Machine Learning(7)Neural network —— Perceptrons
Chenjing Ding
2018/02/21
| notation | meaning |
|---|---|
| g(x) | activate function |
| the n-th input vector (simplified as when n is not specified) | |
| the i-th entry of (simplified as when n is not specified) | |
| N | the number of input vectors |
| K | the number of classes |
| a vector with K dimensional with k-th entry 1 only when the n-th input vector belongs to k-th class, tn = (0,0,…1…0) | |
| the output of j-th output neural | |
| a output vector of input vector x; | |
| the ( )-th update of weight | |
| the -th update of weight | |
| the gradient of m-th layer weight | |
| the number of neural in i-th layer | |
| the weight between layer m and n |
1. two layers perceptron
1.1 construction
2 layers refers to output layer and input layer; the basic construction of 2 layers perceptron is as followed:
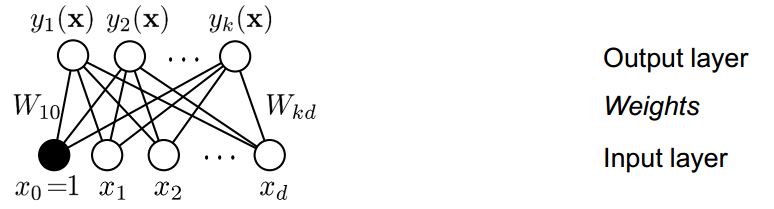
figure1 the construction of 2 layers perceptron
input layer:
d neural, d is the dimensional of an input vector x; The input layer can applied with non-linear basic functions
.
Weights:
, j is the index of neural in output layer;i is the index of neural in input layer;
Output layer:
There are k classes, so there are k output functions. The output layer can applied with activate function g(x).
1.2 Learning: How to get
Gradient descent with sequential updating can be used to minimize the error function E(W) to adjust weights.
step1: set up an error function E(W);
if we use L2 loss,
step2: calculate ;
step3: sequential updating, is the learning rate;
Thus, perceptron learning corresponds to Gradient Descent of a quadratic error function.
- effor function more details:
- sequential updating and delta rule:
- Gradient descent
1.3 properties of 2 layers perceptron
it can only represent the linear function since
the discriminant boundary is always linear in input space x or input space when input layer applied with , to be specific, the boundary can be a line, a plane and can not be a curve and so on. However, multi layers perceptron with hidden units can represent any continuous functions. 2. multi layers perceptronand are given before; They are fixed functions.
There is always bias item in the linear discriminant function; (y = ax+b,b is the bias item and it has nothing to do with input x), thus the input layer always have d+1 input neural and the is always 1, in a result ;
2 multi layers perceptron
There are some hidden layers between input layer and output layer.
For example, perceptron with one hidden layer as followed,
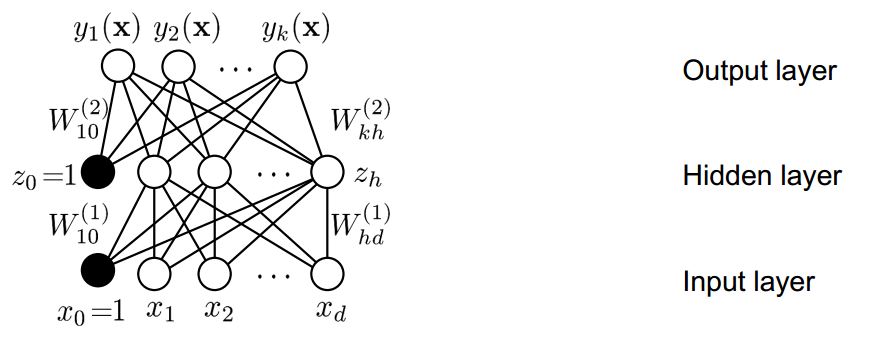
figure2 the construction of multi layers perceptron
