小罗碎碎念
本文提出了一种基于集成Transformer的多实例学习框架,结合自监督学习的Vision Transformer特征编码器(ETMIL-SSLViT),用于从子宫内膜癌(EC)和结直肠癌(CRC)患者的H&E染色全切片图像(WSIs)中预测病理亚型和肿瘤突变负荷(TMB)状态。

| 姓名 | 单位 |
|---|---|
| Ching-Wei Wang | 国立台湾科技大学生物医学工程研究所 |
| Tai-Kuang Chao | 国立台湾科技大学生物医学工程研究所、三军总医院妇产部、国防医学院病理学系、三军总医院病理科、国防医学院病理学与寄生虫学研究所 |
一、研究背景
1-1:背景介绍
这篇文章的研究背景是子宫内膜癌(EC)和结直肠癌(CRC)中,肿瘤突变负荷(TMB)逐渐成为一种重要的基因组生物标志物,可用于临床判断哪些患者可能从免疫检查点抑制剂中受益。
高TMB的特点是突变基因数量多,编码异常肿瘤新抗原,意味着对免疫治疗的反应更好。然而,TMB的测量主要通过全外显子测序或下一代测序评估,成本高昂且难以在所有临床病例中广泛应用。
因此,迫切需要一种有效、高效、低成本且易于获取的工具来区分EC和CRC患者的TMB状态。
1-2:研究内容
该问题的研究内容包括:提出一种深度学习框架,即集成Transformer的多实例学习框架,结合自监督学习的Vision Transformer特征编码器(ETMIL-SSLViT),直接从EC和CRC患者的H&E染色全切片图像(WSIs)中预测病理亚型和TMB状态,有助于病理分类和癌症治疗计划。
二、研究方法
这张图展示了一个名为EFML-OMF的多阶段机器学习框架,用于病理图像的分析和分类。
该框架分为三个主要部分:VPSM、SSLViT-FEM和EF with T-OMF。
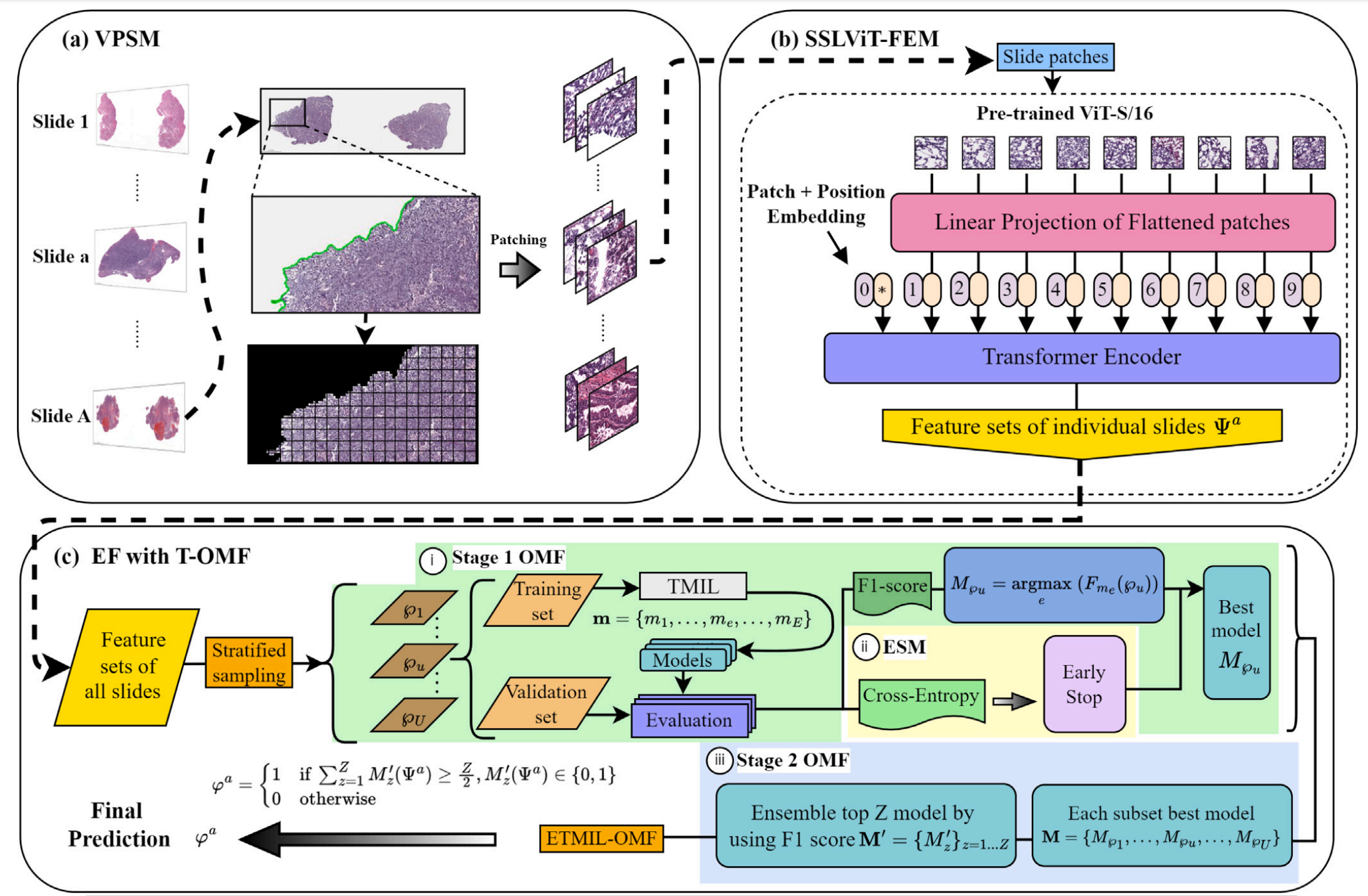
下面是对每个部分的详细分析:
2-1:VPSM
- 功能:Vision Patch Segmentation Module (VPSM) 用于快速提取非重叠前景补丁,增强WSI分析的效率和准确性。
- 过程:
- 输入的病理切片图像被分割成多个小块(Patching)。
- 这些小块被进一步处理,以准备输入到后续的模型中。
2-2:SSLViT-FEM
- 功能:Self-Supervised Learning Vision Transformer Feature Encoder Module (SSLViT-FEM) 集成预训练的ViT-S/16和SSL技术,提取图像的全局显著特征,解决图像内容之间的长距离连接,并充分利用注意力机制将全局上下文信息纳入图像特征,提高特征提取的准确性。
- 过程:
- 将图像块和位置嵌入(Patch + Position Embedding)输入到预训练的ViT-S/16模型中。
- 通过线性投影将展平的图像块转换为特征向量。
- 使用Transformer编码器处理这些特征向量,生成每个切片的特征集(Feature sets of individual slides)。
2-3:EF with T-OMF
-
功能:
- Transformer-based Multiple Instance Learning (TMIL) 将每个WSI视为一个包,从WSI中提取的补丁视为实例,利用Transformer的自注意力机制建模实例之间的关系,增强表示能力。
- Early Stop Mechanism (ESM) 基于交叉熵损失,防止过拟合并节省计算资源和时间。
- Ensemble Framework (EF) 使用袋装策略和两阶段最优模型查找方法(T-OMF),提高方差减少、预测性能和模型鲁棒性,减少过拟合。
-
过程:
- Stage 1 OMF:
- 使用训练集和验证集进行模型训练和验证。
- 通过模型评估(Evaluation)选择最佳模型。
- Stage 2 OMF:
- 集成前Z个模型,这些模型根据F1分数(F1-score)和交叉熵(Cross-Entropy)进行选择。
- 使用早期停止(Early Stop)策略来防止过拟合。
- 每个子集的最佳模型被组合起来,形成最终的集成模型。
- Final Prediction:
- 通过策略化采样(Stratified sampling)从所有切片的特征集中选择特征。
- 使用特定的规则(如公式中所示)来确定最终的预测结果。
- Stage 1 OMF:
这个框架结合了图像处理、深度学习和集成学习的技术,旨在提高病理图像分析的准确性和效率。每个阶段都有其特定的目标和方法,共同构成了一个复杂的机器学习流程。
三、数据集分析
3-1:TCGA EC队列和CRC队列的数据
这张图展示了TCGA(The Cancer Genome Atlas)项目中的两个癌症队列:子宫内膜癌(EC)队列和结直肠癌(CRC)队列。TCGA是一个公共的癌症基因组学数据库,它提供了多种癌症类型的基因组、转录组、蛋白质组和临床数据。

EC队列(子宫内膜癌队列)
- 幻灯片数量:918张
- 患者数量:529名
- 组织来源地点:29个
CRC队列(结直肠癌队列)
- 幻灯片数量:1495张
- 患者数量:594名
- 组织来源地点:25个
3-2:数据的图像多样性:
这张图展示了两个癌症队列(EC和CRC)的图像多样性,具体包括不同类型的组织学特征和肿瘤突变负荷(TMB)的高低。
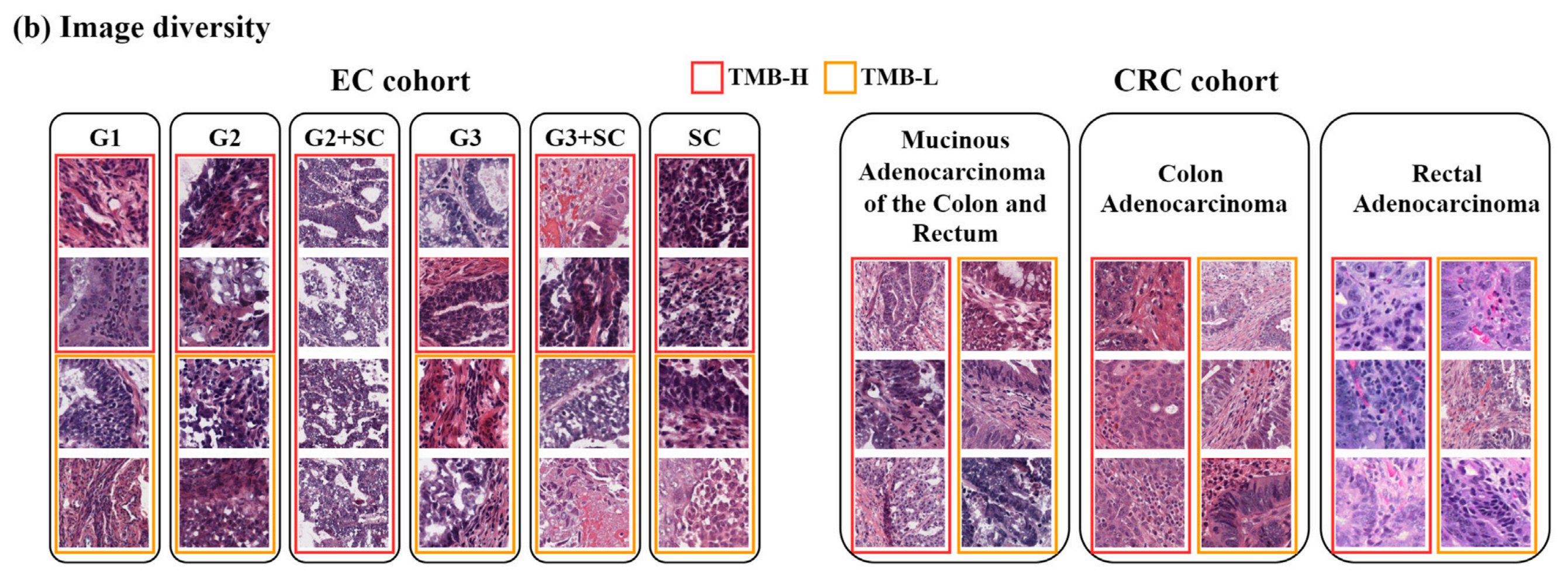
EC队列(子宫内膜癌队列)
- G1, G2, G3:这些是子宫内膜癌的分级,从G1(低级别)到G3(高级别)。
- G2+SC, G3+SC:这些表示除了分级之外,还伴有肉瘤(SC)成分的肿瘤。
- TMB-H(红色框):表示肿瘤突变负荷高。
- TMB-L(黄色框):表示肿瘤突变负荷低。
CRC队列(结直肠癌队列)
- Mucinous Adenocarcinoma of the Colon and Rectum:粘液性结直肠腺癌,这是一种特殊类型的结直肠癌,其特点是产生大量粘液。
- Colon Adenocarcinoma:结直肠腺癌,这是结直肠癌中最常见的类型。
- Rectal Adenocarcinoma:直肠腺癌,与结肠癌类似,但发生在直肠部位。
图像分析
- 每个队列的图像展示了不同的组织学特征,这些特征对于病理学家来说是诊断和分级癌症的关键。
- TMB的高低可能影响癌症的生物学行为和对治疗的反应。高TMB(TMB-H)通常与更高的免疫反应和可能更好的免疫治疗反应相关。
- 图像中的红色和黄色框用于强调TMB的不同水平,这对于研究癌症的遗传特性和开发个性化治疗方案非常重要。
研究意义
- 通过分析这些图像,研究人员可以更好地理解不同类型和级别的癌症的组织学特征。
- 了解TMB与癌症类型和分级的关系,有助于预测癌症的进展和治疗反应。
- 这些信息对于开发新的诊断工具和治疗策略具有重要价值。
总的来说,这张图提供了一个直观的视角,展示了子宫内膜癌和结直肠癌在组织学特征和遗传特性上的多样性。
3-3:亚型分布:
这张图展示了子宫内膜癌(EC)和结直肠癌(CRC)队列中不同亚型的患者分布情况。
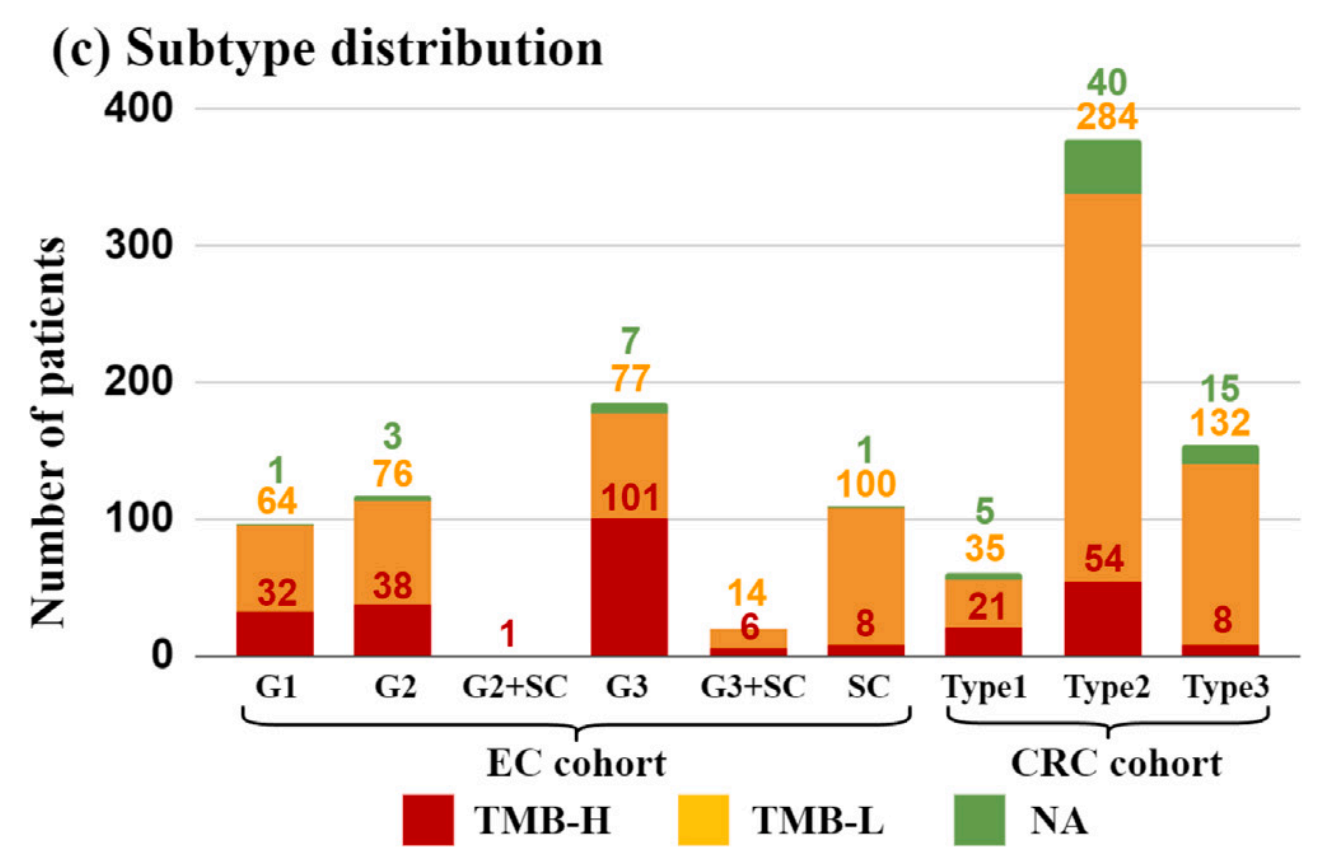
图中使用了不同颜色来表示肿瘤突变负荷(TMB)的高低,以及未确定(NA)的情况。
分析
- TMB分布:在EC队列中,G3亚型的TMB-H患者比例较高,而在CRC队列中,Type3亚型的TMB-H患者比例相对较低。
- NA比例:CRC队列中Type2和Type3亚型的NA比例较高,这可能表明在这些亚型中,TMB的测定可能存在困难或未进行。
