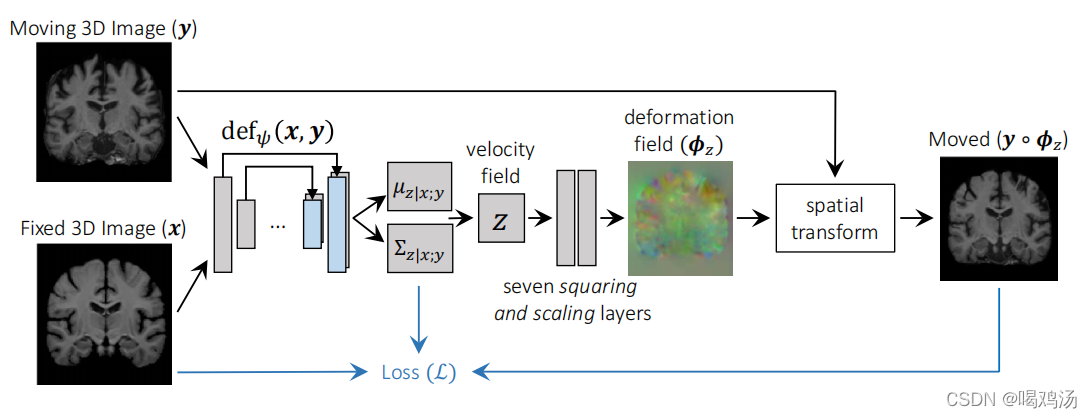
设计了3D-Uet类型的网络框架(如上图),输入 ( x , y ) (x,y) (x,y)输出 μ z ∣ x ; y \mu_{z|x;y} μz∣x;y(期望)和 Σ z ∣ x ; y \Sigma_{z|x;y} Σz∣x;y(方差)。由四层U-Net构成,(具体结构可见)每层卷积层(3×3的卷积核)后加入LeakyReLu激活函数。
为了实现无监督的 L ( ψ , x , y ) \mathcal{L(\psi,x,y)} L(ψ,x,y),必须保证形成 y ∘ ϕ z y\circ \phi_z y∘ϕz,使用了一个通过重参数化技巧来采样一个新的 z k ∼ N ( μ z ∣ x ; y , Σ z ∣ x ; y ) z_k\sim \mathcal{N}(\mu_{z|x;y},\Sigma_{z|x;y}) zk∼N(μz∣x;y,Σz∣x;y)。
本文提出了一个新的缩放和平方(缩小和扩张UNet的特点)的网络层计算空间变化 ϕ z k = e z k \phi_{zk}=e^{z_k} ϕzk=ezk。给定两个三维矢量场 ( a , b ) (a,b) (a,b),对每个体素p,使用线性插值法计算 ( a ∘ b ) ( p ) = a ( b ( p ) ) (a\circ b)(p)=a(b(p)) (a∘b)(p)=a(b(p)), a a a中非整数体素的坐标 b ( p ) b(p) b(p)。(这里有没有懂的,在评论区交流一下)
首先 v ( 1 / 2 T ) = z k v^{(1/{2^T})}=z_k v(1/2T)=zk,递归的使用网络层计算 ϕ ( 1 / 2 t − 1 ) = ϕ ( 1 / 2 t ) ∘ ϕ ( 1 / 2 t ) \phi^{(1/2^{t-1})}=\phi^{(1/2^{t})}\circ\phi^{(1/2^{t})} ϕ(1/2t−1)=ϕ(1/2t)∘ϕ(1/2t)(原文这里是+,但对比上文我觉得是-),最后得出 v ( 1 ) ≜ ϕ z k = e z k v^{(1)} \triangleq\phi_{z_k}=e^{z_k} v(1)≜ϕzk=ezk,使用T=7,输入图像尺寸为128( 2 7 2^7 27),最后通过空间变换层使用计算得到的微分同胚形变场 ϕ z k \phi_{z_k} ϕzk扭曲浮动图像。最后会得到三个输出 μ z ∣ x ; y , Σ z ∣ x ; y , y ∘ ϕ z k \mu_{z|x;y},\Sigma_{z|x;y},y\circ\phi_{z_k} μz∣x;y,Σz∣x;y,y∘ϕzk。
