一. 中断上半部,下半部理解
设备的中断会打断内核中进程的正常调度和运行,系统对更高吞吐率的追求势必要求中断服务程序尽可能地短小精悍。但是,这个良好的愿望往往与现实并不吻合。在大多数真实的系统中,当中断到来时,要完成的工作往往并不会是短小的,它可能要进行较大量的耗时处理。
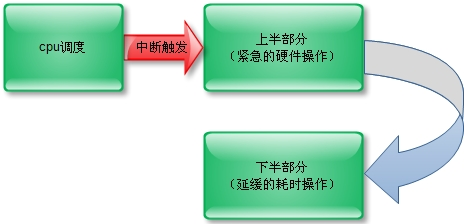
如上图描述了Linux内核的中断处理机制
为了在中断执行时间尽可能短和中断处理需完成大量工作之间找到一个平衡点,Linux将中断处理程序分解为两个半部:顶半部(top half)和底半部(bottom half)。
顶半部完成尽可能少的比较紧急的功能,它往往只是简单地读取寄存器中的中断状态并清除中断标志后就进行“登记中断”的工作。“登记中断”意味着将底半部处理程序挂到该设备的底半部执行队列中去。这样,顶半部执行的速度就会很快,可以服务更多的中断请求。
现在,中断处理工作的重心就落在了底半部的头上,它来完成中断事件的绝大多数任务。底半部几乎做了中断处理程序所有的事情,而且可以被新的中断打断,这也是底半部和顶半部的最大不同,因为顶半部往往被设计成不可中断。底半部则相对来说并不是非常紧急的,而且相对比较耗时,不在硬件中断服务程序中执行。
尽管顶半部、底半部的结合能够改善系统的响应能力,但是,僵化地认为Linux设备驱动中的中断处理一定要分两个半部则是不对的。如果中断要处理的工作本身很少,则完全可以直接在顶半部全部完成。
其实上面这一段大致说明一个问题,那就是:中断要尽可能耗时比较短,尽快恢复系统正常调试,所以把中断触发、中断执行分开,也就是所说的“上半部分(中断触发)、底半部(中断执行)”,其实就是我们后面说的中断上下文。下半部分一般有tasklet、工作队列实现,触摸屏中中断实现以工作队列形式实现的
二. 中断下半部的处理
对于一个中断,如何划分出上下两部分呢?哪些处理放在上半步,哪些放在下半部?
这里有一些经验可供借鉴:
如果一个任务对时间十分敏感,将其放在上半部。
如果一个任务和硬件有关,将其放在上半部。
如果一个任务要保证不被其他中断打断,将其放在上半部。
其他所有任务,考虑放在下半部。
三. 实现下半部中断的三种机制
目前使用下面三种方法:
1.软中断
2.tasklet
3.工作队列
四. 软中断
软中断是一组静态定义的下半部接口,有 32 个,可以在所有处理器上同时执行,类型相同也可以;在编译时静态注册。
软中断的流程如下:

软中断执行函数如下:
1 asmlinkage void do_softirq(void) 2 { 3 __u32 pending; 4 unsigned long flags; 5 6 /* 判断是否在中断处理中,如果正在中断处理,就直接返回 */ 7 if (in_interrupt()) 8 return; 9 10 /* 保存当前寄存器的值 */ 11 local_irq_save(flags); 12 13 /* 取得当前已注册软中断的位图 */ 14 pending = local_softirq_pending(); 15 16 /* 循环处理所有已注册的软中断 */ 17 if (pending) 18 __do_softirq(); 19 20 /* 恢复寄存器的值到中断处理前 */ 21 local_irq_restore(flags); 22 }
代码之中第一次就判断是否在中断处理中,如果在立刻退出函数。这说明了什么?说明了如果有其他软中断触发,执行到此处由于先前的软中断已经在处理,则其他软中断会返回。所以,软中断不能被另外一个软中断抢占!唯一可以抢占软中断的是中断处理程序,所以软中断允许响应中断。虽然不能在本处理器上抢占,但是其他的软中断甚至同类型可以再其他处理器上同时执行。由于这点,所以对临界区需要加锁保护。
软中断留给对时间要求最严格的下半部使用。目前只有网络,内核定时器和 tasklet 建立在软中断上。
Tasklet
注意,这第二种机制是基于软中断实现的,灵活性强,动态创建的下半部实现机制。两个不同类型的 tasklet 可以在不同处理器上运行,但相同的不可以,可以通过代码动态注册。
在 SMP 上,调用 tasklet 是会检测 TASKLET_STATE_SCHED 标志,如果同类型在运行,就退出函数。
tasklet 由于是基于软中断实现的,所以也允许响应中断。但不能睡眠(我认为不能睡眠原因是它们内部有 spin lock)。
工作队列
工作队列(work queue)是另外一种将中断的部分工作推后的一种方式,它可以实现一些tasklet不能实现的工作,比如工作队列机制可以睡眠。这种差异的本质原因是,在工作队列机制中,将推后的工作交给一个称之为工作者线程(worker thread)的内核线程去完成(单核下一般会交给默认的线程events/0)。因此,在该机制中,当内核在执行中断的剩余工作时就处在进程上下文(process context)中。也就是说由工作队列所执行的中断代码会表现出进程的一些特性,最典型的就是可以重新调度甚至睡眠。
