Segmentiertes Protokoll
Teilen Sie große Dateien in mehrere kleinere Dateien auf, die einfacher zu handhaben sind.
Problemhintergrund
Eine einzelne Protokolldatei kann sehr groß werden und beim Start des Programms gelesen werden, was zu einem Leistungsengpass wird. Alte Protokolle müssen regelmäßig bereinigt werden, aber das Bereinigen einer großen Datei ist sehr mühsam.
Lösung
Teilen Sie ein einzelnes Protokoll in mehrere auf. Wenn das Protokoll eine bestimmte Größe erreicht, wird zu einer neuen Datei gewechselt, um mit dem Schreiben fortzufahren.
//写入日志
public Long writeEntry(WALEntry entry) {
//判断是否需要另起新文件
maybeRoll();
//写入文件
return openSegment.writeEntry(entry);
}
private void maybeRoll() {
//如果当前文件大小超过最大日志文件大小
if (openSegment.
size() >= config.getMaxLogSize()) {
//强制刷盘
openSegment.flush();
//存入保存好的排序好的老日志文件列表
sortedSavedSegments.add(openSegment);
//获取文件最后一个日志id
long lastId = openSegment.getLastLogEntryId();
//根据日志id,另起一个新文件,打开
openSegment = WALSegment.open(lastId, config.getWalDir());
}
}Wenn das Protokoll segmentiert ist, ist ein Mechanismus zum schnellen Auffinden einer Datei mit einem Protokollspeicherort (oder einer Protokollsequenznummer) erforderlich. Es kann auf zwei Arten erreicht werden:
- Der Name jeder Protokollaufteilungsdatei enthält einen bestimmten Anfangs- und Protokollpositionsversatz (oder eine Protokollsequenznummer).
- Jede Protokollsequenznummer enthält den Dateinamen und den Transaktionsoffset.
//创建文件名称
public static String createFileName(Long startIndex) {
//特定日志前缀_起始位置_日志后缀
return logPrefix + "_" + startIndex + "_" + logSuffix;
}
//从文件名称中提取日志偏移量
public static Long getBaseOffsetFromFileName(String fileName) {
String[] nameAndSuffix = fileName.split(logSuffix);
String[] prefixAndOffset = nameAndSuffix[0].split("_");
if (prefixAndOffset[0].equals(logPrefix))
return Long.parseLong(prefixAndOffset[1]);
return -1l;
}Nachdem der Dateiname diese Informationen enthält, wird der Lesevorgang in zwei Schritte unterteilt:
- Rufen Sie bei gegebenem Offset (oder Transaktions-ID) die Datei ab, in der das Protokoll größer als dieser Offset ist
- Lesen Sie alle Protokolle, die größer als dieser Versatz sind, aus der Datei
//给定偏移量,读取所有日志
public List<WALEntry> readFrom(Long startIndex) {
List<WALSegment> segments = getAllSegmentsContainingLogGreaterThan(startIndex);
return readWalEntriesFrom(startIndex, segments);
}
//给定偏移量,获取所有包含大于这个偏移量的日志文件
private List<WALSegment> getAllSegmentsContainingLogGreaterThan(Long startIndex) {
List<WALSegment> segments = new ArrayList<>();
//Start from the last segment to the first segment with starting offset less than startIndex
//This will get all the segments which have log entries more than the startIndex
for (int i = sortedSavedSegments.size() - 1; i >= 0; i--) {
WALSegment walSegment = sortedSavedSegments.get(i);
segments.add(walSegment);
if (walSegment.getBaseOffset() <= startIndex) {
break; // break for the first segment with baseoffset less than startIndex
}
}
if (openSegment.getBaseOffset() <= startIndex) {
segments.add(openSegment);
}
return segments;
}Zum Beispiel
Grundsätzlich verwenden alle gängigen MQ-Speicher wie RocketMQ, Kafka und Pulsars zugrunde liegender Speicher BookKeeper segmentierte Protokolle.
RocketMQ: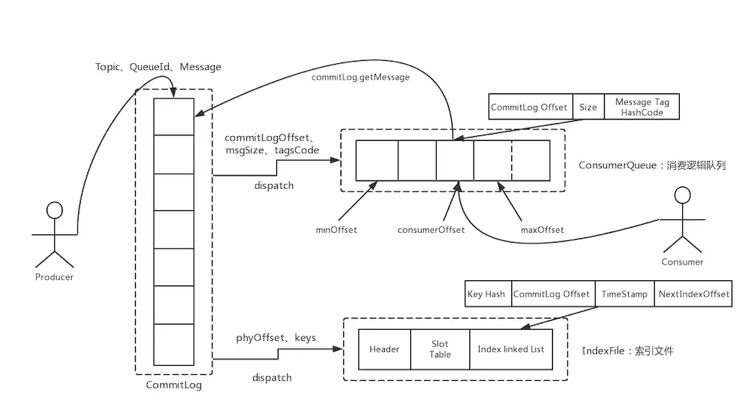
Kafka:
Pulsar Storage implementiert BookKeeper: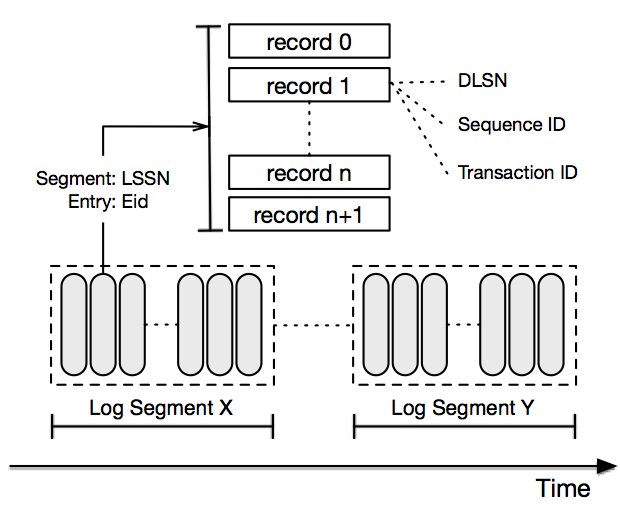
Darüber hinaus verwendet der auf dem Konsistenzprotokoll Paxos oder Raft basierende Speicher im Allgemeinen segmentierte Protokolle wie Zookeeper und TiDB.
Mit einem Schlag pro Tag können Sie Ihre Fähigkeiten ganz einfach verbessern und verschiedene Angebote erhalten:
