In der modernen Deep-Learning-Entwicklung greifen wir normalerweise auf andere Module zurück, um komplexe Softwaresysteme wie Bausteine zu erstellen. Dieser Prozess ist oft schnell und effektiv. Aufgrund der Komplexität und Kopplung des Systems war es jedoch schon immer ein Problem für Designer und Betreuer von Deep-Learning-Systemen, Probleme schnell zu lokalisieren und zu lösen.
Als Mitglied des Back-End-Technikteams von iQiyi haben wir den Prozess der Lösung von Gedächtnisproblemen im Deep-Learning-Training detailliert aufgezeichnet, in der Hoffnung, Kollegen, die hart an der Lösung heikler Probleme arbeiten, etwas Inspiration zu geben.
Hintergrund
Im letzten Quartal haben wir im A100-Cluster zufällige CPU-Speicher-OOM-Phänomene beobachtet. Mit der Einführung des Trainings für große Modelle wurde Oom noch unerträglicher, was uns entschlossen machte, dieses Problem zu lösen.
Als ich auf meine Herkunft zurückblickte, fühlte ich mich plötzlich erleuchtet. Tatsächlich waren wir einmal sehr nah an der Wahrheit des Problems, aber es fehlte uns die Vorstellungskraft und wir haben es verpasst.
Verfahren
Zu Beginn führten wir eine induktive Analyse der historischen Protokolle durch. Es wurden mehrere Regeln entdeckt, die für die endgültige Lösung eine sehr gute leitende Bedeutung haben:
-
Dies ist ein neues Problem, das im A100-Cluster auftritt und in anderen Clustern nicht aufgetreten ist.
-
Das Problem hängt mit dem verteilten DDP-Training von Pytorch zusammen. Andere Trainingsmodi, die Pytorch verwenden, sind nicht aufgetreten.
-
Dieses OOM-Problem ist ziemlich zufällig, einige treten innerhalb von 3 Stunden auf, andere treten erst nach mehr als einer Woche auf.
-
Während des OOM kommt es zu einem Speicheranstieg, der im Grunde den Anstieg von 10 % auf 90 % innerhalb von eineinhalb Minuten abschließt, wie in der folgenden Abbildung dargestellt:
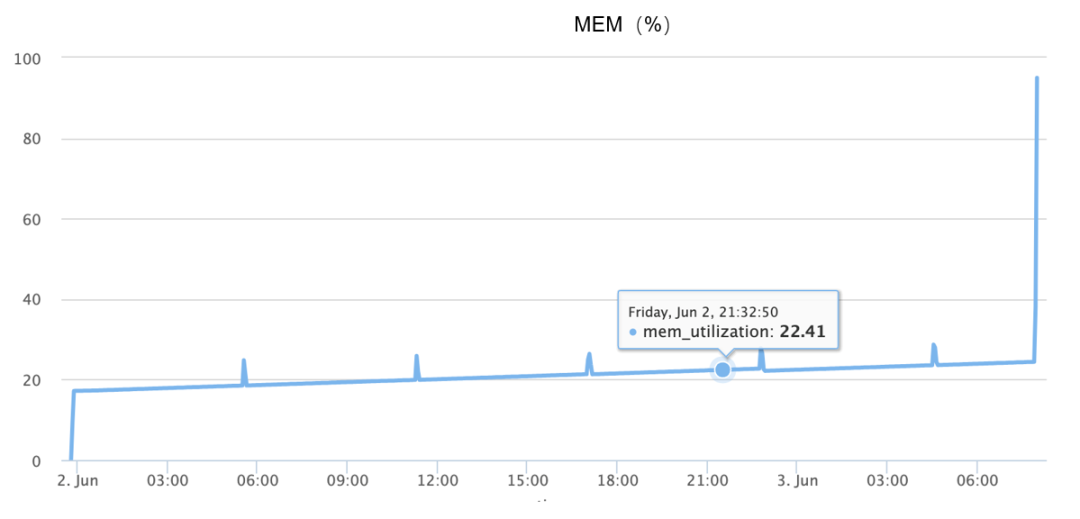
Obwohl die oben genannten Informationen verfügbar sind, habe ich mich zu Beginn völlig auf unterschiedliche Vorstellungen verlassen, da das Problem nicht zuverlässig reproduziert werden kann, wie zum Beispiel:
-
Könnte es sich um ein Codeproblem handeln, weil das Objekt nicht recycelt wird, was zu kontinuierlichen Speicherverlusten führt?
