

Artikelquelle |. ByteDance Intelligent Creation Team
Wir freuen uns, Ihnen unser neuestes Vincentian-Grafikmodell SDXL-Lightning vorzustellen, das eine beispiellose Geschwindigkeit und Qualität erreicht und jetzt der Community zur Verfügung steht.
Modell: https://huggingface.co/ByteDance/SDXL-Lightning
Papier: https://arxiv.org/abs/2402.13929

Blitzschnelle Bilderzeugung
Generative KI erlangt weltweite Aufmerksamkeit aufgrund ihrer Fähigkeit, auf der Grundlage von Texteingaben beeindruckende Bilder und sogar Videos zu erstellen. Aktuelle generative Modelle auf dem neuesten Stand der Technik basieren jedoch auf Diffusion, einem iterativen Prozess, der Rauschen schrittweise in Bildbeispiele umwandelt. Dieser Prozess erfordert enorme Rechenressourcen und ist langsam. Bei der Generierung hochwertiger Bildbeispiele beträgt die Verarbeitungszeit eines einzelnen Bildes etwa 5 Sekunden, was normalerweise mehrere Aufrufe (20 bis 40 Mal) an ein riesiges neuronales Netzwerk erfordert. . Diese Geschwindigkeit schränkt Anwendungsszenarien ein, die eine schnelle Generierung in Echtzeit erfordern. Die Beschleunigung der Generierung bei gleichzeitiger Verbesserung der Qualität ist ein aktuelles Forschungsgebiet und das Kernziel unserer Arbeit.
SDXL-Lightning durchbricht diese Barriere durch eine innovative Technologie – Progressive Adversarial Distillation – um beispiellose Erzeugungsgeschwindigkeiten zu erreichen. Das Modell ist in der Lage, Bilder in extrem hoher Qualität und Auflösung in nur 2 oder 4 Schritten zu erzeugen, wodurch Rechenkosten und -zeit um den Faktor zehn reduziert werden. Unsere Methode kann für zeitüberschreitungsempfindliche Anwendungen sogar Bilder in einem Schritt generieren, allerdings kann die Qualität etwas darunter leiden.
Zusätzlich zu seinem Geschwindigkeitsvorteil liefert SDXL-Lightning auch eine erhebliche Leistung in der Bildqualität und übertrifft bisherige Beschleunigungstechnologien in Bewertungen. Erzielen Sie eine höhere Auflösung und bessere Details bei gleichzeitig guter Diversität und Bild-Text-Übereinstimmung.
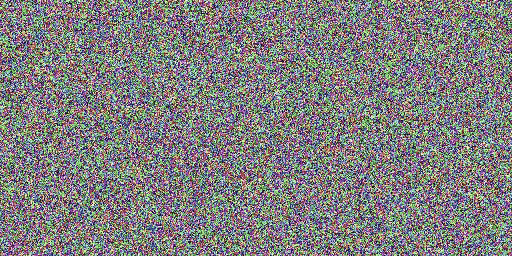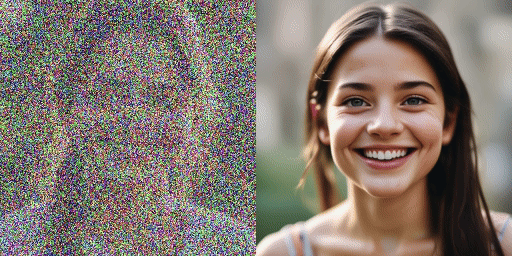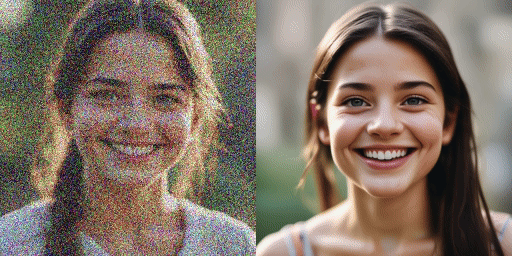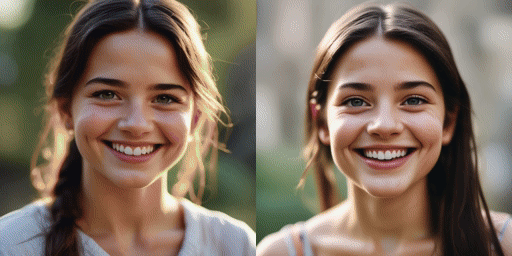 Geschwindigkeitsvergleich
Geschwindigkeitsvergleich
Originalmodell (20 Schritte), unser Modell (2 Schritte)
Modelleffekt
Unser Modell kann Bilder in 1 Schritt, 2 Schritt, 4 Schritt und 8 Schritt erzeugen. Je mehr Inferenzschritte vorhanden sind, desto besser ist die Bildqualität.
