Microservices sind unsterblich – ausführliche Erläuterung der Implementierung gemeinsamer Variablen im Policy-Engine-Projekt
Others
2024-04-17 01:01:57
views: null
Hintergrund
1. Vorschlag gemeinsamer Variablen
Vor einiger Zeit sorgte eine Fallstudie des Amazon Prime Video-Teams für Aufruhr in der Entwickler-Community. Grundsätzlich stellt Prime Video als Streaming-Plattform seinen Kunden täglich Tausende von Live-Streams zur Verfügung. Um sicherzustellen, dass Kunden Inhalte reibungslos erhalten, musste Prime Video ein Überwachungstool entwickeln, um Qualitätsprobleme in jedem von Kunden angesehenen Stream zu identifizieren, was extrem hohe Skalierbarkeitsanforderungen mit sich brachte.
In diesem Zusammenhang hat das Prime Video-Team der Microservice-Architektur Priorität eingeräumt. Da Microservices eine einzelne Anwendung in mehrere Module zerlegen können, löst dies nicht nur das Problem der unabhängigen Entwicklung und Bereitstellung von Tools, sondern sorgt auch für eine höhere Verfügbarkeit, Zuverlässigkeit und technische Vielfalt für Anwendungen. Letztendlich besteht der Dienst von Prime Video aus drei Teilen: Der Medienkonverter sendet die Audio- und Videoströme an den Audio- und Videopuffer; der Fehlerdetektor führt den Algorithmus aus und sendet Echtzeitbenachrichtigungen, wenn Fehler gefunden werden; die Orchestrierung von Serviceprozessen.
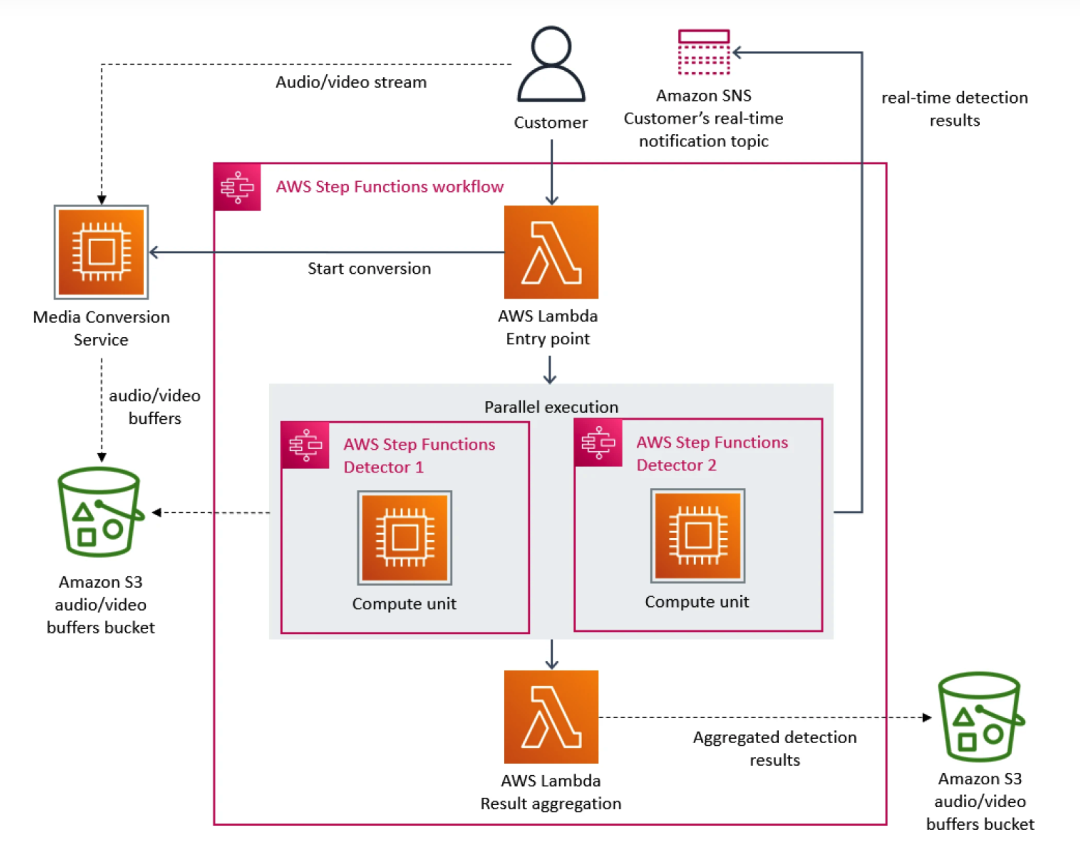 Je mehr Flüsse zum Dienst hinzugefügt werden, desto mehr tritt das Problem übermäßiger Kosten auf. Da AWS Step den Benutzern Gebühren basierend auf Funktionsstatusübergängen berechnet, wird der Overhead für den Betrieb der Infrastruktur in großem Maßstab sehr hoch, was die Verwendung von Prime Video verhindert verhindern, dass das Team die anfängliche groß angelegte Lösung akzeptiert. Am Ende strukturierte das Team von Prime Video die Infrastruktur um und migrierte von Microservices zu einer monolithischen Architektur. Ihren Angaben zufolge konnten die Infrastrukturkosten um 90 % gesenkt werden.
Dieser Vorfall hat uns auch bewusster gemacht, dass die verteilte Architektur im Vergleich zur Single-Service-Architektur auch Mängel aufweist. Beispielsweise stieß das Team von Prime Video auf ein Problem: Die verteilte Architektur kann keine Variablen wie die monolithische Architektur gemeinsam nutzen, was dazu führt, dass der zugrunde liegende Dienst mehr gleiche Anfragen verarbeiten muss, was zu rasant steigenden Kosten führt. Dieses Dilemma besteht auch in der Übersee-Architektur von iQiyi, insbesondere in der Aufrufbeziehung der Strategie-Engine.
Je mehr Flüsse zum Dienst hinzugefügt werden, desto mehr tritt das Problem übermäßiger Kosten auf. Da AWS Step den Benutzern Gebühren basierend auf Funktionsstatusübergängen berechnet, wird der Overhead für den Betrieb der Infrastruktur in großem Maßstab sehr hoch, was die Verwendung von Prime Video verhindert verhindern, dass das Team die anfängliche groß angelegte Lösung akzeptiert. Am Ende strukturierte das Team von Prime Video die Infrastruktur um und migrierte von Microservices zu einer monolithischen Architektur. Ihren Angaben zufolge konnten die Infrastrukturkosten um 90 % gesenkt werden.
