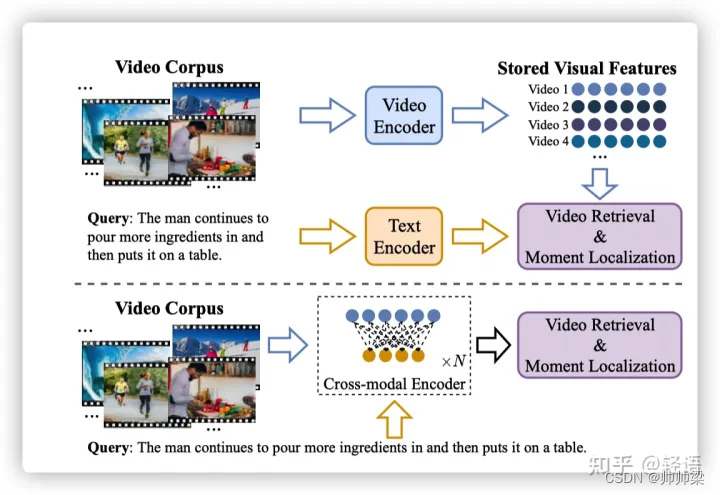
跨语言跨模态整合用于有效的多语言视频语料库时刻检索
摘要
现有的多语言视频语料库矩检索(mVCMR)方法主要基于双流结构。视觉流利用视频中的视觉内容来估计查询视觉相似性,而字幕流利用查询字幕相似性。
最后的查询视频相似性集合了来自两个流的相似性。在我们的工作中,我们提出了一种简单有效的策略,称为跨语言跨模态整合(C3),以提高mVCMR的准确性。我们采用整体相似性作为教师来指导每个流的训练,从而产生更强大的整体相似性。同时,我们使用特定语言的教师来指导学生使用另一种语言,以开发不同语言之间的互补知识。在mTVR数据集上的大量实验证明了我们的C3方法的有效性
1 介绍
视频语料库时刻检索(VCMR)任务已在(Escorcia等人,2019;Lei等人,2020)中提出,其目的是在给定自然语言查询的情况下从大型视频语料库中检索短时刻。
最近,(Lei等人,2021a)引入了一种多语言视频语料库时刻检索(mVCMR)任务。与VCMR相比,mVCMR支持多种语言的查询。它在实践中更有用,特别是在国际应用中。
为了促进mVCMR的研究,(Lei等人,2021a)构建了一个大规模的mTVR数据集,其中查询使用两种语言。
除了视频的视觉内容外,还提供视频的文本字幕作为辅助信息,以帮助查询视频检索。(Lei等人,2021a)提出了一种mXML模型 ,以生成用于视频检索的查询视频相似度和用于两流结构的瞬间定位的查询剪辑相似度。字幕流捕获文本查询和视频文本字幕之间的相似性。同时,视觉流描述文本查询和视频的视觉内容之间的相似性。最终的文本视频相似性是来自两个流的相似性的总和。
由于最终相似性是通过对两个流的相似性进行总结而获得的,因此,直接假设提高每个流的相似的有效性有利于提高最终相似性的性能是合理的。同时,由于最终相似性融合了来自两种模态的信息,因此假设最终相似性比来自每个流的相似性更可靠也是合理的。
基于以上两个假设,我们提出了一种改进mVCMR任务双流架构性能的简单方法。具体来说,我们使用融合两种模式的最终相似性作为教师,使用来自每个流的相似性作为学生。我们通过老师的知识指导来训练学生。
同时,为了利用跨语言的自然补偿,我们设计了一种语言的学生和另一种语言的教师。我们将我们的方法称为跨语言跨模态合并( C 3 C^3 C3),如图1所示。在mTVR数据集上的综合实验结果证明了我们的C3方法的有效性。
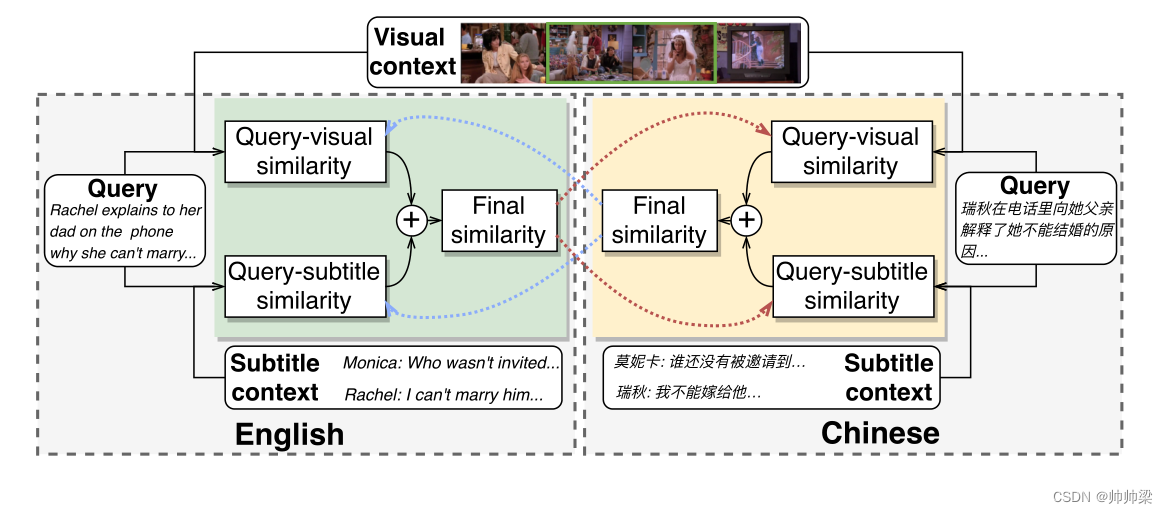
图1:我们的跨语言跨模态整合(C3)图解。左绿色和右黄色框分别包含使用英文和中文查询的相似之处。查询视觉相似性度量查询与视觉上下文之间的相关性,而查询字幕相似性表示查询与字幕上下文之间的关联。通过汇总查询视觉和查询字幕相似性来获得最终的相似性。特定语言中的最终相似性作为教师指导学习另一种语言中的查询字幕/查询视觉相似性。
查询和视频的相似,查询和字母的相似,合并成一个整体的相似
2 相关工作
Text-video retrieval.
Video corpus moment retrieval.
Knowledge distillation.
3
3.1 Preliminary(初步)
