Vorlesung 08: Aufteilung der Beispielanwendung in Microservices
Nach der Einführung in die grundlegenden Konzepte des domänengesteuerten Designs in Lektion 07 wird in dieser Lektion vorgestellt, wie die Ideen im Zusammenhang mit dem domänengesteuerten Design im Bereich Microservices angewendet werden können.
Microservice-Abteilung
Beim Design und der Implementierung von Microservice-Architekturanwendungen muss, wenn Sie die wichtigste Aufgabe herausfinden wollen, die Aufteilung von Nicht-Microservices sein . Den Kern der Microservice-Architektur stellt ein verteiltes System aus mehreren kooperierenden Microservices dar. Erst nachdem die Aufteilung der Microservices abgeschlossen ist, können die Verantwortlichkeiten der einzelnen Microservices geklärt und der Interaktionsmodus zwischen den Microservices festgelegt werden, um dann mit dem API-Design fortzufahren Jeder Microservice ist die endgültige Implementierung, Prüfung und Bereitstellung jedes Microservices.
Wie aus dem obigen Prozess ersichtlich ist, ist die Microservice-Division das erste Glied in der gesamten Kette des Anwendungsdesigns und der Implementierung. Änderungen in jedem Glied der Kette wirken sich auf die nachfolgenden Glieder aus: Als erstes Glied der Microservice-Sparte wirkt sich eine Änderung auf alle nachfolgenden Glieder aus. Das Letzte, was Sie wollen, ist zu erkennen, dass einige Funktionen während der Implementierung von Microservices zu anderen Microservices migriert werden sollten. In diesem Fall müssen sowohl die API als auch die Implementierung des zugehörigen Microservice geändert werden.
Natürlich ist es in der tatsächlichen Entwicklung unrealistisch, Änderungen an der Aufteilung von Microservices vollständig zu vermeiden. In der Phase der Microservice-Division sind die Vorteile, die Sie erhalten, absolut enorm, wenn Sie genügend Energie für die Analyse aufwenden.
Microservices und Bounded Contexts
In der 07. Klasse haben wir das Konzept des definierten Kontexts im domänengetriebenen Design eingeführt.Wenn die Idee des domänengetriebenen Designs auf die Microservice-Architektur angewendet wird, können wir eine Eins-zu-Eins-Entsprechung zwischen Microservices und definiertem Kontext herstellen . Jeder begrenzte Kontext entspricht direkt einem Microservice und verwendet dann das Muster der Kontextzuordnung, um die Art der Interaktion zwischen Microservices zu definieren.
Auf diese Weise wird das Problem der Aufteilung von Microservices in das Problem der Aufteilung des Kontexts transformiert, der im domänengetriebenen Design definiert ist. Wenn Sie bereits über ein solides Verständnis von Domain Driven Design verfügen, ist dies von Vorteil, wenn nicht, können Sie mit den Inhalten von Lektion 07 schnell loslegen.
Nehmen wir die Beispielanwendung in dieser Spalte als Beispiel für eine spezifische Erklärung.
Microservice-Partitionierung der Beispielanwendung
Lektion 06 stellt die Benutzerszenarien der Beispielanwendung vor, basierend auf diesen Szenarien kann die Domäne der Anwendung bestimmt werden. Bei der eigentlichen Anwendungsentwicklung müssen in der Regel Fachexperten und Geschäftsleute teilnehmen.Durch die Kommunikation mit Geschäftsleuten können wir ein klareres Verständnis der Domäne erlangen. Was die Beispielanwendung betrifft, da die Anwendungsdomäne relativ nah am Leben ist und um die damit verbundene Einführung zu vereinfachen, werden wir selbst eine Domänenanalyse durchführen. Allerdings hat dies einen Nachteil, nämlich dass die von Entwicklern durchgeführte Domänenanalyse nicht unbedingt den realen Geschäftsprozess widerspiegelt. Für die Beispielanwendung ist dies jedoch ausreichend.
Domänengesteuertes Design nimmt die Domäne als Kern, und die Domäne wird in Problemraum und Lösungsraum unterteilt .
Der Problemraum hilft uns, auf Geschäftsebene zu denken, und ist der Teil der Domäne, von dem die Kerndomäne abhängt, die die Kerndomäne und je nach Bedarf andere Unterdomänen umfasst. Die Kerndomäne muss von Grund auf neu erstellt werden, da dies der Kern des von uns zu entwickelnden Softwaresystems ist; andere Unterdomänen können bereits vorhanden sein oder müssen ebenfalls von Grund auf neu erstellt werden. Die Kernfrage des Problemraums ist die Identifizierung und Aufteilung von Teilfeldern.
Der Lösungsraum besteht dann aus einem oder mehreren begrenzten Kontexten und den Modellen innerhalb der Kontexte. Idealerweise gibt es eine Eins-zu-Eins-Entsprechung zwischen definierten Kontexten und Unterdomänen. Auf diese Weise kann die Teilung auf der Geschäftsebene begonnen werden, und dann kann die gleiche Teilungsmethode auf der Implementierungsebene angewendet werden, sodass die perfekte Integration des Problemraums und des Lösungsraums realisiert werden kann. In der Praxis ist es unwahrscheinlich, dass es eine Eins-zu-Eins-Entsprechung zwischen definierten Kontexten und Unterfeldern gibt. Bei der Implementierung eines Softwaresystems muss es normalerweise mit bestehenden Legacy-Systemen und externen Systemen integriert werden, und diese Systeme haben ihre eigenen definierten Kontexte. In der Praxis ist es realistischer, dass mehrere begrenzte Kontexte zu demselben Unterfeld gehören oder ein begrenzter Kontext mehreren Unterfeldern entspricht.
Die Idee des domänengetriebenen Designs besteht darin, von der Domäne auszugehen, zuerst die Unterdomäne aufzuteilen und dann den definierten Kontext und das Modell im Kontext von der Unterdomäne zu abstrahieren.Jeder definierte Kontext entspricht einem Microservice.
Kerngebiete
Der Kernbereich ist dort, wo der Wert des Softwaresystems vorhanden ist, und er ist auch der Ausgangspunkt des Designs. Bevor Sie das Softwaresystem starten, sollten Sie den Kernwert des Softwaresystems klar verstehen.Wenn nicht, dann müssen Sie zuerst die Verkaufsargumente des Softwaresystems berücksichtigen.Verschiedene Softwaresysteme haben unterschiedliche Kernbereiche. Als Taxi-Hailing-Anwendung besteht ihr Kernbereich darin, Fahrgäste schnell, bequem und sicher reisen zu lassen, was auch der Kernbereich von Taxi-Hailing-Anwendungen wie Didi Taxi und Uber ist. Für die Happy-Travel-Anwendung als Beispiel stellt ein solcher Kernbereich etwas zu groß dar. Die Happy-Travel-Anwendung vereinfacht den Kernbereich und konzentriert sich nur darauf, Passagiere schnell reisen zu lassen.
Wir müssen der Kerndomäne einen angemessenen Namen geben. Der Kernbereich des glücklichen Reisens besteht darin, schnell zwischen Passagieren, die ein Auto anrufen müssen, und Fahrern, die Reisedienstleistungen erbringen, zusammenzupassen. Nachdem der Benutzer die Reiseroute erstellt hat, verteiltdas System sie an verfügbare Fahrer.Nachdem der Fahrer die Reiseroute empfangen hat, wählt das System einenFahrer zum Verteilen der Reiseroute aus. Der Kernbereich konzentriert sich auf das Versenden von Reiseplänen, daher der Name Reiseplanverteilung .
Konzepte auf dem Gebiet
Wir zählen dann die Konzepte in der Domäne auf. Dies ist ein Brainstorming-Prozess, der auf einem Whiteboard durchgeführt werden kann, um alle verwandten Konzepte aufzulisten, die einem nach dem anderen in den Sinn kommen. Konzepte sind Substantive. Das früheste Konzept ist Reiseroute, was eine Reise von einem bestimmten Startpunkt zu einem Endpunkt bedeutet. Ausgehend von der Reiseroute lässt sich der Fahrgast-Fahrer-Begriff ableiten.Der Fahrgast ist der Initiator der Reiseroute, der Fahrer ist der Vollender der Reiseroute.Jede Reiseroute hat einen Anfangs- und einen Endpunkt, und das entsprechendeKonzept ist die Adresse. Fahrer nutzen Privatfahrzeuge, um Fahrten abzuschließen, daher sind Fahrzeuge ein anderes Konzept.
Wir finden andere Unterfelder, die auf Konzepten basieren, und das Konzept des Reisens gehört zum Kernfeld. Fahrer und Mitfahrer sollen verschiedenen unabhängigen Subdomänen angehören und dann separat verwaltet werden, was zu zwei Subdomänen Fahrgastverwaltung und Fahrerverwaltung führt. Der Adressbegriff gehört zum Teilgebiet der Adressverwaltung , der Fahrzeugbegriff zum Teilgebiet der Fahrerverwaltung.
Nach dem Teilen der Unterdomänen durch die Konzepte in der Domäne besteht der nächste Schritt darin, weiterhin neue Unterdomänen aus den Operationen in der Domäne zu entdecken. Im Benutzerszenario wird erwähnt, dass die Reiseroute überprüft werden muss, und diese Operation hat ihr entsprechendes Unterfeld Reiseroutenüberprüfung . Nachdem die Fahrt beendet ist, muss der Fahrgast eine Zahlung leisten, und dieser Vorgang hat sein entsprechendes Unterfeld Zahlungsverwaltung .
Die folgende Abbildung zeigt die Teilbereiche in der Beispielanwendung.
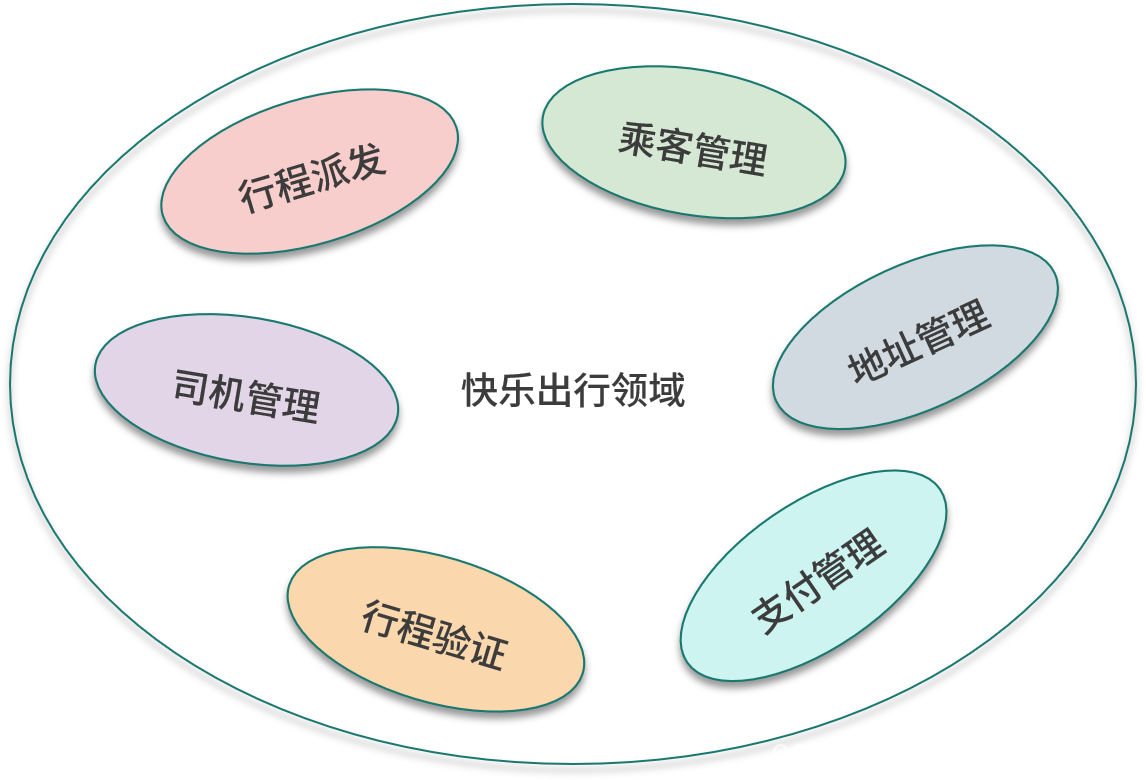 