Dieser Vorfall hat uns auch bewusster gemacht, dass die verteilte Architektur im Vergleich zur Single-Service-Architektur auch Mängel aufweist. Beispielsweise stieß das Team von Prime Video auf ein Problem: Die verteilte Architektur kann keine Variablen wie die monolithische Architektur gemeinsam nutzen, was dazu führt, dass der zugrunde liegende Dienst mehr gleiche Anfragen verarbeiten muss, was zu rasant steigenden Kosten führt. Dieses Dilemma besteht auch in der Übersee-Architektur von iQiyi, insbesondere in der Aufrufbeziehung der Strategie-Engine.
2. iQiyi-Übersee-Strategie-Engine-Anrufbeziehung
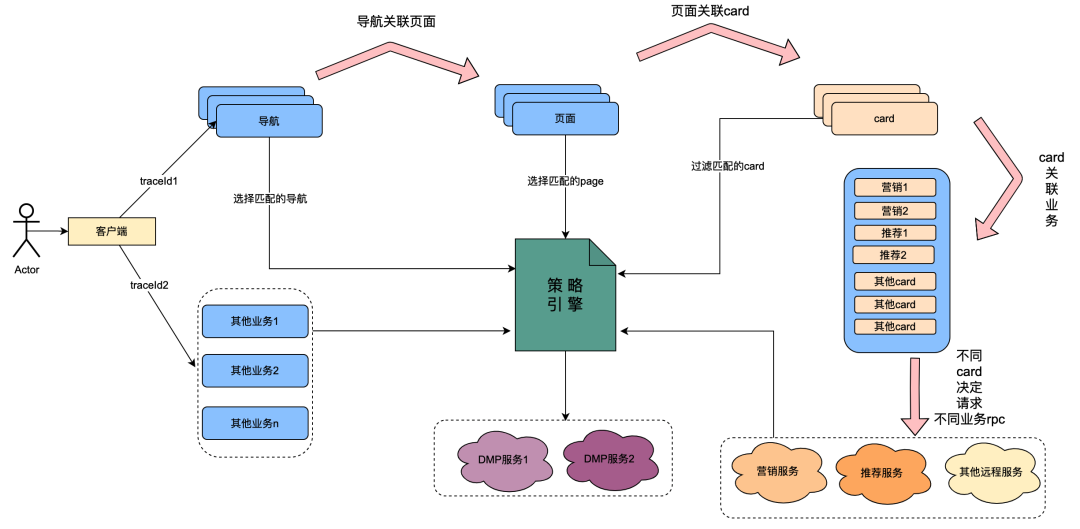
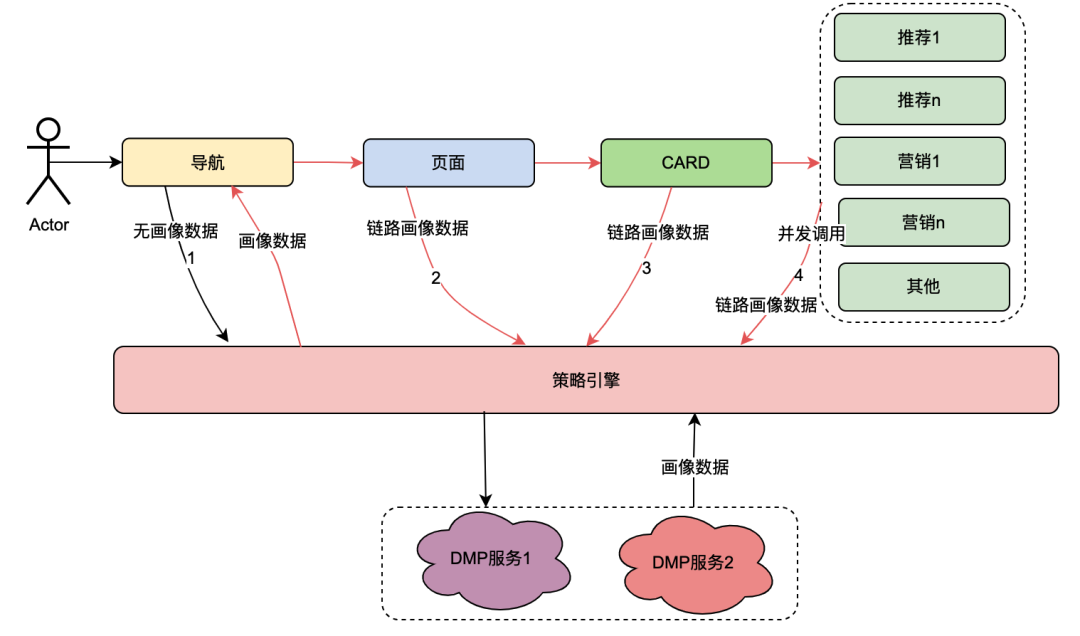
2.1 Einführung in die Aufrufbeziehung der Policy Engine
Unter diesen ist die Karte das Unterteilungsmodul jeder Spalte auf der Seite. Normalerweise sind Spalten wie Fernsehserien und Filme eine Karte. Die Datenquellen in jeder Karte sind unterschiedlich, z. B. Marketingdaten aus Marketing, Inhalte aus Empfehlungen, Programminhalte aus Chips usw. Es besteht eine Zuordnungsbeziehung: Die Seite wird unter der Navigation zugeordnet, die Karte wird unter der Seite zugeordnet und die spezifischen Geschäftsdaten in der Karte werden unter der Karte zugeordnet.
Die Richtlinien-Engine ist ein Matching-Dienst zur Identifizierung von Personengruppen. Derzeit ist beispielsweise eine Gruppenrichtlinie konfiguriert, die japanische Gold-Mitglieder, Männer, Ablauftage der Mitgliedschaft von weniger als 7 Tagen und die Präferenz für japanische Anime enthält. Der Richtlinien-Engine-Dienst kann erkennen, ob ein Benutzer zu den oben genannten Gruppenrichtlinien gehört.
Nach der technologischen Transformation von „ Alles ist möglich “ wurde die Möglichkeit erreicht, die Benutzerprofildimensionen von Navigation, Seiten, Karten und Daten innerhalb von Karten anzupassen. Die allgemeine Implementierung ist wie folgt: Wenn der Client eine Anfrage initiiert, fordert er zuerst die Navigations-API an. Im Hintergrund der Navigationsdatenkonfiguration konfigurierten Betriebsstudenten verschiedene Navigationsdaten, und jedes Navigationsdatenelement wurde einer Richtlinie zugeordnet. Die Navigations-API ruft intern alle Navigationsdaten ab und verwendet dann die mit der Navigation verknüpfte Richtlinie sowie die Benutzer-UID und die Geräte-ID als Eingabeparameter, um die Richtlinien-Engine anzufordern und die entsprechende Richtlinie zurückzugeben Die Navigation mit der Richtlinie, die den Anforderungen entspricht, wird zurückgegeben, wodurch die Möglichkeit für verschiedene Benutzerporträts realisiert wird, unterschiedliche Navigationsdaten anzuzeigen. Seiten, Karten und Daten innerhalb von Karten werden in etwa auf die gleiche Weise implementiert.
