写在前面
这篇关于VLN的论文在2019年CVPR评审过程中得分很高, 用到了强化学习. luffy对强化学习比较感兴趣并想进一步深入学习和研究, 就对这篇论文进行了粗浅的阅读(水平有限, 暂时无法深入理解). 主要对摘要和介绍进行了翻译.
Abstract
- Vision-language navigation (VLN) is the task of navigating an embodied agent to carry out natural language instructions inside real 3D environments.
VLN是什么: 导航一个agent(智能体)在室内3D环境去执行自然语言指令. - In this paper, we study how to address three critical challenges for this task: the cross-modal grounding, the ill-posed feedback, and the generalization problems.
VLN面临的三个挑战- cross-modal grounding(跨模态接地)
- ill-posed feedback(不适当的反馈)
- generalization problem(泛化问题)
- First, we propose a novel Reinforced Cross-Modal Matching (RCM) approach that enforces cross-modal grounding both locally and globally via reinforcement learning (RL). Particularly, a matching critic is used to provide an intrinsic reward to encourage global matching between instructions and trajectories, and a reasoning navigator is employed to perform cross-modal grounding in the local visual scene. Evaluation on a VLN benchmark dataset shows that our RCM model significantly outperforms existing methods by 10% on SPL and achieves the new state-of-the-art performance. To improve the generalizability of the learned policy, we further introduce a Self-Supervised Imitation Learning (SIL) method to explore unseen environments by imitating its own past, good decisions. We demonstrate that SIL can approximate a better and more efficient policy, which tremendously minimizes the success rate performance gap between seen and unseen environments (from 30.7% to 11.7%).
首先提出了强化跨模态匹配(Reinforced Cross-modal Matching), 通过强化学习来实施局部和全局的跨模态接地. 采用了matching critic(匹配评测) 来提供内部奖励, 进而鼓励指令和航线的全局匹配. 采用了推理导航器(resonning navigator)来执行局部视觉场景中的跨模态匹配. 在VLN的基准数据集上, 比现有的方法在SPL(Success Path against Path Length)指标上提升10%, 达到了最先进水平.
针对泛化的问题, 提出了SIL(Self-Supervised Imitation Learning Method). 通过模仿过去的好的决策来探索新环境. 以此来提升学习策略的泛化能力. 证明了SIL可以近似为一个更好更高效的策略, 极大的缩小了已知环境和未知环境之间的执行成功率鸿沟.
Introduction
VLN presents some unique challenges. First, reasoning over visual images and natural language instructions can be difficult. As we demonstrate in Figure 1, to reach a destination, the agent needs to ground an instruction in the local visual scene, represented as a sequence of words, as well as match the instruction to the visual trajectory in the global temporal space.
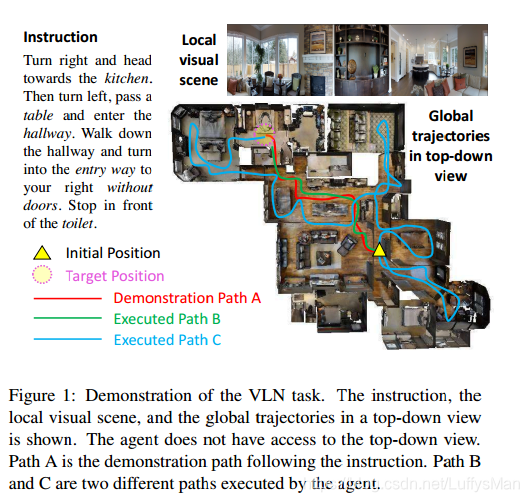
VLN提出了独特的挑战. 首先, 在视觉图像和自然语言指令上进行推理比较困难. 为了到大目的地, 智能体(agent)需要接地(ground)一条指令到局部场景. 并且匹配指令和全局时空的视觉路径.
Secondly, except for strictly following expert demonstrations, the feedback is rather coarse, since the “Success” feedback is provided only when the agent reaches a target position, completely ignoring whether the agent has followed the instructions (e.g., Path A in Figure 1) or followed a random path to reach the destination (e.g., Path C in Figure 1). Even a “good” trajectory that matches an instruction can be considered unsuccessful if the agent stops marginally earlier than it should be (e.g., Path B in Figure 1). An ill-posed feedback can potentially deviate from the optimal policy learning.
其次, 除了严格跟随专家演示(expert demostrations)外, 反馈相当粗糙. 因为"成功"的反馈只有在智能体(agent)到达目标位置才有, 完全忽略agent是遵循了指令还是沿着任意路径到达了目的地. 即使一个与指令比较贴合的航线, 如果停在了目的地的边缘, 也被认为失败. 因此一个不适当的反馈可能导致偏离最优策略学习.