- 患者数量:CRC队列的Type2亚型患者数量远多于其他亚型,这可能反映了该亚型在结直肠癌中的普遍性。
- TMB-L与TMB-H的比例:在大多数亚型中,TMB-L的患者数量多于TMB-H,这可能与癌症的遗传特性有关。
研究意义
- 了解不同亚型中TMB的分布有助于研究者探索癌症的遗传特性和可能的治疗方案。
- NA的高比例提示需要进一步的研究来确定这些患者的TMB状态,以便更好地理解其临床意义。
- 这些数据对于开发针对特定亚型和TMB状态的个性化治疗策略具有重要价值。
总的来说,这张图提供了关于EC和CRC不同亚型中TMB分布的详细信息,这对于癌症研究和治疗具有重要的参考价值。
3-4:长度分布(以像素为单位):
这张图展示了子宫内膜癌(EC)和结直肠癌(CRC)队列中切片的宽度和高度的像素分布。
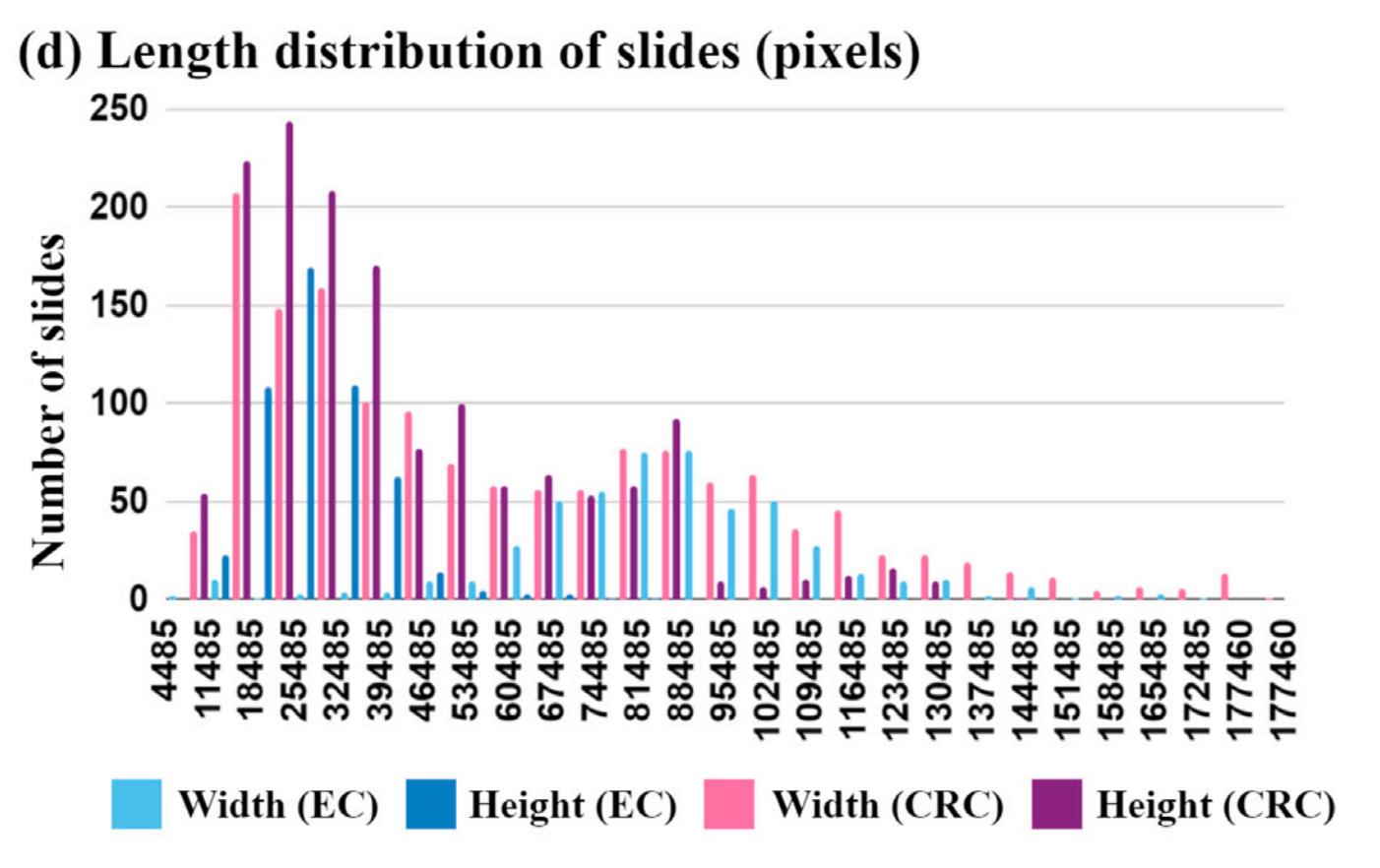
图中使用了不同颜色来区分EC和CRC的宽度和高度。
分析
- 像素范围:幻灯片的宽度和高度的像素值分布在4485到177460之间。
- EC队列:
- 宽度(蓝色):分布较为均匀,但在某些像素值(如4435, 18435, 25435等)处有较高的峰值。
- 高度(浅蓝色):分布也较为均匀,但在某些像素值(如4435, 18435, 25435等)处有较高的峰值。
- CRC队列:
- 宽度(粉色):分布较为均匀,但在某些像素值(如4435, 18435, 25435等)处有较高的峰值。
- 高度(紫色):分布较为均匀,但在某些像素值(如4435, 18435, 25435等)处有较高的峰值。
- 峰值:在某些特定的像素值(如4435, 18435, 25435等)处,EC和CRC的宽度和高度都有较高的峰值,这可能表明这些尺寸的幻灯片在两个队列中都较为常见。
研究意义
- 标准化:了解幻灯片的尺寸分布对于数据标准化和后续的图像分析非常重要。
- 图像处理:在进行图像处理和分析时,需要考虑到不同尺寸的幻灯片可能需要不同的处理方法。
- 数据质量:幻灯片尺寸的分布信息有助于评估数据质量,确保在分析过程中考虑到所有可能的尺寸变体。
总的来说,这张图提供了关于EC和CRC幻灯片尺寸分布的详细信息,这对于癌症研究和图像分析具有重要的参考价值。
四、模型性能评估
4-1:子宫内膜癌亚型分类和肿瘤突变负荷预测
这张表格展示了在子宫内膜癌(EC)的癌症亚型分类和肿瘤突变负荷(TMB)预测任务中,不同方法的性能比较。
表格中列出了每种方法的准确率(Accu.)、精确率(Prec.)、召回率(Sens./Recall)、F1分数(F1-S.)、特异性(Spec.)、平均敏感性(MeanSS)、平均敏感性排名(MeanSS rank)、AUROC值以及Fisher精确检验的p值。

(a) EC亚型分类(侵袭性 vs 非侵袭性)
- 最佳表现:Proposed ETMIL-SSLViT with aug 方法在准确率、F1分数和AUROC值上表现最佳,分别为0.91、0.92和0.91。
- 最低表现:ClassicMIL 方法在所有指标上表现最差,准确率仅为0.53,AUROC值为0.55。
- 统计显著性:大多数方法的Fisher精确检验p值小于0.001,表明结果具有统计学显著性。
(b) 侵袭性亚型中的TMB状态预测
- 最佳表现:Proposed ETMIL-SSLViT with aug 方法在准确率、F1分数和AUROC值上表现最佳,分别为0.77、0.73和0.82。
- 最低表现:ClassicMIL 方法在所有指标上表现最差,准确率仅为0.61,AUROC值为0.57。
- 统计显著性:除了Wang et al. (2023d) 和 TOAD (Lu et al., 2021a) 方法外,其他方法的Fisher精确检验p值均小于0.001。
