Artikelverzeichnis

Gedanken, die durch die Interviewfrage „Ist Redis Single-Threaded?“ ausgelöst wurden.
Autor: Li Le
Quelle: IT Reading Ranking
Viele Menschen sind auf eine solche Interviewfrage gestoßen: Ist Redis Single-Thread oder Multi-Thread? Diese Frage ist sowohl einfach als auch komplex. Es wird als einfach bezeichnet, weil die meisten Leute wissen, dass Redis Single-Threaded ist, und es wird als komplex bezeichnet, weil die Antwort tatsächlich ungenau ist.
Ist Redis nicht Single-Threaded? Wir starten eine Redis-Instanz und überprüfen sie. Die Installations- und Bereitstellungsmethode von Redis lautet wie folgt:
// 下载
wget https://download.redis.io/redis-stable.tar.gz
tar -xzvf redis-stable.tar.gz
// 编译安装
cd redis-stable
make
// 验证是否安装成功
./src/redis-server -v
Redis server v=7.2.4
Starten Sie als Nächstes die Redis-Instanz und verwenden Sie den Befehl ps, um alle Threads anzuzeigen, wie unten gezeigt:
// 启动Redis实例
./src/redis-server ./redis.conf
// 查看实例进程ID
ps aux | grep redis
root 385806 0.0 0.0 245472 11200 pts/2 Sl+ 17:32 0:00 ./src/redis-server 127.0.0.1:6379
// 查看所有线程
ps -L -p 385806
PID LWP TTY TIME CMD
385806 385806 pts/2 00:00:00 redis-server
385806 385809 pts/2 00:00:00 bio_close_file
385806 385810 pts/2 00:00:00 bio_aof
385806 385811 pts/2 00:00:00 bio_lazy_free
385806 385812 pts/2 00:00:00 jemalloc_bg_thd
385806 385813 pts/2 00:00:00 jemalloc_bg_thd
Es gibt tatsächlich 6 Threads! Heißt es nicht, dass Redis Single-Threaded ist? Warum gibt es so viele Threads?
Möglicherweise verstehen Sie die Bedeutung dieser sechs Threads nicht, aber dieses Beispiel zeigt zumindest, dass Redis kein Single-Thread ist.
01 Multithreading in Redis
Als nächstes stellen wir nacheinander die Funktionen der oben genannten 6 Threads vor:
1)redis-server:
Der Hauptthread wird zum Empfangen und Verarbeiten von Clientanfragen verwendet.
2)jemalloc_bg_thd
jemalloc ist ein Speicherzuweiser der neuen Generation, der von der untersten Ebene von Redis zur Speicherverwaltung verwendet wird.
3)bio_xxx:
Bei denen, die mit dem Präfix „bio“ beginnen, handelt es sich ausschließlich um asynchrone Threads, mit denen einige zeitaufwändige Aufgaben asynchron ausgeführt werden. Unter diesen wird der Thread bio_close_file zum asynchronen Löschen von Dateien, der Thread bio_aof zum asynchronen Löschen von AOF-Dateien auf die Festplatte und der Thread bio_lazy_free zum asynchronen Löschen von Daten (verzögertes Löschen) verwendet.