Thirdly, existing work suffers from the generalization problem, causing a huge performance gap between seen and unseen environments.
第三, 现有工作遭受泛化困难的问题, 导致在已知和未知环境的性能差距很大.
In this paper, we propose to combine the power of reinforcement learning (RL) and imitation learning (IL) to address the challenges above. First, we introduce a novel Reinforced Cross-Modal Matching (RCM) approach that enforces cross-modal grounding both locally and globally via RL. Specifically, we design a reasoning navigator that learns the cross-modal grounding in both the textual instruction and the local visual scene, so that the agent can infer which sub-instruction to focus on and where to look at. From the global perspective, we equip the agent with a matching critic that evaluates an executed path by the probability of reconstructing the original instruction from it, which we refer to as the cycle-reconstruction reward.
本文提出要结合强化学习和模仿学习的力量. 首先, 引入了新的方法–RCM. 具体包括了用推理导航器(resoning navigator)来学习在文本指令和本地视觉场景之间的跨模态接地(cross-modal grounding). 从全局的视角, 给智能体(agent)装备了匹配评判(match critic), 用来评估用一条走过的航线去重建原始指令的概率. 这被称为循环重建奖励(cycle-reconstruction reward).
Being trained with the intrinsic reward from the matching critic and the extrinsic reward from the environment, the reasoning navigator learns to ground the natural language instruction on both local spatial visual scene and global temporal visual trajectory. Our RCM model significantly outperforms the existing ethods and achieves new state-ofthe-art performance on the Room-to-Room (R2R) dataset.
通过匹配评判(matching critic)提供的内部奖励和外部环境提供的奖励进行训练, 推理导航器(resoning navigator)学习去接地(grounding)自然语言指令到本地空间视觉场景和全局时间视觉路径. RCM模型的表现远超现存方法, 并且在R2R数据集上的表现达到了领先水平.
Our experimental results indicate a large performance gap between seen and unseen environments. To narrow the gap, we propose an effective solution to explore unseen environments with self-supervision. his technique is valuable because it can facilitate lifelong learning and adaption to new environments. For xample, in-home robots can explore a new home it arrives at and iteratively improve the navigation policy by learning from previous experience. Motivated by this fact, we introduce a Self-Supervised Imitation Learning (SIL) method in favor of exploration on unseen environments that do not have labeled data. The agent learns to imitate its own past, good experience. Specifically, in our framework, the navigator performs multiple roll-outs, of which good trajectories (determined by the matching critic) are stored in the replay buffer and later used for the navigator to imitate.
以往, 在未知环境和已知环境的性能有很大的有很大的差距. 我们提出了一种有效的解决方案来探索未知环境–通过自监督. 这种技术很有价值, 因为他促进了长期学习和对新环境的适应. 基于这个事实, 我们引入了自监督模仿学习(SIL)用来探索没有标签的未知环境. 智能体(agent)尝试去模仿自己以往的好的经验. 具体的, 在我们的架构中, 导航器执行了多种实现, 其中表现最好的航线(由匹配评判来决定)存入重播缓存(replay buffer)并被用于导航器模仿.
To summarize, our contributions are mainly four-fold:
• We propose a novel Reinforced Cross-Modal Matching (RCM) framework that utilizes both extrinsic and
intrinsic rewards for reinforcement learning, of which we introduce a cycle-reconstruction reward as the ntrinsic reward to enforce the global matching between the language instruction and the agent’s trajectory.
• Our reasoning navigator learns the cross-modal contexts and makes decisions based on trajectory history, textual context, and visual context.
• Experiments show that RCM achieves the new stateof-the-art performance on the R2R dataset, and among the prior art, is ranked first in the VLN Challenge in terms of SPL, the most reliable metric for the task.
• In addition, we introduce a Self-Supervised Imitation Learning (SIL) method to explore the unseen environments with self-supervision, and validate its effectiveness and efficiency on the R2R dataset.
我们的贡献总结为一下四部分:
- 提出了新的RCM框架, 同时利用了内部和外部的奖励来进行强化学习, 在这当中, 我们引入了循环重建(cycle reconstruction)作为内部奖励来实现自然语言指令与智能体(agent)航线的全局匹配.
- 我们的推理导航器(resoning navigator)可以学习跨模态语境, 并且基于历史航线, 文本上下文和视觉上下文来做出决策.
- 实验表明, RCM在R2R数据集上的表现取得了卓越的性能, 就最重量级的评估指标SPL来说, 超过以往的方法, 排名第一.
- 另外, 我们引入了自监督模仿学习(SIL)来探索未知环境, 并且在R2R数据集上验证了它的有效性和效率.
启发
学习机器学习的多种领域, 进行融合, 比如视觉和自然语言的结合, 深度学习和强化学习的结合等. 总的来说, 知识面又要广又要深啊.