

Das visuelle Generationsparadigma der neuen Generation „VAR: Visual Auto Regressive“ ist da! Das autoregressive Modell im GPT-Stil übertrifft zum ersten Mal das Diffusionsmodell bei der Bilderzeugung , und es werden die Skalierungsgesetze und die Generalisierungsfähigkeit der Zero-Shot-Aufgabengeneralisierung beobachtet, die denen des großen Sprachmodells ähneln :
论文标题:Visuelle autoregressive Modellierung: Skalierbare Bilderzeugung mittels Next-Scale-Vorhersage
Diese neue Arbeit namens VAR wurde von Forschern der Peking-Universität und ByteDance vorgeschlagen . Sie stand auf den Hotlists von GitHub und Paperwithcode und erhielt viel Aufmerksamkeit von Kollegen:
Derzeit wurden die Erlebniswebsite, Papiere, Codes und Modelle veröffentlicht:
- Erlebnis-Website: https://var.vision/
- Link zum Papier: https://arxiv.org/abs/2404.02905
- Open-Source-Code: https://github.com/FoundationVision/VAR
- Open-Source-Modell: https://huggingface.co/FoundationVision/var
Hintergrundeinführung
Bei der Verarbeitung natürlicher Sprache hat das autoregressive autoregressive Modell am Beispiel großer Sprachmodelle wie GPT- und LLaMa-Reihen große Erfolge erzielt. Insbesondere das Skalierungsgesetz und die Zero-Shot- Task-Generalisierbarkeit haben eine sehr beeindruckende Zero-Shot-Task-Generalisierung erzielt Fähigkeiten, die zunächst das Potenzial zeigen, zu einer „allgemeinen künstlichen Intelligenz AGI“ zu führen.
