合同C { uint256 a;
函数C(){ a = 1; } }
该合约归结为sstore指令的调用:
// a = 1 sstore(0x0,0x1)
- EVM将值
0x1存储在存储位置0x0。 - 每个存储位置可以存储32个字节(或256位)。
如果这看起来不熟悉,我推荐阅读: 潜入以太坊虚拟机第1部分 - 装配&字节码
在本文中,我们将开始研究Solidity如何使用32个字节的块来表示更复杂的数据类型,如结构和数组。 我们还会看到如何优化存储,以及优化如何失败。
在典型的编程语言中,理解数据类型如何在如此低层次上表现出来并不是非常有用。 在Solidity(或任何EVM语言)中,此知识至关重要,因为存储访问非常昂贵:
-
sstore成本为20000sstore,或比基本算术指令贵〜5000倍。 -
sload需要200sload天然气,或比基本算术指令贵〜100倍。
而通过“成本”,我们在这里谈论真钱,而不仅仅是毫秒的表现。 运行和使用您的合同的成本很可能由sstore和sstore支配!
Parsecs在Parsecs磁带上
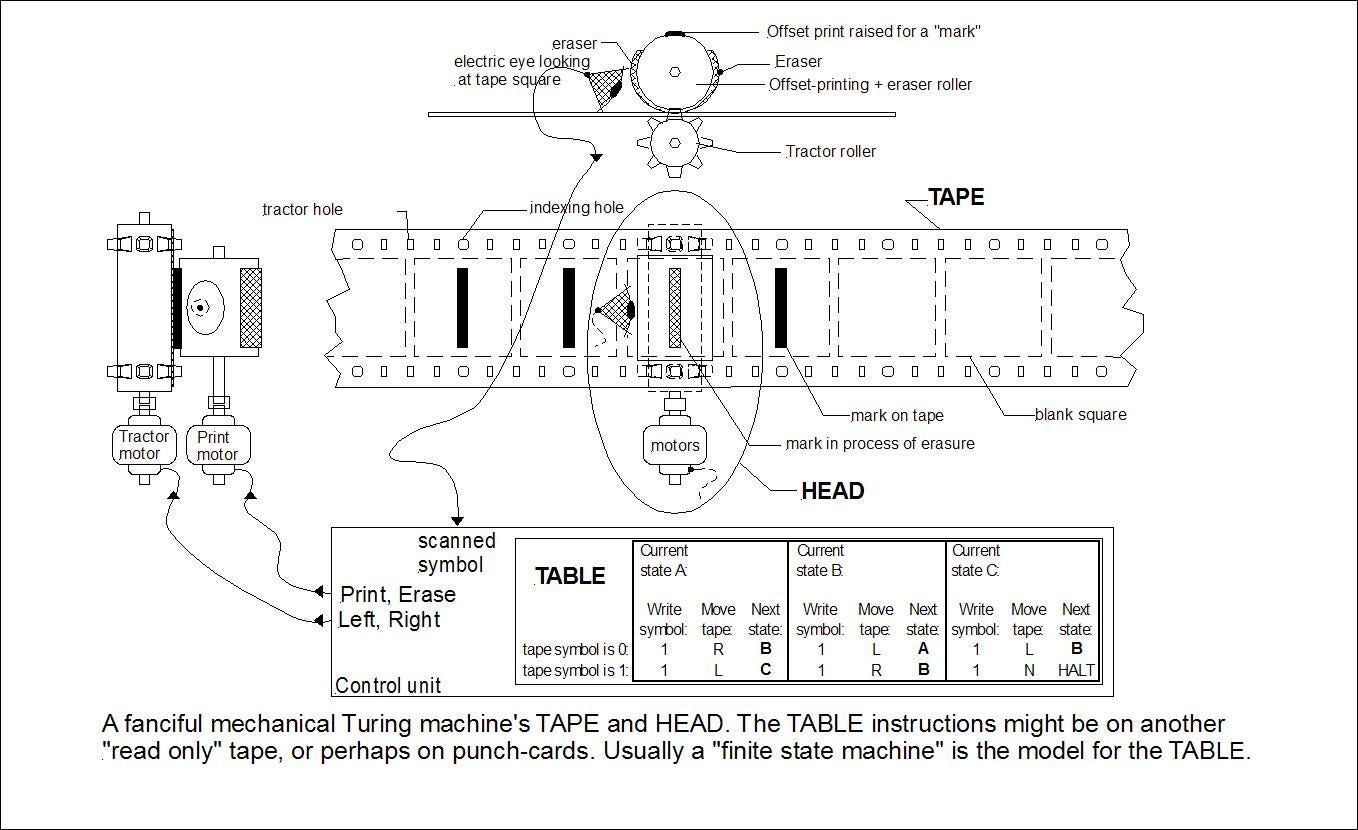
构建通用计算机需要两个基本要素:
- 循环的一种方式,无论是跳转还是递归。
- 无限量的记忆。
EVM汇编代码跳转,EVM存储提供无限的内存。 这对一切都是足够的,包括模拟一个运行以太坊版本的世界,它本身模拟一个运行以太坊的世界......