对于tasklet机制(中断处理程序也是如此),内核在执行时处于中断上下文(interrupt context)中。而中断上下文与进程毫无瓜葛,所以在中断上下文中就不能睡眠。因此,选择tasklet还是工作队列来完成下半部分应该不难选择。当推后的那部分中断程序需要睡眠时,工作队列毫无疑问是你的最佳选择;否则,还是用tasklet吧。
中断上下文
在了解中断上下文时,先来回顾另一个熟悉概念:进程上下文(这个中文翻译真的不是很好理解,用“环境”比它好很多)。一般的进程运行在用户态,如果这个进程进行了系统调用,那么此时用户空间中的程序就进入了内核空间,并且称内核代表该进程运行于内核空间中。由于用户空间和内核空间具有不同的地址映射,并且用户空间的进程要传递很多变量、参数给内核,内核也要保存用户进程的一些寄存器、变量等,以便系统调用结束后回到用户空间继续执行。这样就产生了进程上下文。
所谓的进程上下文,就是一个进程在执行的时候,CPU的所有寄存器中的值、进程的状态以及堆栈中的内容。当内核需要切换到另一个进程时(上下文切换),它需要保存当前进程的所有状态,即保存当前进程的进程上下文,以便再次执行该进程时,能够恢复切换时的状态继续执行。上述所说的工作队列所要做的工作都交给工作者线程来处理,因此它可以表现出进程的一些特性,比如说可以睡眠等。
对于中断而言,是硬件通过触发信号,导致内核调用中断处理程序,进入内核空间。这个过程中,硬件的一些变量和参数也要传递给内核,内核通过这些参数进行中断处理,中断上下文就可以理解为硬件传递过来的这些参数和内核需要保存的一些环境,主要是被中断的进程的环境。因此处于中断上下文的tasklet不会有睡眠这样的特性。
工作队列实现方法
使用方法和tasklet类似
相关操作:
struct work_struct my_wq; //定义一个工作队列
void my_wq_func(unsigned long); //定义一个处理函数
通过INIT_WORK()可以初始化这个工作队列并将工作队列与处理函数绑定
INIT_WORK(&my_wq,(void ()(void ))my_wq_func,NULL);
/*初始化工作队列并将其与处理函数绑定*/
schedule_work(&my_wq);/调度工作队列执行/
1 /*定义工作队列和关联函数*/ 2 struct work_struct xxx_wq(unsigned long); 3 4 /*中断处理底半部*/ 5 void xxx_do_work(unsigned long){...} 6 7 /*中断处理顶半部*/ 8 irqreturn_t xxx_interrupt(int irq,void *dev_id) 9 { 10 //TODO 11 schedule_work(&my_wq); 12 } 13 14 /*设备驱动模块加载函数*/ 15 int xxx_init(void) 16 { 17 //TODO 18 //申请中断 19 //原型:int request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags,const char *name, void *dev) 20 request = request_irq(xxx_wq,xxx_interrupt,IRQF_DISABLED,"XXX",NULL); 21 ... 22 // 初始化工作队列 23 INIT_WORK(&my_wq,(void(*)(void *))xxx_do_work,NULL ) 24 } 25 26 /*设备驱动模块卸载函数*/ 27 void xxx_exit(void) 28 { 29 //TODO 30 //释放中断 31 free_irq(xxx_irq,xxx_interrupt); 32 //TODO 33 }
中断中为何不能使用信号量?中断上下为何不能睡眠?
信号量会导致睡眠
中断发生以后,CPU跳到内核设置好的中断处理代码中去,由这部分内核代码来处理中断。这个处理过程中的上下文就是中断上下文。
为什么可能导致睡眠的函数都不能在中断上下文中使用呢? 首先睡眠的含义是将进程置于“睡眠”状态,在这个状态的进程不能被调度执行。然后,在一定的时机,这个进程可能会被重新置为“运行”状态,从而可能被调度执行。 可见,“睡眠”与“运行”是针对进程而言的,代表进程的task_struct结构记录着进程的状态。内核中的“调度器”通过task_struct对进程进行调度。
但是,中断上下文却不是一个进程,它并不存在task_struct,所以它是不可调度的。所以,在中断上下文就不能睡眠。
那么,中断上下文为什么不存在对应的task_struct结构呢?
中断的产生是很频繁的(至少每毫秒(看配置,可能10毫秒或其他值)会产生一个时钟中断),并且中断处理过程会很快。如果为中断上下文维护一个对应的task_struct结构,那么这个结构频繁地分配、回收、并且影响调度器的管理,这样会对整个系统的吞吐量有所影响。
但是在某些追求实时性的嵌入式linux中,中断也可能被赋予task_struct结构。这是为了避免大量中断不断的嵌套,导致一段时间内CPU总是运行在中断上下文,使得某些优先级非常高的进程得不到运行。这种做法能够提高系统的实时性,但是代价中吞吐量的降低