-
Könnte es sich um ein Problem mit der zugrunde liegenden Speicherzuweisung handeln, ähnlich der Tatsache, dass die PTMALLOC-Zuweisung der Glibc zu viele Fragmente hat, sodass plötzliche Speicheranforderungen zu einem bestimmten Zeitpunkt zu einer kontinuierlichen Speicherzuweisung führen?
-
Könnte es sich um ein Hardwareproblem handeln?
-
Könnte es sich um einen Fehler in einer bestimmten Version der Software handeln?
Im Folgenden stellen wir die ersten beiden Annahmen im Detail vor.
-
Ist es ein Problem mit dem Code?
Um festzustellen, ob es sich um ein Codeproblem handelt, haben wir der Szene, in der das Problem aufgetreten ist, Debugging-Code hinzugefügt und ihn regelmäßig aufgerufen. Der folgende Code gibt alle Objekte aus, die vom aktuellen Python-GC-Modul nicht recycelt werden können.
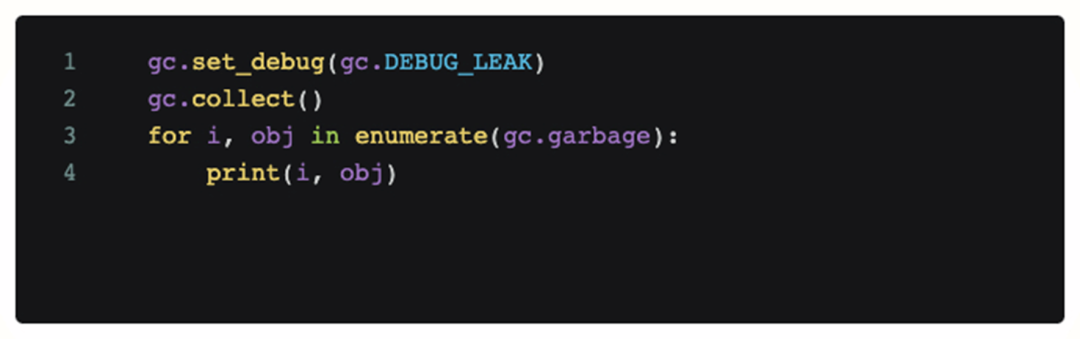 Nach dem Hinzufügen dieses Codes zeigt die erhaltene Protokollanalyse jedoch , dass es während OOM kein nicht erreichbares Objekt gibt, das viel Speicher beansprucht, und dass kontinuierliches GC OOM selbst nicht lindern kann. An diesem Punkt ist unsere erste Vermutung also fehlgeschlagen, das Problem wird nicht durch den Code verursacht (Speicherleck).
Nach dem Hinzufügen dieses Codes zeigt die erhaltene Protokollanalyse jedoch , dass es während OOM kein nicht erreichbares Objekt gibt, das viel Speicher beansprucht, und dass kontinuierliches GC OOM selbst nicht lindern kann. An diesem Punkt ist unsere erste Vermutung also fehlgeschlagen, das Problem wird nicht durch den Code verursacht (Speicherleck).
-
Liegt es an der Speicherzuweisung?
Zu diesem Zeitpunkt haben wir den Jemalloc-Speicherzuweiser eingeführt. Im Vergleich zum Standard-PTMALLOC besteht der Vorteil darin, dass er eine effizientere Speicherzuweisung und eine bessere Unterstützung für das Debuggen der Speicherzuweisung selbst bietet.