合同的EVM存储就像一个无限的自动收报机磁带,磁带的每个插槽都可容纳32个字节。 喜欢这个:
[32个字节] [32个字节] [32个字节] ...
我们将看到数据如何存在于无限大的磁带上。
磁带的长度为2÷5⁶,或每个合约约10⁷⁷个存储插槽。 可观测宇宙的粒子数是10⁸⁰。 大约1000个合约足以容纳所有这些质子,中子和电子。 不要相信营销炒作,因为它比无限更短。
空白磁带
存储最初是空白的,默认为零。 拥有无限磁带并不需要花费任何东西。
我们来看一个简单的合约来说明零价值行为:
杂注扎实0.4.11;
合同C { uint256 a; uint256 b; uint256 c; uint256 d; uint256 e; uint256 f;
函数C(){ f = 0xc0fefe; } }
存储中的布局很简单。
- 位置为
0x0的变量a - 位置为
0x1的变量b - 等等…
关键问题:如果我们只使用f ,我们为a,b,c,d,e支付多少钱?
让我们编译看看:
$ solc --bin --asm --optimize c-many-variables.sol
大会:
// sstore(0x5,0xc0fefe) TAG_2: 0xc0fefe 0x5的 sstore
因此,存储变量声明不需要任何费用,因为不需要初始化。 Solidity为该商店变量保留一个位置,并且只有当您存储某些内容时才支付。
在这种情况下,我们只支付存储到0x5 。
如果我们手工编写程序集,我们可以选择任何存储位置而不必“扩展”存储:
//写入任意位置 sstore(0xc0fefe,0x42)
读零
您不仅可以在存储的任何地方写字,还可以立即从任何地方读取。 从未初始化的位置读取仅返回0x0 。
让我们看看一个从未初始化位置读取的合约:
杂注扎实0.4.11;
合同C { uint256 a;
函数C(){ a = a + 1; } }
编译:
$ solc --bin --asm --optimize c-zero-value.sol
大会:
TAG_2: // sload(0x0)返回0x0 为0x0 DUP1 SLOAD
// a + 1; 其中一个== 0 为0x1 加
// sstore(0x0,a + 1) swap1 sstore
请注意,生成从未初始化位置sload代码是有效的。
然而,我们可以比Solidity编译器更聪明。 由于我们知道tag_2是构造函数,并且从未写入过,所以我们可以用0x0替换sload序列以节省5000个气体。
代表结构
我们来看看我们的第一个复杂数据类型,一个有6个字段的结构体:
杂注扎实0.4.11;
合同C { 结构元组{ uint256 a; uint256 b; uint256 c; uint256 d; uint256 e; uint256 f; }
元组t;
函数C(){ tf = 0xC0FEFE; } }
存储中的布局与状态变量相同:
- 位置
0x0的字段ta - 位置为
0x1的字段tb - 等等…
像以前一样,我们可以直接写入tf而无需支付初始化费用。
让我们编译一下:
$ solc --bin --asm --optimize c-struct-fields.sol
我们看到完全相同的组件:
TAG_2: 0xc0fefe 0x5的 sstore
固定长度数组
现在我们来声明一个固定长度的数组:
杂注扎实0.4.11;
合同C { uint256 [6]数字;
函数C(){ 数字[5] = 0xC0FEFE; } }
由于编译器确切地知道有多少个uint256(32个字节),因此它可以简单地将数组的元素放在存储器中,就像存储变量和结构一样。
在这份合同中,我们再次存储到位置0x5 。
编译:
$ solc --bin --asm --optimize c-static-array.sol
大会:
TAG_2: 0xc0fefe 为0x0 0x5的 tag_4: 加 为0x0 tag_5: 流行的 sstore
它稍微长一些,但如果你稍微眯起一点,你会发现它实际上是一样的。 我们手工进一步优化:
TAG_2: 0xc0fefe
// 0 + 5。 用0x5替换 为0x0 0x5的 加