本框架的每一步都是可微的,使用随机梯度下降的方法计算网络参数。
2.4配准和不确定性
目的是使用学习到的参数,使 ( x , y ) (x,y) (x,y)两个输入接近。
首先通过在两个输入图像上评估神经网络 d e f ψ ( x , y ) def_\psi(x,y) defψ(x,y),使用下式获得 z ^ k \hat z_k z^k, z ^ k = a r g m a x z k p ( z k ∣ x ; y ) = μ z ∣ x : y \hat z_k=arg{max_{z_{k}}}p(z_k|x;y)=\mu_{z|x:y} z^k=argmaxzkp(zk∣x;y)=μz∣x:y
然后使用缩放和平方网络计算 ϕ z ^ k \phi_{\hat z_{k}} ϕz^k。同时获得 Σ z ∣ x ; y \Sigma_{z|x;y} Σz∣x;y估计每个体素j上的速度场z的不确定性: H ( z [ j ] ) ≈ E [ − log q ψ ( z ∣ x ; y ) ] = 1 2 log 2 π Σ z ∣ x ; y [ j , j ] H(z[j])\approx \mathbf{E}[-\log q_{\psi}(z|x;y)]=\frac{1}{2}\log 2\pi\Sigma_{z|x;y}[j,j] H(z[j])≈E[−logqψ(z∣x;y)]=21log2πΣz∣x;y[j,j]
同时还估计形变场 ϕ z \phi_z ϕz的不确定性,采样一些代表 z k ′ ∼ q ψ ( z ∣ x ; y ) z_{k'}\sim q_{\psi}(z|x;y) zk′∼qψ(z∣x;y),经微分同胚层传播计算 ϕ z k ′ \phi_{z_{k'}} ϕzk′,计算样本间的对角协方差 Σ ^ ϕ z [ j , j ] \hat\Sigma_{\phi_z}[j,j] Σ^ϕz[j,j],所以不确定性为:
H ( ϕ [ j ] ) ≈ 1 2 log 2 π Σ ^ ϕ z [ j , j ] H(\phi[j])\approx \frac{1}{2} \log2\pi \hat\Sigma_{\phi_z}[j,j] H(ϕ[j])≈21log2πΣ^ϕz[j,j]
实验
本实验在基于3D地图(atlas,所有数据的平均值)上进行配准,使用一个由额外数据集计算的地图。