begrenzter Kontext
Nach der Identifizierung der Kerndomäne und anderer Unterdomänen kann der nächste Schritt darin bestehen, vom Problemraum zum Lösungsraum zu wechseln. Zuerst werden die Teilbereiche auf den abgegrenzten Kontext abgebildet, und der abgegrenzte Kontext hat denselben Namen wie der Teilbereich, dann wird der abgegrenzte Kontext modelliert, und die Hauptaufgabe der Modellierung besteht darin, die zugehörigen Konzepte zu konkretisieren.
Reiseroutenverteilung
Die wichtige Entität im Reiserouten-Dispatch-Modell ist die Reiseroute, die auch die Wurzel des Aggregats ist, in dem sich die Reiseroute befindet. Eine Fahrt hat ihre Start- und Zielorte, ausgedrückt als Wertobjektadressen. Die Reiseroute wird durch den Fahrgast initiiert, daher muss die Reiserouteneinheit einen Bezug zu dem Fahrgast haben.Wenn das System einen Fahrer auswählt, um die Reiseroute anzunehmen, hat die Reiserouteneinheit eine Referenz zu dem Fahrer. Während des gesamten Lebenszyklus kann sich die Reise in verschiedenen Zuständen befinden, und es gibt ein Attribut und den entsprechenden Aufzählungstyp, um den Zustand der Reise zu beschreiben.
Die folgende Abbildung zeigt die Entitäten und Wertobjekte im Modell.
 

Passagiermanagement
Die wichtige Entität im Fahrgastverwaltungsmodell ist der Fahrgast, der auch die Wurzel des Aggregats ist, in dem sich der Fahrgast befindet. Zu den Attributen der Passagiereinheit gehören Name, E-Mail-Adresse, Kontaktnummer usw. Die Passagiereinheit hat eine Liste gespeicherter Adressen, die ihr zugeordnet sind, und die Adresse ist eine Einheit.
Die folgende Abbildung zeigt die Entitäten im Modell.
 

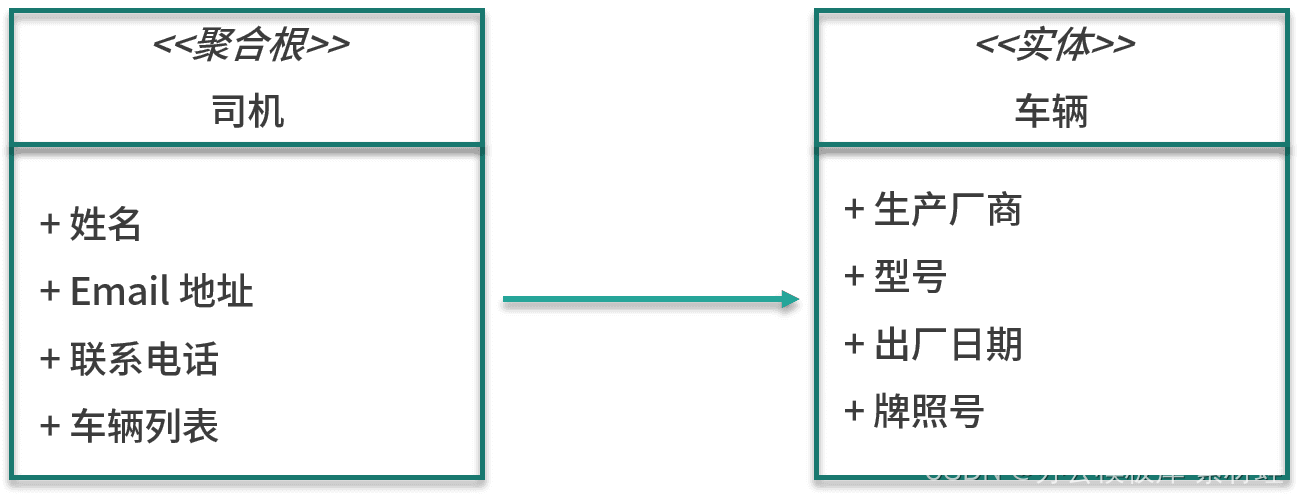
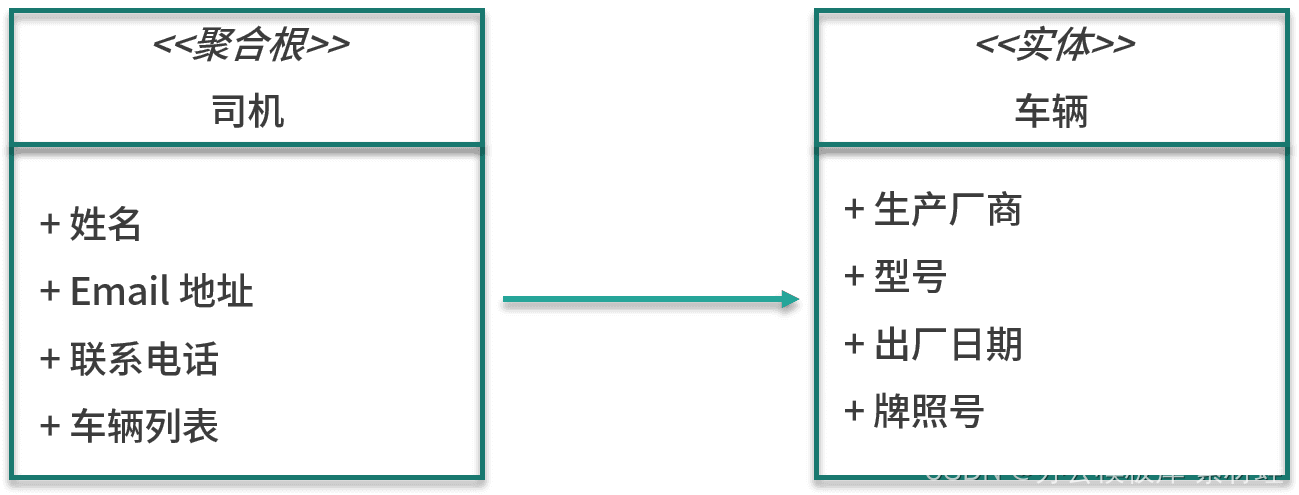
Fahrerverwaltung
Die wichtige Entität im Fahrerverwaltungsmodell ist der Fahrer, der auch die Wurzel des Aggregats ist, in dem sich der Fahrer befindet. Zu den Attributen der Entität Fahrer gehören Name, E-Mail-Adresse, Kontaktnummer usw. Neben der Entität Fahrer umfasst die Aggregation auch die Entität Fahrzeug Die Attribute der Entität Fahrzeug umfassen Hersteller, Modell, Herstellungsdatum und Lizenz Kennzeichen.
Die folgende Abbildung zeigt die Entitäten im Modell.

