本文首发于公众号:机器感知
高保真度与流畅度MagicVideo-V2视频生成模型;3D人形虚拟角色;微调量化的扩散模型;自动给视频配音;非自回归音频生成
MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation

本文提出了MagicVideo-V2视频生成模型,该模型将文生图模型、视频运动生成器、参考图像embedding模块和帧插值模块集成到端到端视频生成管道中,MagicVideo-V2能够生成逼真度与流畅度都较高的高分辨率视频,并显著优于Runway、Pika 1.0、Morph、Moon Valley和Stable Video Diffusion model等领先的文生视频模型。
Morphable Diffusion: 3D-Consistent Diffusion for Single-image Avatar Creation

本文提出将3D morphable模型集成到多视图一致扩散方法中,提高了生成可控性和人形虚拟角色的质量。这种方法能准确地将面部表情和身体姿态控制纳入生成过程,是首个从单个未见过的人像中创建出完全3D一致、可动画且逼真的人形虚拟角色的扩散模型。
Memory-Efficient Personalization using Quantized Diffusion Model


本文研究了微调量化的扩散模型这一领域,并通过定制三个模型(PEQA用于微调量化参数,Q-Diffusion用于后训练量化,DreamBooth用于个性化),建立了强大的基线模型。分析显示,基线模型在主体和提示保真度之间存在显著的权衡。为了解决这些问题,作者提出了两种策略:a.优化选定时间步长的参数集,b.创建多组专用的微调参数集,每个参数集针对不同的时间步长。该方法不仅增强了个性化,而且保持了提示保真度和图像质量,在质量和数量上都显著优于基线。
SonicVisionLM: Playing Sound with Vision Language Models
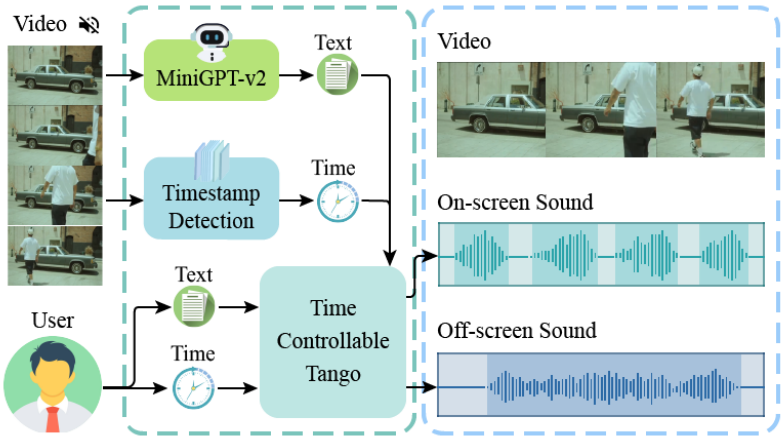
本文提出了一种名为SonicVisionLM的新框架,通过利用视觉语言模型来生成各种声音效果。该方法首先使用视觉语言模型识别视频中的事件,然后根据视频内容推荐可能的声音。这种方法将图像和音频的匹配任务转化为更易研究的图像到文本和文本到音频的匹配任务。为了提高音频推荐的质量,作者收集了一个大规模数据集,将文本描述映射到特定的声音效果,并开发了时间控制的音频适配器。该方法在将视频转换为音频方面超越了当前SOTA方法,提高了视频与音频的同步性,并改善了音频和视频元素之间的对齐。
Masked Audio Generation using a Single Non-Autoregressive Transformer

本文提出了MAGNeT,一种直接在音频标记流上操作的掩码生成序列建模方法,它由一个单阶段、非自回归transformer组成。在训练期间,预测从掩码调度器获得的掩码标记的范围,而在推理期间,使用多个解码步骤逐步构建输出序列。为了进一步提高生成的音频质量,引入了一种新的评分方法。最后,作者探索了MAGNeT的混合版本,其中以自回归方式将自回归和非自回归模型融合在一起,以生成序列的前几秒,而其余的序列则并行解码。这种方法与所评估的基线模型相当,但速度要快7倍。