数据预处理
使用了大尺度、多范围的T1加权脑部MRI图像(来自八个公开数据集,攻击7829张图像,ADNI,OASIS,ABIDE,ADHD200,MCIC,PPMI,HABS和Harvard GSP),所有图像重采样为具有1mm各项同性的体素,进行仿射空间归一化并且使用FreeSurfer去除颅骨,提取脑部图像。裁剪图像为( 160 × 192 × 224 160 × 192 × 224 160×192×224),使用29个解剖结构,按7329:250:250划分数据集。
评价指标
对每个解剖结构进行DICE系数评估,同时还评价微分同胚的性能。雅可比行列式 J ϕ ( p ) = ▽ ϕ ( p ) ∈ R 3 × 3 J_{\phi}(p)=\bigtriangledown\phi(p)\in\mathcal{R}^{3\times3} Jϕ(p)=▽ϕ(p)∈R3×3(点我直达)可以评估行变场在体素p周围的局部属性。 J ϕ ( p ) > 0 J_{\phi}(p)>0 Jϕ(p)>0的体素是微分同胚的(既可逆又保持方向),统计 J ϕ ( p ) ≤ 0 J_{\phi}(p)\leq0 Jϕ(p)≤0的体素。
结果分析
对比ANTs(一个软件包)与对称归一化(Symmetric Normalization,SyN),结果如下:
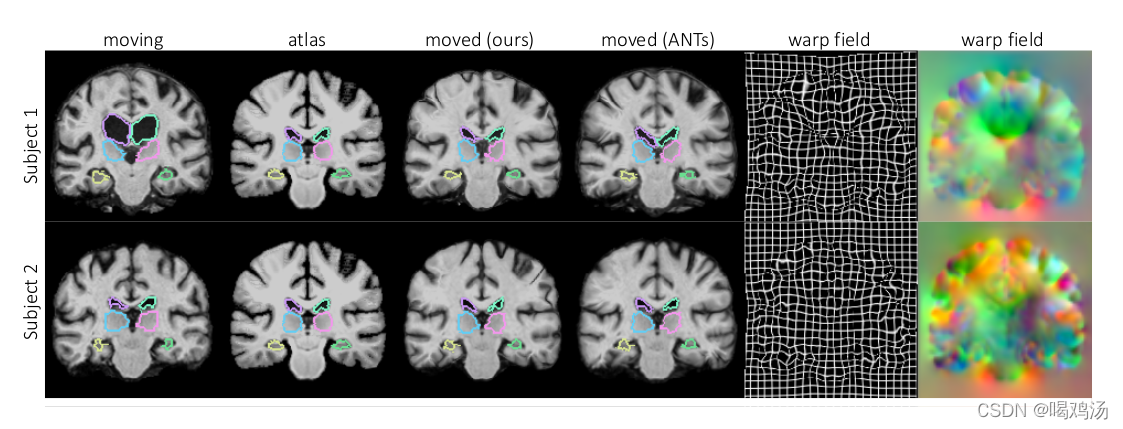

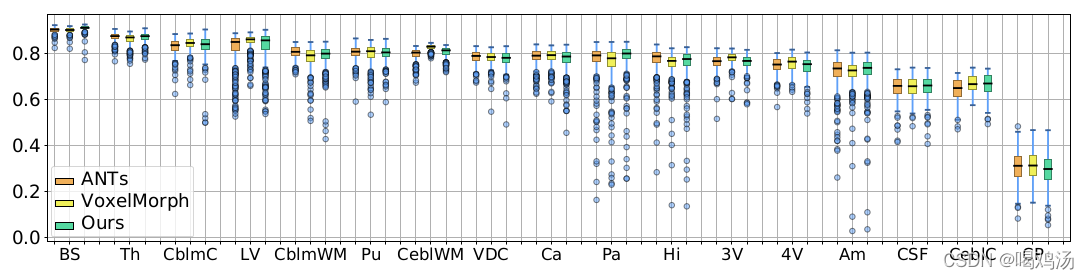
实例图如上,配准结果与ANTs几乎一样,且行变场并没有紊乱(有时会为了配准而配准,即出现大幅跳跃,不连续现象)视觉上看不出有跳跃的地方。表格中的数据更加直观表明效果好,计算时间短,具有可确定性,良好的微分同胚特性(负雅可比体素的数目非常少)。
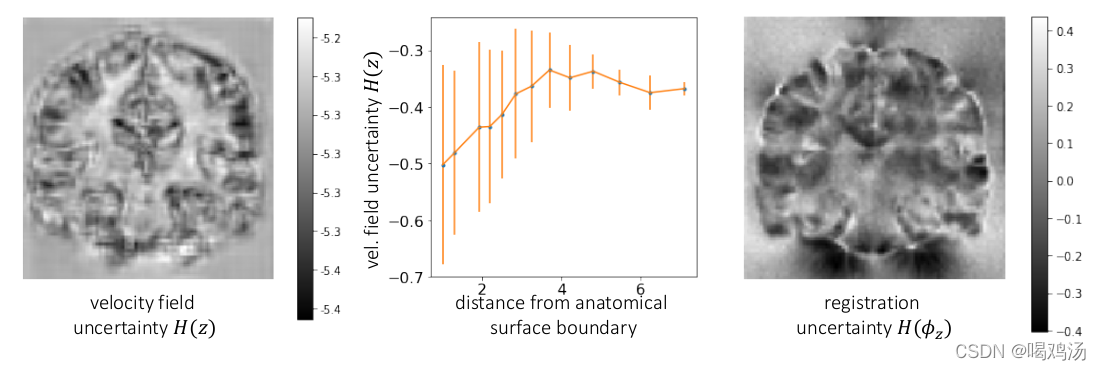
上图是图像的不确定性估计,左图为行变场的不确定性,边界的不确定性较小,右图为扭曲后的图像,均匀扫描的地方(eg:白质)不确定性较高。中间折线图没看懂。
参数设置
经实验,发现设置 σ 2 ∼ ( 0.035 ) 2 , λ = 70000 \sigma^2\sim(0.035)^2,\lambda=70000 σ2∼(0.035)2,λ=70000时效果理想。
结论
提出一种使用微分图像配准的概率模型,推导出使用CNN和直观损失函数的学习算法,还引入了缩放和平方层。实现了快速有效的运算,还保证了微分同胚,提供不确定性估计。