Adressverwaltung
Die wichtige Entität im Adressverwaltungsmodell ist die hierarchische Adresse, die von Provinzen, Gemeinden und autonomen Regionen bis hin zu Dörfern und Straßen reicht. Neben der hierarchischen Adresse gibt es noch eine weitere wichtige Information, nämlich die geografischen Ortskoordinaten inklusive Längen- und Breitengrad.
Reiseroutenüberprüfung
Das Reiseroutenverifizierungsmodell enthält keine spezifischen Entitäten, sondern Dienste und zugehörige Algorithmusimplementierungen, die die Reiseroute verifizieren.
Zahlungsverwaltung
Eine wichtige Entität im Zahlungsverwaltungsmodell ist der Zahlungsdatensatz, der Informationen wie Verweise auf Reiserouten und den Zahlungsstatus enthält.
Interaktion zwischen begrenzten Kontexten
In dem Modell unseres definierten Kontexts muss sich die Reiserouteneinheit des Reiseroutenabfertigungsmodells auf die Stammeinheit des Aggregats „Passagier“ im Fahrgastverwaltungsmodell und auf die Stammeinheit des Aggregats „Fahrer“ im Fahrerverwaltungsmodell beziehen . In Lektion 07 haben wir erwähnt, dass externe Objekte nur auf die Root-Entität des Aggregats verweisen können und beim Referenzieren auf die Kennung der Root-Entität des Aggregats verwiesen werden sollte, nicht auf die Entität selbst. Die Identifikatoren der Passenger-Entität und der Driver-Entität sind beide Zeichenfolgentypen, sodass die Trip-Entität zwei Eigenschaften des Typs String enthält, um auf die Passenger-Entität bzw. die Driver-Entität zu verweisen.
Wenn dasselbe Konzept in Modellen in unterschiedlichen abgegrenzten Kontexten erscheint, ist eine Abbildung erforderlich, und wir können den in Lektion 07 erwähnten Kontextabbildungsmodus für die Abbildung verwenden.
Sowohl im Zusammenhang mit der Adressverwaltung als auch mit dem Versand von Reiseplänen gibt es den Begriff einer Adresse. Die Adressinstanz in der Adressverwaltung ist ein komplexes Gebilde, das geographische Namen verschiedener Ebenen umfasst, wodurch eine mehrstufige Adressauswahl und Adressabfrage realisiert werden soll. Im Zusammenhang mit einem Reiseroutenversand besteht eine Adresse einfach aus einem vollständigen Namen und geografischen Standortkoordinaten. Um zwischen den beiden Kontexten abzubilden, können wir für die Modellkonvertierung eine Antikorrosionsschicht zum Reiseabfertigungskontext hinzufügen.
Migration bestehender monolithischer Anwendungen
Die Beispielanwendung in dieser Spalte ist eine von Grund auf neu erstellte Anwendung, sodass beim Teilen von Microservices auf keine vorhandene Implementierung verwiesen werden kann. Bei der Migration einer bestehenden monolithischen Anwendung auf eine Microservice-Architektur wird die Aufteilung der Microservices besser nachvollziehbar.Aus der bestehenden Implementierung der monolithischen Anwendung können Sie sich über das tatsächliche Zusammenspiel der einzelnen Teile des Systems informieren, was Ihnen hilft, es besser zu verstehen Es ist gut, sie nach ihren Verantwortlichkeiten aufzuteilen. Die so aufgeteilten Microservices sind näher an der tatsächlichen Betriebssituation.
Sam Newman von ThoughtWorks teilte in seinem Buch „Building Microservices“ seine Erfahrungen in der Microservice-Sparte des Produkts SnapCI.“ Aufgrund der einschlägigen Erfahrung aus dem Open-Source-Projekt GoCD teilte das SnapCI-Team die Microservices von SnapCI schnell auf. Allerdings gibt es einige Unterschiede zwischen den Benutzerszenarien von GoCD und SnapCI: Nach einiger Zeit stellte das SnapCI-Team fest, dass die aktuelle Aufteilung der Microservices viele Probleme mit sich brachte, da sie oft einige Änderungen über mehrere Microservices hinweg vornehmen mussten, was zu hohem Overhead führte . . .
Was das SnapCI-Team tat, war, diese Microservices wieder zu einem einzigen Monolithen zusammenzuführen, um ihnen mehr Zeit zu geben, zu verstehen, wie das System tatsächlich lief. Ein Jahr später teilte das SnapCI-Team dieses monolithische System erneut in Microservices auf.Nach dieser Aufteilung wurden die Grenzen der Microservices stabiler. Dieses Beispiel von SnapCI zeigt, dass Domänenwissen bei der Partitionierung von Microservices entscheidend ist.
Zusammenfassen
Die Partitionierung von Microservices ist entscheidend für die Anwendungsentwicklung von Microservice-Architekturen. Durch die Anwendung der Idee des domänengetriebenen Designs wird die Aufteilung von Microservices in die Aufteilung von Subdomänen im domänengetriebenen Design umgewandelt, und dann werden die Konzepte in der Domäne durch den definierten Kontext modelliert. Modelltransformationen können durch Abbildungsmuster zwischen definierten Kontexten durchgeführt werden.
Vorlesung 09: Rapid Deployment Development Environment und Framework
In diesem Kurs werden die Inhalte im Zusammenhang mit „Entwicklungsumgebung und Framework für schnelle Bereitstellung“ vorgestellt.
In den vorherigen Unterrichtsstunden haben wir das Hintergrundwissen zur Cloud-nativen Microservice-Architektur eingeführt, und die nächsten Unterrichtsstunden werden in die eigentliche Microservice-Entwicklung einfließen. Dieser Kurs ist der erste Kurs, der sich auf die Entwicklung von Microservices bezieht. Er konzentriert sich auf die Vorbereitung der lokalen Entwicklungsumgebung und stellt das Framework, Bibliotheken und Tools von Drittanbietern vor, die in der Beispielanwendung verwendet werden.
Notwendig für die Entwicklung
Entwicklungsvoraussetzungen beziehen sich auf diejenigen, die für die Entwicklungsumgebung erforderlich sind.
Java
Die Microservices der Beispielanwendung werden auf Basis von Java 8 entwickelt. Obwohl Java 14 veröffentlicht wurde, verwendet die Beispielanwendung immer noch die ältere Version von Java 8, da diese Version immer noch weit verbreitet ist und neue Funktionen, die nach Java 8 hinzugefügt wurden, für die Beispielanwendung nicht nützlich sind. Wenn JDK 8 nicht installiert ist, wird empfohlen, dass Sie zur AdoptOpenJDK- Website gehen, um das OpenJDK 8-Installationsprogramm herunterzuladen. Unter MacOS und Linux können Sie SDKMAN! verwenden , um JDK 8 zu installieren und verschiedene Versionen von JDK zu verwalten.
Das Folgende ist die Ausgabe von java -version:
openjdk-Version „1.8.0_242“ OpenJDK-Laufzeitumgebung (AdoptOpenJDK) (Build 1.8.0_242-b08) OpenJDK 64-Bit-Server-VM (AdoptOpenJDK) (Build 25.242-b08, gemischter Modus)
Maven
Das von der Beispielanwendung verwendete Build-Tool ist Apache Maven. Sie können Maven 3.6 manuell installieren oder das integrierte Maven in der IDE verwenden, um das Projekt zu erstellen. HomeBrew wird für MacOS und Linux empfohlen und Chocolatey wird für Windows empfohlen .
Integrierte Entwicklungsumgebung
Eine gute IDE kann die Entwicklerproduktivität erheblich verbessern. In Bezug auf IDE gibt es hauptsächlich zwei Möglichkeiten: IntelliJ IDEA und Eclipse; in Bezug auf die IDE-Wahl gibt es keinen großen Unterschied zwischen den beiden. Ich verwende IntelliJ IDEA Community Edition 2020.
Docker
Die lokale Entwicklungsumgebung muss Docker verwenden, um die unterstützenden Dienste auszuführen, die von der Anwendung benötigt werden, einschließlich Datenbank- und Nachrichten-Middleware. Durch Docker wird das Installationsproblem verschiedener Softwaredienste gelöst, wodurch die Konfiguration der Entwicklungsumgebung sehr einfach wird. Andererseits ist die Produktions- und Ausführungsumgebung der Anwendung Kubernetes, das ebenfalls mithilfe von Containerisierung bereitgestellt wird, wodurch die Konsistenz zwischen der Entwicklungsumgebung und der Produktionsumgebung sichergestellt wird. Um den lokalen Entwicklungsprozess zu vereinfachen, wird Docker Compose in der lokalen Umgebung zur Container-Orchestrierung verwendet.
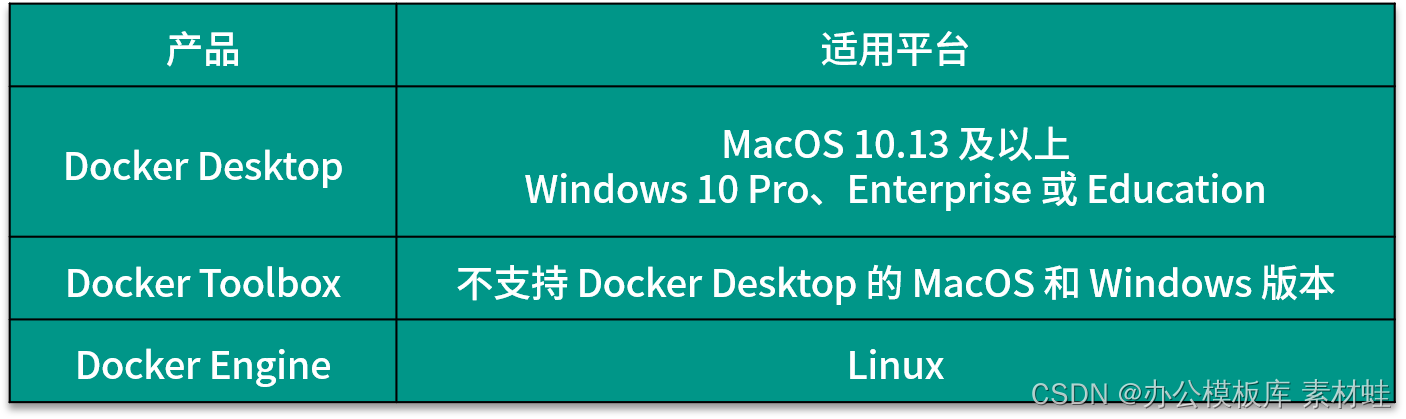
Je nach Betriebssystem der Entwicklungsumgebung ist der Weg zur Installation von Docker unterschiedlich. Es gibt 3 verschiedene Docker-Produkte, die zur Installation von Docker verwendet werden können, nämlich Docker Desktop, Docker Toolbox und Docker Engine. Die folgende Tabelle zeigt die anwendbaren Plattformen dieser 3 Produkte. Für MacOS und Windows sollte Docker Desktop zuerst installiert werden, wenn die Version dies unterstützt, und dann Docker Toolbox in Betracht gezogen werden.
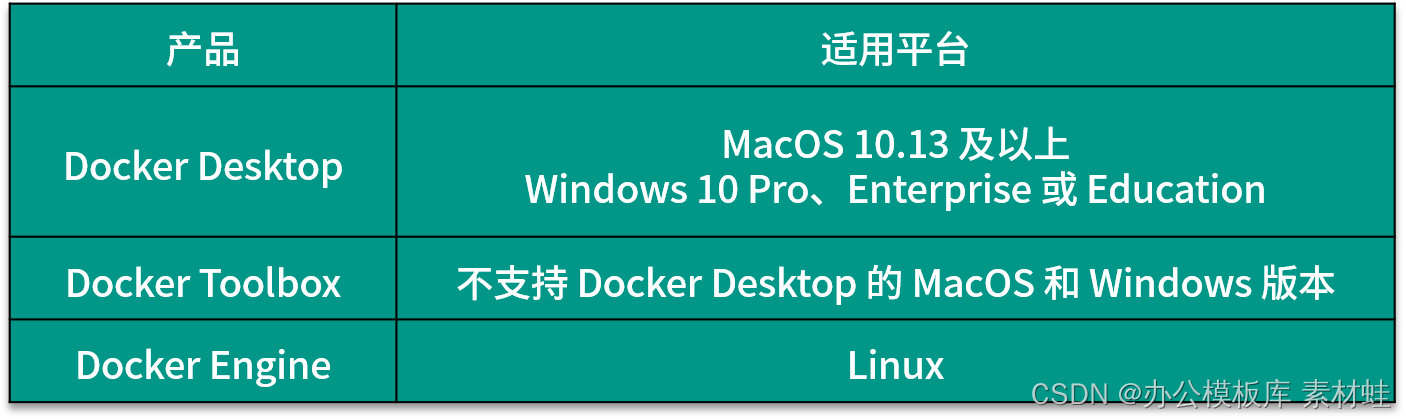 

Das Produkt Docker Desktop besteht aus vielen Komponenten, darunter Docker Engine, Docker Command Line Client, Docker Compose, Notary, Kubernetes und Credential Helper. Der Vorteil von Docker Desktop ist, dass es direkt die vom Betriebssystem bereitgestellte Virtualisierungsunterstützung nutzen kann, was eine bessere Integration ermöglichen kann.Darüber hinaus bietet Docker Desktop auch eine grafische Verwaltungsoberfläche. Meistens bedienen wir Docker über die Docker-Befehlszeile. Wenn der Befehl docker -v die richtigen Versionsinformationen anzeigen kann, bedeutet dies, dass Docker Desktop erfolgreich installiert wurde.
Die folgende Abbildung zeigt die Versionsinformationen von Docker Desktop.
 

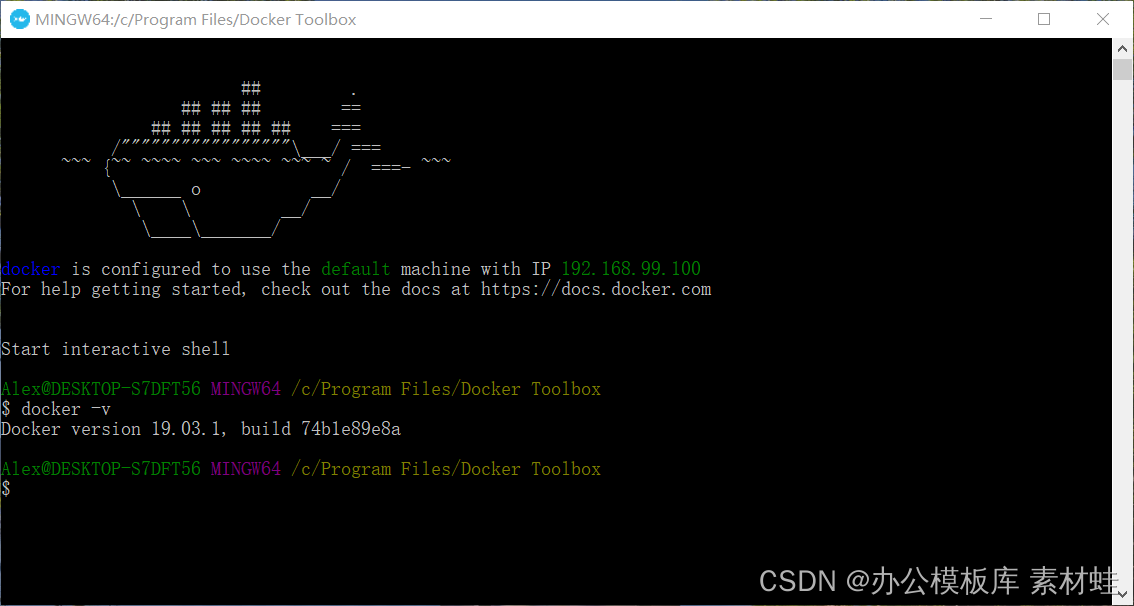
Docker Toolbox ist der Vorgänger von Docker Desktop. Docker Toolbox verwendet VirtualBox für die Virtualisierung, die geringe Systemanforderungen hat. Docker Toolbox besteht aus Docker Machine, Docker Command Line Client, Docker Compose, Kitematic und Docker Quickstart Terminal. Starten Sie nach Abschluss der Installation ein Terminal über Docker Quickstart, um Docker-Befehle auszuführen.
Die folgende Abbildung zeigt den laufenden Effekt des Docker Quickstart-Terminals.