Aus dem obigen Inhalt lässt sich zusammenfassen, dass der aufrufende Link der Richtlinien-Engine die folgenden Merkmale aufweist:
(1) Ein Benutzervorgang, der eine Seite öffnet, ruft nacheinander mehrere Richtlinien-Engine-Dienste auf.
(2) Die Leistung der Policy-Engine-Schnittstelle wirkt sich direkt auf die Benutzererfahrung aus: Sie verknüpft Anfragen für viele Seitengeschäftsdienste.
(3) Strategie-Engine-Daten erfordern einen starken Echtzeitcharakter: Nachdem ein Benutzer eine Mitgliedschaft erworben hat, sollten diese sofort mit mitgliederbezogenen Strategien verknüpft werden.
2.2 Aufgetretene Dilemmata
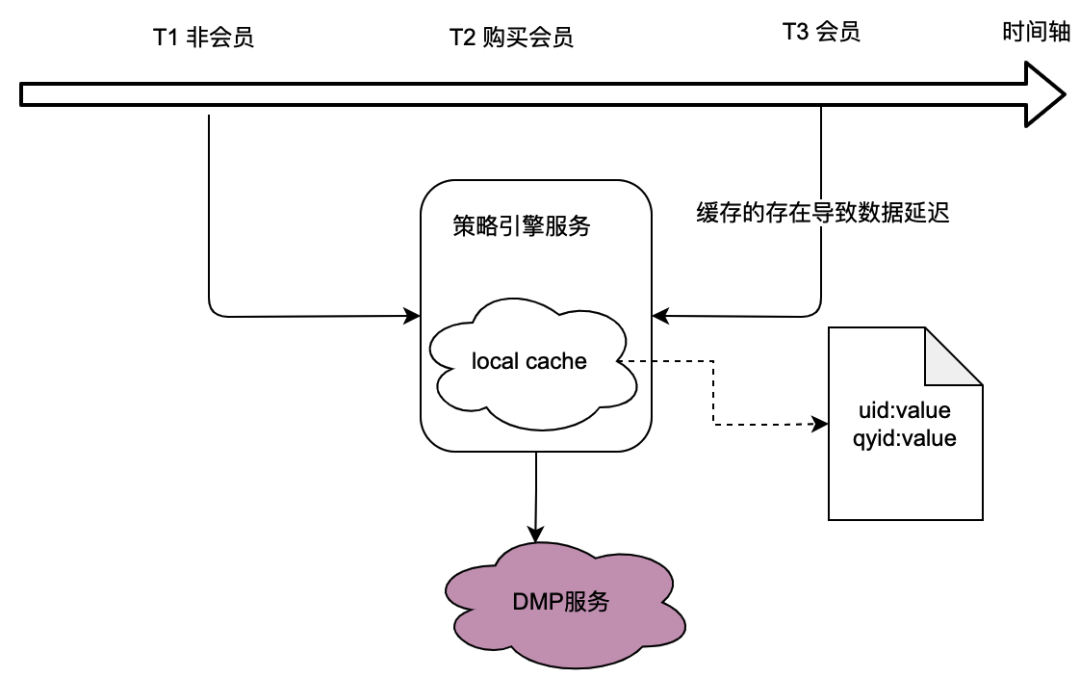
Wie aus der Aufrufbeziehung im vorherigen Abschnitt hervorgeht, übernimmt die Richtlinien-Engine als zugrunde liegender Dienst den Datenverkehr vieler Geschäftsparteien, und die Richtlinien-Engine muss Benutzerporträtdaten abrufen, um festzustellen, ob die Crowd-Richtlinie übereinstimmt wiederum ist stark auf den DMP-Dienst (Data Management Platforms) angewiesen. Um den Datenverkehr zum DMP-Dienst zu reduzieren, haben wir über eine lokale Caching-Lösung nachgedacht.
Das Problem dabei liegt jedoch auf der Hand: Es kann die Anforderungen an Echtzeitdaten nicht erfüllen . Wenn ein Benutzer eine Mitgliedschaft erwirbt und sich die vom DMP-Dienst zurückgegebenen Porträtdaten ändern, kann der Benutzer aufgrund der offensichtlich nicht tolerierbaren Verzögerung beim lokalen Caching die neuesten richtlinienbezogenen Daten nicht sehen.
Wir haben auch über verteilte Caching-Lösungen nachgedacht. Wenn die Benutzer-ID als Schlüssel verwendet wird, ist der Problempunkt derselbe wie beim lokalen Cache, der die Echtzeitanforderungen nicht erfüllen kann.
Daher ist die Optimierung des Datenverkehrs zu DMP- Diensten bei gleichzeitiger Erfüllung der Echtzeitanforderungen der Daten eine Herausforderung für die Optimierung des gesamten Policy-Engine-Projekts.
Der Beginn gemeinsamer Variablen
1. Übersicht
Der Kern des Dilemmas besteht darin, dass verteilte Dienste keine Variablen gemeinsam nutzen können. Das Seitenöffnungsverhalten eines Benutzers geht mit mehreren Backend-Anfragen einher, und die mit diesen mehreren Backend-Anfragen verbundenen Benutzerprofildaten sind tatsächlich eins, dh die vom DMP-Dienst erhaltenen Profildaten müssen identisch sein. Als Nächstes führen wir eine abstrakte Analyse des Aufruflinks der Richtlinien-Engine durch, um zu sehen, welche Funktionen sie bietet.
2. Analyse der Aufrufverknüpfungen der Policy Engine
Die Aufrufbeziehung der Richtlinien-Engine wurde im Kapitel 1.2.1 Einführung in die Aufrufbeziehung der Richtlinien-Engine vorgestellt. Dieses Mal klassifizieren wir hauptsächlich ihre Aufrufverbindungen.