-
Könnte es ein Problem mit der Standardspeicherzuweisung sein?
-
Bessere Debugging- und Analysetools
Um den aktuellen Status von Jemalloc in Python direkt anzuzeigen, ohne den Torch-Code selbst zu ändern, haben wir ctypes verwendet, um die Jemalloc-Schnittstelle direkt in Python verfügbar zu machen:
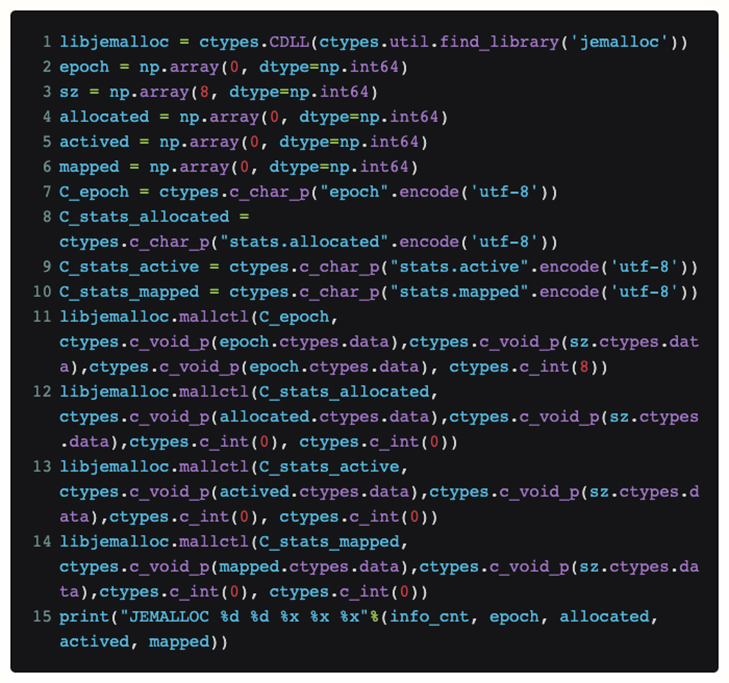
Wenn wir diesen Code in eine Funktion einfügen, können wir auf diese Weise regelmäßig die aktuell von jemalloc von der oberen Schicht empfangene Anfrage und die tatsächliche physische Speichergröße kennen, die vom System angefordert wird.
Nach dem eigentlichen Reproduktionsprozess wurde schließlich festgestellt, dass die beiden zugewiesenen und zugeordneten Werte beim Auftreten von OOM sehr nahe beieinander liegen. Unsere Hypothese über die Fragmentierung des Gedächtnisses ist also bankrott.
-
Was genau hat das Problem verursacht?
Als wir am Ende unserer Kräfte waren, sortierten wir noch einmal die vorhandenen OOM-Protokolle und stellten fest, dass es eine Richtung gab, auf die wir uns zuvor nicht konzentriert hatten: Das heißt, wir hatten mehrere Maschinen, die zu ähnlichen Zeiten arbeiteten (1-2 Minuten nebenan) mehrmals ) OOM auftritt.
Welche logische Erklärung gibt es also für diese magische Synchronizität? Gewöhnliche Fehler sollten nicht dazu führen, dass diese Kohärenz erneut auftritt. Es könnte also eine unvermeidliche Verbindung zwischen ihnen bestehen.
Woher kommt also dieser Zusammenhang? Um dieses Problem zu untersuchen, verlagert sich die analytische Perspektive auf die Netzwerkkommunikation im verteilten Training.
Der anfängliche Verdacht bezüglich der Kommunikation konzentrierte sich auf Maschinen, bei denen OOM auftrat. Es wurde vermutet, dass sie aus irgendeinem Grund miteinander kommunizierten, was zu Problemen untereinander führen würde. Deshalb wurde tcpdump zum täglichen Training hinzugefügt, um den Netzwerkverkehr zu überwachen.