Es ist zu beachten, dass der Hauptthread Aufgaben über die Warteschlange an asynchrone Threads verteilt und dieser Vorgang eine Sperre erfordert. Die Beziehung zwischen dem Hauptthread und dem asynchronen Thread ist wie in der folgenden Abbildung dargestellt:
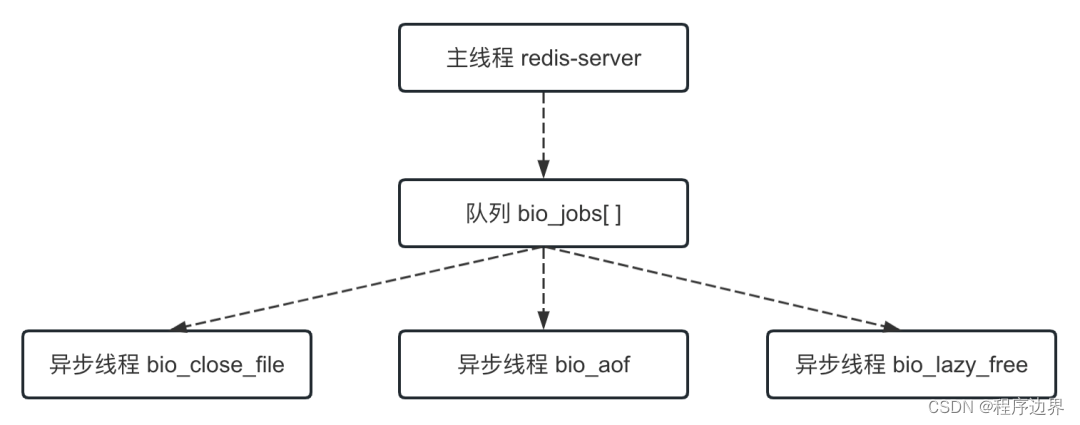
Hauptthread und asynchroner Thread Hauptthread und asynchroner ThreadHauptthread und asynchroner Thread
Hier nehmen wir das verzögerte Löschen als Beispiel, um zu erklären, warum ein asynchroner Thread verwendet werden sollte. Redis ist eine In-Memory-Datenbank, die mehrere Datentypen unterstützt, darunter Zeichenfolgen, Listen, Hash-Tabellen, Sätze usw. Denken Sie darüber nach: Wie werden Listentypdaten (DEL) gelöscht? Der erste Schritt besteht darin, das Schlüssel-Wert-Paar aus dem Datenbankwörterbuch zu löschen, und der zweite Schritt besteht darin, alle Elemente in der Liste zu durchlaufen und zu löschen (Speicher freizugeben). Überlegen Sie, was passiert, wenn die Anzahl der Elemente in der Liste sehr groß ist? Dieser Schritt wird sehr zeitaufwändig sein. Diese Löschmethode wird als synchrones Löschen bezeichnet. Der Vorgang ist in der folgenden Abbildung dargestellt:
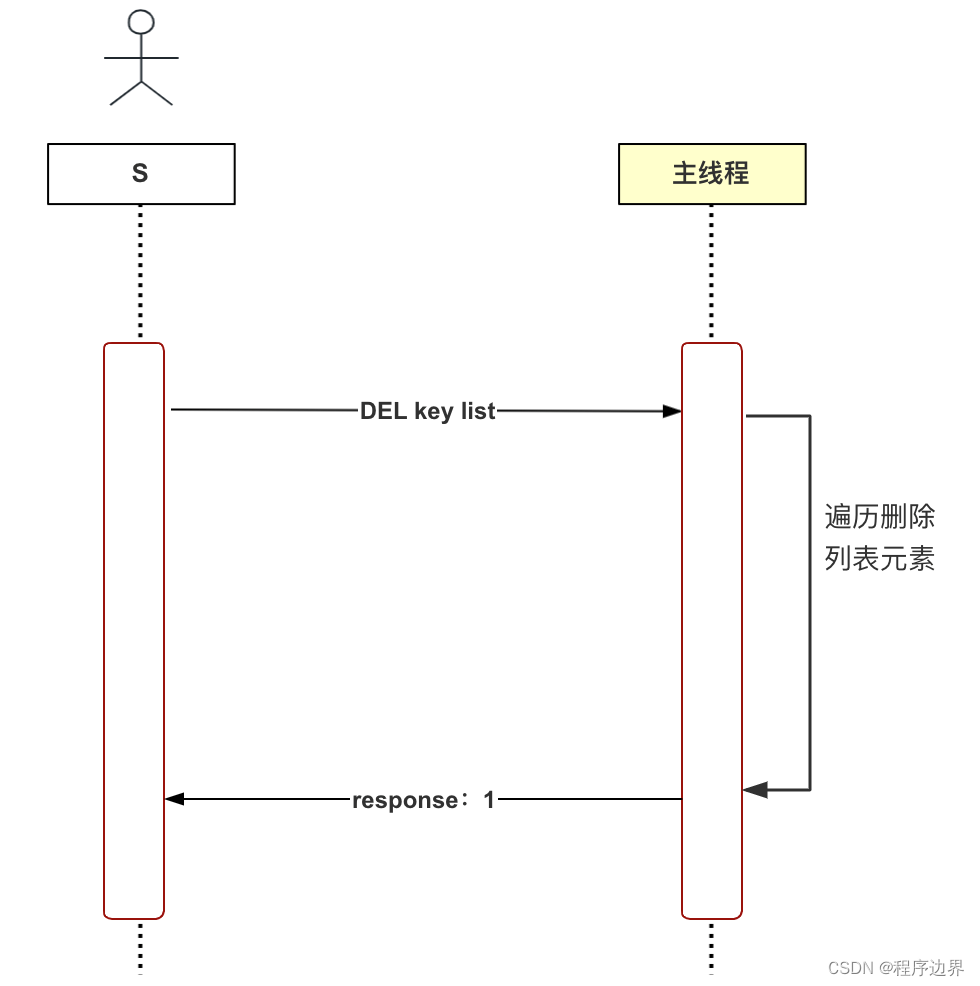
Ablaufdiagramm zum synchronen Löschen. Ablaufdiagramm zum synchronen LöschenAblaufdiagramm für synchrones Löschen