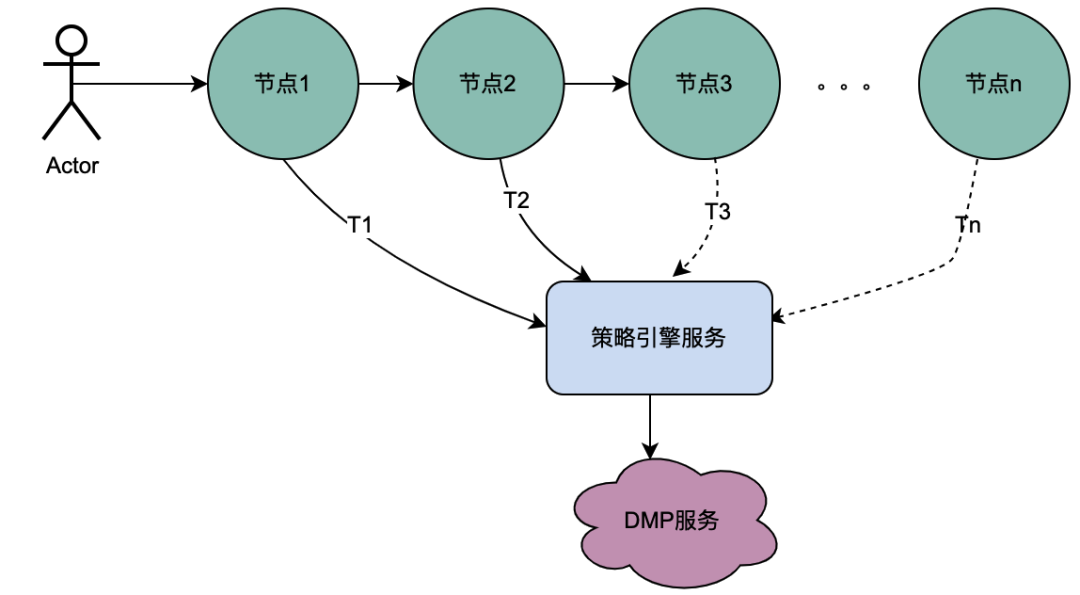
2.1 Szenario für serielle Anrufe
Wie Sie der obigen Abbildung entnehmen können, initiiert ein Benutzer eine Anfrage und durchläuft mehrere Knotendienste. Die Knotendienste stehen in einer seriellen Beziehung, und jeder Knoten ist auf den Richtlinien-Engine-Dienst angewiesen, um das Porträt des Benutzers abzurufen Daten, und natürlich stammen die Anfragen von T1 bis Tn alle vom selben Benutzer, und die vom DMP-Dienst erhaltenen Daten müssen identisch sein Der Service von T1 nach Tn kann auf 1 Anfrage optimiert werden. Wir nennen die vom DMP-Dienst erhaltenen Porträtdaten hier verteilte gemeinsam genutzte Variablen .
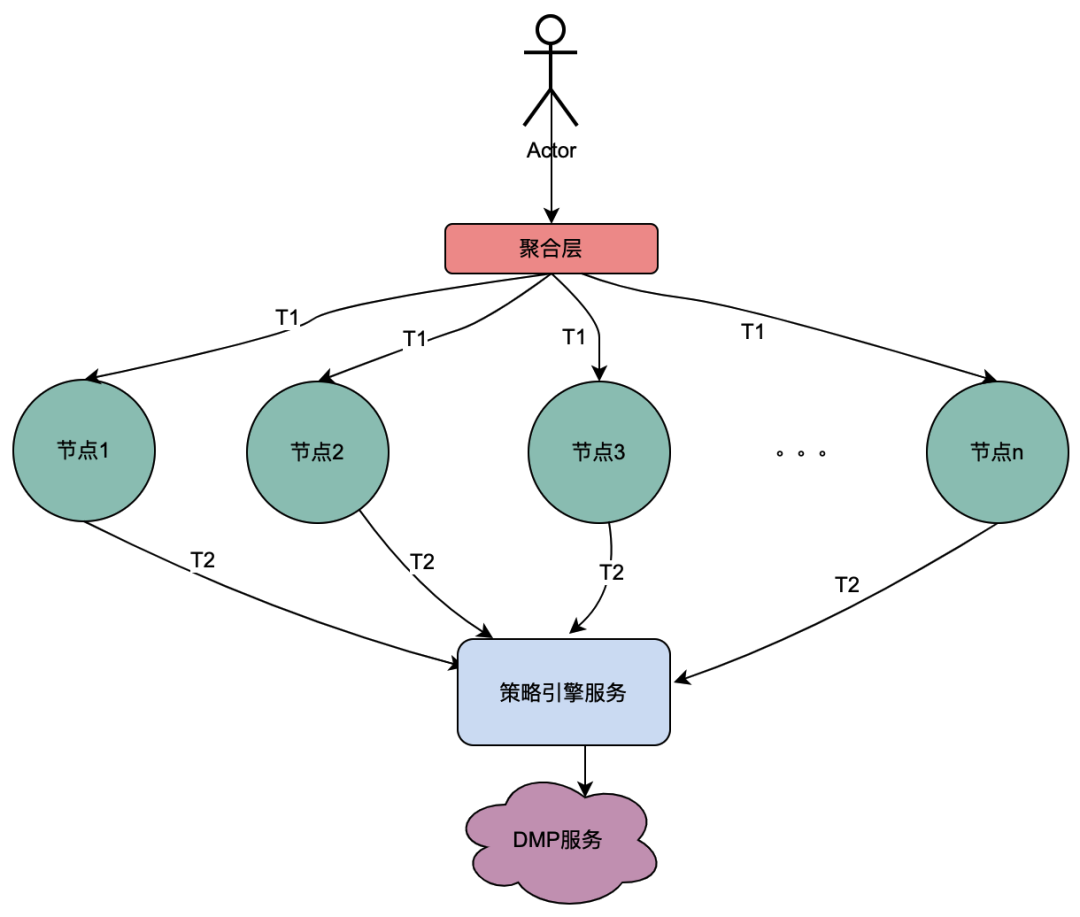
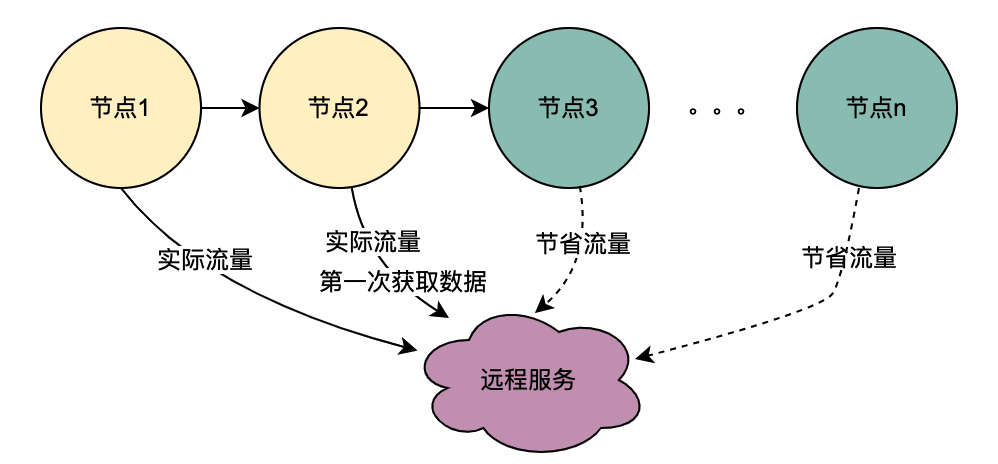
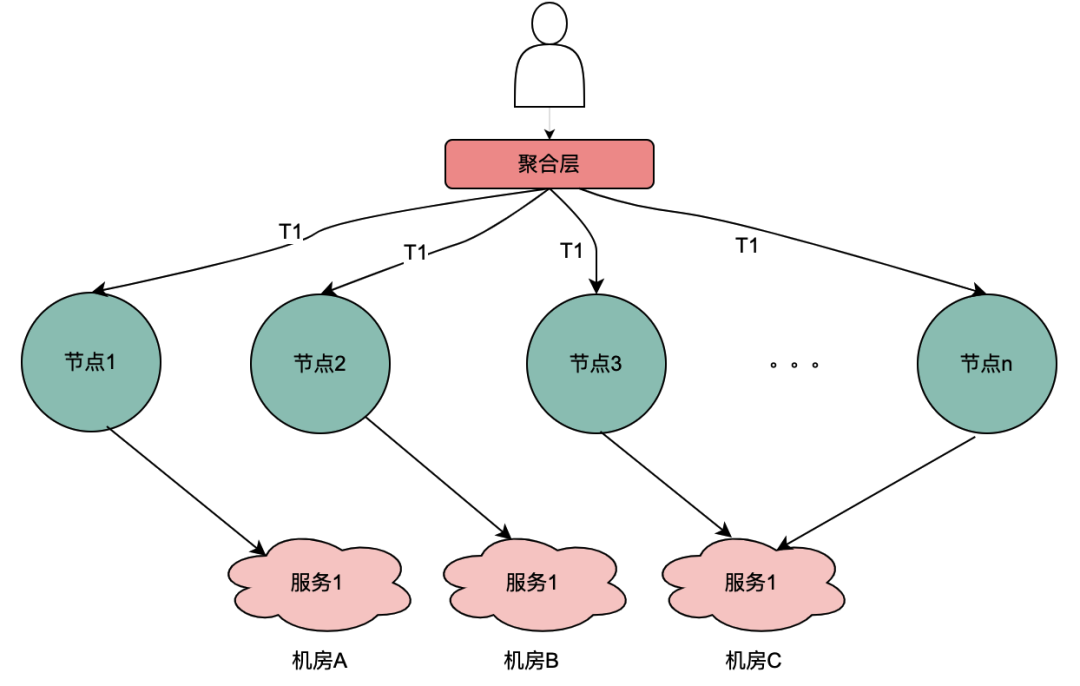
2.2 Parallelanrufszenario
Anders als bei der obigen seriellen Anrufkette erfolgen die seriellen Anrufe T1 bis Tn in zeitlicher Reihenfolge und der T1-Anruf muss vor dem T2-Anruf erfolgen. Es gibt keine zeitliche Reihenfolge für parallele Anrufe, das heißt, derselbe Benutzer kann eine Anfrage initiieren, und das Unternehmen der Aggregationsschicht kann gleichzeitig eine Anfrage an den abhängigen Dienst initiieren, und der abhängige Dienst hängt von der Richtlinien-Engine ab. Eine vom selben Benutzer initiierte Anfrage wird gleichzeitig ausgeführt. Stellen Sie mehrere Anfragen an die Richtlinien-Engine. Wenn dann mehrere Anfragen in eine Warteschlange gestellt werden, die erste Anfrage tatsächlich den DMP-Dienst anfordert und die übrigen Anfragen in der Warteschlange auf die Daten der ersten Anfrage warten, können n Anfragen zu einer Anfrage optimiert werden. Wir nennen die vom DMP-Dienst erhaltenen Porträtdaten hier lokale gemeinsam genutzte Variablen .