问题定义:当前的多语言时刻检索模型mXML(Lei等人,2021a)在其浅层执行视频检索,在其深层执行时刻定位。(两步走)
我们用qg表示查询,其中g表示语言类型,例如英语。视频v由L个连续时刻{cl}Ll=1组成。每个时刻cl与字幕sg,l配对。mXML生成用于视频检索的查询视频分数S(qg,v)和用于时刻定位的开始/结束帧tst/ted的索引:
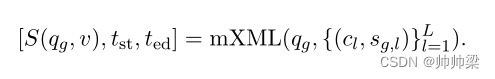
mXML支持英文(en)和中文(zh),即g∈{en,zh}。
下面,我们简要介绍mXML中的视频检索和时刻定位。
输入特征: ResNet-152 (He et al, 2016) 和 I3D (Carreira and Zisserman, 2017) 提取每个视频时刻的视觉特征。 RoBERTa-base (Liu et al, 2019) 分别提取英语 (Liu et al, 2019) 和中文 (Cui et al, 2020) 的语言特征。基于 Transformer (Vaswani et al, 2017) 和模块化注意力 (Lei et al, 2020) 的自编码器 (SE) 用于进一步编码视觉和文本特征。
视频检索:视频检索的基于字幕的分数 Ss(qg, v) 和基于视觉的分数 Sv(qg, v) 分别由两个流获得。
获得 Ss(qg, v) 和 Sv(qg, v) 的细节见附录 A.3。使用两种上下文的最终视频检索分数 S(qg, v) 被设计为
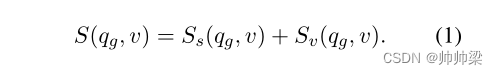
Moment Localization(时刻定位): 基于字幕的查询片段得分 Ss(qg, cl) 和基于视觉的查询片段得分 Sv(qg, cl) 分别由两个流计算。附录 A.4 中显示了计算 Ss(qg, cl) 和 Sv(qg, cl) 的详细信息。最终的查询剪辑分数被设计为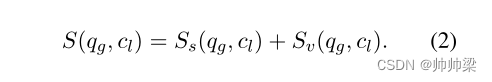
然后,为了从 S(qg, cl) 生成矩定位预测,mXML 预测每个查询的开始和结束概率 pstg , pedg ∈ RL 。
对于 mXML,视频检索损失 Lvr、矩定位损失 Lloc 和语言邻域约束损失 Lnc 在附录 A.5 中进行了说明。
mXML 的最终损失函数设计为
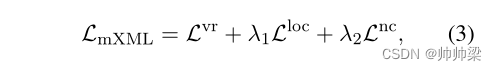
3.2 C 3 C^3 C3 in Video Retrieval
在等式中。 (1),最终的视频级相似度 S(qg, v) 是两种模态 Sv(qg, v) 和 Ss(qg, v) 得分的总和。我们使用具有两种模态知识的 S(qg, v) 作为教师,并将其知识提炼 (Hinton et al, 2015) 到仅具有单一模态信息的分数。
在多语言场景中,为了利用更多的互补知识,一种更有效的方法是将一种语言 g ∈ {en, zh} 的分数蒸馏到另一种语言 h ∈ {en, zh} 的分数:
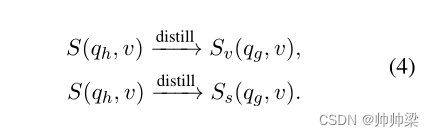