//按下然后立即弹出。 没用,只是删除。 为0x0 流行的
sstore
除去标签和伪指令,我们再次得到相同的字节码序列:
TAG_2: 0xc0fefe 0x5的 sstore
数组绑定检查
我们已经看到,固定长度的数组与存储结构和状态变量具有相同的存储布局,但生成的汇编代码是不同的。 原因是Solidity为数组访问生成了边界检查。
让我们再次编译数组合约,这次关闭优化:
$ solc --bin --asm c-static-array.sol
程序集在下面注释,每条指令后打印机器状态:
TAG_2: 0xc0fefe [0xc0fefe] 0x5的 [0x5 0xc0fefe] DUP1
/ *数组绑定检查代码* / // 5 <6 为0x6 [0x6 0x5 0xc0fefe] DUP2 [0x5 0x6 0x5 0xc0fefe] LT [0x1 0x5 0xc0fefe] // bound_check_ok = 1(TRUE)
// if(bound_check_ok){goto tag5} else {invalid} tag_5 [tag_5 0x1 0x5 0xc0fefe] jumpi //测试条件为真。 会得到tag_5。 //并且`jumpi`消耗堆栈中的两项。 [0x5 0xc0fefe] 无效
//数组访问是有效的。 做到这一点。 // stack:[0x5 0xc0fefe] tag_5: sstore [] 存储:{0x5 => 0xc0fefe}
我们现在看到绑定检查代码。 我们已经看到编译器能够优化这些东西,但并不完美。
在本文的后面,我们将看到数组绑定检查如何干扰编译器优化,使得固定长度数组比存储变量或结构的效率低得多。
包装行为
存储是昂贵的(yayaya我已经说了一百万次)。 一个关键的优化是尽可能多地将数据打包到一个32字节的插槽中。
考虑具有四个存储变量(每个64位)的合同,总共可以累加256位(32个字节):
杂注扎实0.4.11;
合同C { uint64 a; uint64 b; uint64 c; uint64 d;
函数C(){ a = 0xaaaa; b = 0xbbbb; c = 0xcccc; d = 0xdddd; } }
我们希望(希望)编译器使用一个sstore将它们放在同一个存储槽中。
编译:
$ solc --bin --asm --optimize c-many-variables - packing.sol
大会:
TAG_2: / *“c-many-variables - packing.sol”:121:122 a * / 为0x0 / *“c-many-variables - packing.sol”:121:131 a = 0xaaaa * / DUP1 SLOAD / *“c-many-variables - packing.sol”:125:131 0xaaaa * / 加上0xAAAA 不是(0xffffffffffffffff) / *“c-many-variables - packing.sol”:121:131 a = 0xaaaa * / swap1 swap2 和 要么 not(sub(exp(0x2,0x80),exp(0x2,0x40))) / *“c-many-variables - packing.sol”:139:149 b = 0xbbbb * / 和 0xbbbb0000000000000000 要么 not(sub(exp(0x2,0xc0),exp(0x2,0x80))) / *“c-many-variables - packing.sol”:157:167 c = 0xcccc * / 和 0xcccc00000000000000000000000000000000 要么 sub(exp(0x2,0xc0),0x1) / *“c-many-variables - packing.sol”:175:185 d = 0xdddd * / 和 0xdddd000000000000000000000000000000000000000000000000 要么 swap1 sstore
很多我无法破译的小混混,我不在乎。 关键要注意的是,只有一个sstore 。
优化成功!