Unter Linux können wir Docker Engine nur direkt installieren und müssen Docker Compose auch manuell installieren.
Es gibt einen wesentlichen Unterschied in der Verwendung von Docker Desktop und Docker Toolbox. Der Container, der auf Docker Desktop ausgeführt wird, kann das Netzwerk auf dem aktuellen Host der Entwicklungsumgebung verwenden, und auf den vom Container bereitgestellten Port kann mit localhost zugegriffen werden; der Container, der auf Docker Toolbox ausgeführt wird, wird tatsächlich auf einer virtuellen Maschine von VirtualBox ausgeführt, auf die zugegriffen werden muss über die IP-Adresse der virtuellen Maschine zugreifen. Wir können die IP-Adresse über den Befehl docker-machine ip auf dem von Docker Quickstart gestarteten Terminal abrufen, z. B. 192.168.99.100. Auf den vom Container bereitgestellten Port muss über diese IP-Adresse zugegriffen werden, die nicht festgelegt ist. Die empfohlene Vorgehensweise besteht darin, der Hosts-Datei einen Hostnamen namens dockervm hinzuzufügen und auf diese IP-Adresse zu verweisen. Verwenden Sie immer den Dockervm-Hostnamen, wenn Sie auf Dienste in Containern zugreifen. Wenn sich die IP-Adresse der virtuellen Maschine ändert, muss nur die Hosts-Datei aktualisiert werden.
Kubernetes
Bei der Bereitstellung von Anwendungen benötigen wir einen verfügbaren Kubernetes-Cluster.Im Allgemeinen gibt es drei Möglichkeiten, einen Kubernetes-Cluster zu erstellen.
Die erste Möglichkeit besteht darin, die Cloud-Plattform zum Erstellen von . Viele Cloud-Plattformen bieten Unterstützung für Kubernetes. Die Cloud-Plattform ist für die Erstellung und Verwaltung von Kubernetes-Clustern verantwortlich. Sie müssen nur die Weboberfläche oder Befehlszeilentools verwenden, um schnell Kubernetes-Cluster zu erstellen. Der Vorteil der Nutzung der Cloud-Plattform ist, dass sie Zeit und Aufwand spart, aber teuer ist.
Die zweite Möglichkeit besteht darin, einen Kubernetes-Cluster auf einer virtuellen Maschine oder einem physischen Bare-Metal zu installieren . Die virtuelle Maschine kann von der Cloud-Plattform bereitgestellt oder selbst erstellt und verwaltet werden, und es ist auch möglich, den selbst verwalteten physischen Bare-Metal-Cluster zu verwenden. Es sind viele Open-Source-Installationstools für Kubernetes verfügbar, z. B. RKE , Kubespray , Kubicorn usw. Der Vorteil dieser Methode ist, dass der Overhead relativ gering ist, aber der Nachteil ist, dass Vorinstallation und Nachwartung erforderlich sind.
Die dritte Möglichkeit besteht darin, Kubernetes in der lokalen Entwicklungsumgebung zu installieren . Docker Desktop kommt bereits mit Kubernetes, du musst es nur aktivieren, zusätzlich kannst du auch Minikube installieren . Dieser Ansatz hat den Vorteil, dass er den geringsten Overhead hat und gut kontrollierbar ist, der Nachteil ist, dass er viele Ressourcen in der lokalen Entwicklungsumgebung beansprucht.
Unter den oben genannten drei Methoden ist die Cloud-Plattform-Methode für die Bereitstellung der Produktionsumgebung geeignet. Für die Test- und Bereitstellungsvorbereitungsumgebung (Staging) können Sie eine Cloud-Plattform wählen oder die Umgebung aus Kostengründen selbst erstellen. Auch Kubernetes auf der lokalen Entwicklungsumgebung ist in vielen Fällen notwendig.
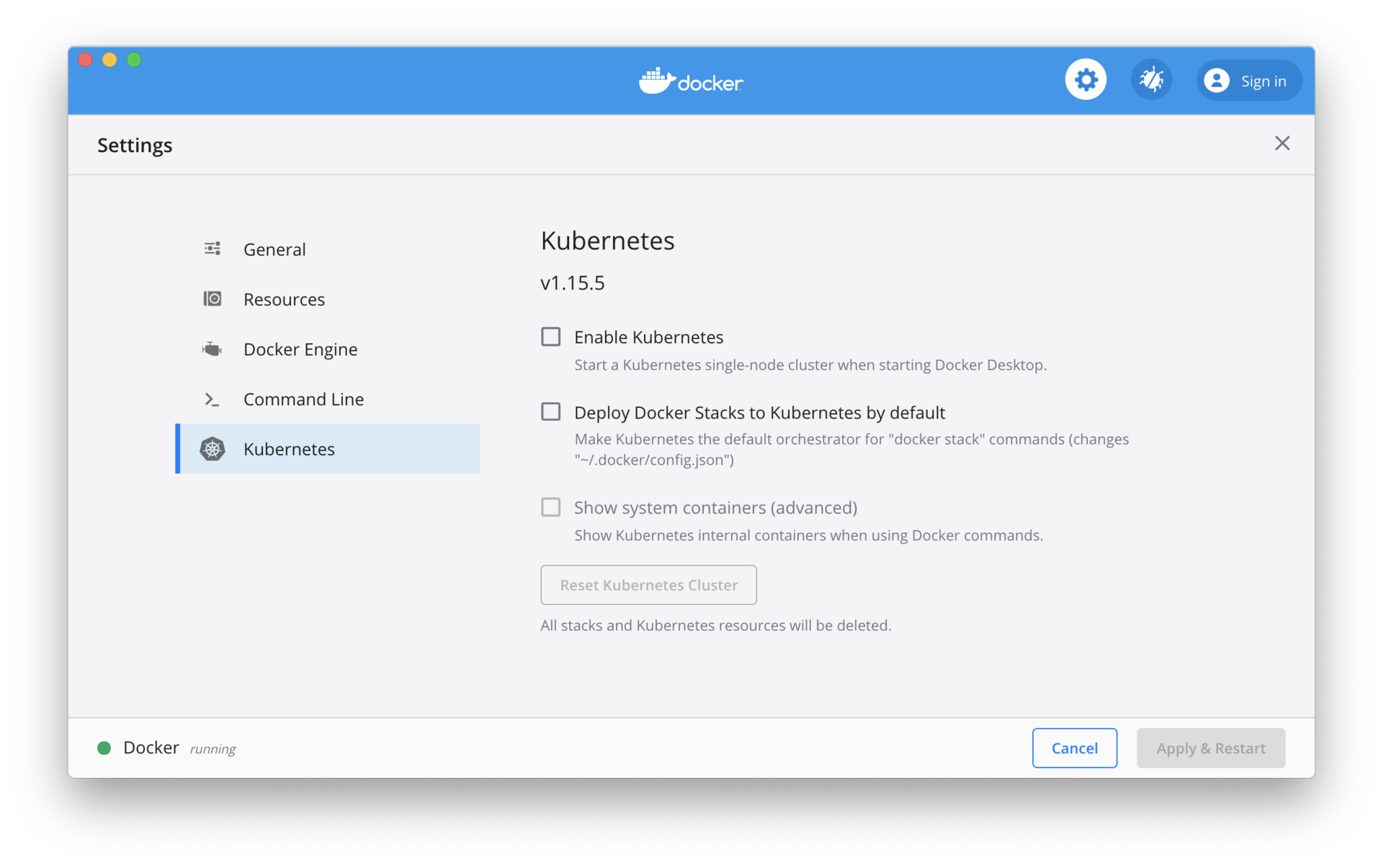
In einer lokalen Entwicklungsumgebung muss Kubernetes für Docker Desktop manuell aktiviert werden. Für Minikube können Sie sich auf die offizielle Dokumentation beziehen , um es zu installieren. Der Unterschied zwischen den beiden besteht darin, dass die mit Docker Desktop gelieferte Version von Kubernetes im Allgemeinen ein paar Nebenversionen hinterherhinkt. Aktivieren Sie, wie in der folgenden Abbildung gezeigt, die Option „Kubernetes aktivieren“, um den Kubernetes-Cluster zu starten. Die mit Docker Desktop gelieferte Kubernetes-Version ist 1.15.5, und die neueste Kubernetes-Version ist 1.18.