© 非侵袭性亚型中的TMB状态预测
- 最佳表现:Proposed ETMIL-SSLViT 方法在准确率和AUROC值上表现最佳,分别为0.66和0.61。
- 最低表现:MRAN (Xiang et al., 2023) 方法在所有指标上表现最差,准确率仅为0.47,AUROC值为0.57。
- 统计显著性:除了Improved_InceptionV3_MS (Wang et al., 2023e) 和 TOAD (Lu et al., 2021a) 方法外,其他方法的Fisher精确检验p值均小于0.001。
总结
- Proposed ETMIL-SSLViT with aug 方法在所有任务中均表现出色,特别是在EC亚型分类任务中。
- ClassicMIL 方法在所有任务中表现较差,可能需要进一步改进。
- 大多数方法的结果在统计上是显著的,表明这些方法在EC亚型分类和TMB预测上具有实际应用价值。
这些结果为子宫内膜癌的亚型分类和TMB状态预测提供了有价值的参考,有助于进一步的研究和临床应用。
4-2:子宫内膜癌分类性能
这张图展示了三种不同任务的ROC曲线,用于评估不同方法在癌症亚型分类和TMB预测中的性能。
每个子图(a、b、c)代表一个不同的任务,横轴是假阳性率(False Positive Rate),纵轴是真阳性率(True Positive Rate)。AUROC(Area Under the Receiver Operating Characteristic Curve)值用于衡量模型的整体性能,值越接近1表示性能越好。
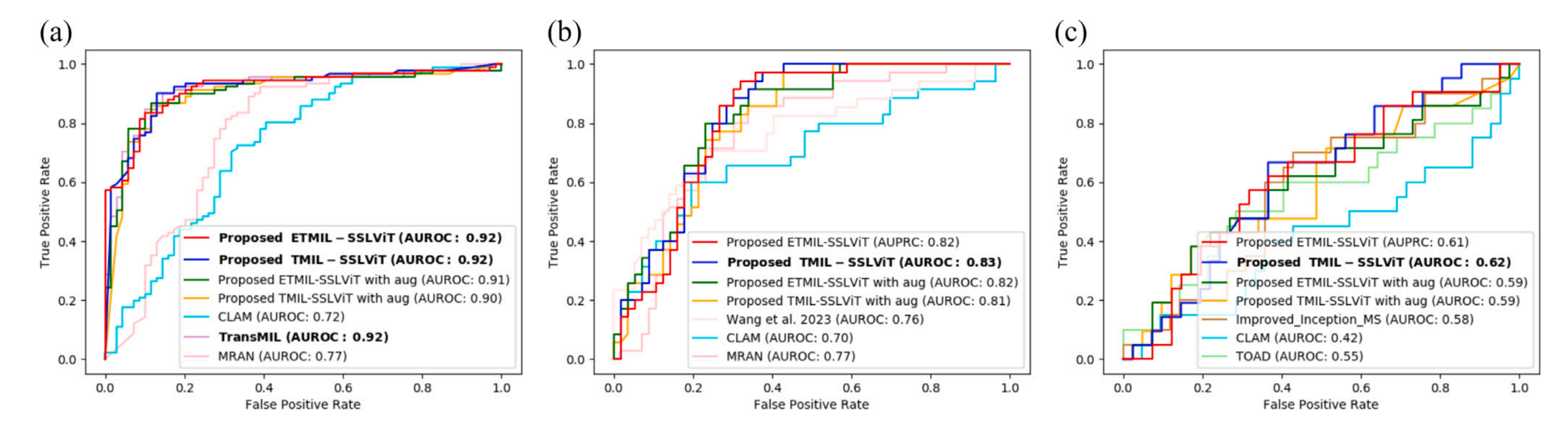
(a) EC亚型分类(侵袭性 vs 非侵袭性)
- Proposed ETMIL-SSLViT 和 Proposed TMIL-SSLViT 表现最佳,AUROC值分别为0.92和0.92,表明这两种方法在区分侵袭性和非侵袭性EC亚型方面非常有效。
- Proposed TMIL-SSLViT with aug 和 Proposed ETMIL-SSLViT with aug 也表现良好,AUROC值分别为0.91和0.91。
- TransMIL 和 MRAN 的AUROC值分别为0.92和0.77,其中TransMIL表现优异,而MRAN相对较差。
(b) 侵袭性亚型中的TMB状态预测
- Proposed ETMIL-SSLViT 和 Proposed TMIL-SSLViT 再次表现最佳,AUROC值分别为0.82和0.83。
- Proposed ETMIL-SSLViT with aug 和 Proposed TMIL-SSLViT with aug 的AUROC值分别为0.82和0.81,略低于未增强的版本。
- Wang et al. 2023 和 CLAM 的表现较差,AUROC值分别为0.76和0.70。
© 非侵袭性亚型中的TMB状态预测
- Proposed ETMIL-SSLViT 和 Proposed TMIL-SSLViT 的AUROC值分别为0.61和0.62,表现相对较好,但不如在侵袭性亚型中的表现。
- Proposed ETMIL-SSLViT with aug 和 Proposed TMIL-SSLViT with aug 的AUROC值分别为0.59和0.59,表现略差。
- CLAM 和 TOAD 的表现最差,AUROC值分别为0.42和0.55。
总结
- Proposed ETMIL-SSLViT 和 Proposed TMIL-SSLViT 在所有任务中均表现出色,尤其是在EC亚型分类任务中。
- 增强方法(with aug) 在侵袭性亚型中的TMB状态预测任务中表现略逊于未增强的版本。