Einführung in verteilte Umgebungsvariablen
1. Prinzipübersicht
Wenn der Benutzer die Seite öffnet, fordert der Client die Navigation an und ruft dann nacheinander die Funktionsseite, die spezifische Karte und die Funktionskartendaten ab. Jeder Link beinhaltet den Policy Engine-Dienst. Unter normalen Umständen löst eine Clientanforderung mehrere Aufrufe an die Richtlinien-Engine aus, wodurch mehrere Aufrufe an den DMP-Dienst verursacht werden. Offensichtlich handelt es sich jedoch um eine Anfrage desselben Benutzers, und die durch diese Anfragen an den DMP-Dienst erhaltenen Benutzerporträtdaten müssen identisch sein.
Basierend auf der obigen Analyse besteht eine einfache Beschreibung des Prinzips verteilter gemeinsam genutzter Variablen darin, dass [Navigation] beim ersten Abrufen der Porträtdaten deren Inhalt in den Anforderungslink einfügt und ihn ähnlich wie die TraceId des Vollständigen weitergibt Verknüpfung. Wenn der Downstream wie [Seite] auf diese Weise die Richtlinien-Engine erneut anfordert, kann er die Linkdaten direkt im Linkkontext TraceContext abrufen, ohne den DMP-Dienst anzufordern. Für CARD gilt das Gleiche auch für das Seitengeschäft.
Es ist erwähnenswert, dass TraceContext nur per Anfrage weitergegeben werden kann. Auf diese Weise können beim Speichern von Linkdaten die Porträtdaten erst im Linkkontext TraceContext platziert werden, nachdem [Navigation] die Richtlinien-Engine-Daten abgerufen hat.