Schließlich habe ich nach meinem Beitritt zu tcpdump die fragwürdigste Kommunikation während eines OOM mitbekommen. Das heißt, der OOM-Computer hat einige Minuten vor dem Auftreten des Problems Sicherheitsscan-Verkehr empfangen.
endgültige Positionierung
Nachdem wir das Sicherheitsteam beim Scannen des verdächtigen Objekts erwischt hatten, führten wir gemeinsam mit dem Sicherheitsteam eine Analyse durch und stellten schließlich fest, dass das OOM-Problem auf der Grundlage des Scans stabil reproduziert werden konnte, sodass die auslösende Ursache fast sicher war. Zu diesem Zeitpunkt können wir jedoch nur die Sicherheitsscanstrategie reproduzieren und ändern, um das OOM-Problem zu vermeiden. Außerdem müssen wir den Code weiter analysieren und ihn schließlich lokalisieren.
Nach der Analyse und Positionierung des Codes wurde schließlich festgestellt, dass das Problem im verteilten DDP-Trainingsprotokoll von Pytorch liegt. Der relevante Code lautet wie folgt:
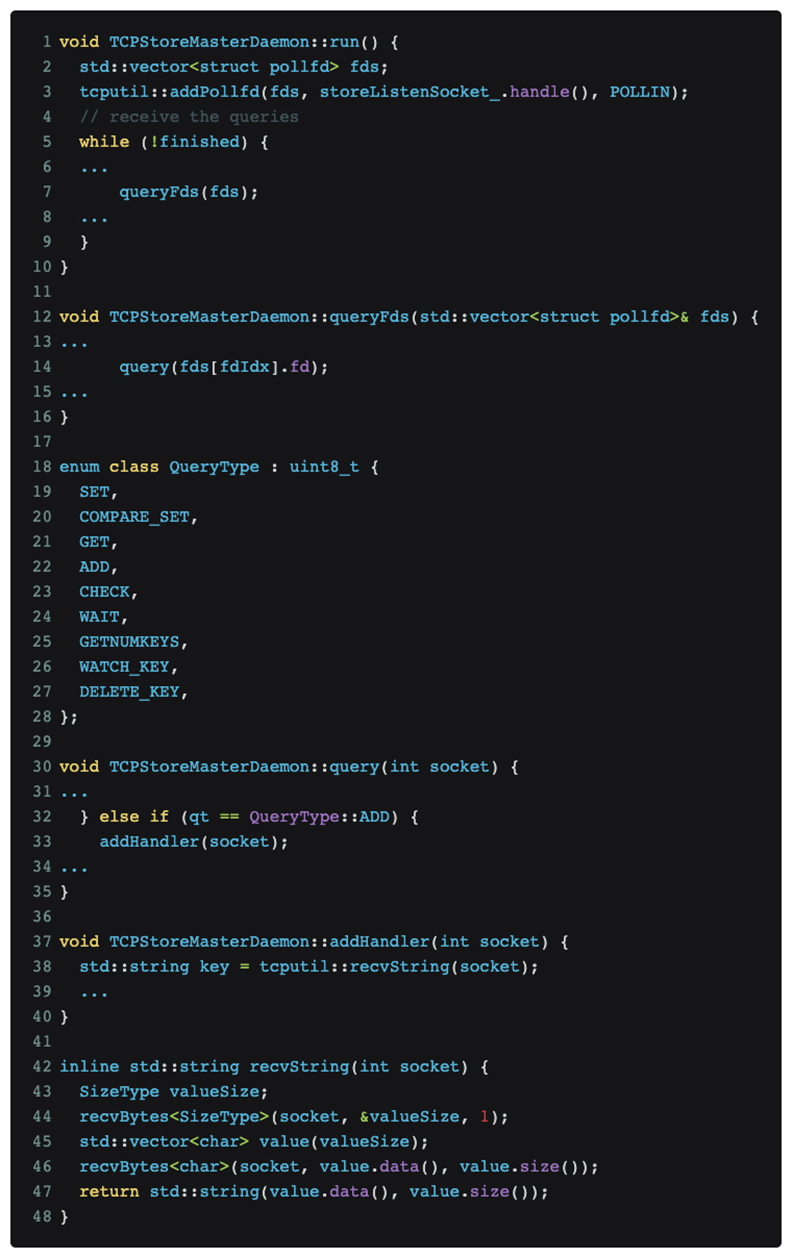
Wie in der Abbildung oben gezeigt, wartet das verteilte Pytorch-Training weiterhin auf Nachrichten am Master-Port.