- 非侵袭性亚型中的TMB状态预测 对所有方法来说都是一个挑战,因为AUROC值普遍较低,表明这一任务的难度较大。
这些结果强调了不同方法在处理不同癌症亚型和TMB状态预测任务时的适用性和有效性,为未来的研究和临床应用提供了重要的参考。
4-3:定量评估比较模型选择机制在食管癌亚型分类中的应用
这张表格展示了在子宫内膜癌(EC)亚型分类任务中,不同模型选择指标和骨干网络(Backbone)的性能比较。

表格中列出了每种方法的准确率(Accu.)、敏感性(Sens.)、特异性(Spec.)和MeanSS(敏感性和特异性的平均值)。
分析
- 模型选择指标:
- Cross Entropy、MeanSS、Macro F1-Score 和 F1-Score 被用作模型选择的指标。
- 骨干网络:
- ResNet50:由He等人在2016年提出,是一种常用的深度学习模型,用于图像识别任务。
- 性能指标:
- 准确率(Accu.):所有方法的准确率都在0.82到0.86之间,表明模型在分类任务中的整体表现良好。
- 敏感性(Sens.):敏感性在0.75到0.90之间,表明模型在识别正类(侵袭性EC亚型)方面的能力。
- 特异性(Spec.):特异性在0.80到0.91之间,表明模型在识别负类(非侵袭性EC亚型)方面的能力。
- MeanSS:是敏感性和特异性的平均值,提供了一个综合的性能指标。
- 最佳性能:
- F1-Score 作为模型选择指标时,结合ResNet50骨干网络,达到了最高的MeanSS值0.85,表明在平衡敏感性和特异性方面表现最佳。
结论
- F1-Score 作为模型选择指标时,能够提供最佳的综合性能,尤其是在平衡敏感性和特异性方面。
- 使用ResNet50作为骨干网络,结合不同的模型选择指标,可以有效地进行EC亚型的分类。
- 这些结果为选择最佳的模型和指标提供了依据,有助于提高EC亚型分类的准确性和可靠性。
总的来说,这张表格提供了关于不同模型选择指标和骨干网络在EC亚型分类任务中的性能比较,有助于研究者和临床医生选择最适合的模型进行疾病诊断和研究。
4-4:比较所提出方法在使用不同特征提取方法对食管癌样本的性能表现
这张表格(Table 4)比较了在子宫内膜癌(EC)样本中使用不同特征提取方法的提议方法的性能。
表格中列出了每种方法的准确率(Accu.)、敏感性(Sens.)、特异性(Spec.)和MeanSS(敏感性和特异性的平均值)。
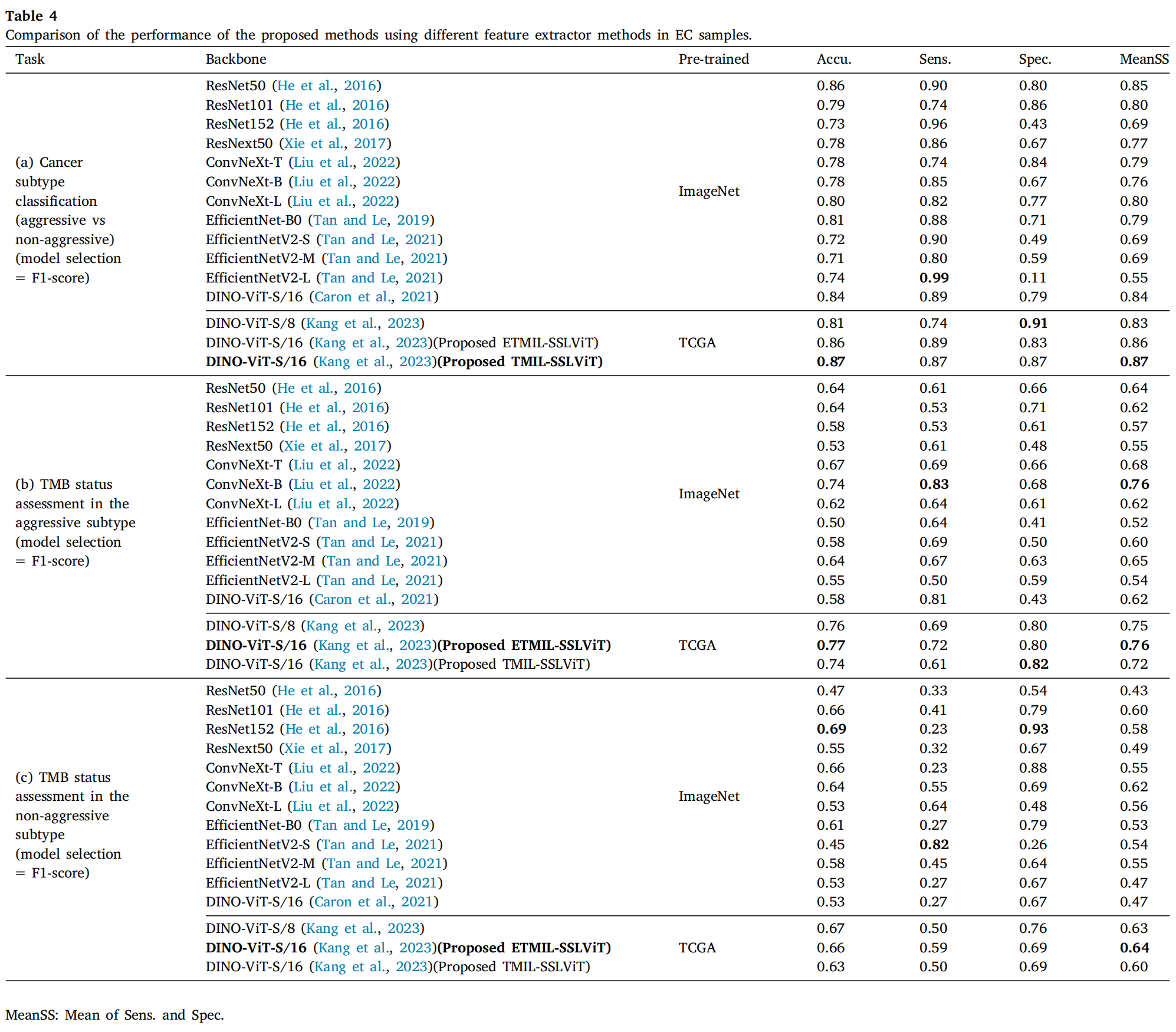
分析
-
任务分类:
- (a) 癌症亚型分类:区分侵袭性和非侵袭性癌症亚型。
- (b) 侵袭性亚型中的TMB状态评估:在侵袭性亚型中评估肿瘤突变负荷(TMB)状态。
- © 非侵袭性亚型中的TMB状态评估:在非侵袭性亚型中评估TMB状态。
-
骨干网络:
- 包括ResNet50、ResNet101、ResNet152、ResNext50、ConvNeXt-T、ConvNeXt-B、ConvNeXt-L、EfficientNet-B0、EfficientNetV2-S、EfficientNetV2-M、EfficientNetV2-L、DINO-ViT-S/16和DINO-ViT-S/8等。
- 一些模型使用了ImageNet或TCGA数据集进行预训练。
-
性能指标:
- 准确率(Accu.):大多数方法的准确率在0.64到0.87之间,表明模型在分类任务中的整体表现。
- 敏感性(Sens.):敏感性在0.27到0.99之间,表明模型在识别正类(如侵袭性EC亚型或高TMB状态)方面的能力。
- 特异性(Spec.):特异性在0.11到0.96之间,表明模型在识别负类(如非侵袭性EC亚型或低TMB状态)方面的能力。
