机器人操作课题涉及与环境中物体的复杂交互,而如何有效地表示这些交互中的约束是关键问题。斯坦福大学AI团队发表的论文“ReKep: Spatio - Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation”的论文提出的创新方法,为机器人操作带来了新的突破。该方法将机器人操作任务表示为约束,通过关键点映射的方式实现。ReKep 可分解任务为多阶段约束,能自动从RGB-D的观察和语言指令中获取关键点和约束的信息,在轮式单臂和固定式双臂平台上进行实验。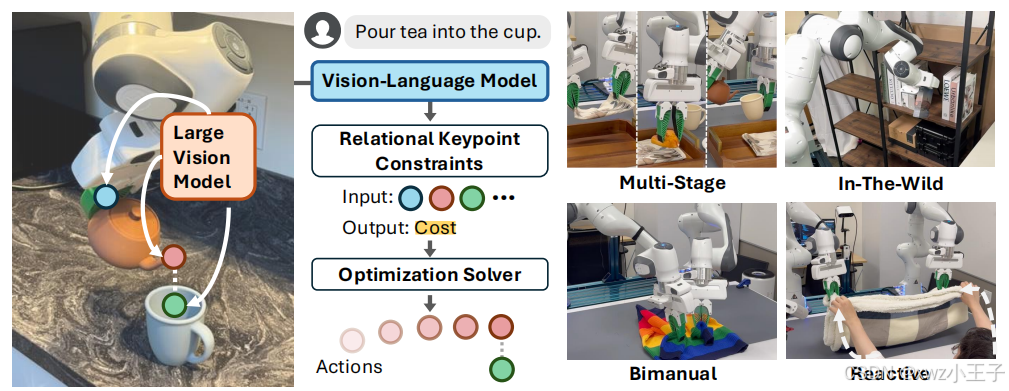
▲图1|Relational Keypoint Constraints (ReKep)©️传统的方法在处理多样性任务、自动化标注和实时优化等方面存在挑战。例如,使用相对姿势来表示约束的方法虽然直接且广泛使用,但刚性变换无法描绘几何细节,需要事先获取物体模型,且不能处理可变形物体。而数据驱动的方法虽然更灵活,但随着约束数量的增加,如何有效地收集训练数据是很大的难题。基于此,研究人员提出了一个问题:如何表示机器人操作中的约束,使其能够广泛应用于各种任务,具有可扩展性,并能够通过现成的求解器进行实时优化,以适应复杂的操作行为?为了解决上述问题,研究人员提出了Relational Keypoint Constraints(ReKep)。具体来说,ReKep将约束表示为Python函数,该函数将一组关键点映射到一个数值,其中每个关键点是场景中对应特定任务和语义、且有意义的3D点。每个函数由关键点上的(可能是非线性的)运算组成,编码了它们之间所需的“关系”,这些关键点可能属于环境中的机器人手臂、物体部件和其他主体。然而,一个操作任务通常涉及多个空间关系,并可能包含多个时间阶段,每个阶段都包含不同的空间关系。为了应对这一挑战,研究人员将任务分解为N个阶段,并使用ReKep为每个阶段i指定两种约束。以倒茶任务为例,该任务包括三个阶段:抓取、对齐和倾倒。阶段1的子目标约束会将末端执行器拉向茶壶手柄。然后,阶段2的子目标约束规定茶壶嘴需要在杯子开口的上方。此外,阶段2的路径约束会确保茶壶在运输过程中保持直立以避免溢出。最后,阶段3的子目标约束指定了所需的倾倒角度。
▲图2|实验任务和优化结果的视觉化展示©️【深蓝AI】编译■4.1 关键点选取
实验会给定一个RGB图像,再使用DINOv2提取补丁特征,并通过双线性插值将其采样到原始图像大小。然后,使用Segment Anything(SAM)提取场景中的所有标记。对于每个标记,研究人员使用PCA将特征投影到三个维度,并使用k-means聚类(k = 5)来获取聚类中心。这些中心将作为关键点的“候选“,研究人员会使用校准的RGB - D相机将其投影到世界坐标中。在”候选点“中,距离在8cm以内的点会被过滤掉,以确保识别出大部分粒度精细,且语义有意义的物体区域。■4.2 约束生成获得关键点候选后,研究人员将它们与数值标记一起叠加在原始RGB图像上。然后,再将图像和任务指令输入到GPT - 4o中,使用特定的 prompt 来生成所需的阶段数以及每个阶段对应的子目标约束和路径约束。GPT - 4o基于其内部的世界知识来生成这些约束。函数不直接操作关键点位置的数值,而是利用VLM的优势将空间关系指定为关键点之间的算术运算,如L2距离或点积。而只有当使用专门的 3D 跟踪器所跟踪的实际关键点位置被调用时,它们才会被实例化。