Frameworks und Bibliotheken von Drittanbietern
Die Beispielanwendung verwendet einige Frameworks und Bibliotheken von Drittanbietern, die im Folgenden kurz vorgestellt werden.
Spring Framework und Spring Boot
Es ist schwierig, Java-Anwendungen ohne das Spring-Framework zu entwickeln. Spring Boot stellt derzeit auch eine der beliebtesten Möglichkeiten für die Entwicklung von Microservices in Java dar. Die Einführung von Spring und Spring Boot würde den Rahmen dieser Kolumne sprengen. Die Microservices der Beispielanwendung verwenden einige Unterprojekte im Spring-Framework, darunter Spring Data JPA, Spring Data Redis und Spring Security.
Eventuelle Straßenbahn
Eventuate Tram ist ein Transaktionsnachrichten-Framework, das von der Beispielanwendung verwendet wird.Der Transaktionsnachrichtenmodus spielt eine wichtige Rolle bei der Aufrechterhaltung der Datenkonsistenz. Eventuate Tram bietet Unterstützung für transaktionale Messaging-Muster und umfasst auch Unterstützung für asynchrones Messaging. Eventuate Tram lässt sich in PostgreSQL und Kafka integrieren.
Axon-Server und Framework
Die Beispielanwendung verwendet auch Event-Sourcing- und CQRS-Technologie, und die Event-Sourcing-Implementierung verwendet Axon-Server und Axon-Framework. Der Axon-Server bietet Ereignisspeicherung; das Axon-Framework stellt eine Verbindung zum Axon-Server her und bietet CQRS-Unterstützung.
Support-Services und Tools
Die unterstützenden Dienste der Beispielanwendung sind zur Laufzeit erforderlich, und die zugehörigen Tools können in der Entwicklung verwendet werden.
Apache Kafka und ZooKeeper
Die Beispielanwendung verwendet asynchrone Nachrichten zwischen verschiedenen Microservices, um die endgültige Konsistenz der Daten sicherzustellen, daher ist Nachrichten-Middleware erforderlich. Apache Kafka ist die Nachrichten-Middleware, die in der Beispielanwendung verwendet wird, und ZooKeeper ist erforderlich, um Kafka auszuführen.
PostgreSQL
Einige der Microservices der Beispielanwendung verwenden eine relationale Datenbank zum Speichern von Daten. Unter vielen relationalen Datenbanken wird PostgreSQL als Datenbank für einige Microservices in der Beispielanwendung ausgewählt.
Datenbankverwaltungstool
In der Entwicklung müssen wir möglicherweise Daten in einer relationalen Datenbank anzeigen. Es sind viele PostgreSQL-Clients verfügbar, einschließlich DBeaver , pgAdmin 4 , OmniDB usw. Sie können auch IDE-Plug-Ins verwenden, z. B. das Database Navigator- Plug-In für IntelliJ IDEA.
Briefträger
In der Entwicklung und beim Testen müssen wir häufig HTTP-Anfragen senden, um REST-Dienste zu testen. Es gibt viele Tools zum Testen von REST-Diensten, wie Postman , Insomnia und Advanced REST Client . Ich empfehle die Verwendung von Postman, da es OpenAPI-Spezifikationsdateien direkt importieren und entsprechende REST-Anforderungsvorlagen generieren kann. Da unsere Microservices einen API-First-Designansatz verfolgen, verfügt jede Microservice-API über eine entsprechende OpenAPI-Spezifikationsdatei. Während der Entwicklung müssen wir nur die OpenAPI-Datei in Postman importieren, und dann können wir mit dem Testen beginnen, was uns die Arbeit der manuellen Erstellung von Anfragen erspart.
Zusammenfassen
Bevor wir den eigentlichen Kampf erklären, müssen wir zuerst die lokale Entwicklungsumgebung vorbereiten. Dieser Kurs führt zunächst in die Installation und Konfiguration von Java, Maven, der integrierten Entwicklungsumgebung, Docker und Kubernetes ein, stellt dann kurz das Framework und die Bibliotheken von Drittanbietern vor, die in der Beispielanwendung verwendet werden, und stellt schließlich die unterstützenden Dienste vor, die von der Beispielanwendung verwendet werden, und die Werkzeuge, die für die Entwicklung benötigt werden.
Vorlesung 10: API-First-Design mit OpenAPI und Swagger
Ausgehend von dieser Klasse steigen wir in die eigentliche Entwicklung von Cloud-nativen Microservice-Architekturanwendungen ein.Bevor wir die konkrete Implementierung von Microservices vorstellen, besteht die erste Aufgabe darin, die offene API jedes Microservices zu entwerfen und festzulegen . Open API war in den letzten Jahren weit verbreitet, und viele Online-Dienste und Regierungsbehörden haben Open API bereitgestellt, das zu einer Standardfunktion von Online-Diensten geworden ist. Entwickler können die offene API verwenden, um verschiedene Anwendungen zu entwickeln.
Obwohl es eine gewisse Beziehung zwischen der offenen API in der Microservice-Anwendung und der offenen API im Onlinedienst gibt, sind ihre Funktionen unterschiedlich. In der Anwendung der Microservice-Architektur können Microservices nur durch Kommunikation zwischen Prozessen interagieren, im Allgemeinen unter Verwendung von REST oder gRPC. Eine solche Interaktionsmethode muss formalisiert festgelegt werden und eine offene API bilden. Eine offene API eines Microservices schirmt die internen Implementierungsdetails des Service von externen Benutzern ab und ist auch die einzige Möglichkeit für externe Benutzer, damit zu interagieren ( bezieht sich hier natürlich auf die Integration zwischen Microservices nur über API, wenn asynchrone Events zur Integration verwendet werden, sind diese Events auch interaktiv). Daraus können wir die Bedeutung der Microservice-API erkennen. Aus Sicht des Publikums sind die Nutzer von Microservice-APIs hauptsächlich andere Microservices, also hauptsächlich interne Benutzer der Anwendung, was anders ist als die API von Online-Diensten, die hauptsächlich auf externe Benutzer ausgerichtet sind. Neben anderen Microservices müssen auch die Webschnittstelle der Anwendung und mobile Clients die API des Microservice verwenden, aber sie verwenden die API des Microservice normalerweise über ein API-Gateway.
Aufgrund der Bedeutung der Microservice-API müssen wir die API sehr früh entwerfen, d. h. die API-First-Strategie.
Eine API-First-Strategie
Wenn Sie Erfahrung in der Entwicklung von Online-Service-APIs haben, werden Sie feststellen, dass normalerweise zuerst die Implementierung kommt, gefolgt von der öffentlichen API, da die öffentliche API nicht vor dem Design berücksichtigt wurde, sondern später hinzugefügt wurde. Das Ergebnis dieses Ansatzes ist, dass die offene API nur die aktuelle tatsächliche Implementierung widerspiegelt, nicht das, was die API sein sollte. Die Designmethode von API first (API First) besteht darin, das Design der API vor die spezifische Implementierung zu stellen. API first betont, dass das Design der API eher aus der Perspektive der API-Benutzer betrachtet werden sollte.
Bevor die erste Zeile des Implementierungscodes niedergeschrieben wird, sollten der API-Anbieter und der Benutzer eine vollständige Diskussion über die API führen, die Meinungen der beiden Seiten kombinieren, schließlich alle Details der API festlegen und sie in einem formalen Format fixieren eine API-Spezifikation. Danach stellt der Anbieter der API sicher, dass die tatsächliche Implementierung die Anforderungen der API-Spezifikation erfüllt, und der Benutzer schreibt die Client-Implementierung gemäß der API-Spezifikation. Die API-Spezifikation ist ein Vertrag zwischen dem Anbieter und dem Benutzer, und die API-First-Strategie wurde bei der Entwicklung vieler Online-Dienste angewendet. Nachdem die API entworfen und implementiert wurde, werden die Webschnittstelle und die mobile Anwendung des Onlinedienstes selbst, wie andere Anwendungen von Drittanbietern, unter Verwendung derselben API implementiert.
Die API-First-Strategie spielt eine wichtigere Rolle bei der Anwendungsimplementierung der Microservice-Architektur. Hier müssen zwei Arten von APIs unterschieden werden: Zum einen die für andere Microservices bereitgestellte API und zum anderen die für das Webinterface und mobile Clients bereitgestellte API. Bei der Einführung in das domänengetriebene Design in der 07. Klasse habe ich den offenen Hostdienst und die öffentliche Sprache im Abbildungsmodus des begrenzten Kontexts erwähnt, und die Microservices entsprechen dem begrenzten Kontext eins zu eins. Wenn Sie den offenen Hostdienst mit der gemeinsamen Sprache kombinieren, erhalten Sie die API des Microservices, und die gemeinsame Sprache ist die Spezifikation der API.
Von hier aus können wir wissen, dass der Zweck der ersten Art von Microservice-API die Kontextzuordnung ist, die sich erheblich von der Rolle der zweiten Art von API unterscheidet. Beispielsweise stellt der Passagierverwaltungsmikrodienst Funktionen zum Verwalten von Passagieren bereit, einschließlich Passagierregistrierung, Informationsaktualisierung und Abfrage. Für die Fahrgast-App benötigen diese Funktionen die Unterstützung der API. Wenn andere Microservices Fahrgastinformationen erhalten müssen, müssen diese ebenfalls die API des Microservice Fahrgastmanagement aufrufen. Dies dient dazu, das Konzept der Passagiere zwischen verschiedenen Microservices abzubilden.
API-Implementierung
Bei der API-Implementierung besteht eines der ersten Probleme darin, die Implementierungsmethode der API auszuwählen. Theoretisch haben die internen APIs von Microservices keine hohen Anforderungen an die Interoperabilität und können private Formate verwenden. Um das Service Grid zu nutzen, empfiehlt es sich jedoch, ein gängiges Standardformat zu verwenden, die folgende Tabelle zeigt das gängige API-Format. Wählen Sie im Allgemeinen zwischen REST und gRPC, außer dass Sie weniger SOAP verwenden. Der Unterschied zwischen den beiden besteht darin, dass REST ein Textformat und gRPC ein Binärformat verwendet; die beiden unterscheiden sich in Popularität, Implementierungsschwierigkeiten und Leistung. Kurz gesagt, REST ist relativ beliebter und weniger schwierig zu implementieren, aber seine Leistung ist nicht so gut wie die von gRPC.
 

Die API für die Beispielanwendung in dieser Spalte wird mit REST implementiert, obwohl es eine Klasse gibt, die gRPC gewidmet ist. Im Folgenden wird die OpenAPI-Spezifikation in Bezug auf die REST-API beschrieben.
OpenAPI-Spezifikation
Um besser zwischen API-Anbietern und Benutzern kommunizieren zu können, brauchen wir ein Standardformat zur Beschreibung von APIs. Für REST-APIs wird dieses Standardformat durch die OpenAPI-Spezifikation definiert.
Die OpenAPI-Spezifikation (OAS) ist eine offene API-Spezifikation, die von der OpenAPI Initiative (OAI) unter der Linux Foundation verwaltet wird. Das Ziel des OAI ist es, ein herstellerneutrales API-Beschreibungsformat zu erstellen, weiterzuentwickeln und zu fördern. Die OpenAPI-Spezifikation basiert auf der Swagger-Spezifikation, gestiftet von der SmartBear Corporation.
Das OpenAPI-Dokument beschreibt oder definiert die API, und das OpenAPI-Dokument muss der OpenAPI-Spezifikation entsprechen. Die OpenAPI-Spezifikation definiert das Inhaltsformat eines OpenAPI-Dokuments, d. h. die Objekte und ihre Attribute, die darin enthalten sein können. Ein OpenAPI-Dokument ist ein JSON-Objekt, das im JSON- oder YAML-Dateiformat dargestellt werden kann. Das Folgende stellt eine Einführung in das Format des OpenAPI-Dokuments dar. Die Codebeispiele in dieser Lektion verwenden alle das YAML-Format.
In der OpenAPI-Spezifikation sind mehrere Grundtypen definiert, nämlich Integer, Number, String und Boolean. Für jeden Grundtyp kann das spezifische Format des Datentyps über das Formatfeld angegeben werden, beispielsweise kann das Format des Zeichenfolgentyps Datum, Datum-Uhrzeit oder Passwort sein.
Die Felder und ihre Beschreibungen, die im Stammobjekt des OpenAPI-Dokuments erscheinen können, sind in der folgenden Tabelle angegeben.Die neueste Version der OpenAPI-Spezifikation ist 3.0.3.
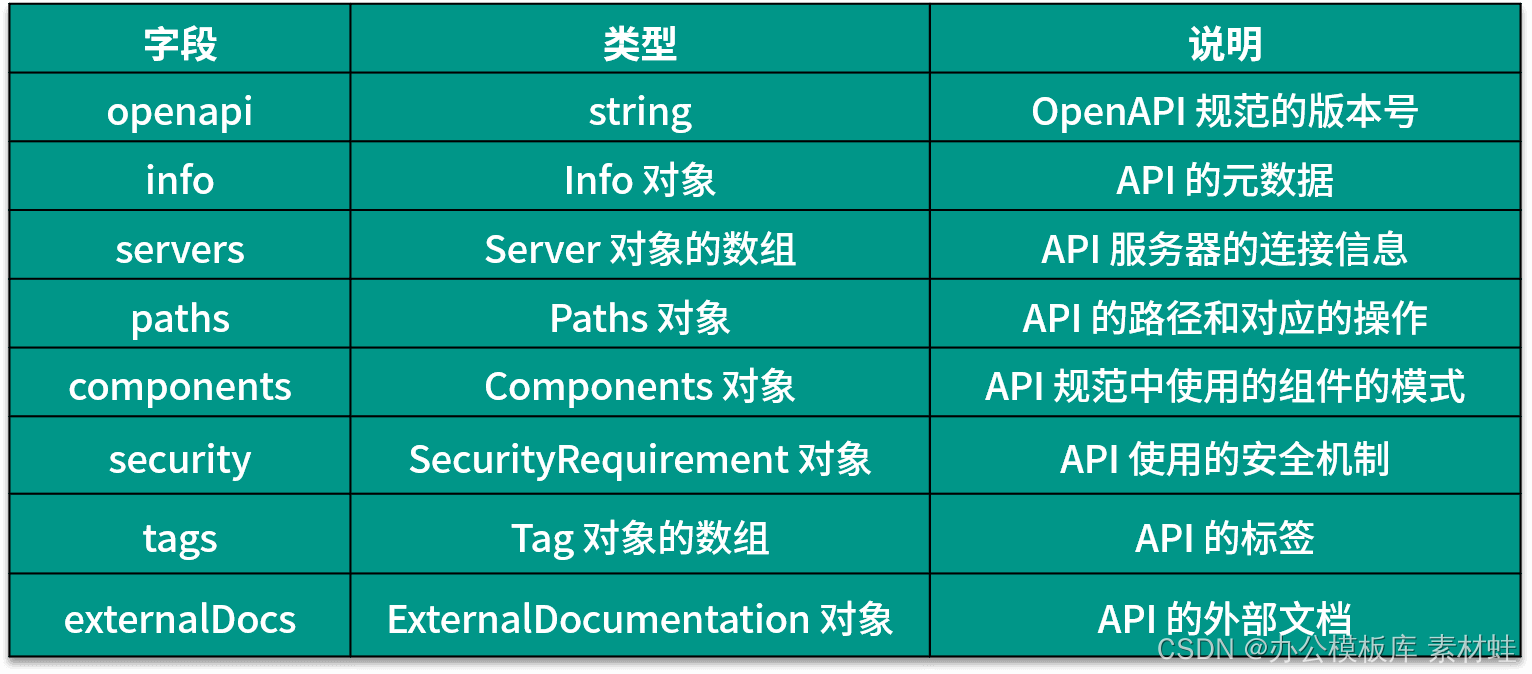 

