Machine Learning(7)Neural network —— optimization techniques I
Chenjing Ding
2018/02/27
| notation | meaning |
|---|---|
| g(x) | activate function |
| the n-th input vector (simplified as when n is not specified) | |
| the i-th entry of (simplified as when n is not specified) | |
| N | the number of input vectors |
| K | the number of classes |
| a vector with K dimensional with k-th entry 1 only when the n-th input vector belongs to k-th class, tn = (0,0,…1…0) | |
| the output of j-th output neural | |
| a output vector of input vector x; | |
| the ( )-th update of weight | |
| the -th update of weight | |
| the gradient of m-th layer weight | |
| the number of neural in i-th layer(simplified as l when i is not specified) | |
| the weight between layer m and n |
1. Regularization
To avoid overfitting:
is regularizers:L2 regularizer is ; L1 regularizer is ;
is regularization parameter;
This means every weight can not be too big, thus the model cannot be too complex including so many useless features.
1.what is L1, L2 regularization :
https://www.youtube.com/watch?v=TmzzQoO8mr4 (Chinese)2.Regularization and Cost Function
https://www.youtube.com/watch?v=KvtGD37Rm5I&list=PLLssT5z_DsK-h9vYZkQkYNWcItqhlRJLN&index=40
2.Normalizing the Inputs
Convergence is faster if:
- the mean of all input data is 0
,weights can only change together if input vector are all positive ao negative, thus it will lead to slow convergence. - the variance of all input data is the same
- all input data are not correlated if possible (using PCA to decorrelate them)
if the input are correlated, the direction of steepest descent is not optimal, maybe perpendicular to the direction towards the minimum.
3.Commonly Used Nonlinearities
??????????????The activation function is often nonlinear, here are some.
logistic sigmoid
tanh
扫描二维码关注公众号,回复: 3817152 查看本文章
Advantages: compared with logistic sigmoidalready centred at zero , thus often converge faster than the standard logistic sigmoid.
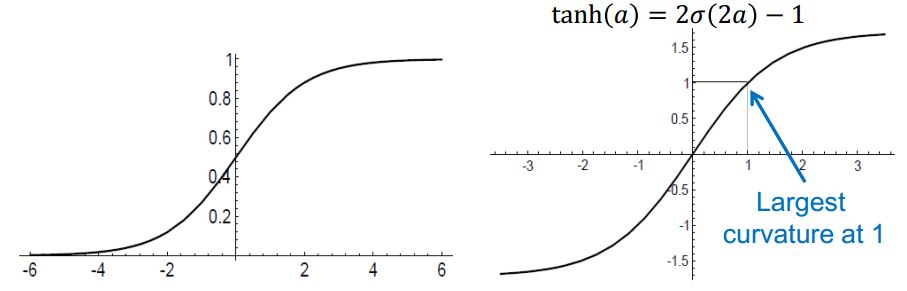
figure1 nonlinear activation function(left: logistic sigmoid; right: tanh)
softmax
ReLU
Advantages:thus gradient will be passed with a constant factor( ), make it easier to propagate gradient through deep networks.( Imagine , then will be smaller and smaller with the networks deep, finally the gradient will be close to zero)
don’t need to store ReLU output separately
Reduction of the required memory by half compared with tanh!
Because of these two features,ReLU has become the de-facto standard for deep networks.
Disadvantages:
stuck at zero, if the output of ReLU is zero for the input vector, then the concerned gradient can not be passed to next layer down since it is zero.
Offset bias since it is always positive.
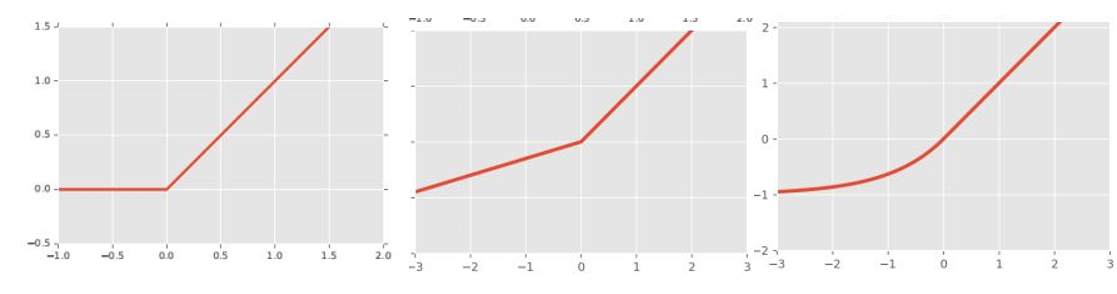
Leaky ReLU
Advantages:avoid “stuck at zero”
weaker offset bias.
ELU
no offset bias but needs to store the activation.
figure2 left:ReLU middle: Leaky ReLU right: ELUusage of nonlinear function
Output nodes
2 class classfication: sigmoid
multi-class classification: softmax
regression tasks: tanhInternal nodes
tanh is better than sigmoid for internal nodes since it is already centered at 0;
4.Weight Initialization
If we normalize all the input data, we also want to reserve the variance of input data because that the output data which is the input data of next layer again will have the same variance. As a result, convergence will be faster.
Thus our goal is to let variance of input data and output data be same.
if the mean of input data and weights are zero and they are identical independent distributed
4.1 Glorot Initialization
If
;
is the number of input neural linked to j-th output neural. If we do the same for the backpropagated gradient (
), then
.
The glorot initialization is:
4.2 He Initialization
The glorot initialization was based on tanh(centred at 0), He et al. made the derivations, proposed to use instead based on ReLU:
5.Stochastic and Batch learning
In Gradient Descent, the last step is to adjust weights in the direction of gradients. The equation is:
5.1 Batch learning
Process the full data at once to computer the gradient.
5.2 Stochastic learning
Choose a single training sample
to obtain
;
5.3 Stochastic vs. Batch Learning
5.3.1 Batching learning advantages
- Many acceleration techniques (e.g., conjugate gradients) only operate in batch learning.
- Theoretical analysis of the weight dynamics and convergence rates are simpler.
5.3.2 Stochastic advantages
- Usually much faster than batch learning.
- Often results in better solutions.
- Can be used for tracking changes.
5.4 Minibatch
Minibatch combine two methods above together, process only a small batch of training examples together.
5.4.1 Advantages
- more stable than stochastic learning but faster than batch learning
- take advantage of redundancies in training data(some training sample can appear in different mini batches)
- the input data is matrix since it’s the combination of input vector, and matrix operations is more efficient than vector operations
5.4.2 Caveat
The error function needs to be normalized by minibatch size because we want to keep the learning rate same in different minibatches. Suppose M is the minibatch size: