这两天在做信用卡的数据分析项目,出现了除标题错误以外 +
(
ValueError: Found input variables with inconsistent numbers of samples: [56411, 27785]
)
这两个报错,因为标题字数有限,所以只写了一个。现在我们先解决第一个问题:
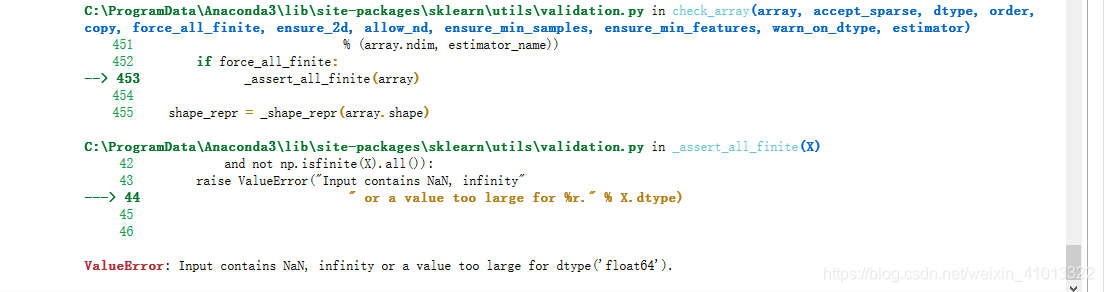
正如上面报错所写,错误原因就是:
输入的数据里面包含NaN值或者无穷大的数据
所以解决办法:
找到NaN值补齐或者删除该列;减小样本数据。
然后先用pandas的describe()和head()属性来查看一下数据集情况,前者是对整个数据有个概览,后者可以直接打印出前几行数据,这里我们选择前5看看,代码如下:
print(data1.describe())
#数据集概览
print(data1.head(5))
#前5行
然后输出的结果发现:
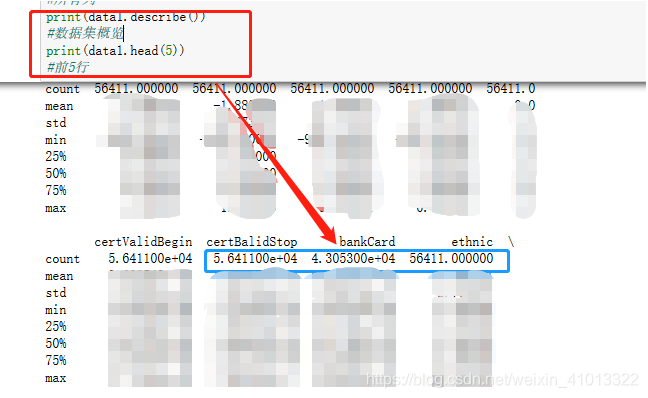

可以看出来bankCard这一列的数据是不完整的,存在NaN值,鉴于他对于预测模型的生成没有太大影响,所以直接删除了该列,问题解决!
data1.drop(['bankCard'], axis = 1)
==================================================================================================分割线
好了,现在解决第二个问题:

这个错误的原因是:
输入的训练集数据的数目与测试集的数据数目不一致导致的!!!比如你的训练集是1000个数据,那么你的测试集也要是1000个数据才行
上次我这里理解错了,不好意思?(网上搜到的那个同样问题的博客,他的理解也是错误的。。。所以还是要看官方文档啊!!!)这里不是说的训练集和测试集数目不一致,而是 因为训练集的样本数与你选的特征变量数不一致才导致的!!!即如果你的train_x 是(21000,23),那么 train_y也要是(21000,)!
解决办法:
使结果长度保持一致即可。
再次运行,问题解决?
PS:
第一个问题其实还有一种查看数据有没有缺失值的办法,就是用pandas的.isnull().any() 方法,比如看下面代码:
print(data4.isnull().any())
结果打印出来是:
loanProduct False
gender False
age False
dist False
edu False
...
ncloseCreditCard False
unpayIndvLoan False
unpayOtherLoan False
unpayNormalLoan False
5yearBadloan False
Length: 99, dtype: bool
解释一下,False代表该字段没有空值,所以是完整的,不存在缺失值;
True代表该字段有缺失值。
可以看出来,这里显示的是没有缺失值,但是我们刚刚通过开头的方法已经发现了缺失值的字段,
所以当特征字段太多的时候,此方法就不容易看出缺失的字段; 建议特征字段较少的时候使用该方法。