Info-Objekt
Das Info-Objekt enthält die Metadaten der API, die Benutzern helfen können, die relevanten Informationen der API besser zu verstehen. Die folgende Tabelle zeigt die Felder, die in das Info-Objekt aufgenommen werden können, und ihre Beschreibungen.
 

Der folgende Code ist ein Beispiel für die Verwendung des Info-Objekts.
Titel: Testdienst Beschreibung: Dieser Dienst dient zum einfachen Testen der Servicebedingungen: http://myapp.com/terms/ Kontakt: Name: Administrator URL: http://www.myapp.com/support E-Mail: support@myapp .com Lizenz: Name: Apache 2.0 URL: https://www.apache.org/licenses/LICENSE-2.0.html Version: 2.1.0
Serverobjekt
Das Server-Objekt stellt den Server der API dar. Die folgende Tabelle zeigt die Felder, die in das Server-Objekt aufgenommen werden können, und ihre Beschreibungen.
 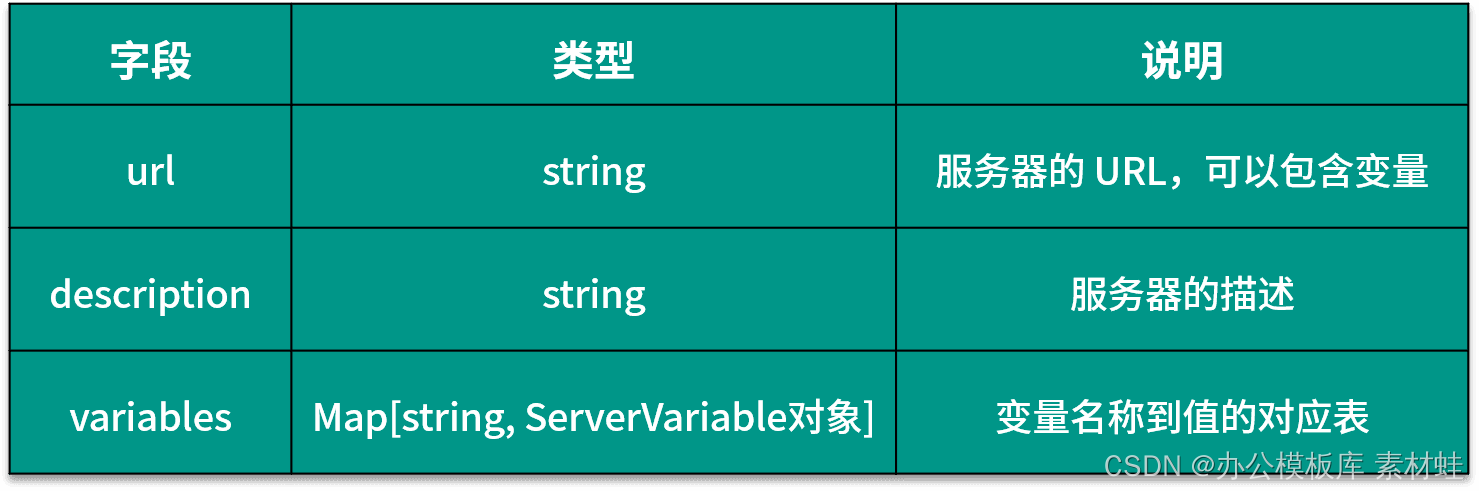

Der folgende Code ist ein Beispiel für die Verwendung des Serverobjekts, wobei die URL des Servers zwei Parameter enthält, port und basePath, port ein Aufzählungstyp ist und die optionalen Werte 80 und 8080 sind.
url: http://test.myapp.com:{port}/{basePath}
description: Testservervariablen
:
port:
enum:
- '80'
- '8080'
default: '80'
basePath:
default: v2
Pfade-Objekt
Die Felder im Paths-Objekt sind dynamisch. Jedes Feld stellt einen Pfad dar, beginnend mit „/“, der Pfad kann eine Zeichenfolgenvorlage sein, die Variablen enthält. Der Wert des Felds ist ein PathItem-Objekt, in dem Sie allgemeine Felder wie Zusammenfassung, Beschreibung, Server und Parameter sowie HTTP-Methodennamen verwenden können, einschließlich get, put, post, delete, options, head, patch und trace , die das Methodennamensfeld definiert die HTTP-Methoden, die vom entsprechenden Pfad unterstützt werden.
Operationsobjekt
Im Paths-Objekt ist der Werttyp des Felds, das der HTTP-Methode entspricht, ein Operation-Objekt, das eine HTTP-Operation darstellt. Die folgende Tabelle zeigt die Felder und ihre Beschreibungen, die in das Operation-Objekt aufgenommen werden können.Von diesen Feldern werden Parameter, RequestBody und Responses häufiger verwendet.
 

Parameterobjekt
Ein Parameter-Objekt repräsentiert die Parameter einer Operation. Die folgende Tabelle zeigt die Felder, die in einem Parameterobjekt enthalten sein können, und ihre Beschreibungen.
 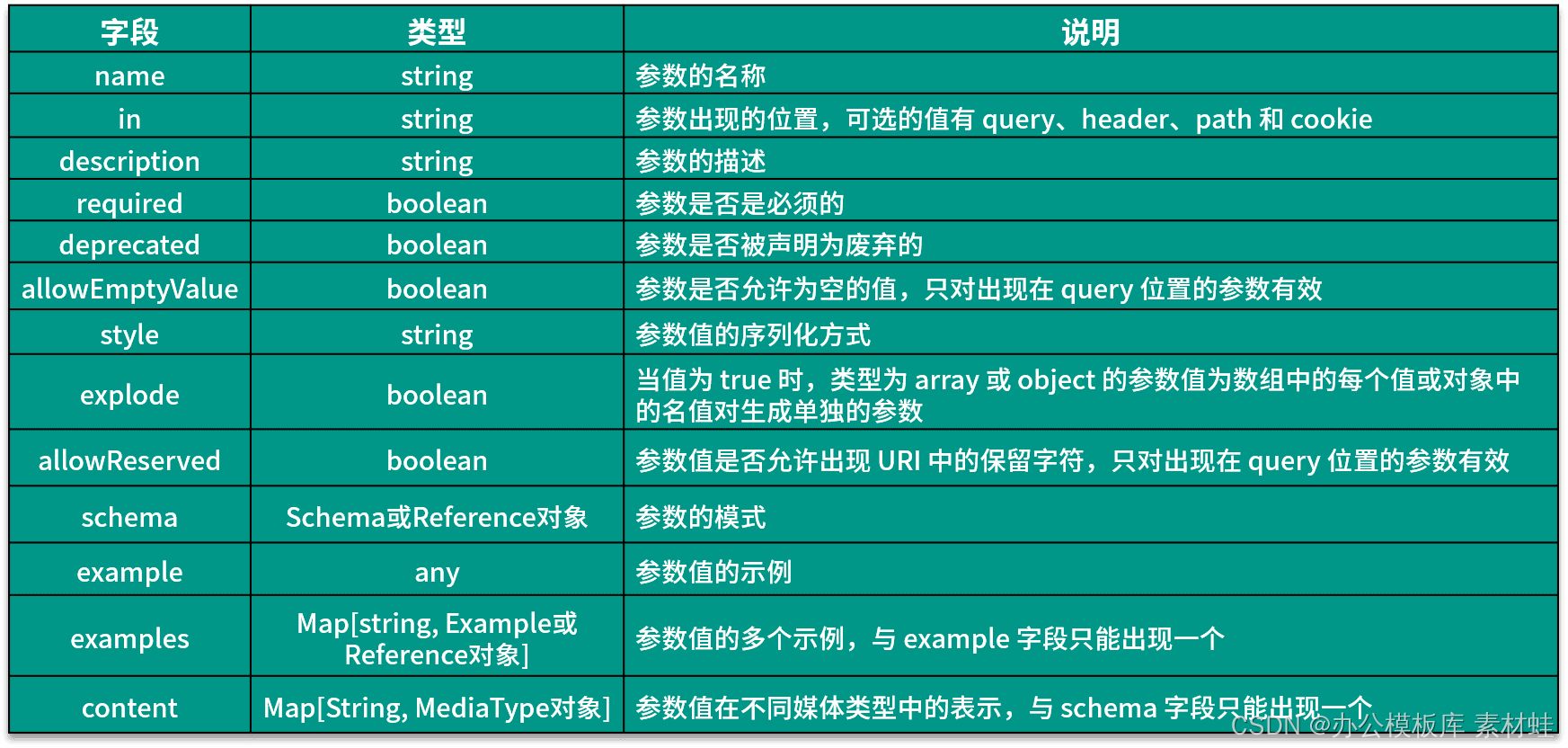