- MeanSS:是敏感性和特异性的平均值,提供了一个综合的性能指标。
-
最佳性能:
- 在癌症亚型分类任务中,DINO-ViT-S/16(Kang et al.,2023)(Proposed TMIL-SSLViT)达到了最高的MeanSS值0.87。
- 在侵袭性亚型中的TMB状态评估任务中,DINO-ViT-S/16达到了最高的MeanSS值0.76。
- 在非侵袭性亚型中的TMB状态评估任务中,DINO-ViT-S/16达到了最高的MeanSS值0.64。
结论
- DINO-ViT-S/16和DINO-ViT-S/8 在所有任务中均表现出色,尤其是在侵袭性亚型中的TMB状态评估任务中。
- ResNet152 在癌症亚型分类任务中表现较差,特别是在特异性方面。
- EfficientNetV2-L 在非侵袭性亚型中的TMB状态评估任务中表现不佳,敏感性特别低。
这些结果强调了不同特征提取方法在处理不同EC亚型和TMB状态预测任务时的适用性和有效性,为未来的研究和临床应用提供了重要的参考。
4-5:将所提出的框架与各种基于SSL的骨干网络在食管癌亚型分类中进行比较
这张表格(Table 5)展示了在子宫内膜癌(EC)亚型分类任务中,使用不同自监督学习(SSL)方法和骨干网络的性能比较。
表格中列出了每种方法的准确率(Accu.)、精确率(Prec.)、敏感性(Sens.)、F1分数(F1-S.)、特异性(Spec.)和MeanSS(敏感性和特异性的平均值)。

分析
-
SSL方法:
- 包括BT、MoCoV2、SwAV和DINO等,这些方法都是基于自监督学习的框架,用于特征提取和表示学习。
-
骨干网络:
- 使用了ResNet50和Vision Transformer(ViT)的不同变体,如ViT-S/8和ViT-S/16。
-
预训练数据集:
- 所有方法都在TCGA(The Cancer Genome Atlas)数据集上进行了预训练,这是一个公共的癌症基因组学数据库。
-
性能指标:
- 准确率(Accu.):大多数方法的准确率在0.81到0.87之间,表明模型在分类任务中的整体表现良好。
- 精确率(Prec.):精确率在0.83到0.92之间,表明模型在预测正类时的准确性。
- 敏感性(Sens.):敏感性在0.74到0.90之间,表明模型在识别正类(侵袭性EC亚型)方面的能力。
- F1分数(F1-S.):F1分数在0.82到0.88之间,提供了精确率和召回率的平衡度量。
- 特异性(Spec.):特异性在0.76到0.91之间,表明模型在识别负类(非侵袭性EC亚型)方面的能力。
- MeanSS:是敏感性和特异性的平均值,提供了一个综合的性能指标。
-
最佳性能:
- DINO (Kang et al., 2023) 使用ViT-S/16骨干网络时,达到了最高的MeanSS值0.87,表明在平衡敏感性和特异性方面表现最佳。
- DINO (Kang et al., 2023) 使用ViT-S/8骨干网络时,也表现出色,MeanSS值为0.83。
结论
- DINO方法 结合ViT-S/16骨干网络在EC亚型分类任务中表现最佳,特别是在平衡敏感性和特异性方面。
- ResNet50 作为骨干网络时,MoCoV2和SwAV方法的性能也相当接近,但略低于DINO方法。
- 这些结果强调了自监督学习方法在医学图像分类任务中的潜力,尤其是在处理复杂的生物医学数据时。
总的来说,这张表格提供了关于不同自监督学习方法和骨干网络在EC亚型分类任务中的性能比较,有助于研究者和临床医生选择最适合的模型进行疾病诊断和研究。
4-6:使用不同的基于SSL的骨干网络对所提出框架的运行时间进行分析
这张表格(Table 6)提供了使用不同自监督学习(SSL)方法和骨干网络在特征提取和AI推理中的运行时间分析。
表格分为两部分:(a) 数据大小(b)特征提取时间,以及 © AI推理时间和(d) AI训练时间。
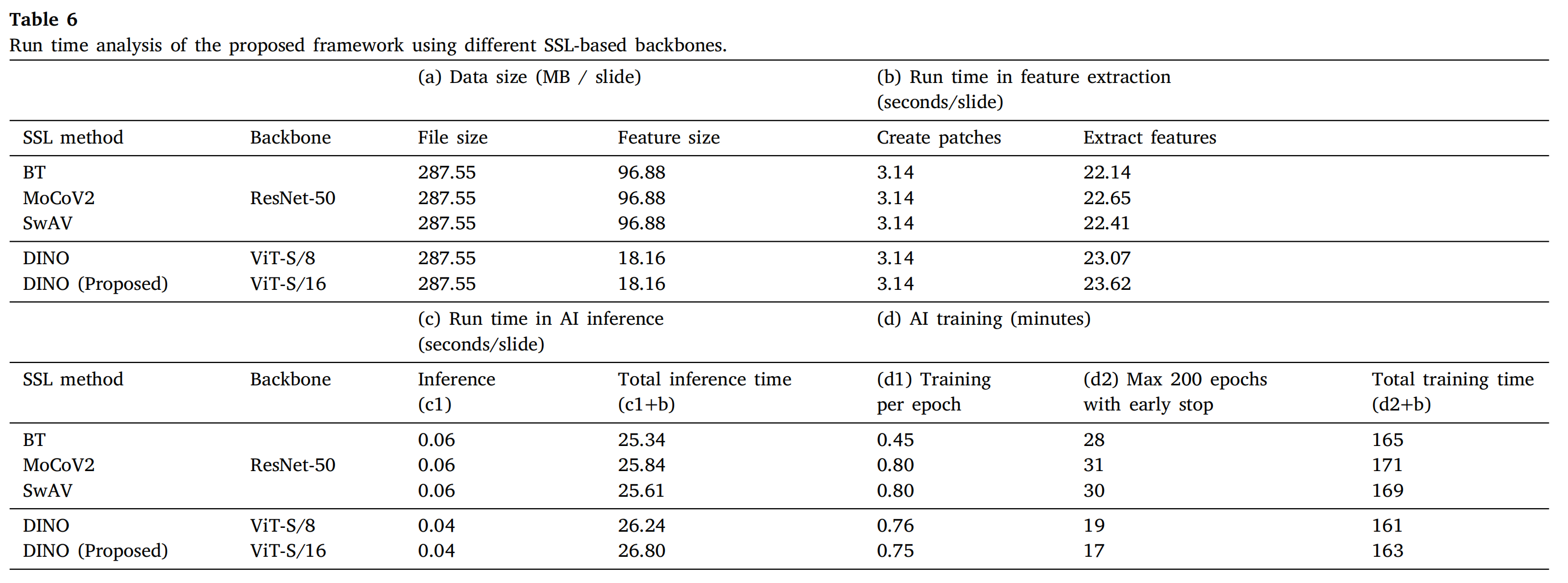
(a&b) 数据大小和特征提取时间
- 文件大小:所有方法的文件大小均为287.55 MB/slide,这表明输入数据的尺寸是一致的。
- 特征大小:ResNet-50骨干网络的特征大小为96.88 MB,而ViT-S/8和ViT-S/16骨干网络的特征大小显著较小,为18.16 MB。这表明ViT骨干网络在特征提取时更为高效。
- 创建补丁时间:所有方法在创建补丁上的时间相同,为3.14秒/slide。
- 提取特征时间:使用ResNet-50的BT、MoCoV2和SwAV方法的提取特征时间分别为22.14、22.65和22.41秒/slide,而使用ViT-S/8和ViT-S/16的DINO方法的提取特征时间稍长,分别为23.07和23.62秒/slide。
© AI推理时间
- 推理时间(c1):ViT-S/8和ViT-S/16的DINO方法的推理时间最短,为0.04秒/slide,而ResNet-50的BT、MoCoV2和SwAV方法的推理时间为0.06秒/slide。
- 总推理时间(c1+b):包括特征提取和推理时间,DINO方法的总时间较短,ViT-S/8为26.24秒/slide,ViT-S/16为26.80秒/slide。
(d) AI训练时间
- 每轮训练时间(d1):DINO方法的每轮训练时间较短,ViT-S/8为0.76分钟,ViT-S/16为0.75分钟。
- 最大200轮训练与早停(d2):DINO方法在早停策略下的训练轮数较少,ViT-S/8为19轮,ViT-S/16为17轮。
- 总训练时间(d2+b):包括训练和推理时间,DINO方法的总训练时间较短,ViT-S/8为161分钟,ViT-S/16为163分钟。
结论
- DINO方法,特别是使用ViT-S/8和ViT-S/16骨干网络的版本,在特征提取、AI推理和训练时间上均表现出较高的效率。
- ViT骨干网络在特征大小上更为紧凑,可能有助于减少存储和处理需求。
- 早停策略在DINO方法中有效地减少了训练时间,同时保持了模型性能。
这些结果表明,DINO方法结合ViT骨干网络在处理时间和效率方面具有优势,这对于需要快速处理大量数据的临床应用场景尤为重要。
4-7:将所提出的方法与不同的优化器在食管癌亚型分类中进行比较
这张表格(Table 7)展示了在子宫内膜癌(EC)亚型分类任务中,使用不同优化器的性能比较。
表格中列出了每种方法的准确率(Accu.)、精确率(Prec.)、敏感性(Sens.)、F1分数(F1-S.)、特异性(Spec.)和MeanSS(敏感性和特异性的平均值)。

分析
-
损失函数:所有方法均使用交叉熵(Cross Entropy)作为损失函数。
-
骨干网络:使用的是DINO-ViT-S/16,预训练数据集为TCGA。
-
优化器:
- lookahead+Radam
- Radam
- lookahead+Adam
- Adam
- lookahead+RMSProp
- RMSProp
-
性能指标:
- 准确率(Accu.):从0.80到0.87不等,表明模型在分类任务中的整体表现。
- 精确率(Prec.):从0.85到0.90不等,表明模型在预测正类时的准确性。
- 敏感性(Sens.):从0.76到0.87不等,表明模型在识别正类(侵袭性EC亚型)方面的能力。
- F1分数(F1-S.):从0.82到0.88不等,提供了精确率和召回率的平衡度量。
- 特异性(Spec.):从0.80到0.89不等,表明模型在识别负类(非侵袭性EC亚型)方面的能力。
- MeanSS:是敏感性和特异性的平均值,提供了一个综合的性能指标。