Der Nmap-Scan [nmap -sS -sV] löste zufällig den Nachrichtentyp QueryType::ADD aus, bei dem es sich um die grüne Boxnummer [03] im Datenteil handelt, der im Bild tcpdump oben gezeigt wird, was dazu führte, dass Pytorch versuchte, den recvString zu verwenden Funktion zum Vorbelegen eines Puffers für den Empfang von Folgenachrichten. Diese Pufferlänge wird jedoch mit einem uint64_t[Little-Endian]-Typ nach [03] analysiert, der die Red-Box-Nummer [e0060b0000] ist, was 962174058496 Bytes entspricht. Dieser Wert bedeutet, dass 1T-Daten und Pytorch empfangen werden Nachdem der Speicherzuweiser den entsprechenden Speicher angefordert hat, fordert der Speicherzuweiser weiterhin die entsprechende physische Seite vom Kernel an. Da unser GPU-Trainingscluster nicht mit einer großen Seitentabelle konfiguriert ist, kann Linux die 1T-Speicheranforderung des Speicherzuweisers in seitenfehlenden Interrupts gemäß der 4K-Granularität nur schrittweise erfüllen, was bedeutet, dass die Zuweisung des gesamten Speichers etwa 1 Minute dauert Das zuvor beobachtete OOM tritt wahrscheinlich als Reaktion auf ein schnelles Gedächtniswachstum von etwa einer Minute auf.
Lösung
Nachdem Ursache und Wirkung bekannt sind, ergibt sich eine natürliche Lösung:
1. Kurzfristig: Ändern Sie die Sicherheitsscan-Richtlinie, um dies zu vermeiden
2. Langfristig: Kommunizieren Sie mit der Community, um die Robustheit [ 1 ]
Zusammenfassen
Nachdem wir die Rückverfolgung des OOM-Problemuntersuchungsprozesses abgeschlossen hatten, stellten wir fest, dass wir während dieses Prozesses tatsächlich eine effektive Testrunde für speicherbezogene Tools und Debugging-Methoden durchgeführt hatten.
Während dieses Prozesses haben wir herausgefunden, dass es einige gemeinsame Punkte gibt, die als Referenz für spätere Forschung und Entwicklung verwendet werden können:
-
Jemalloc kann eine sehr effektive quantitative Analyse von Speicherproblemen bereitstellen und zugrunde liegende speicherbezogene Probleme in hybriden Programmiersystemen wie Python+C erfassen.
-
Memray. Wir hatten während des Debugging-Prozesses hohe Erwartungen daran, aber am Ende stellten wir fest, dass der Bereich, in dem Memray die beste Leistung erbringen kann, immer noch auf der reinen Python-Seite liegt und es nicht für hybride Programmiersysteme wie Pytorch DDP geeignet ist.
Manchmal müssen wir noch über Probleme aus einer größeren Dimension nachdenken. Wenn beispielsweise der Kommunikationsprozess mit externen, unabhängigen Diensten nicht in die Betrachtung einbezogen wird, wird die eigentliche Ursache nicht entdeckt.
Vielleicht möchten Sie es auch sehen