Als Reaktion auf die oben genannten Probleme schlug Redis das verzögerte Löschen (asynchrones Löschen) vor. Wenn der Hauptthread den Löschbefehl (UNLINK) empfängt, löscht er zunächst das Schlüssel-Wert-Paar aus dem Datenbankwörterbuch und verteilt die Löschung dann Aufgabe an den asynchronen Thread. bio_lazy_free, der zweite Schritt der zeitaufwändigen Logik wird vom asynchronen Thread ausgeführt. Der Prozess zu diesem Zeitpunkt ist unten dargestellt:
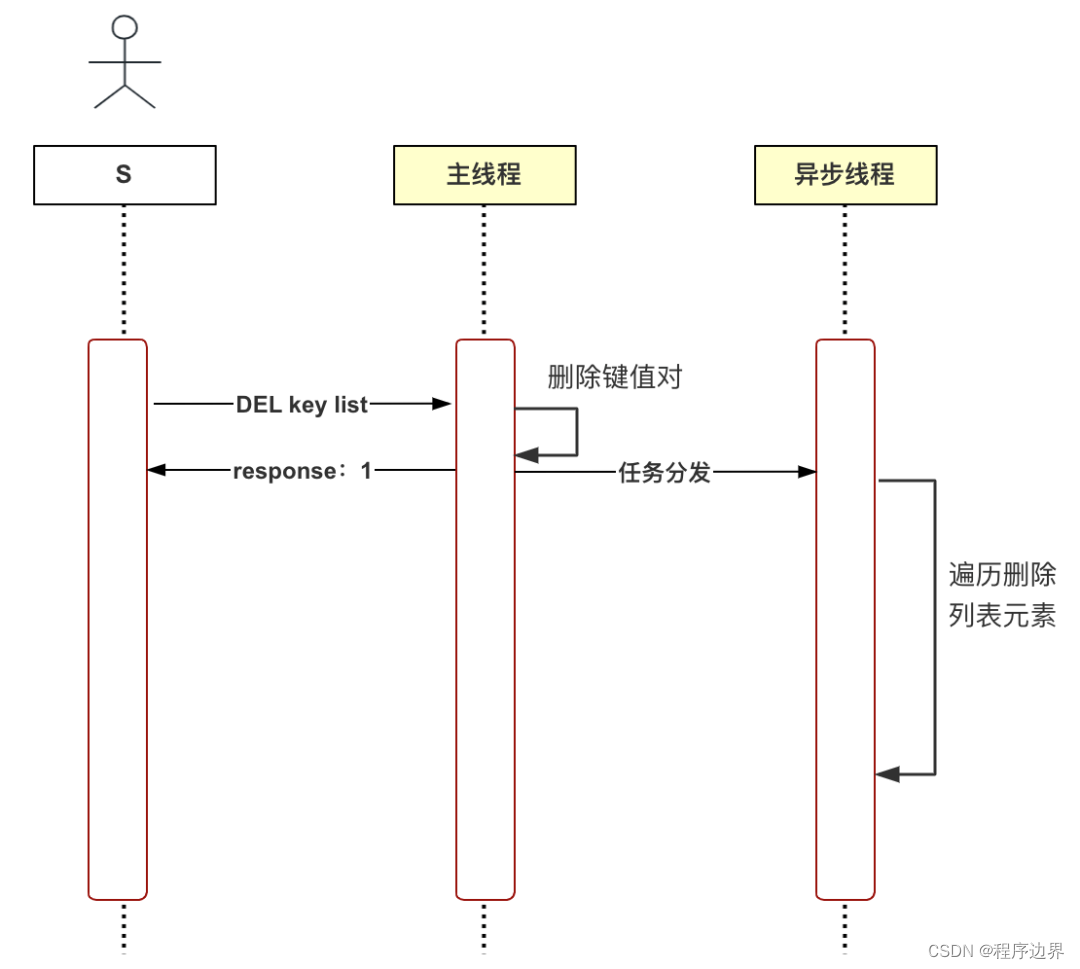
Flussdiagramm für verzögertes Löschen Flussdiagramm für verzögertes LöschenFlussdiagramm zum verzögerten Löschen
02 E/A-Multithreading
Ist Redis Multi-Threaded? Warum sagen wir also immer, dass Redis Single-Threaded ist? Dies liegt daran, dass das Lesen von Client-Befehlsanforderungen, das Ausführen von Befehlen und die Rückgabe von Ergebnissen an den Client im Hauptthread abgeschlossen werden. Wenn andernfalls mehrere Threads gleichzeitig die In-Memory-Datenbank betreiben, wie kann dann das Parallelitätsproblem gelöst werden? Was ist der Unterschied zu einem einzelnen Thread, wenn eine Sperre vor jedem Vorgang gesperrt wird?
Natürlich hat sich dieser Prozess auch in der Redis 6.0-Version geändert. Redis-Beamte wiesen darauf hin, dass Redis eine speicherbasierte Schlüsselwertdatenbank ist. Der Prozess der Befehlsausführung ist sehr schnell. Er liest die Client-Befehlsanforderung und gibt die Ergebnisse an zurück Der Client (dh Netzwerk-E/A) wird normalerweise zum Leistungsengpass von Redis.