如果导航没有关联策略数据,无需请求策略引擎,但是后面的页面、CARD等又关联了策略引擎,那该怎么处理呢?我们参考了TraceId的处理方式,在每个调用策略引擎服务的节点(不同业务如页面、CARD等)进行判断是否有链路数据,如果没有,则获取策略引擎数据后放置进去,如果有则忽略。这样就保证最前置的节点拿到画像数据后,进行向后传递,减少后续节点对于DMP服务的流量。很明显,这些逻辑有一些业务侵入性,所以我们将调用策略引擎的方式优化为SDK调用,在SDK内部做了一些统一的逻辑处理,让业务调用方无感知。
2、全链路追踪 — 基于SkyWalking
skywalking 是分布式系统的应用程序性能监视工具,专为微服务、云原生架构和基于容器化技术(docker、K8s、Mesos)架构而设计,它是一款优秀的 APM(Application Performance Management)工具。skywalking 是观察性分析平台和应用性能管理系统。提供分布式追踪、服务网格遥测分析、度量聚合和可视化一体化解决方案。对于为什么选择skywalking,除去skywalking本身的优势以外,业务上的理由是爱奇艺海外项目目前已经接入SkyWalking,开发成本最低,维护更加便利。所以,使用skywalking传递分布式共享变量只需要引入一个Maven依赖,调用其特有的方法,就可以将数据进行链路传递。
分布式共享变量的方案会增加网络传递数据的大小,增加网络开销;当链路数据足够大的时候甚至会影响服务响应性能。因此控制链路数据大小、链路数据的控制和评估链路数据对网络性能造成影响是尤为重要的。下面将详细介绍。
3、链路传输优化 — 压缩解压缩
3.1 压缩基本原理
目前用处最为广泛的压缩算法包括Gzip等大多是基于DEFLATE,而DEFLATE 是同时使用了 LZ77 算法与哈夫曼编码(Huffman Coding)的一种无损数据压缩算法。其中 LZ77 算法是先通过前向缓冲区预读取数据,然后再向滑动窗口移入(滑动窗口有一定的长度), 不断寻找能与字典中短语匹配的最长短语,然后通过标记符标记,依次来缩短字符串的长度。哈夫曼编码主要是用较短的编码代替较常用的字母,用较长的编码代替较少用的字母,从而减少了文本的总长度,其较少的编码通常使用构造二叉树来实现。
3.2 压缩选型
由于BI获取的用户画像TAG固定且个数较少,因此这里选择DMP数据作为实验对比数据。以下是不同场景下压缩大小对比数据

方案3得到的数据最小,因此选择方案3作为分布式共享变量的压缩方案。
4、数据大小导致的网络消耗分析和极端情况控制
4.1 背景概述
这种方案也存在一些弊端,即需要把用户画像数据通过网络传递,显然这增加了网络开销。理论上,网络数据量与传输速度成正比,但是在工程实践中,带宽肯定是有上限的,因此,对于DMP画像数据存入大小进行压测试验,以确定分布式共享变量对于网络性能的影响。
4.2 压测方案
1.测试网络,画像数据不被策略引擎使用,策略引擎依然请求DMP服务。
实验组是请求策略引擎服务的时候带入压缩后的画像数据,对照组是请求策略引擎服务的时候不带入压缩后的画像数据。调整并发值,比较在不同QPS场景下两者的接口性能。
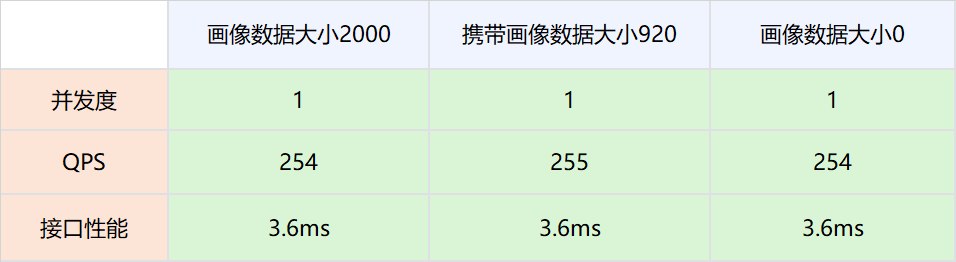
