【2024|全球滑坡数据集论文解读4】基于多源高分辨率遥感影像的同震滑坡制图全球分布式数据集
【2024|全球滑坡数据集论文解读4】基于多源高分辨率遥感影像的同震滑坡制图全球分布式数据集
文章目录
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文:
可访问艾思科蓝官网,浏览即将召开的学术会议列表。会议入口:https://ais.cn/u/mmmiUz
论文链接:https://essd.copernicus.org/articles/16/4817/2024/essd-16-4817-2024.pdf
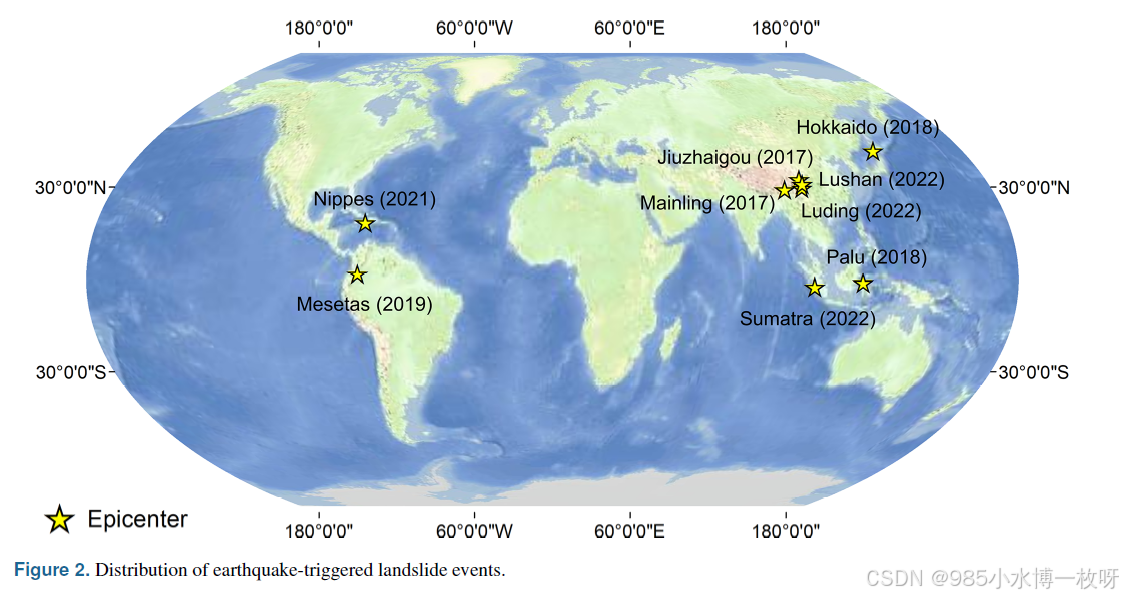
4. Experimental setup
在数据集构建完成后,进入实验阶段。在此部分,我们介绍用于数据集验证的几种语义分割算法、实验中采用的损失函数与精度评估指标,以及实验过程中使用的各种超参数设置。
4.1 Segmentation algorithms
本节选取了七种当前流行的语义分割网络模型,其中包括基于卷积神经网络(CNN)架构的四种模型和基于Transformer架构的三种模型。这七种算法具有中等至大型的参数规模和计算复杂度,并在多种遥感语义场景中表现出色,适用于精确对比和验证新型数据集。
U-Net
U-Net。作为最早且广为人知的语义分割模型之一,U-Net以其独特的U形架构而著称(Ronneberger等, 2015)。该设计通过将高分辨率特征从收缩路径与扩展路径中的上采样输出相结合,实现了高效学习与精确定位。U-Net的编码器和解码器均由纯卷积神经网络(CNN)结构组成(O’Shea和Nash, 2015)。这种简洁性以及相对较少的参数量使得U-Net能够在小规模数据集上实现出色的精度和快速推理。因此,它被广泛应用于小目标分类、变化检测和医学影像等应用场景。
ResU-Net
ResU-Net。ResU-Net是U-Net模型的增强变体,加入了残差连接以提升其性能和学习效率(Diakogiannis等, 2020)。ResU-Net的核心创新在于在编码器和解码器路径中引入残差块,这不仅解决了梯度消失问题,还支持更深层次网络的训练(He等, 2016)。这些残差块能够学习恒等映射,从而促进梯度在网络中的流动,加速收敛速度。与U-Net类似,ResU-Net保持U形结构,将收缩路径的高分辨率特征与扩展路径的上采样输出相结合,以确保精确定位和上下文捕获。残差连接的加入提升了特征复用和学习效率,使ResU-Net在语义分割任务中有效提升了召回率和小目标检测能力。
DeepLabV3
DeepLabV3:DeepLabV3是一种以其复杂的空洞卷积(或扩张卷积)技术而闻名的语义分割模型(Chen等, 2018)。这种技术使网络在保持空间分辨率的同时捕捉多尺度的上下文信息,克服了传统卷积网络在密集预测任务中的局限性。DeepLabV3通过空洞空间金字塔池化(ASPP)模块,利用不同扩张率的空洞卷积并行处理,实现对多尺度目标的鲁棒分割。该模型融合了编码器和解码器路径的特征,增强了边界的精确性。此外,DeepLabV3架构还采用批量归一化和深度可分离卷积,从而有效降低了模型的复杂度和计算成本,同时比简单网络(如U-Net)具有更强的特征提取和泛化能力。
HRNet
HRNet:高分辨率网络(HRNet)以其在网络中持续保持高分辨率特征的创新方法而著称(Wang等, 2020)。与传统模型逐步下采样输入以提取特征的方式不同,HRNet通过并行的高、低分辨率子网络来保留高分辨率特征。该设计使HRNet能够有效集成多尺度信息,确保精确定位和强大的特征表达能力。网络通过不同分辨率间的信息交换实现了优越的精度和细致的分割效果。凭借保留精细空间信息的能力,HRNet在复杂任务中表现优异,如细粒度地形分类、城市场景语义分割及精细视觉检测。