Hier sind die Ergebnisse unseres 4-stufigen Prozesses:
Hier sind die Ergebnisse unseres zweistufigen Aufbaus:
Im Vergleich zu früheren Methoden (Turbo und LCM) generiert unsere Methode Bilder, die im Detail deutlich verbessert sind und dem Stil und Layout des ursprünglichen generativen Modells besser entsprechen.

Geben Sie der Gemeinschaft etwas zurück, offenes Modell
Die Open-Source-Welle ist zu einer Schlüsselkraft bei der Förderung der rasanten Entwicklung künstlicher Intelligenz geworden, und ByteDance ist stolz, Teil dieser Welle zu sein. Unser Modell basiert auf SDXL, dem derzeit beliebtesten offenen Modell für die Textgenerierung von Bildern, das bereits über ein florierendes Ökosystem verfügt. Jetzt haben wir beschlossen, SDXL-Lightning für Entwickler, Forscher und kreative Praktiker auf der ganzen Welt zu öffnen, damit sie auf dieses Modell zugreifen und es anwenden können, um Innovation und Zusammenarbeit in der gesamten Branche weiter zu fördern.
Bei der Entwicklung von SDXL-Lightning haben wir die Kompatibilität mit der Open-Model-Community berücksichtigt. Viele Künstler und Entwickler in der Community haben eine Vielzahl stilisierter Bildgenerierungsmodelle erstellt, beispielsweise Cartoon- und Anime-Stile. Um diese Modelle zu unterstützen, bieten wir SDXL-Lightning als Beschleunigungs-Plug-in an, das nahtlos in diese verschiedenen Arten von SDXL-Modellen integriert werden kann, um die Bildgenerierung für verschiedene Modelle zu beschleunigen.