Daher hat der Autor in der Redis 6.0-Version die Fähigkeit von Multithread-E/A hinzugefügt, d. h. mehrere E/A-Threads können geöffnet werden, Client-Befehlsanforderungen können parallel gelesen werden und Ergebnisse können an den Client zurückgegeben werden parallel zu. Die I/O-Multithreading-Fähigkeit verdoppelt die Leistung von Redis mindestens.
Um die Multithread-E/A-Fähigkeit zu aktivieren, müssen Sie zunächst die Konfigurationsdatei redis.conf ändern:
io-threads-do-reads yes
io-threads 4
Die Bedeutung dieser beiden Konfigurationen ist wie folgt:
-
io-threads-do-reads: Ob Multithread-E/A-Fähigkeit aktiviert werden soll, der Standardwert ist „Nein“;
-
io-threads: Die Anzahl der E/A-Threads. Der Standardwert ist 1, d Anzahl der CPU-Kerne. Der Autor empfiehlt die Einstellung 2–3 für eine 4-Kern-CPU mit I/O-Threads, eine 8-Kern-CPU legt 6 I/O-Threads fest.
Nachdem Sie die Multithread-E/A-Funktion aktiviert haben, starten Sie die Redis-Instanz neu und sehen Sie sich alle Threads an. Die Ergebnisse sind wie folgt:
ps -L -p 104648
PID LWP TTY TIME CMD
104648 104648 pts/1 00:00:00 redis-server
104648 104654 pts/1 00:00:00 io_thd_1
104648 104655 pts/1 00:00:00 io_thd_2
104648 104656 pts/1 00:00:00 io_thd_3
……
Da wir io-threads auf 4 setzen, werden 4 Threads erstellt, um E/A-Vorgänge auszuführen (einschließlich des Hauptthreads). Die obigen Ergebnisse entsprechen den Erwartungen.
Natürlich wird nur in der E/A-Phase Multithreading verwendet, und die Verarbeitung von Befehlsanforderungen erfolgt immer noch in einem Single-Thread. Schließlich gibt es bei Multithread-Vorgängen von Speicherdaten Probleme mit der Parallelität.