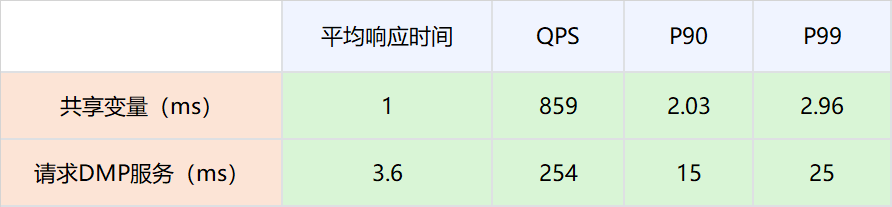
2.分布式共享变量的画像数据被策略引擎使用,策略引擎在有分布式共享变量画像数据的时候,不再请求DMP服务。
4.3结论
-
网络链路上存放数据大小在2000以下,对网络性能的影响可以忽略不计。
-
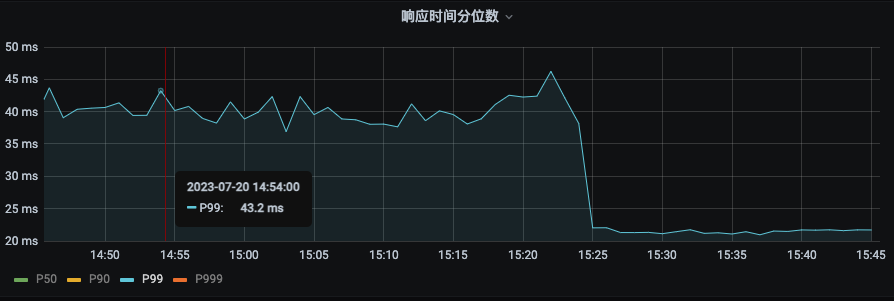
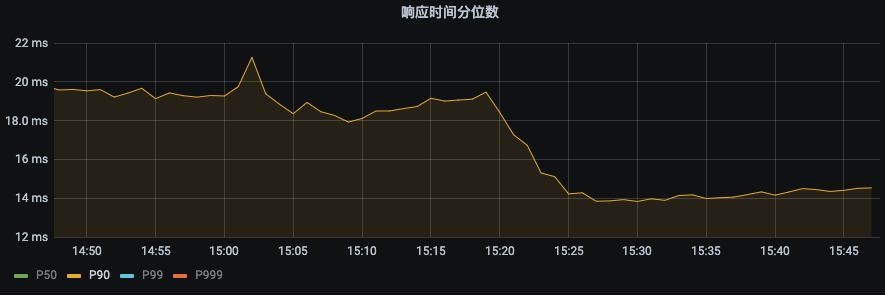
因为分布式共享变量的存在而减少对DMP服务的请求,接口性能可以有比较大的提升。具体数值为P99从25ms提升到2.96ms。
4.4 极端情况控制
因为DMP数据与用户行为相关,比如一个用户在海外站点所有站点都有购买会员的行为,那么其DMP画像数据就会很大。为了防止这种极端情况所以在判断压缩后的用户画像数据足够大的时候,将自动舍弃,而不是放入网络当中,防止大数据对整个网路数据的性能损耗。
5、线上运行情况
5.1 性能优化
|
|
|
|
|
|
|
P99 由之前的43ms下降到22ms。下降幅度 48.8%
|
P90由之前19ms下降到14ms,下降幅度26.3%
|
5.2 对DMP服务的流量优化
|
|
|
|
|
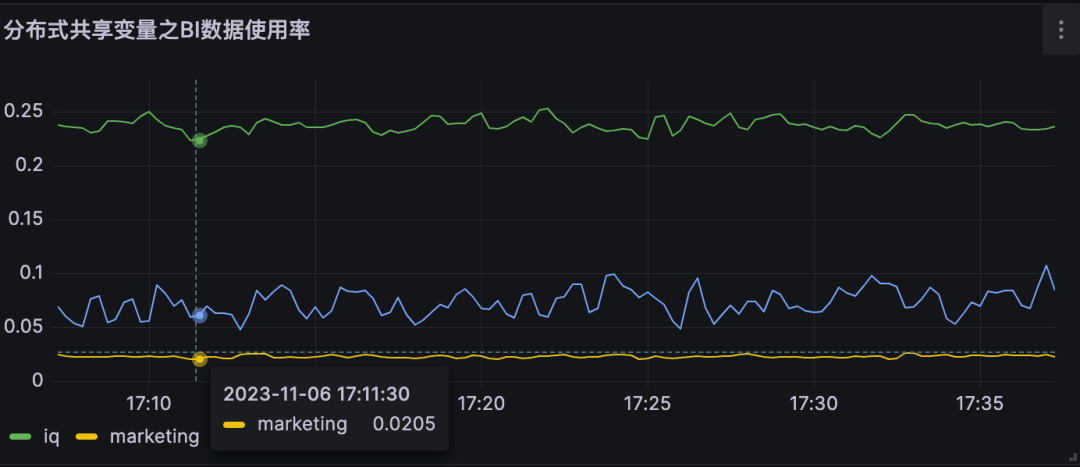
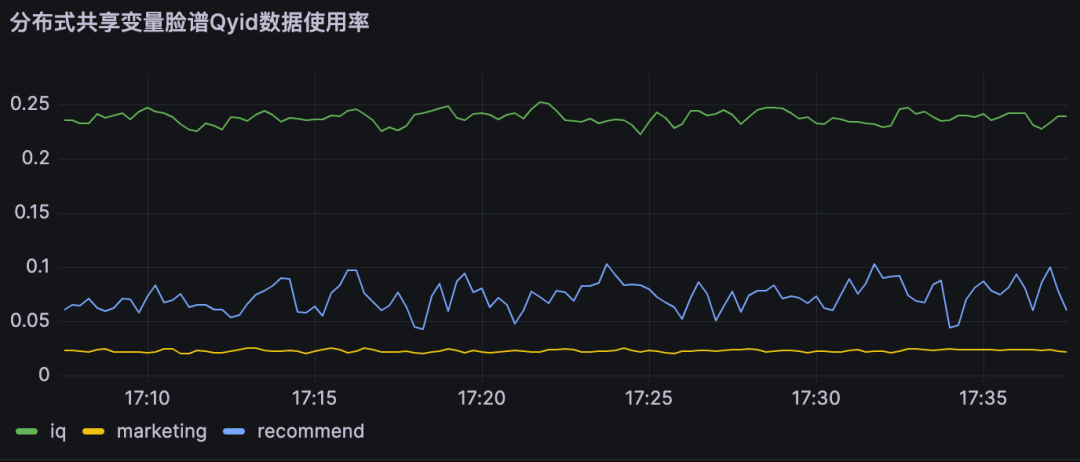
分布式共享变量使用率即为对不同DMP服务优化流量。
A业务节约大约25%的流量,B业务节约约10% 的流量,
|
|
|
|
|
6、结论
分布式共享变量在满足数据实时性要求的前提下,减少了对DMP服务的流量,同时提高了策略引擎服务的接口性能,具体优化指标见上节。
本地共享变量介绍
1、原理概述
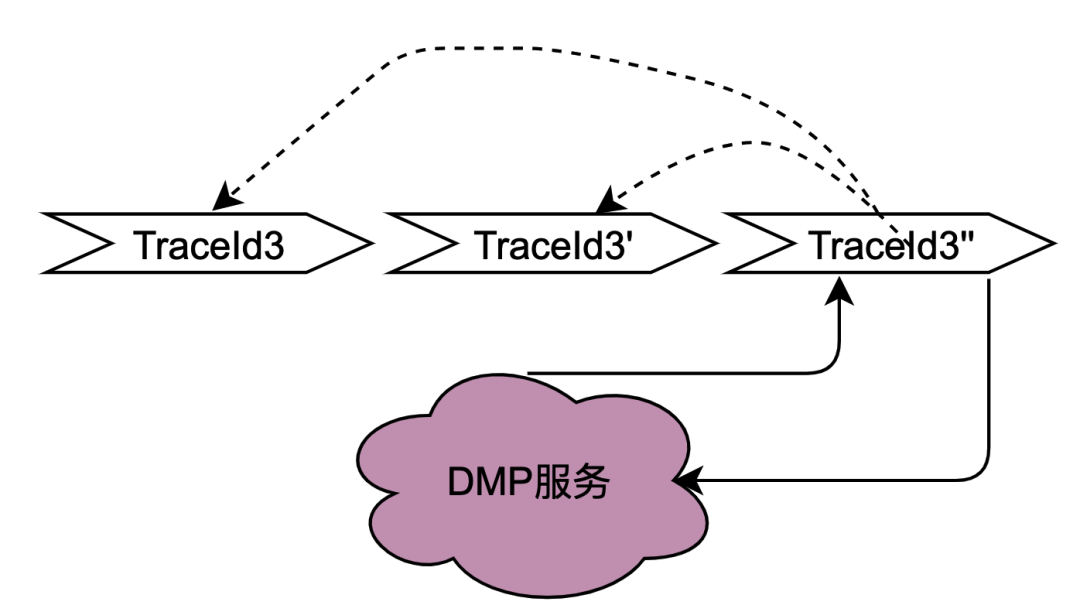
在2.2.2 并行调用场景章节对本地共享变量解决的调用场景进行了阐述,主要解决的是同一个用户并发请求策略引擎带来的多次请求DMP服务问题。如何区分是同一个用户的同一次请求呢?答案是TraceId。在一个请求下,TraceId一定是相同的,如果TraceId相同,那么策略引擎则可以认为是同一个用户的一次请求。
如上图,如果同时多个TraceId3的请求到达策略引擎,将这些请求放入队列,只要其中一个去获取用户画像数据(此处为TraceId3''),其余的请求TraceId3和TraceId3'在队列中等待TraceId3''的结果拿来用即可。
这种思路可以很好的优化并发请求的数据,符合策略引擎调用特性。实现起来有点类似AQS,开发落地有一些难点,比如Trace3''什么时候去请求DMP服务,当拿到数据后,后面仍然有其他trace3进来该如何处理,等待多少时间?这么一思考,这个组件的实现将会耗费我们很多的开发时长,那么有没有现成的中间件可以用呢?答案是本地缓存框架。
无论是本地缓存Caffeine 还是Guava Cache,有相同key的多个请求,只有一个key会请求下游服务,而其他请求会等待拿现成的结果。另外存放的时间可以通过配置缓存的失效时间来确定,至于失效时间的计算方法,将在下面章节会介绍。
2、网关层Hash路由方式的支持
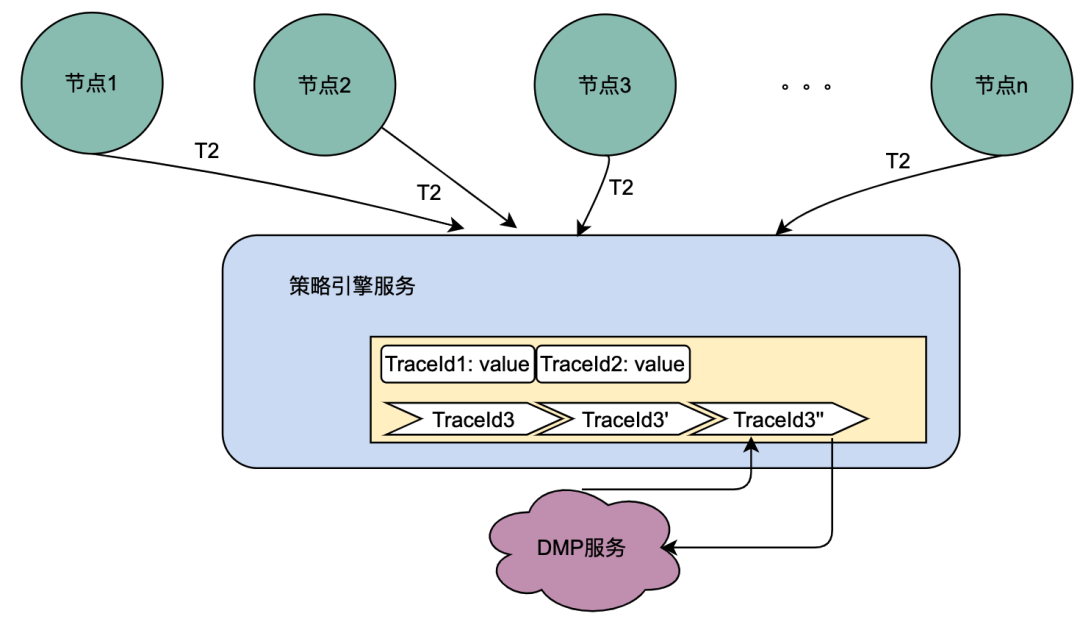