output:
In 1.2 we know how to learn the weight of 2 layers perceptron. As the same way, for multi layers, we also need to find the error function and using Gradient Decent to update all weights, but computing the gradient is more complex. So here are 2 main steps:
step1: computing the gradient
2.1Backpropogation
step2: adjusting the weight in the direction of gradient, same as 1.2 step3, we well later focus on some optimization techniques to improve the performance
Machine Learning(7)Neural network–optimization techniques
2.1 Backpropagation
2.1.1 How to use backpropagation
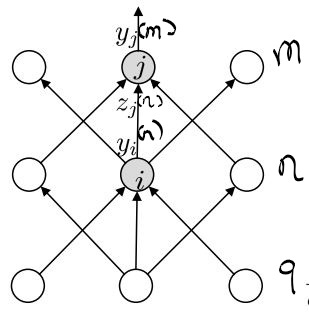
figure3 the construction of multi layers perceptron
if the id of layer is m, n and q form top to bottom, the number of neural in each layer is and ; between 2 layers, the above layer is always the output layer with index of neural j and similarly, the bottom layer is always the input layer with i;
Our goal is to obtain the gradient of
:
2.1.2 Why use backpropagation with reverse-mode differentiation
For all adjacent layers m and n, There are 2 ways to calculate . To simplify, suppose we want to calculate , one way is to apply operator to every node, which is called Forward-Mode Differentiation. The other way is to apply operator called reverse-mode differentiation;
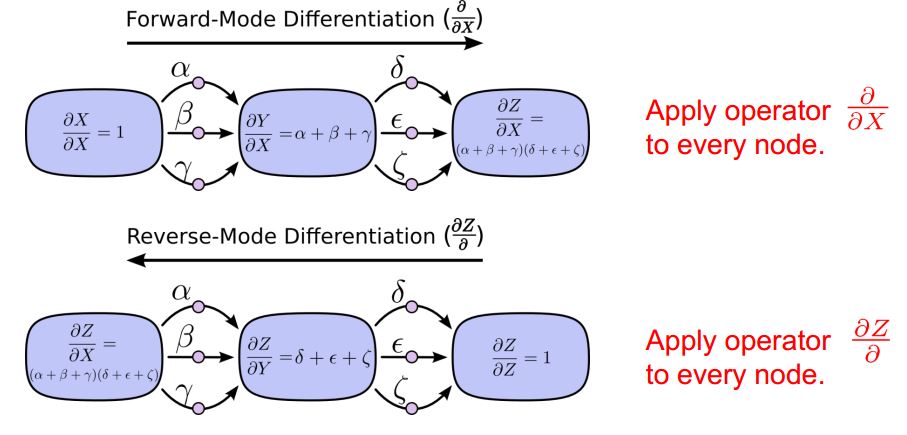 *figure4 computation graph* *1: Forward - Mode - Differentiate*
*figure4 computation graph* *1: Forward - Mode - Differentiate*
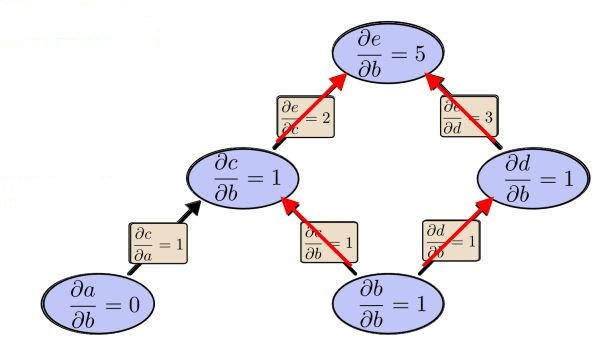 *figure5 Forward - Mode - Differentiate computation graph*
*figure5 Forward - Mode - Differentiate computation graph*
Forward-mode-differentiate apply operator
to every node, in our cases, the operator is
if the goal is to obtain
;the id of first layer down is 0;
thus we need to visit every layer only to get , when it comes to ,we need to visit every layer again!
2: reverse-mode differentiation
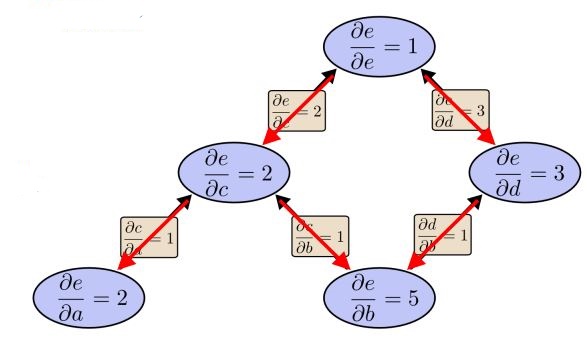
figure6 Reverse-mode differentiation computation graph
From the graph above, only one pass we know
to all nodes. It is more efficient than Forward-mode-differentiate.
Reverse-mode differentiation apply
to every node, in our case, it is
;That is to say,
are calculated in order.
Then
are also obtained ; As mentioned above,
is the id of neural in m-th layer when this layer is input layer,
can be 0 to
;
is in similar way.
From all above, Reverse-mode differentiation can compute all derivatives in one single pass, that is why we use Back-propagation with reverse-mode differentiation;
Next topic will introduce some optimization techniques and how to implement these ideas with python.