-
最佳性能:
- 使用lookahead+RMSProp优化器时,模型达到了最高的精确率(0.90)和F1分数(0.83),并且特异性(0.89)也是最高的。
- 使用lookahead+Radam优化器时,模型的MeanSS值最高,为0.87,表明在平衡敏感性和特异性方面表现最佳。
结论
- lookahead+RMSProp 和 lookahead+Radam 优化器在EC亚型分类任务中表现出色,特别是在精确率、F1分数和MeanSS方面。
- lookahead 策略似乎对提高模型性能有积极影响,因为它在多个指标上都显示出较好的结果。
- 这些结果表明,选择合适的优化器对于提高模型在特定任务上的性能至关重要。
总的来说,这张表格提供了关于不同优化器在EC亚型分类任务中的性能比较,有助于研究者和临床医生选择最适合的模型进行疾病诊断和研究。
4-8:比较所提出的方法与不同损失函数在食管癌亚型分类中的应用
这张表格(Table 8)比较了在子宫内膜癌(EC)亚型分类任务中,使用不同损失函数的性能。
表格中列出了每种方法的准确率(Accu.)、精确率(Prec.)、敏感性(Sens.)、F1分数(F1-S.)、特异性(Spec.)和MeanSS(敏感性和特异性的平均值)。

分析
-
优化器:所有方法均使用lookahead+Radam优化器。
-
损失函数:
- 交叉熵(Cross Entropy)
- 焦点损失(Focal Loss)
- 均方误差(MSE)
-
性能指标:
- 准确率(Accu.):交叉熵损失函数的准确率最高,为0.87,而焦点损失和MSE的准确率分别为0.66和0.57。
- 精确率(Prec.):交叉熵损失函数的精确率最高,为0.90,焦点损失和MSE的精确率分别为0.71和0.59。
- 敏感性(Sens.):MSE损失函数的敏感性最高,为0.90,交叉熵和焦点损失的敏感性分别为0.87和0.68。
- F1分数(F1-S.):交叉熵损失函数的F1分数最高,为0.88,焦点损失和MSE的F1分数分别为0.70和0.71。
- 特异性(Spec.):交叉熵损失函数的特异性最高,为0.87,焦点损失和MSE的特异性分别为0.63和0.13。
- MeanSS:交叉熵损失函数的MeanSS值最高,为0.87,焦点损失和MSE的MeanSS值分别为0.65和0.51。
结论
- 交叉熵损失函数在所有性能指标上均表现最佳,特别是在精确率、F1分数和特异性方面,表明它在区分EC亚型方面非常有效。
- 焦点损失在敏感性上表现尚可,但精确率和特异性较低,可能需要进一步调整以提高性能。
- MSE损失函数在敏感性上表现突出,但特异性极低,这可能表明它在区分正负类时存在问题。
总的来说,这张表格提供了关于不同损失函数在EC亚型分类任务中的性能比较,有助于研究者和临床医生选择最适合的模型进行疾病诊断和研究。交叉熵损失函数在这项任务中显示出了其优越性。
4-9:在食管癌亚型分类中,对所提出的方法在五个独立来源站点上的评估
这张表格(Table 9)展示了在五个独立的数据源上对EC亚型分类任务中提出的两种方法的性能评估。
表格中列出了每种方法的平均准确率(Accu.)、精确率(Prec.)、敏感性(Sens.)、F1分数(F1-S.)、特异性(Spec.)和MeanSS(敏感性和特异性的平均值),以及它们的标准差(STD)。

分析
- ETMIL-SSLViT 在所有性能指标上均优于TMIL-SSLViT,特别是在准确率、精确率、F1分数和MeanSS方面。
- TMIL-SSLViT 的特异性较低,这可能表明该方法在区分阴性样本时的性能不如ETMIL-SSLViT。
- ETMIL-SSLViT 的MeanSS值较高,表明它在敏感性和特异性之间取得了较好的平衡。