Der folgende Code stellt ein Beispiel für die Verwendung des Parameter-Objekts dar. Die Parameter-ID erscheint im Pfad und ihr Typ ist Zeichenfolge.
name: id in: path description: 乘客ID erforderlich: true schema: type: string
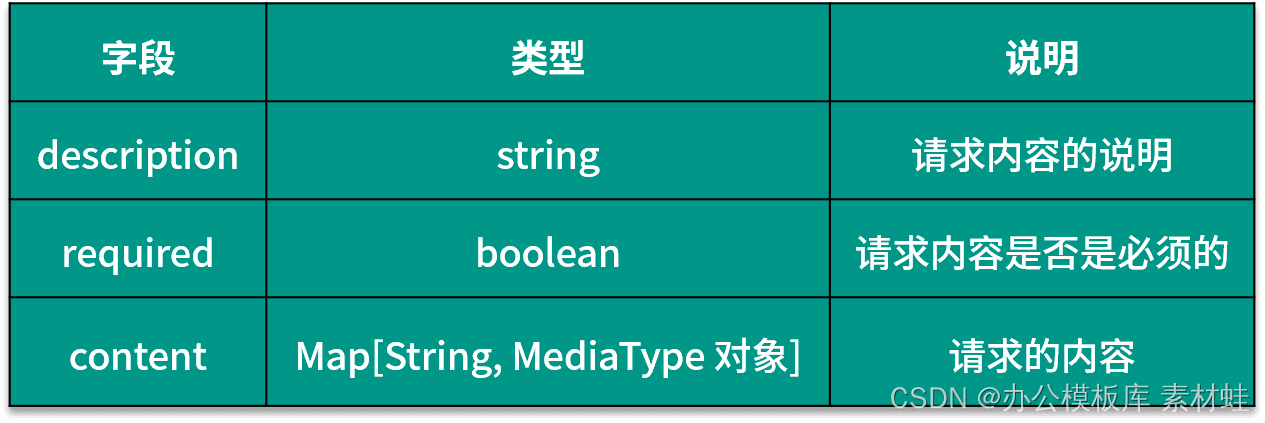
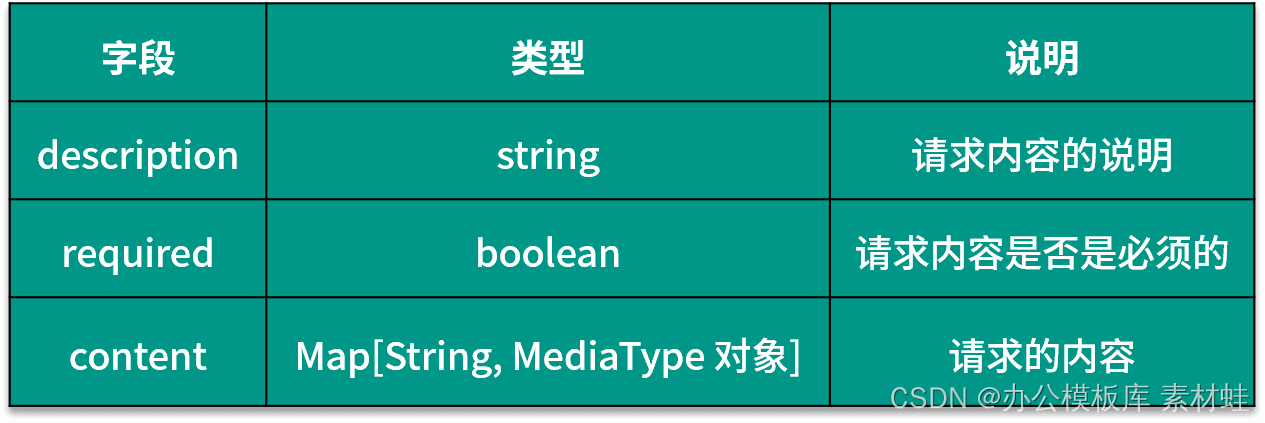
RequestBody-Objekt
Das RequestBody-Objekt stellt den Inhalt der HTTP-Anforderung dar. Die folgende Tabelle zeigt die Felder, die im RequestBody-Objekt enthalten sein können, und ihre Beschreibungen.

Responses-Objekt
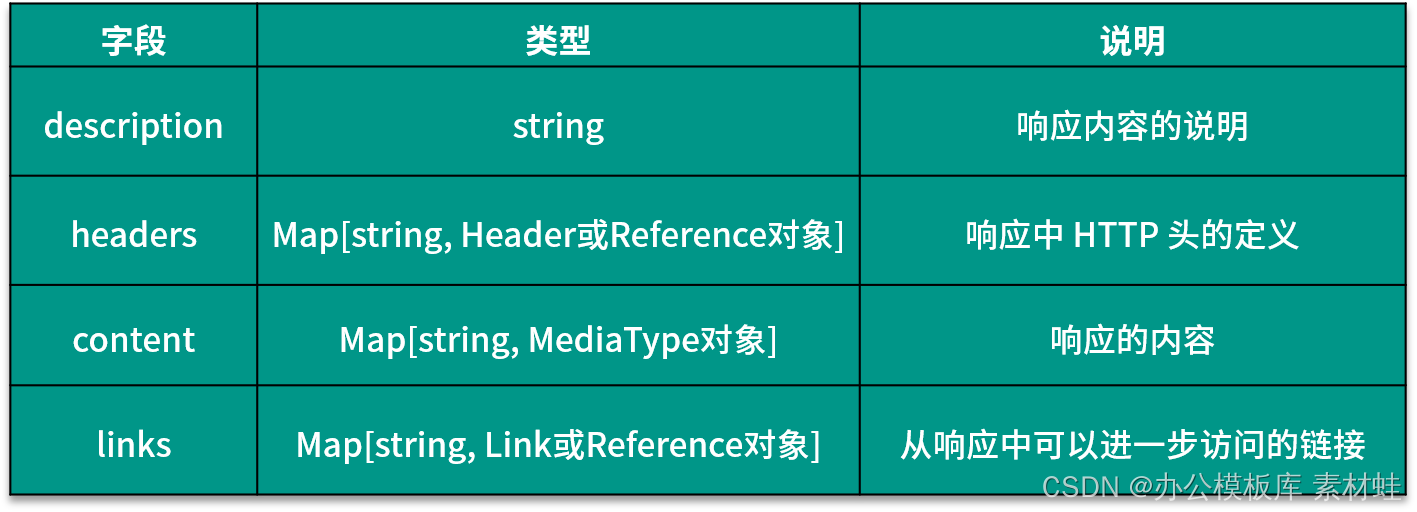
Das Responses-Objekt stellt die Antwort auf die HTTP-Anforderung dar, und die Felder in diesem Objekt sind dynamisch. Der Name des Felds ist der Statuscode der HTTP-Antwort, und der Typ des entsprechenden Werts ist ein Response- oder Reference-Objekt. Die folgende Tabelle zeigt die Felder, die in das Response-Objekt aufgenommen werden können, und ihre Beschreibungen.

Bezugsobjekt
Bei der Beschreibung verschiedener Arten von Objekten kann der Feldtyp ein Referenzobjekt sein, das eine Referenz auf andere Komponenten darstellt, die nur ein $ref-Feld enthält, um die Referenz zu deklarieren. Verweise können auf Komponenten innerhalb desselben Dokuments oder aus externen Dateien erfolgen. Innerhalb des Dokuments können verschiedene Arten von wiederverwendbaren Komponenten im Components-Objekt definiert und durch das Reference-Objekt referenziert werden; die Referenz innerhalb des Dokuments ist ein Objektpfad, der mit # beginnt, wie beispielsweise #/components/schemas/CreateTripRequest.
Schema-Objekt
Das Schema-Objekt wird verwendet, um die Definition des Datentyps zu beschreiben. Der Datentyp kann ein einfacher Typ, ein Array oder ein Objekttyp sein. Der Typ kann durch das Feld type angegeben werden, und das Formatfeld gibt das Format des Typs an . Wenn es sich um einen Array-Typ handelt, d. h. der Wert von type ist Array, müssen Sie die Feldelemente verwenden, um den Typ der Elemente im Array darzustellen; wenn es sich um einen Objekttyp handelt, ist der Wert von type objekt , müssen Sie die Feldeigenschaften verwenden, um den Typ der Eigenschaften im Objekt darzustellen.
Vollständiges Dokumentationsbeispiel
Unten sehen Sie ein Beispiel für ein vollständiges OpenAPI-Dokument. Im Pfadobjekt sind drei Operationen definiert, und die Typdefinition des Anforderungsinhalts und des Antwortformats der Operation ist im Feld schemas des Komponentenobjekts definiert. Sowohl das RequestBody- als auch das Response-Feld einer Operation werden mit einem Reference-Objekt referenziert.
openapi: '3.0.3'
info:
title: Trip service
version: '1.0'
server:
- url: http://localhost:8501/api/v1
tags:
- name: trip
description: Reisebezogene
Pfade:
/:
post:
Tags:
-
Reisezusammenfassung: Reise erstellen
operationId: createTrip
requestBody:
Inhalt:
Anwendung/json:
Schema:
$ref: "#/components/schemas/CreateTripRequest"
erforderlich: wahr
Antworten:
'201':
Beschreibung: erfolgreich erstellt
/{tripId} :
bekommen:
Tags:
-
Fahrtzusammenfassung: Fahrtoperations-ID abrufen
: GetTrip-
Parameter:
- Name: TripId
in:
Pfadbeschreibung: Fahrt-ID
erforderlich: True
Schema:
Typ: Zeichenfolge
Antworten:
'200':
Beschreibung: Erfolgsinhalt abrufen
:
Anwendung/json:
Schema:
$ref: "#/components/schemas/TripVO"
'404':
description: Trip not found
/{tripId}/accept:
post:
tags:
- trip
Zusammenfassung: 接受行程
Typ: Zeichenfolge
operationId: acceptTrip
parameter:
- name: tripId
in: path
description: 行程ID
erforderlich: true
schema:
type: string
requestBody:
content:
application/json:
schema:
$ref: "#/components/schemas/AcceptTripRequest"
required: true
responses:
'200 ':
Beschreibung: 接受成功
Komponenten:
Schemas:
CreateTripRequest:
Typ: Objekteigenschaften
:
PassengerId:
StartPos:
$ref: "#/components/schemas/PositionVO"
endPos:
$ref: "#/components/schemas/PositionVO"
erforderlich:
- PassengerId
- StartPos
- EndPos
AcceptTripRequest:
type: object
properties:
driverId:
type: string
posLng:
type: Zahlenformat
: Double
PosLat:
Typ: Zahlenformat
: Double
Erforderlich:
- DriverId
- PosLng
- PosLat
TripVO:
Typ: Objekteigenschaften
:
ID:
Typ: String
PassengerId:
Typ: String
DriverId:
Typ: String
StartPos:
$ref: "#/components/schemas/PositionVO"
EndPos:
$ref: "#/components/schemas/PositionVO"
Status:
Typ: Zeichenfolge
PositionVO:
Typ: Objekteigenschaften
:
lng:
Typ: Zahlenformat
: Double
Lat:
Typ: Zahlenformat
: Double
AddressId:
Typ: Zeichenfolge
erforderlich:
- Lng
- Lat
OpenAPI-Tools
Wir können einige Tools verwenden, um die Entwicklung im Zusammenhang mit der OpenAPI-Spezifikation zu unterstützen. Als Vorgänger der OpenAPI-Spezifikation bietet Swagger viele Tools im Zusammenhang mit OpenAPI.
Swagger-Editor
Swagger Editor ist eine Webversion des Swagger- und OpenAPI-Dokumentationseditors. Auf der linken Seite des Editors befindet sich der Editor und auf der rechten Seite eine Vorschau der API-Dokumentation. Der Swagger-Editor bietet viele nützliche Funktionen, einschließlich Syntaxhervorhebung, schnelles Hinzufügen verschiedener Objekttypen, Generieren von Servercode und Generieren von Clientcode usw.
Wenn Sie den Swagger-Editor verwenden, können Sie die Online-Version direkt verwenden oder ihn lokal ausführen. Der einfachste Weg, ihn lokal auszuführen, ist die Verwendung des Docker-Images swaggerapi/swagger-editor.
Der folgende Code startet den Docker-Container des Swagger-Editors. Nachdem der Container gestartet wurde, kann auf ihn über localhost:8000 zugegriffen werden.
docker run -d -p 8000:8080 Swaggerapi/Swagger-Editor
Die folgende Abbildung zeigt die Oberfläche des Swagger-Editors.
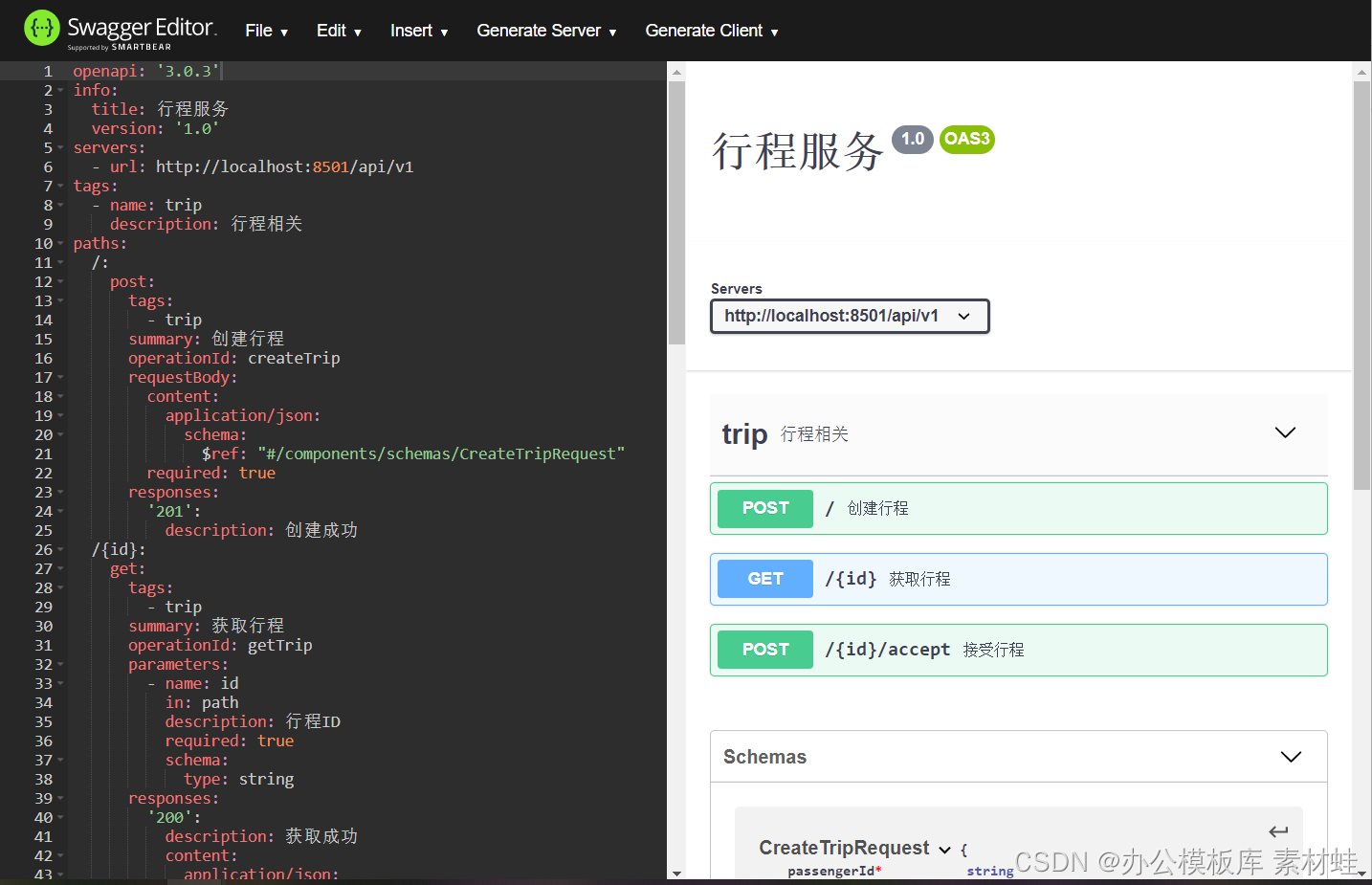 