UPerNet
UPerNet:UPerNet采用金字塔特征提取方法,将多尺度信息整合以捕捉不同分辨率下的上下文细节(Xiao等, 2018;Liu等, 2022)。其基于特征金字塔网络(FPN)的主干网络进行层次化特征提取,并通过全局上下文集成模块提升对整体场景的理解。此外,UPerNet还通过横向连接实现特征金字塔层间的高效信息传递,确保信息流畅通和分割精度。此架构使得UPerNet在处理复杂场景和多样化目标尺度的任务中具有出色的分割性能。
SwinU-Net
SwinU-Net:SwinU-Net基于Swin Transformer架构,结合了自注意力机制与U-Net,实现卓越表现(Cao等, 2022)。该模型继承了Swin Transformer的分层特征提取方式,有效捕捉局部和全局上下文信息(Liu等, 2021)。自注意力机制使模型能够捕捉数据中的细微关系。SwinU-Net在解码过程中结合了U-Net的收缩和扩展路径,强调空间细节的保留。这种组合使SwinU-Net在需要精确定位和强大上下文理解的任务中表现出色。
SegFormer
SegFormer:SegFormer通过Transformer架构在语义分割领域取得了重要进展(Xie等, 2021)。与传统CNN方法不同,SegFormer采用分层Transformer编码器,在不依赖位置编码或大规模预训练数据集的情况下,有效捕捉多尺度上下文信息。其解码器通过轻量级多层感知机集成不同尺度的特征,确保了高效、精准的分割。该创新设计使SegFormer能够在高分辨率复杂场景中,以中等参数量和快速推理速度实现卓越的分割效果。
4.2 Loss function and accuracy evaluation
由于滑坡检测是一个二分类语义分割任务,我们选择二元交叉熵(De Boer等, 2005)作为模型训练的损失函数,其数学表达式如下:
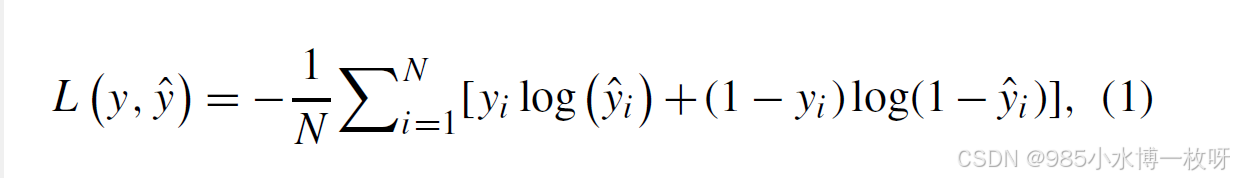
其中, L L L 表示损失函数, N N N 是样本总数, y i y_i yi为第 i i i 个样本的真实标签(0或1), y ^ i \hat{y}_i y^i为第 i i i 个样本的预测概率。
在精度评估方面,我们通过混淆矩阵(Townsend, 1971)计算以下精度指标:精度(Precision)、召回率(Recall)、F1分数(Chicco和Jurman, 2020)以及平均交并比(mIoU)(Rezatofighi等, 2019)。其计算公式如下:

其中,TP为真正例,FP为假正例,TN为真负例,FN为假负例。
4.3 Equipment and parameter
本研究采用的深度学习框架基于Paddle 2.3.2(Ma等, 2019),实验环境配置为Python 3.8、CUDA 11.2及CuDNN 8.3.0。实验设备包含Intel Xeon W2255 CPU(3.7 GHz)和256GB内存,GPU为Tesla V100,显存32GB,操作系统为Ubuntu 20.04。模型优化器选择AdamW(Loshchilov和Hutter, 2017),初始学习率设置为0.0006,beta1为0.9,beta2为0.999,权重衰减为0.01,总训练轮数为100。
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文:
可访问艾思科蓝官网,浏览即将召开的学术会议列表。会议入口:https://ais.cn/u/mmmiUz