目前,主流的服务一般都是多机房多机器部署,这样有水平扩展能力可以应对业务增长带来的流量增加的问题。但同一个用户的同一个请求,很可能到不同的服务实例,这样上一次获取到的本地缓存数据在下一次请求当中就无法获取。
如上图,同一个用户的同一次请求,被聚合层并发请求到不同业务节点1到节点n。由于策略引擎服务是多实例部署,那么不同节点的请求可能到不同实例,那么本地共享变量的命中率就会大大降低,对DMP服务的流量节约数据就会小很多。因此,需要一个方案使得用户的多次请求能到同一个机房的同一个实例。
最终落地的方案是网关支持按照业务自定义字段Hash路由。策略引擎使用qyid进行hash路由,即同一个设备的所有请求到策略引擎服务,那么路由到的机器实例一定是同一个。这样可以很好的提升本地共享变量的命中率。这里提一下,相比轮询请求,字段Hash方式存在如流量偏移的问题,需要配合服务实例流量的监控和报警,避免某些实例流量过多而导致不可用。由于和本次主题无关,实例流量的监控和报警在这里就不做介绍。
3、本地共享变量个数和有效时间设计
和本地缓存不同,本地共享变量的最大个数和过期时间与命中率不成正比,这和具体业务指标相关。
假设策略引擎服务QPS10000,服务实例有50台,那么每台实例的QPS是200,即一台服务实例每秒的请求是200个。只需要保证,同一个TraceId的一批请求,在个数区间内不被淘汰,在时间区间内不被过期即可。我们通过网关日志查找历史上同一个traceId的请求时间戳,几乎都在100ms内。
那么过期时间设置为1s,最大个数设置为200个就可以保证绝大多数同一个TraceId的批次请求,只有一个请求下游服务,其余从缓存获取数据。我们为此也进行了实验,设置不同的过期时间和缓存最大个数,结论和以上分析完全一致。
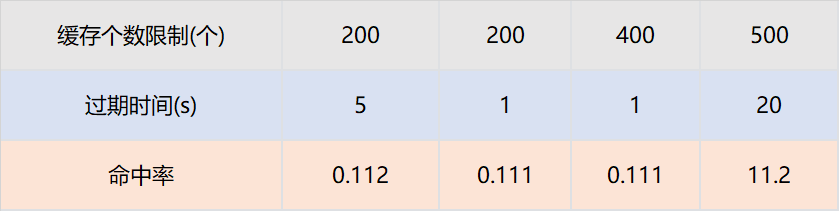
本地共享变量命中率与接口QPS和相同TraceId并发时间相关。
4、结论
-
对于DMP服务1,优化流量15.8%。对于DMP服务2,优化流量 16.7%。对于DMP服务3,优化流量16.2%。
-
与分布式共享变量一样,本地共享变量同样可以满足数据实时性要求,即不会存在1.2.2 遇到的困境 所遇到的缓存导致的数据实时性不够的问题。
总结和展望
本次优化是比较典型的技术创新项目。是先从社区看到一篇技术博客,然后想到爱奇艺海外遇到相同痛点问题的的项目,从而提出优化因为微服务导致的策略引擎对于DMP服务流量压力的目标。
在落地过程中,遇到使用本地缓存进行优化而无法克服数据实效性问题的挑战。最终沉下心分析策略引擎的调用链路,将调用链路一分为二:串行调用和并行调用,最终提出了共享变量的解决方案。因为串行调用和并行调用的特点迥异,依次针对两者进行分期优化,其中第一期通过分布式共享变量优化了串行调用DMP服务的流量,在第二期通过本地共享变量优化了并行调用DMP服务的流量。
参考文章:

也许你还想看
低代码、中台化:爱奇艺号微服务工作流实践
揭秘内存暴涨:解决大模型分布式训练OOM纪实
分布式系统日志打印优化方案的探索与实践
本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Origin my.oschina.net/u/4484233/blog/10924140