Swagger-Schnittstelle
Die Swagger-Oberfläche bietet eine intuitive Möglichkeit zum Anzeigen und Interagieren mit der API-Dokumentation. Über diese Schnittstelle können Sie HTTP-Anforderungen direkt an den API-Server senden und die Antwortergebnisse anzeigen.
Ebenso können wir Docker verwenden, um die Swagger-Schnittstelle zu starten, wie im folgenden Befehl gezeigt. Nachdem der Container gestartet wurde, kann über localhost:8010 darauf zugegriffen werden.
docker run -d -p 8010:8080 swaggerapi/swagger-ui
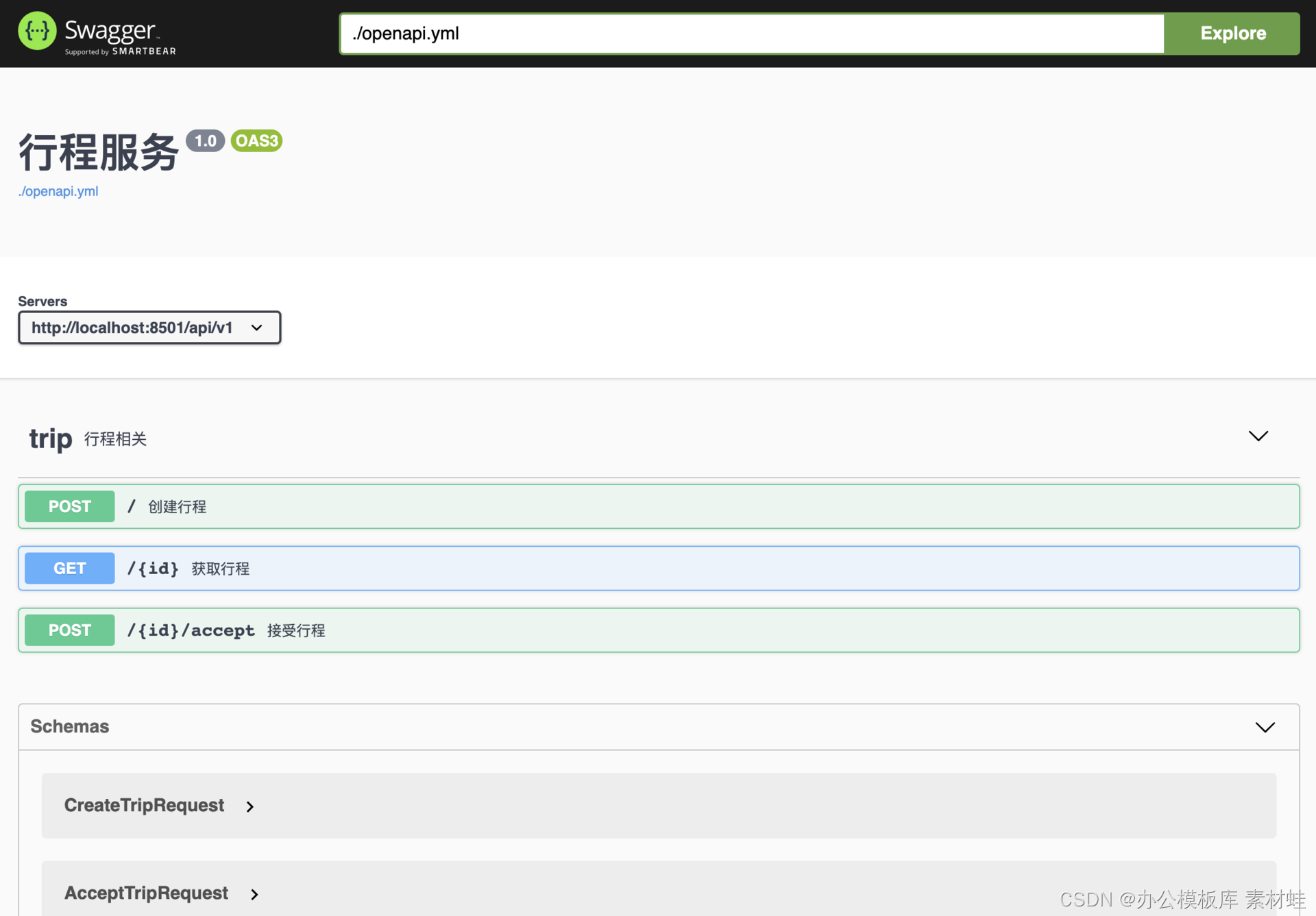
Für die lokale OpenAPI-Dokumentation kann ein Docker-Image so konfiguriert werden, dass es diese Dokumentation verwendet. Unter der Annahme, dass sich im aktuellen Verzeichnis ein OpenAPI-Dokument openapi.yml befindet, können Sie mit dem folgenden Befehl das Docker-Image starten, um das Dokument anzuzeigen.
docker run -p 8010:8080 -e SWAGGER_JSON=/api/openapi.yml -v $PWD:/api swaggerapi/swagger-ui
Die folgende Abbildung ist ein Screenshot der Swagger-Oberfläche.

Codegenerierung
Über das OpenAPI-Dokument können Sie das von Swagger bereitgestellte Codegenerierungstool verwenden, um Server-Stub-Code und Client automatisch zu generieren. Für die Codegenerierung können unterschiedliche Programmiersprachen und Frameworks verwendet werden.
Die von den Codegenerierungstools unterstützten Programmiersprachen und Frameworks sind unten aufgeführt.
aspnetcore, csharp, csharp-dotnet2, go-server, dynamisches HTML, html, html2, java, jaxrs-cxf-client, jaxrs- cxf, Inflector, jaxrs-cxf-cdi, jaxrs-spec, jaxrs-jersey, jaxrs- di, jaxrs-resteasy-eap, jaxrs-resteasy, micronaut, spring, nodejs-server, openapi, openapi-yaml, kotlin-client, kotlin-server, php, python, python-flask, r, scala, scal a- akka -http-Server, Swift3, Swift4, Swift5, Typescript-Winkel, Javascript
Das Codegenerierungstool ist ein Java-Programm, das nach dem Download direkt ausgeführt werden kann. Nach dem Herunterladen der JAR-Datei swagger-codegen-cli-3.0.19.jar können Sie den folgenden Befehl verwenden, um den Java-Client-Code zu generieren, wobei der Parameter -i das Eingabe-OpenAPI-Dokument angibt, -l die generierte Sprache angibt und - o gibt das ausgegebene Inhaltsverzeichnis an.
java -jar swagger-codegen-cli-3.0.19.jar generate -i openapi.yml -l java -o /tmp
Zusätzlich zum Generieren von Client-Code kann auch Server-Stub-Code generiert werden. Der folgende Code dient zum Generieren von NodeJS-Server-Stub-Code:
java -jar swagger-codegen-cli-3.0.19.jar generate -i openapi.yml -l nodejs-server -o /tmp
Zusammenfassen
Die API-First-Strategie stellt sicher, dass die Microservice-API unter vollständiger Berücksichtigung der Bedürfnisse der API-Benutzer entwickelt wird, wodurch die API zu einem guten Vertrag zwischen dem Anbieter und dem Benutzer wird. Diese Klasse führt zuerst in die Entwurfsstrategie der API ein, dann in die verschiedenen Implementierungsmethoden der API, dann in die OpenAPI-Spezifikation der REST-API und schließlich in die zugehörigen Tools der OpenAPI.