Nachdem E/A-Multithreading aktiviert wurde, sieht der Ablauf der Befehlsausführung schließlich wie folgt aus:
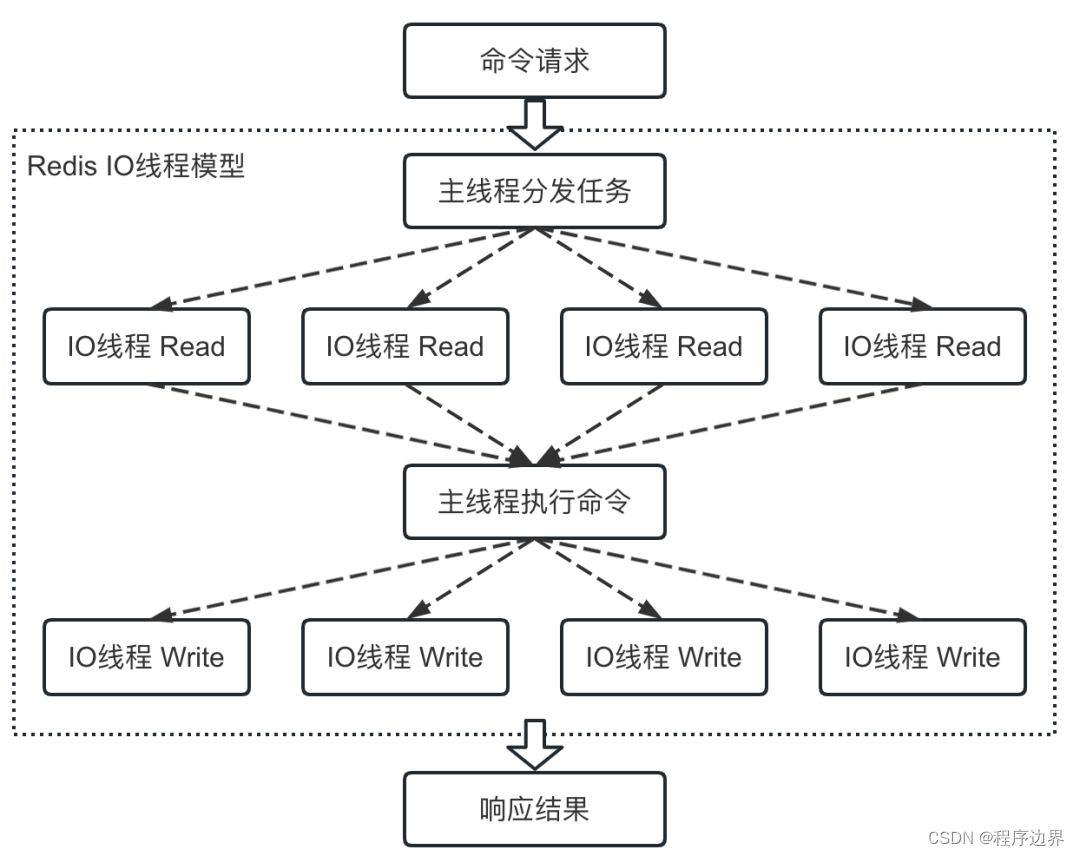
I/O-Multithread-Flussdiagramm I/O-Multithread-FlussdiagrammI / O -Multithreading-Flussdiagramm
03 Multiprozess in Redis
Verfügt Redis über mehrere Prozesse? Ja. In einigen Szenarien erstellt Redis auch mehrere Unterprozesse, um einige Aufgaben auszuführen. Am Beispiel der Persistenz unterstützt Redis zwei Arten der Persistenz:
-
AOF (Append Only File): Es kann als Protokolldatei mit Befehlen betrachtet werden. Redis hängt jeden Schreibbefehl an die AOF-Datei an.
-
RDB (Redis-Datenbank): speichert Daten in Form von Snapshots im Redis-Speicher. Mit dem Befehl SAVE wird die RDB-Persistenz manuell ausgelöst. Denken Sie darüber nach, wenn die Datenmenge in Redis sehr groß ist, der Persistenzvorgang lange dauern muss und Redis Befehlsanforderungen in einem einzelnen Thread verarbeitet. Wenn die Ausführungszeit des SAVE-Befehls also zu lang ist, hat dies unweigerlich Auswirkungen die Ausführung anderer Befehle.
Der SAVE-Befehl blockiert möglicherweise andere Anforderungen. Aus diesem Grund hat Redis den Befehl BGSAVE eingeführt, der einen Unterprozess zum Durchführen von Persistenzoperationen erstellt, sodass der Hauptprozess nicht durch die Ausführung anderer Anforderungen beeinträchtigt wird.
Zur Überprüfung können wir den Befehl BGSAVE manuell ausführen. Verwenden Sie zunächst GDB, um den Redis-Prozess zu verfolgen, Haltepunkte hinzuzufügen und den untergeordneten Prozess in der Persistenzlogik blockieren zu lassen. Wie folgt:
// 查询Redis进程ID
ps aux | grep redis
root 448144 0.1 0.0 270060 11520 pts/1 tl+ 17:00 0:00 ./src/redis-server 127.0.0.1:6379
// GDB跟踪进程
gdb -p 448144
// 跟踪创建的子进程(默认GDB只跟踪主进程,需手动设置)
(gdb) set follow-fork-mode child
// 函数rdbSaveDb用于持久化数据快照
(gdb) b rdbSaveDb
Breakpoint 1 at 0x541a10: file rdb.c, line 1300.
(gdb) c
Nachdem Sie den Haltepunkt festgelegt haben, verwenden Sie den Redis-Client, um den Befehl BGSAVE zu senden. Die Ergebnisse sind wie folgt:
// 请求立即返回
127.0.0.1:6379> bgsave
Background saving started
// GDB输出以下信息
[New process 452541]
Breakpoint 1, rdbSaveDb (...) at rdb.c:1300
Wie Sie sehen, verfolgt GDB derzeit den untergeordneten Prozess und die Prozess-ID lautet 452541. Sie können alle Prozesse auch über den Linux-Befehl ps anzeigen. Die Ergebnisse sind wie folgt:
ps aux | grep redis
root 448144 0.0 0.0 270060 11520 pts/1 Sl+ 17:00 0:00 ./src/redis-server 127.0.0.1:6379
root 452541 0.0 0.0 270064 11412 pts/1 t+ 17:19 0:00 redis-rdb-bgsave 127.0.0.1:6379
Sie können sehen, dass der Name des untergeordneten Prozesses redis-rdb-bgsave ist, was bedeutet, dass dieser Prozess Snapshots aller Daten in RDB-Dateien beibehält.
Betrachten Sie abschließend zwei Fragen.
- Frage 1: Warum einen Unterprozess anstelle eines Unterthreads verwenden?
Da RDB Daten-Snapshots dauerhaft speichert, teilen sich der Haupt-Thread und die Unter-Threads bei Verwendung von Sub-Threads Speicherdaten. Der Haupt-Thread ändert auch die Speicherdaten, während er persistiert, was zu Dateninkonsistenzen führen kann. Die Speicherdaten des Hauptprozesses und des untergeordneten Prozesses sind vollständig isoliert, und dieses Problem besteht nicht.
- Frage 2: Angenommen, 10 GB Daten sind im Redis-Speicher gespeichert. Benötigt der untergeordnete Prozess nach dem Erstellen eines untergeordneten Prozesses zur Durchführung von Persistenzvorgängen zu diesem Zeitpunkt auch 10 GB Speicher? Das Kopieren von 10 GB Speicherdaten wird zeitaufwändig sein, oder? Kann der Befehl BGSAVE trotzdem ausgeführt werden, wenn das System nur über 15 GB Arbeitsspeicher verfügt?
Hier gibt es ein Konzept namens „Kopieren beim Schreiben“. Nach der Verwendung des Fork-Systemaufrufs zum Erstellen eines untergeordneten Prozesses werden die Speicherdaten des Hauptprozesses und des untergeordneten Prozesses vorübergehend gemeinsam genutzt Das System erstellt automatisch eine Kopie dieses Speicherblocks, um eine Isolierung der Speicherdaten zu erreichen.