打破优化
如果只有优化器可以一直很好地工作。 让我们打破它。 我们唯一的改变是我们使用助手函数来设置存储变量:
杂注扎实0.4.11;
合同C { uint64 a; uint64 b; uint64 c; uint64 d;
函数C(){ SETAB(); setCD(); }
函数setAB()internal { a = 0xaaaa; b = 0xbbbb; }
函数setCD()internal { c = 0xcccc; d = 0xdddd; } }
编译:
$ solc --bin --asm --optimize c-many-variables - packing-helpers.sol
装配输出太多了。 我们将忽略大部分细节并关注结构:
//构造函数 TAG_2: // ... //通过跳转到tag_5来调用setAB() 跳 tag_4: // ... //通过跳转到tag_7来调用setCD() 跳
//函数setAB() tag_5: // Bit-shuffle并设置a,b // ... sstore tag_9: 跳转//返回setAB()的调用者
//函数setCD() tag_7: // Bit-shuffle并设置c,d // ... sstore tag_10: 跳转//返回setCD()的调用者
现在有两个sstore而不是一个。 Solidity编译器可以在标签内进行优化,但不能在标签内进行优化。
调用函数会花费更多,而不是太多,因为函数调用很昂贵(它们只是跳转指令),但是因为sstore优化可能会失败。
为了解决这个问题,Solidity编译器需要学习如何内联函数,本质上得到的代码与不调用函数相同:
a = 0xaaaa; b = 0xbbbb; c = 0xcccc; d = 0xdddd;
如果我们仔细阅读完整的汇编输出,我们会看到函数setAB()和setCD()的汇编代码 被包含两次,从而膨胀了代码的大小,从而花费额外的气体来部署合同。 我们稍后会在了解合同生命周期时再讨论这一点。
为什么优化器打破
优化器不会跨标签进行优化。 考虑“1 + 1”,如果在相同的标签下,它可以优化为0x2 :
//优化OK! TAG_0: 为0x1 为0x1 加 ...
但是,如果指令由标签分隔,则不适用:
//优化失败! TAG_0: 为0x1 为0x1 TAG_1: 加 ...
从版本0.4.13开始这种行为是正确的。 未来可能会改变。
再次打破优化器
让我们看看优化器失败的另一种方式。 包装是否适用于固定长度的阵列? 考虑:
杂注扎实0.4.11;
合同C { uint64 [4]数字;
函数C(){ 数字[0] = 0x0; 数字[1] = 0x1111; 数字[2] = 0x2222; 数字[3] = 0x3333; } }
同样,我们希望使用一个sstore指令将四个64位数字打包到一个32字节的存储插槽中。
编译后的程序集太长。 让我们来计算一下sstore和sstore指令的数量:
$ solc --bin --asm --optimize c-static-array - packing.sol | grep -E'(sstore | sload)' SLOAD sstore SLOAD sstore SLOAD sstore SLOAD sstore
哦,不。 即使这个固定长度数组的存储布局与等效的结构或存储变量完全相同,优化也会失败。 它现在需要四对sstore和sstore 。
快速查看汇编代码可以发现,每个数组访问都绑定了检查代码,并在不同的标记下进行组织。 但标签边界打破了优化。
虽然有一点小小的安慰。 3个额外的sstore指令比第一个便宜:
-
sstore花费20000瓦斯首先写入新的位置。 -
sstore花费5000瓦斯用于后续写入现有位置。
所以这个特定的优化失败花费我们35k而不是20k,另外75%。
结论
如果Solidity编译器能够计算出存储变量的大小,它只是将它们放在一个接一个的存储空间中。 如果可能的话,编译器将数据紧密地打包成32字节的块。
总结我们迄今为止看到的包装行为:
- 存储变量:是的。
- 结构字段:是。
- 固定长度数组:不。 理论上,是的。
由于存储访问成本非常高,因此您应该将存储变量视为数据库架构。 在编写契约时,做小型实验可能会很有用,并检查程序集以确定编译器是否正在优化。
我们可以肯定,Solidity编译器将来会有所改进。 不幸的是,现在我们不能盲目信任它的优化器。
它从字面上支付了解您的商店变量。
在这篇关于EVM的文章系列中,我写到:
- EVM汇编代码简介。
- 如何表示固定长度的数据类型。
- 如何表示动态数据类型。
- ABI如何编码外部方法调用。
- 新合同创建时发生了什么。
https://medium.com/@hayeah/diving-into-the-ethereum-vm-part-2-storage-layout-bc5349cb11b7