此外,该实验可以使用算术运算来指定3D旋转,从而使VLM能够在3D笛卡尔空间中通过算术运算来推理3D旋转,避免了处理其他3D旋转中用于”表示“和进行数值计算的需要。■4.3 动作优化为了根据生成的约束获得机器人末端执行器在SE中的密集动作序列,研究人员采用了一种分解和算法实例化的方法。具体来说,该实验将控制问题形式转化为一个优化问题,通过求解一系列的子目标和路径问题来获得末端执行器的轨迹。在每个控制循环中,首先解决子目标问题以获得当前阶段的子目标,同时考虑辅助控制成本,如场景碰撞避免、可达性、解决方案一致性和双手设置时的自碰撞等。然后再解决路径问题,即从当前末端执行器姿态到子目标生成一条轨迹,同时满足路径约束和成本控制。如果到子目标的距离在一个小的容忍范围内,则可以进入下一个阶段。此外,该实验设计还引入了回退机制,以应对阶段间的重新规划,例如当最后一个阶段的任何子目标约束不再满足时(如在倒茶任务中杯子从夹具中取出),系统会回退到一个满足路径约束的先前阶段。为了验证ReKep的有效性,研究人员在两个真实机器人平台上进行了实验:一个轮式单臂平台和一个固定式双臂平台。实验任务包括倒茶、存放书籍、回收罐子、封装盒子、折叠衣物、包装鞋子和协作折叠等,旨在检验系统的多阶段、野外、双手和反应性行为。实验结果表明,ReKep能够有效地处理每个任务的核心挑战。例如,在倒茶任务中,它能够制定正确的时间依赖关系,在多阶段任务中使茶壶嘴在倾倒前与杯子对齐,并利用常识知识(如可乐罐应回收)。在双手操作设置中,它能够构建协调行为,例如同时折叠衣物的左右袖子或在与人类协作时对齐大毯子的四角。此外,结合优化框架,它能够在存放书籍任务中在受限空间中生成具有挑战性的行为,并在包装鞋子任务中找到一个可行的解决方案,将两只鞋子紧密地放入一个小体积中。由于关键点以高频率跟踪,系统还能够对外部干扰做出反应,并进行重新规划。然而,实验结果也表明,生成的约束并不总是完全正确的,但随着预训练模型的快速发展,有望得到改善。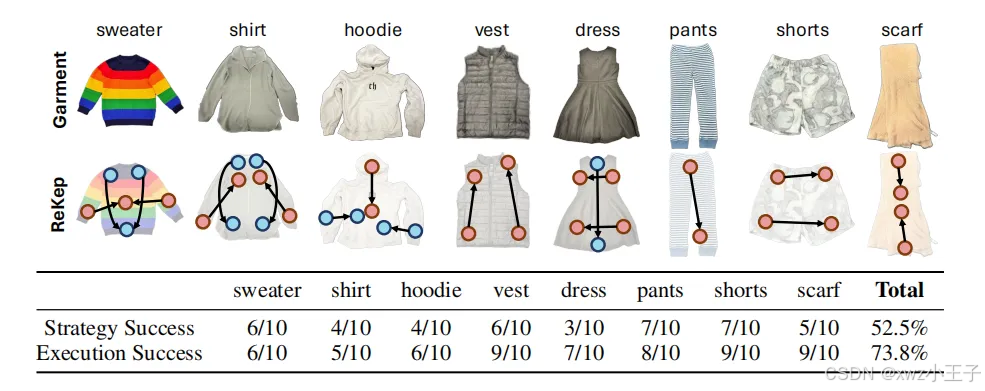
▲图3|ReKep折叠不同类别服装的新型“双手”策略及其成功比率©️【深蓝AI】编译尽管ReKep取得了一定的成果,但仍存在一些局限性。首先,优化框架依赖于基于刚性假设的关键点前向模型,尽管高频反馈循环放松了对模型精度的要求,但仍然存在一定的局限性。其次,ReKep依赖于精确的点跟踪来正确优化闭环中的动作,但由于间歇性遮挡等问题,点跟踪本身就是一个具有挑战性的3D视觉任务。最后,当前的公式假设每个任务的阶段序列是固定的,重新规划不同的骨架需要在高频下运行关键点提议和VLM,这带来了相当大的计算挑战。未来的研究可以进一步改进和完善ReKep,以应对实际应用中的各种挑战。例如,可以探索更先进的点跟踪技术,以提高系统在复杂环境中的鲁棒性。此外,还可以研究如何更好地将ReKep应用于具有关节的物体操作,以扩展其应用范围。总的来说,这项研究为机器人操作领域带来了新的思路和方法,有望推动机器人技术在更多领域的应用和发展。我们期待着看到ReKep在未来的进一步发展和应用,为我们的生活带来更多的便利和创新。
斯坦福大学李飞飞教授团队最新研究:聚焦机器人抓取交互,让机器人操作真正地适应各种环境
猜你喜欢
转载自blog.csdn.net/weixin_44887311/article/details/143107040
今日推荐
周排行