给定一个小批量的查询-视频对 {(qig, vi)}ni=1,其中 n 是批量大小,S(qih, vk) 是基于两种模态的教师模型的 qih 和 vk 之间的相似性得分(即视觉和字幕上下文),其中 k ∈ [1, n]。 Sv(qig, vk) 和 Ss(qig, vk) 分别是来自视觉和字幕上下文的学生模型的相应相似度分数。然后,对于每个查询 qih,我们可以生成教师分数 {S(qih, vk)}nk=1,并对分数执行具有温度 τvr 的 softmax 函数以获得归一化分数:
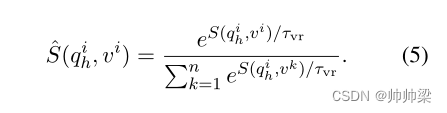
以同样的方式,我们得到归一化的学生分数 ^Sv(qih, vi) 和 ^Ss(qih, vi)。最后,视频检索的 C3 损失被设计为
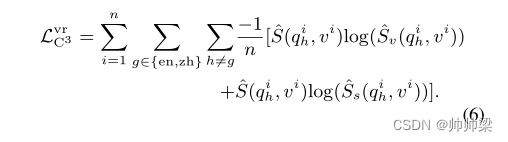
视频检索的损失被设计为:
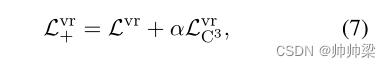
3.3 C 3 C^3 C3 in Moment Localization
同样,C3 也可以用于矩定位。在等式中。 (2),我们使用两个上下文生成查询剪辑相似性分数,然后生成开始和结束概率。同理,基于单一字幕上下文的Ss(qg, cl),我们可以生成开始和结束概率pstg,s, pedg,s ∈ RL,并且基于单一视觉上下文的Sv(qg, cl),我们可以生成 pstg,v, pedg,v ∈ RL。请注意,我们使用具有温度 τloc 的 softmax 函数以类似方程式的方式生成开始和结束概率。 (5).我们使用视觉上下文将来自语言h的教师模型的开始和结束概率定义为psth和pedh,将来自语言g的学生模型的开始概率和结束概率分别定义为pstg、v、pedg、v,以及使用字幕上下文的pstg、s、pedg和s。因此,力矩定位的C3损失定义如下:
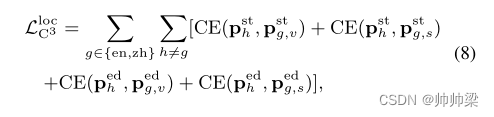
其中CE()是交叉熵函数,定义为
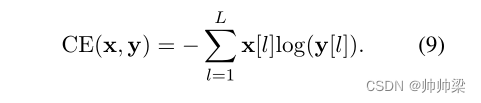
力矩定位损失如下:
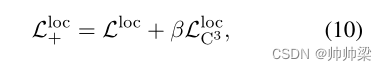
3.4 Training and Inference
最终损失函数 : 考虑到我们提出的C3,最终损失函数构造如下: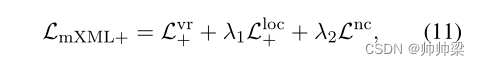
它类似于Eq.(3)中定义的LmXML的公式,但基于我们的C3将Lvr替换为Lvr+,将Lloc替换为Lloc+。
Training: 训练分为两个阶段。
在第一阶段,我们使用Eq.(3)中的损失函数LmXML对标准mXML模型进行训练,得到教师模型,该模型通过两种模态知识生成查询视频分数S(qg, v)和查询剪辑分数S(qg, cl)。
然后,在第二阶段,我们使用teacher mXML模型,利用Eq.(11)中的损失函数LmXML+提取随机初始化的student mXML模型的训练过程。经过训练后,学生mXML模型将比教师模型表现得更好。因此,我们利用训练过的学生mXML模型作为新的教师mXML模型,从一开始就指导一个新的随机初始化的学生mXML模型的训练。我们在第二阶段重复蒸馏过程,进行Q次迭代,直到性能饱和。为了更好地说明,我们总结了我们提出的C3方法的训练过程,如算法1所示。

推理。由于我们的方法与模型正交,推理过程与mXML相同。
4 实验
数据集。mTVR (Lei et al, 2021a)是一个大型多语言视频瞬间检索数据集,包含21.8万个电视节目视频片段的21.8万个中英文查询。该数据集扩展了TVR数据集(英文)(Lei et al, 2020),并添加了中文查询和字幕。(Lei et al, 2021a)提出将mTVR数据集分为80%的训练数据集,10%的val数据集,5%的测试-公共数据集和5%的测试-私有数据集。我们使用这个数据集来验证我们的方法的有效性。我们工作中的所有实验都在一台NVIDIA Tesla V100 GPU上进行。
实验设置。我们报告了mTVR (Lei et al, 2021a)数据集上的多语言视频语料库时刻检索(mVCMR)任务在K(即R@K)上的平均召回率,其中预测的时刻与地面真相具有高交叉联合(IoU)时是正确的。我们使用mXML相同的训练策略和网络架构(Lei et al, 2021a)。式(3)和式(11)的λ1和λ2分别设为0.01和1。将LvrC3和LlocC3用于视频检索和时刻定位的损失权值α和β分别设为1.0和100。τvr设为0.02,τloc设为1。蒸馏迭代次数Q设为2。我们将提议的C3部署在mXML中,并将mXML缩写为C3到C3。
4.1主要结果
在表1中,在mTVR数据集的测试-公共split1上,我们将C3与现有方法进行了比较,包括基于提议的方法(MCN (Anne Hendricks等人,2017)和CAL (Escorcia等人,2019)),基于重排序的方法(MEE (Miech等人,2018)+MCN, MEE+CAL, MEE+ExCL (Ghosh等人,2019)和XML (Lei等人,2020))和最先进的mXML (Lei等人,2021a)。我们观察到,与基线方法相比,我们的C3在英语和中文中都获得了持续更高的R@1。在表2中,C3还大大改进了mTVR数据集的test-public分割上的XML和mXML的R@10。
注意,XML的R@10结果是基于我们的重新实现的。在表3中,我们比较了mTVR数据集val分割的性能,C3的性能也比mXML好很多,这进一步显示了我们方法的优势。
4.2消融研究与分析
不同成分的效果。默认情况下,我们在视频检索(公式(7)中的LvrC3)和时刻定位(公式(10)中的LlocC3)中都利用了C3。我们通过分别去除LlocC3和LvrC3中的一个来评估它们的重要性。从表4中,我们观察到,去除LlocC3或LvrC3后,视频语料矩检索的R@1显著恶化。
**视频检索分析:**值得注意的是,对于 mVCMR 任务,我们同时考虑了单个视频中的视频检索和时刻定位。为了更全面地展示我们的 C3 的优势,我们还调查了它在视频检索任务中的影响。从表 5 中,我们可以观察到我们的 C3 大大优于基线模型 mXML。
单视频时刻检索分析: 为了进一步证明所提出的 C3 在矩定位方面的有效性,我们还报告了单个视频矩检索(即 SVMR)结果。
从表 6 中,我们观察到与 mXML 相比,我们的 C3 实现了显着的性能改进。这表明我们的 C3 预测了更准确的矩定位结果,这表明我们的 C3 在矩定位方面的有效性
单语视频语料库时刻检索的扩展: 尽管所提出的 C3 方法是针对 mVCMR 设计的,但它也自然适用于单语视频语料库矩检索。