Im Bereich der Bilderzeugung hinken autoregressive Modelle jedoch im Allgemeinen den Diffusionsmodellen hinterher: DALL-E3, Stable Diffusion3, SORA und andere in letzter Zeit beliebte Modelle gehören alle zur Diffusionsfamilie. Darüber hinaus ist noch nicht bekannt, ob es im Bereich der visuellen Generierung ein „Skalierungsgesetz“ gibt , das heißt, ob der Kreuzentropieverlust des Testsatzes einen vorhersehbaren Potenzgesetz-Abwärtstrend mit Modell- oder Trainingsaufwand zeigen kann zu erforschen.
Die leistungsstarken Fähigkeiten und das Skalierungsgesetz des formalen autoregressiven GPT-Modells scheinen im Bereich der Bilderzeugung „gesperrt“ zu sein:

Das autoregressive Modell bleibt in der Liste der Generierungseffekte hinter vielen Diffusionsmodellen zurück
Das Forschungsteam konzentrierte sich darauf, die Fähigkeit autoregressiver Modelle und Skalierungsgesetze „freizuschalten“, ging von der inhärenten Natur von Bildmodalitäten aus, ahmte die logische Abfolge der menschlichen Bildverarbeitung nach und schlug ein neues Paradigma für die „visuelle autoregressive“ Generierung vor: VAR, Visual AutoRegressive Durch die Modellierung übertrifft die autoregressive visuelle Generierung im GPT-Stil erstmals die Diffusion in Bezug auf Wirkung, Geschwindigkeit und Skalierungsfähigkeiten und führt Skalierungsgesetze im Bereich der visuellen Generierung ein:

Der Kern der VAR-Methode: Nachahmung des menschlichen Sehvermögens und Neudefinition der autoregressiven Bildsequenz
Wenn Menschen Bilder wahrnehmen oder malen, neigen sie dazu, sich zunächst einen Überblick zu verschaffen und sich dann in die Details zu vertiefen. Diese Art des Denkens vom Groben zum Feinen, vom Erfassen des Ganzen bis zur Feinjustierung des Teils ist ganz natürlich:
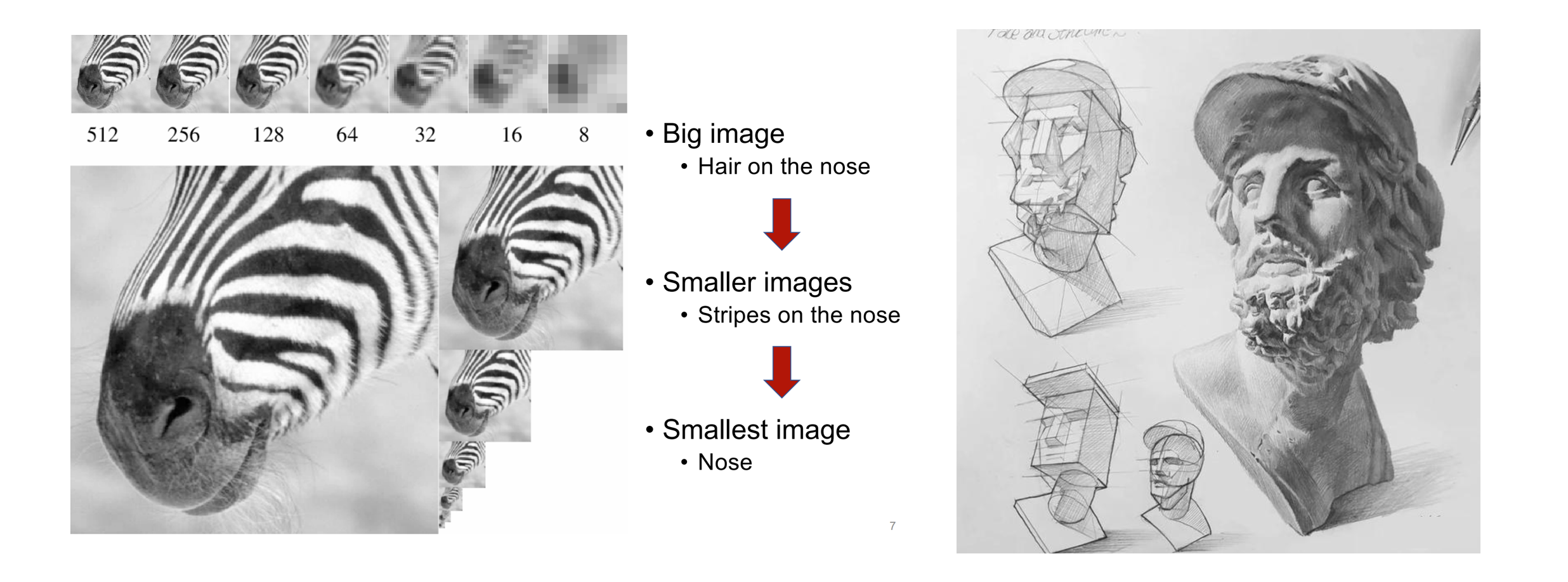
Die logische Abfolge vom Groben zum Feinen der menschlichen Wahrnehmung von Bildern (links) und der Entstehung von Gemälden (rechts)
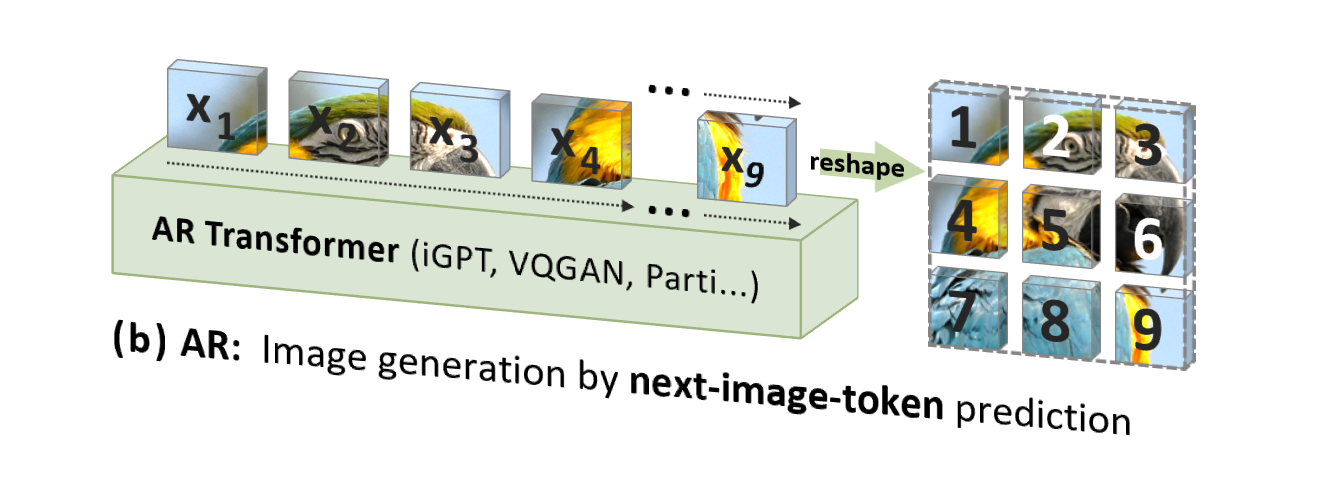
Die herkömmliche Bild-Autoregression (AR) verwendet jedoch eine Reihenfolge, die nicht der menschlichen Intuition entspricht (aber für die Computerverarbeitung geeignet ist), d. h. eine zeilenweise Rasterreihenfolge von oben nach unten, um Bildtoken einzeln vorherzusagen :
VAR ist „personenorientiert“, imitiert die logische Abfolge menschlicher Wahrnehmung oder von Menschen erstellter Bilder und generiert schrittweise eine Token-Karte unter Verwendung einer mehrskaligen Abfolge vom Ganzen bis zu den Details:
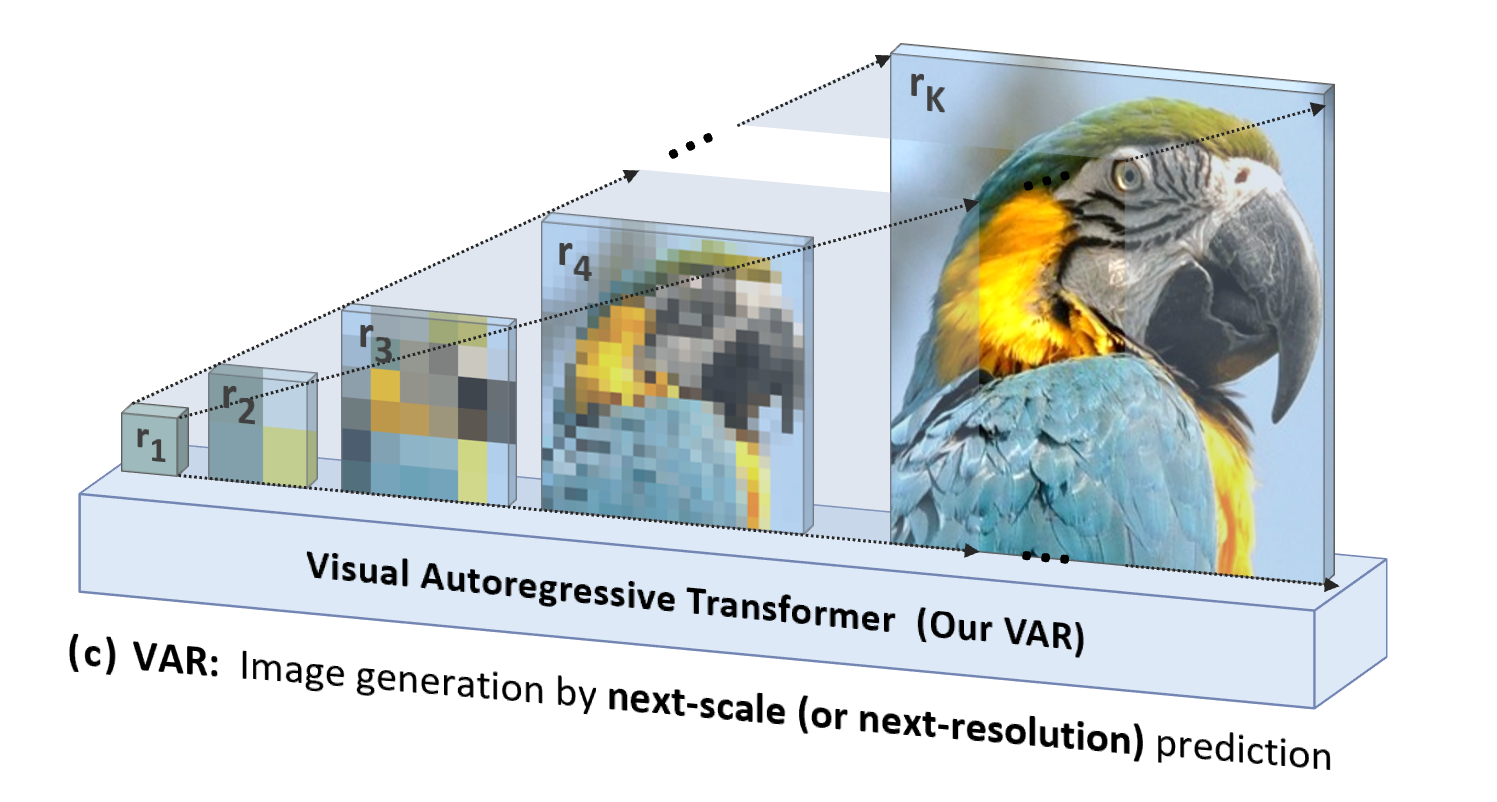
Ein weiterer wesentlicher Vorteil von VAR besteht nicht nur darin, dass es natürlicher ist und der menschlichen Intuition entspricht, sondern auch darin, dass es die Generierungsgeschwindigkeit erheblich erhöht: Bei jedem Schritt der Autoregression (innerhalb jeder Skala) werden alle Bild-Tokens gleichzeitig parallel generiert Skalen Es ist autoregressiv. Dies macht VAR um ein Vielfaches schneller als herkömmliches AR, wenn die Modellparameter und Bildgrößen gleich sind. Darüber hinaus stellte der Autor im Experiment auch fest, dass VAR eine stärkere Leistung und Skalierbarkeit aufweist als AR.
Details zur VAR-Methode: zweistufiges Training
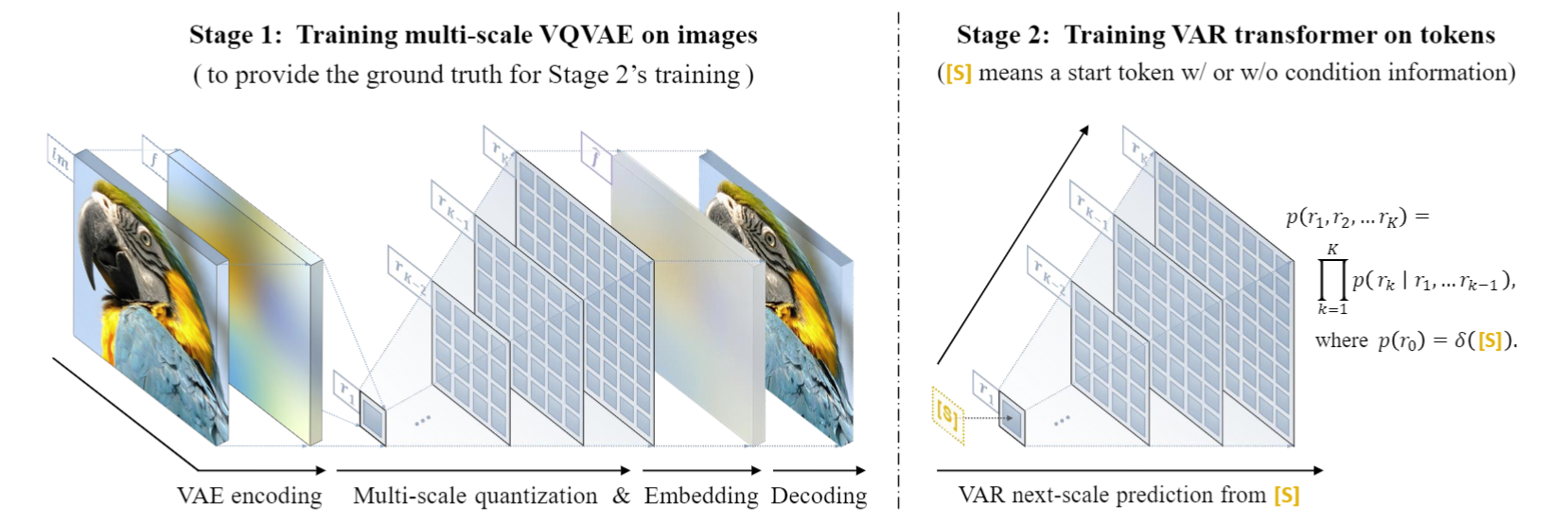
VAR trainiert in der ersten Stufe einen Multiskalen-Quantisierungs-Autoencoder (Multi-Scale VQVAE) und in der zweiten Stufe einen autoregressiven Transformator, der mit der GPT-2-Struktur (kombiniert mit AdaLN) konsistent ist .
Wie im Bild links gezeigt, lauten die Trainings-Prequel-Details von VQVAE wie folgt:
- Diskrete Codierung : Der Encoder wandelt das Bild in eine diskrete Token-Map R=(r1, r2, ..., rk) mit Auflösungen von klein bis groß um
- Kontinuität : r1 bis rk werden zunächst durch die Einbettungsschicht in kontinuierliche Merkmalskarten umgewandelt, dann gleichmäßig auf die maximale Auflösung entsprechend rk interpoliert und summiert
- Kontinuierliche Dekodierung : Die summierte Feature-Map wird durch den Decoder geleitet, um das rekonstruierte Bild zu erhalten, und wird durch eine Mischung aus drei Verlusten trainiert: Rekonstruktion + Wahrnehmung + Konfrontation.
Wie in der Abbildung rechts dargestellt, wird nach Abschluss des VQVAE-Trainings die zweite Stufe des autoregressiven Transformer-Trainings durchgeführt:
- Der erste Schritt der Autoregression besteht darin, die anfängliche 1x1- Token-Karte aus dem Start -****- Token [S] vorherzusagen .
- Bei jedem weiteren Schritt prognostiziert VAR die Token-Karte im nächstgrößeren Maßstab auf der Grundlage aller historischen Token-Karten.
- Während der Trainingsphase verwendet VAR den standardmäßigen Kreuzentropieverlust, um die Wahrscheinlichkeitsvorhersage dieser Token-Karten zu überwachen.
- In der Testphase wird die abgetastete Token-Karte mit Hilfe des VQVAE-Decoders serialisiert, interpoliert, summiert und dekodiert, um das endgültige generierte Bild zu erhalten.
Der Autor sagte, dass das autoregressive Framework von VAR brandneu sei und die spezifische Technologie die Stärken einer Reihe klassischer Technologien wie Rest-VAE von RQ-VAE, AdaLN von StyleGAN und DiT sowie progressives Training von PGGAN übernommen habe. VAR steht tatsächlich auf den Schultern von Giganten und konzentriert sich auf die Innovation des autoregressiven Algorithmus selbst.
Experimenteller Wirkungsvergleich
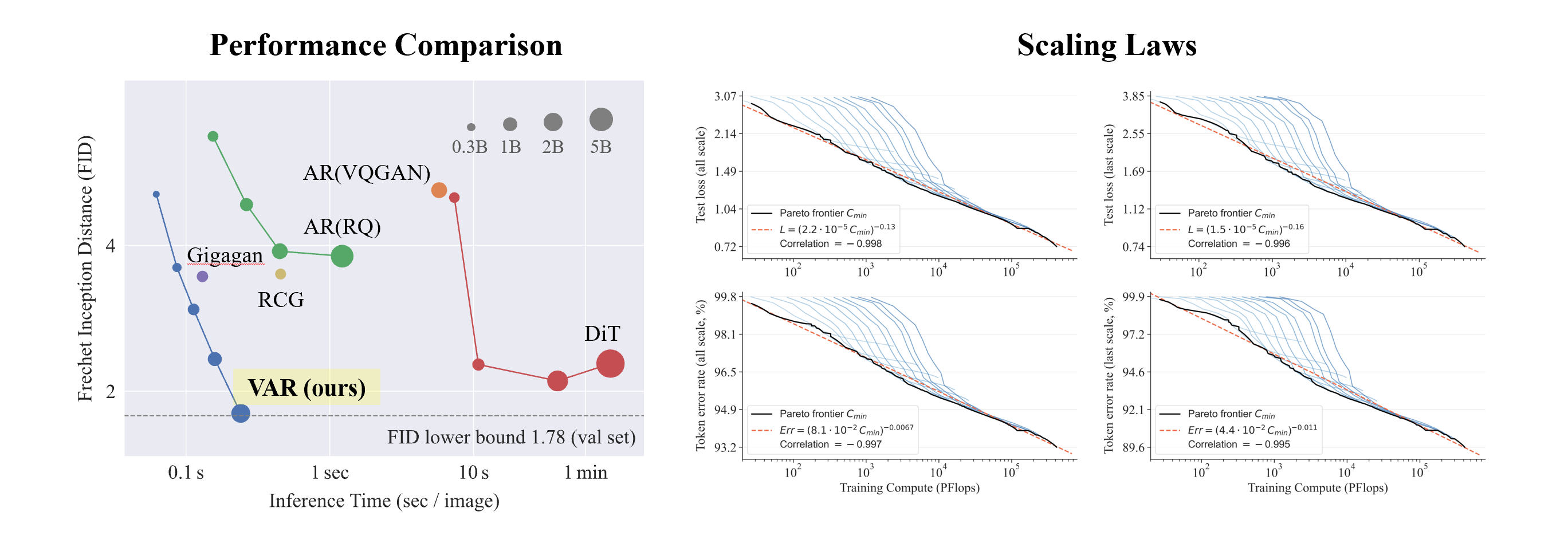
VAR-Experimente mit Conditional ImageNet 256x256 und 512x512:
- VAR hat die Wirkung von AR erheblich verbessert und dafür gesorgt, dass AR nicht mehr hinter der Diffusion zurückbleibt .
- VAR erfordert nur 10 autoregressive Schritte und seine Generierungsgeschwindigkeit übertrifft AR und Diffusion bei weitem und nähert sich sogar der Effizienz von GAN.
- Durch die Skalierung von VAR auf 2B/3B hat VAR das SOTA-Niveau erreicht und zeigt eine neue und potenzielle Familie generativer Modelle.

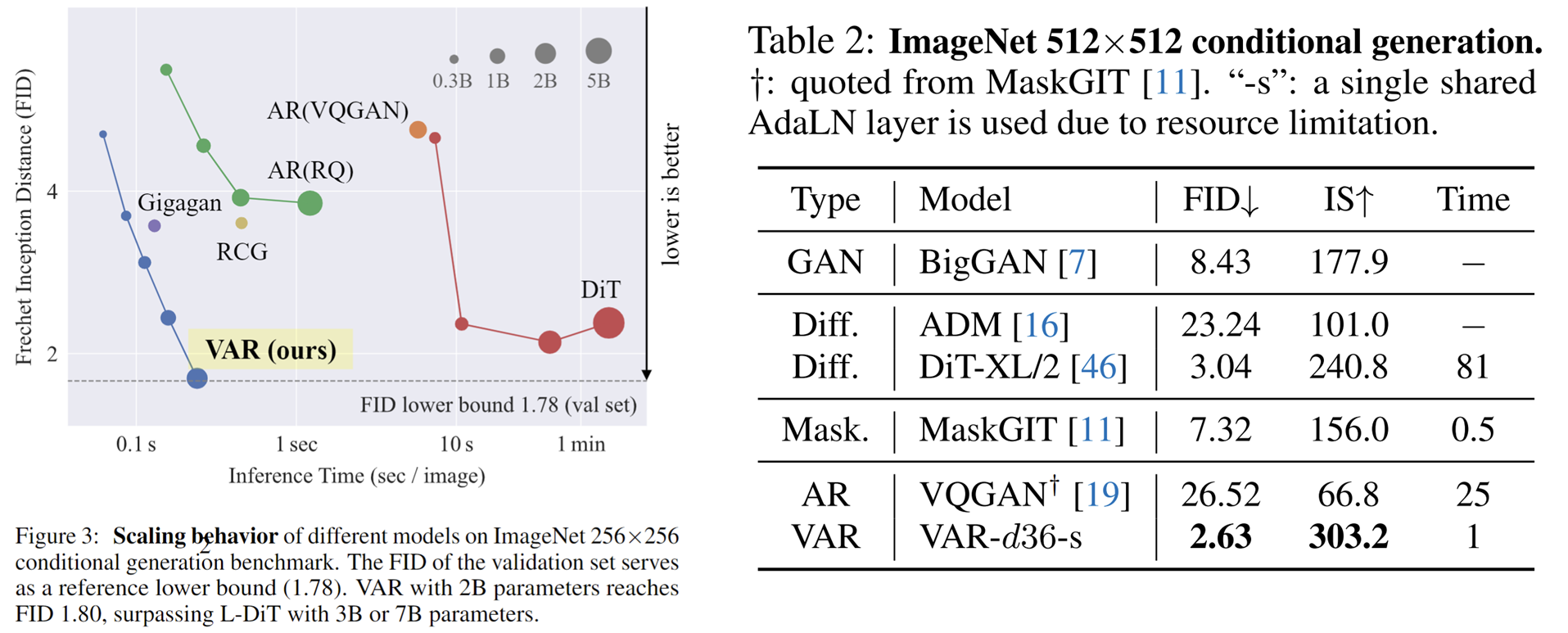
Interessant ist, dass VAR im Vergleich zu SORA und Diffusion Transformer (DiT), dem Grundmodell von Stable Diffusion 3 , Folgendes zeigt:
- Bessere Ergebnisse : Nach der Skalierung erreichte VAR schließlich FID=1,80 und näherte sich damit der theoretischen FID-Untergrenze von 1,78 (ImageNet-Validierungssatz), deutlich besser als DiTs optimaler Wert von 2,10
- Höhere Geschwindigkeit : VAR kann ein 256-Bild in weniger als 0,3 Sekunden erzeugen, was 45-mal schneller ist als DiT auf 512, es ist 81-mal schneller als DiT
- Bessere Skalierungsfähigkeiten : Wie in der linken Abbildung gezeigt, zeigte das große DiT-Modell nach dem Wachstum auf 3B und 7B eine Sättigung und konnte sich der FID-Untergrenze nicht nähern, während VAR auf 2 Milliarden Parameter skalierte, und seine Leistung verbesserte sich weiter endlich die FID-Untergrenze erreicht
- Effizientere Datennutzung : VAR erfordert nur 350- Epochen-Training, was mehr als DiT 1400- Epochen-Training ist.
Diese Beweise dafür, dass es effizienter, schneller und skalierbarer als DiT ist, bringen mehr Möglichkeiten für die nächste Generation von Infrastrukturpfaden der visuellen Generation.
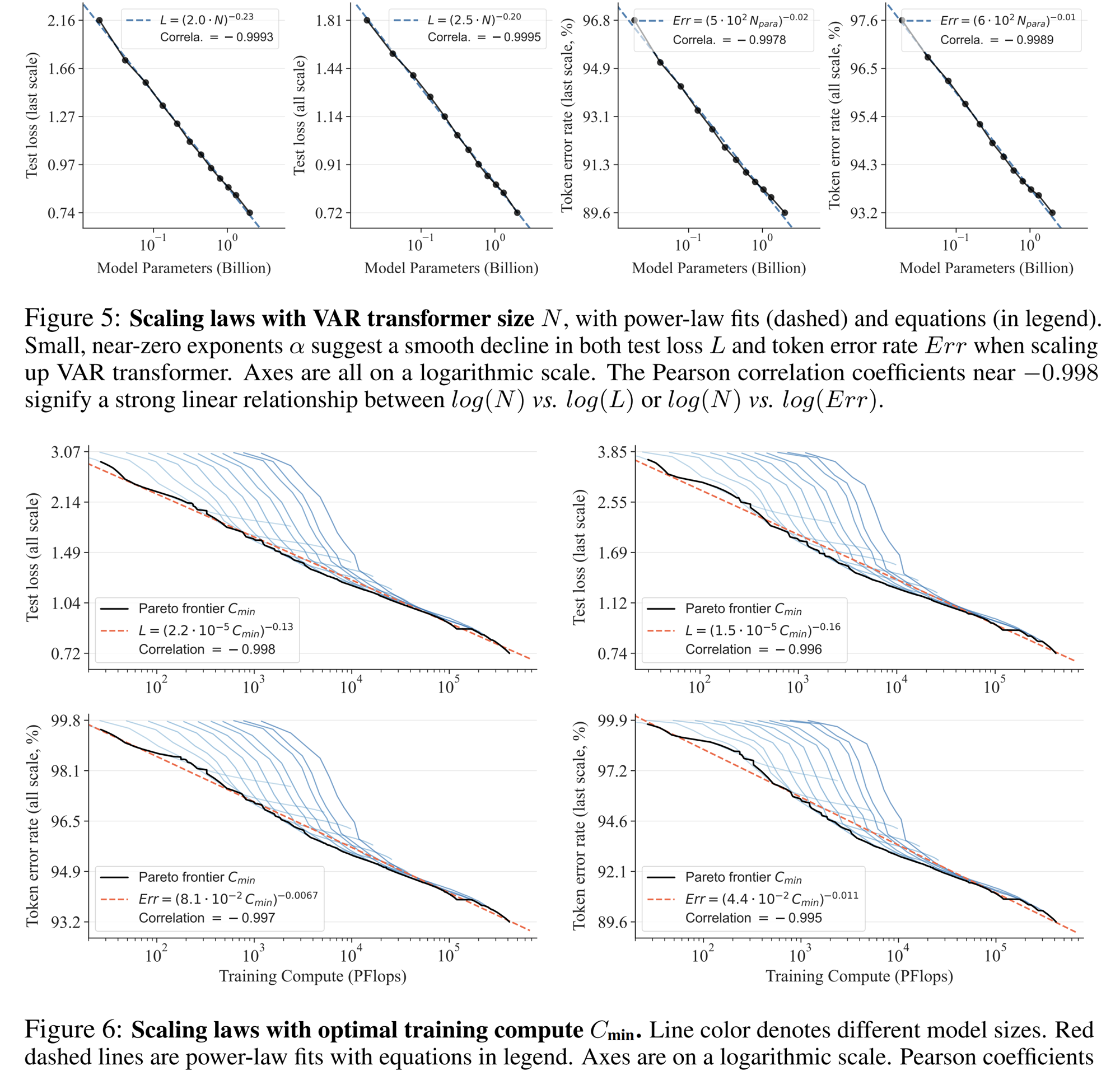
Experiment zum Skalierungsgesetz
Das Skalierungsgesetz kann als „Kronjuwel“ großer Sprachmodelle bezeichnet werden. Einschlägige Untersuchungen haben ergeben, dass bei der Skalierung autoregressiver Sprachmodelle in großem Maßstab der Kreuzentropieverlust L im Testsatz vorhersehbar mit der Anzahl der Modellparameter N, der Anzahl der Trainingstokens T und dem Rechenaufwand abnimmt Cmin . Legen Sie die Potenzgesetzbeziehung offen.
Das Skalierungsgesetz ermöglicht nicht nur die Vorhersage der Leistung großer Modelle auf der Grundlage kleiner Modelle, wodurch Rechenaufwand und Ressourcenzuweisung gespart werden, sondern spiegelt auch die leistungsstarke Lernfähigkeit des autoregressiven AR-Modells wider. Die Leistung des Testsatzes steigt mit N, T und Cmin.
Durch Experimente stellten Forscher fest, dass VAR ein Potenzgesetz-Skalierungsgesetz aufweist, das fast identisch mit LLM ist : Die Forscher trainierten 12 Modellgrößen, wobei die Anzahl der Skalierungsmodellparameter zwischen 18 Millionen und 2 Milliarden lag und der Gesamtberechnungsumfang 6 umfasste Größenordnungen erreicht die maximale Gesamtzahl der Token 305 Milliarden, und es wird beobachtet, dass der Testsatzverlust L oder die Testsatzfehlerrate und N zwischen L und Cmin eine glatte Potenzgesetzbeziehung aufweisen und die Anpassung gut ist :
Im Prozess der Skalierung der Modellparameter und des Berechnungsvolumens kann festgestellt werden, dass die Generierungsfähigkeit des Modells schrittweise verbessert wird (z. B. die folgenden Oszilloskopstreifen):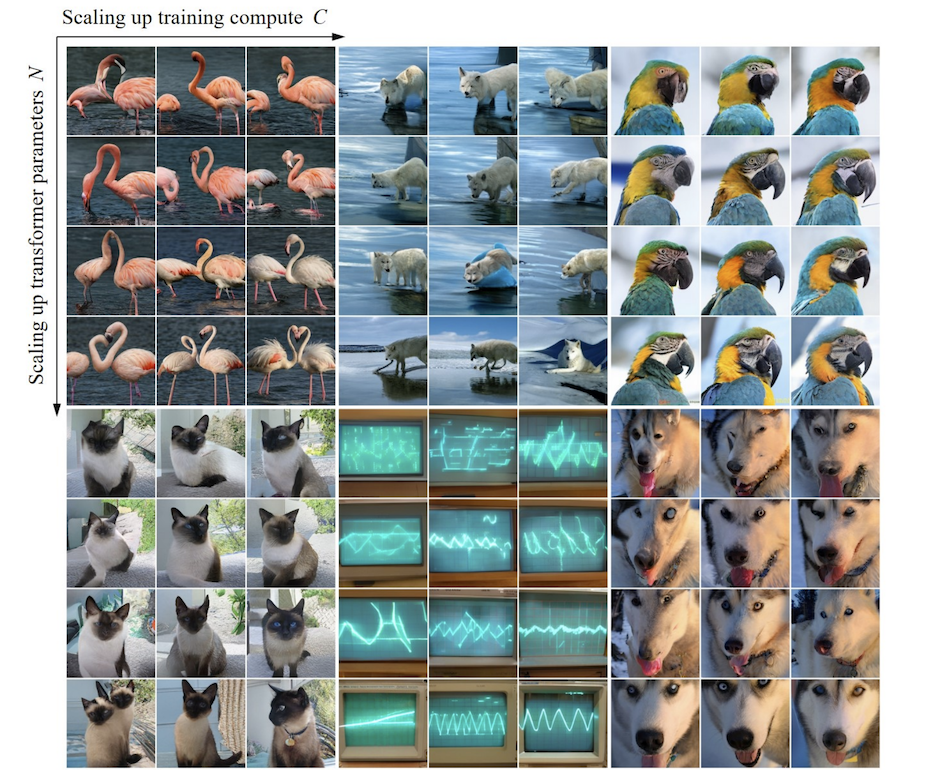
Zero-Shot-Experiment
Dank der hervorragenden Eigenschaft des autoregressiven Modells, den Teacher-Forcing-Mechanismus zu nutzen, um zu erzwingen, dass bestimmte Token unverändert bleiben, weist VAR auch bestimmte Funktionen zur Generalisierung von Aufgaben ohne Stichprobe auf. Der auf die bedingte Generierungsaufgabe trainierte VAR-Transformator kann ohne Feinabstimmung auf einige generative Aufgaben verallgemeinern, z. B. Bildvervollständigung (Inpainting), Bildextrapolation (Outpainting) und Bildbearbeitung (Klassenbedingungsbearbeitung). ) und bestimmte Ergebnisse erzielt:
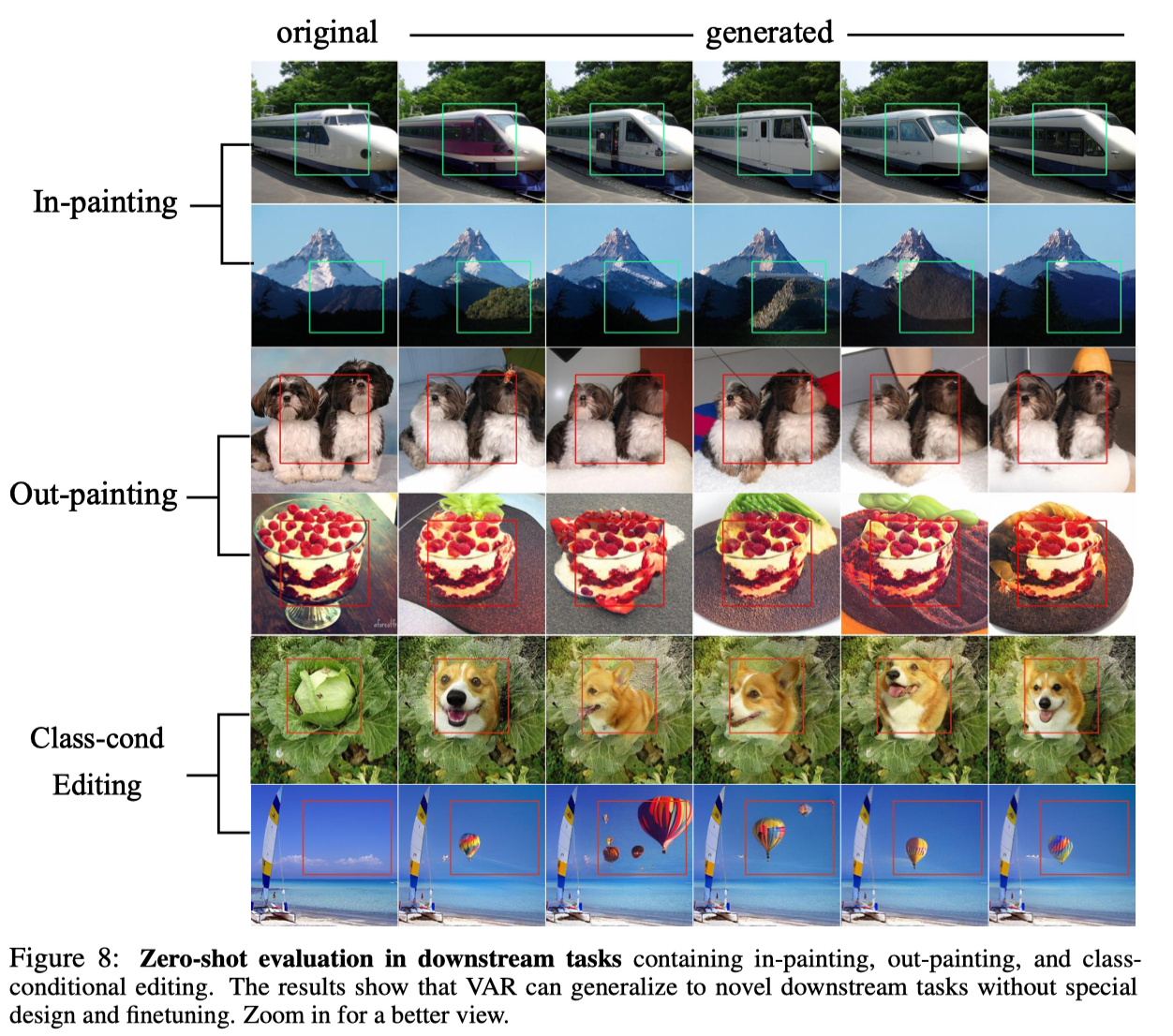
abschließend
VAR bietet eine neue Perspektive für die Definition der autoregressiven Bildfolge, also der Folge von grob bis fein, von globalen Konturen bis zur lokalen Feinabstimmung . Ein solcher autoregressiver Algorithmus stimmt zwar mit der Intuition überein, bringt aber gute Ergebnisse: VAR verbessert die Geschwindigkeit und Generierungsqualität des autoregressiven Modells erheblich, wodurch das autoregressive Modell in vielerlei Hinsicht erstmals das Diffusionsmodell übertrifft . Gleichzeitig weist VAR ähnliche Skalierungsgesetze und Zero-Shot-Generalisierbarkeit auf wie LLM. Die Autoren hoffen, dass die Ideen, experimentellen Schlussfolgerungen und Open Source von VAR zur Erforschung der Verwendung des autoregressiven Paradigmas im Bereich der Bilderzeugung durch die Community beitragen und in Zukunft die Entwicklung einheitlicher multimodaler Algorithmen auf Basis der Autoregression fördern können.
Über das Bytedance Commercialization-GenAI-Team
Das Team von ByteDance Commercialization-GenAI konzentriert sich auf die Entwicklung fortschrittlicher generativer künstlicher Intelligenztechnologie und die Erstellung branchenführender technischer Lösungen einschließlich Text, Bildern und Videos. Durch den Einsatz generativer KI zur Realisierung automatisierter kreativer Arbeitsabläufe können Werbetreibende Institutionen und Entwickler ihre kreative Effizienz und Dynamik verbessern Wert.
Weitere Positionen in den Bereichen visuelle Generierung und LLM des Teams sind offen. Beachten Sie gerne die Rekrutierungsinformationen von ByteDance.
Fellow Chicken „Open-Source“ -Deepin-IDE und endlich Bootstrapping erreicht! Guter Kerl, Tencent hat Switch wirklich in eine „denkende Lernmaschine“ verwandelt. Tencent Clouds Fehlerüberprüfung und Situationserklärung vom 8. April RustDesk-Remote-Desktop-Startup-Rekonstruktion Web-Client WeChats Open-Source-Terminaldatenbank basierend auf SQLite WCDB leitete ein großes Upgrade ein TIOBE April-Liste: PHP fiel auf ein Allzeittief, Fabrice Bellard, der Vater von FFmpeg, veröffentlichte das Audiokomprimierungstool TSAC , Google veröffentlichte ein großes Codemodell, CodeGemma , wird es dich umbringen? Es ist so gut, dass es Open Source ist – ein Open-Source-Bild- und Poster-Editor-Tool