Der Ausführungsablauf des Befehls BGSAVE ist in der folgenden Abbildung dargestellt:
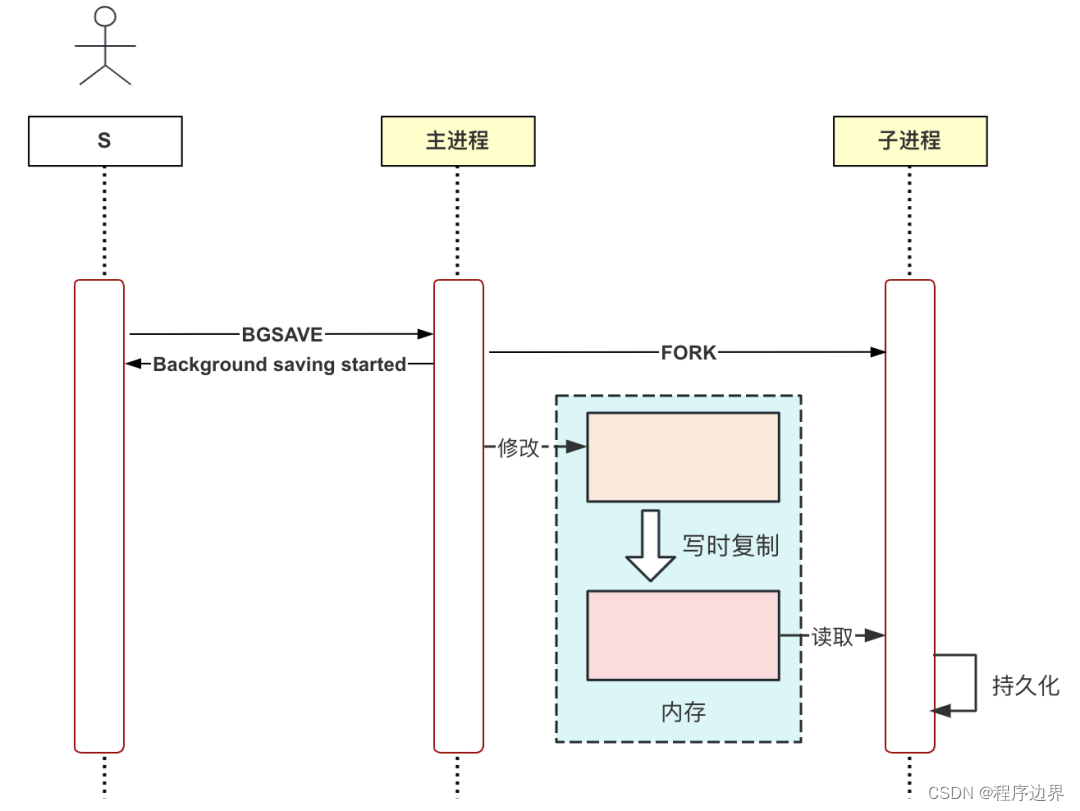
BGSAVE-Ausführungsprozess BGSAVE-AusführungsprozessBGS A V E- Ausführungsprozess
04 Fazit
Das Prozessmodell/Threading-Modell von Redis ist noch relativ komplex. Hier stellen wir Multi-Threading und Multi-Processing in einigen Szenarien nur kurz vor. Multi-Threading und Multi-Processing in anderen Szenarien müssen noch von den Lesern selbst untersucht werden.
Über den Autor
Li Le: Golang-Entwicklungsexperte bei TAL und Master-Abschluss von der Xi'an University of Electronic Science and Technology. Er arbeitete einst für Didi. Er ist bereit, sich mit Technologie und Quellcode zu befassen. Er ist Mitautor von „Redis effizient nutzen: Datenspeicherung und Hochverfügbarkeitscluster in einem Buch lernen“ und „Redis5“-Design und Quellcode-Analyse“ „Nginx-zugrundeliegendes Design und Quellcode-Analyse“.
▼Erweiterte Lektüre

„Redis effizient nutzen: Datenspeicherung und Hochverfügbarkeits-Cluster in einem Buch lernen“ „Redis effizient nutzen: Datenspeicherung und Hochverfügbarkeits-Cluster in einem Buch lernen“„ Redis effizient nutzen : Lernen Sie Datenspeicherung und Hochverfügbarkeitscluster in einem Buch “
Empfohlene Wörter: Gehen Sie tief in die Redis-Datenstruktur und die zugrunde liegende Implementierung ein und überwinden Sie die Probleme der Redis-Datenspeicherung und Clusterverwaltung.