在这里,我们评估了 C3 在单语环境中的有效性。TVR 数据集(Lei 等人,2020 年)包含从 6 个不同类型的电视节目的 21800 个视频中收集的 109000 个查询,其中每个视频都与字幕相关联,每个查询都与一个紧密的时间窗口相关联。
具体而言,我们使用XML(Lei等人,2020)模型作为基线方法,并通过在多模态输出和单模态输出之间应用我们的C3损失函数,提出了一种替代方案,用于视频检索和时刻定位任务,遵循方程(6)和方程(8)的类似策略。换句话说,这种替代变体被称为语内跨模态整合(IC2)方法。在表7中,我们将我们的替代变体IC2与基线模型XML进行了比较,比较了用于单语视频语料库瞬间检索的TVR数据集的val和test公共分割。如表7所示,我们的IC2在TVR数据集上也实现了显著的性能改进,这进一步证明了我们提出的整合策略的多功能性。
5 限制和潜在风险
尽管我们的C3在mTVR数据集上基于mXML实现了实质性改进,但我们发现C3中存在一些超参数(例如τvr、τloc)需要调整,这可能很耗时。此外,我们开发了C3策略来提高mVCMR任务的性能,但我们在论文中没有看到潜在的风险。
6 结论
在我们的工作中,对于多语言视频语料库瞬间检索(mVCMR),我们引入了一种简单有效的跨语言和跨模态整合(即C3)策略。它通过对多模态信息的访问,从相似性得分中提取知识,提高了单一模态相似性得分的可靠性。同时,它通过跨语言知识提取,利用跨语言的互补信息进行视频检索和即时定位。大量的实验结果证明了我们方法的有效性。
ppt附录
1
1.1 Video Corpus Moment Retrieval
简要介绍:video corpus moment retrieval任务需要在__大量__的视频中,根据查询语句检索得到相关的__片段__,
与其相关的任务有:video retrieval(在大量视频中根据查询得到相关的视频)和moment localization(根据查询语句在一个视频中定位相关的片段),其分别对应着对整段视频的全局内容理解以及以clip为单位的片段定位两个不同粒度的视频特征,
相比于前面两个任务,video corpus moment retrieval更加复杂,如果直接在大量视频的每个片段级别进行检索,那么会有相当高的时间复杂度,因此当前的做法往往将该任务分成两个阶段分别进行,即先通过video retrieval检索得到前k个最相关的视频,然后在k个视频中定位相关片段。
1.2
对于作为查询语句的文本内容以及待查询的视频内容,当前有两种主流的做法进行多模态特征的整合来进行检索和定位,如下图所示,
第一种方法对视频和查询语句单独提取特征,通过在后期添加线性变换、注意力机制等实现特征的对齐,而在推理阶段可以对视频提前进行特征提取,从而可以对查询语句快速得到查询结果,这样做的好处是推理速度快,但是缺点在于推理时可能会忽略部分模态间的关联信息,从而导致准确率不高。
而第二种方法是通过cross-modal attention等机制,在早期就进行多模态的融合,从而在推理过程中可以有跨模态信息作为参照,得到更精确的多模态特征融合以及检索定位,但缺点是视频信息必须得到查询语句后才能生成后续任务所需要的特征,从而降低了查询定位效率。这里,我们就从这两个方法,分别进行梳理当前的研究方法与不足。