 Unser Modell kann auch mit dem derzeit sehr beliebten Steuerungs-Plug-In ControlNet kombiniert werden, um eine extrem schnelle und kontrollierbare Bilderzeugung zu erreichen.
Unser Modell kann auch mit dem derzeit sehr beliebten Steuerungs-Plug-In ControlNet kombiniert werden, um eine extrem schnelle und kontrollierbare Bilderzeugung zu erreichen.
 Unser Modell unterstützt auch ComfyUI, die derzeit beliebteste Generationssoftware in der Open-Source-Community, und das Modell kann direkt zur Verwendung geladen werden:
Unser Modell unterstützt auch ComfyUI, die derzeit beliebteste Generationssoftware in der Open-Source-Community, und das Modell kann direkt zur Verwendung geladen werden: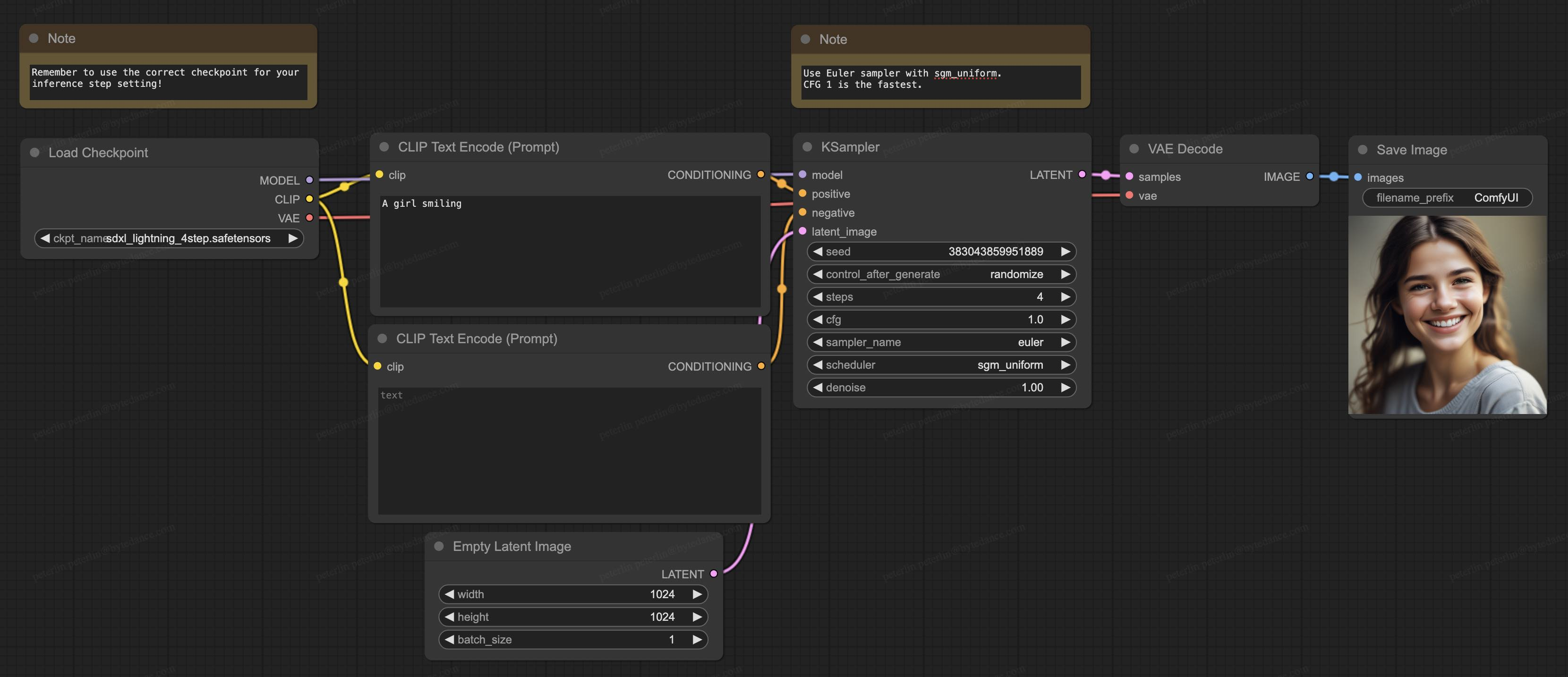
Zu den technischen Details
Theoretisch ist die Bilderzeugung ein schrittweiser Transformationsprozess von Rauschen zu klaren Bildern. Dabei lernt das neuronale Netz die Gradienten an verschiedenen Positionen im Transformationsfluss.
Die spezifischen Schritte zum Generieren eines Bildes sind wie folgt: Zuerst nehmen wir eine Zufallsprobe einer Rauschprobe am Startpunkt des Streams und verwenden dann ein neuronales Netzwerk, um den Gradienten zu berechnen. Basierend auf dem Gradienten an der aktuellen Position nehmen wir kleine Anpassungen an der Probe vor und wiederholen dann den Vorgang. Mit jeder Iteration nähern sich die Proben der endgültigen Bildverteilung an, bis ein klares Bild entsteht.
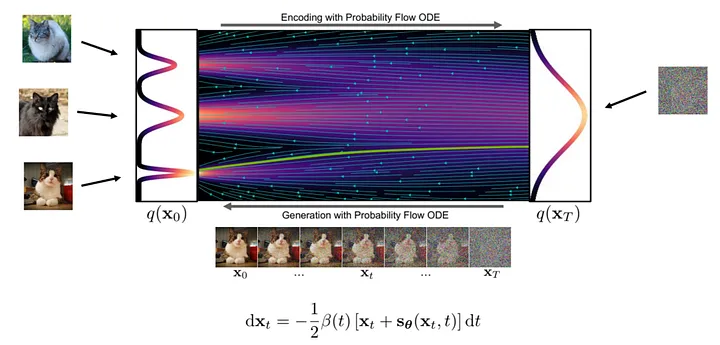 Abbildung: Generierungsprozess ( Bild von : https://arxiv.org/abs/2011.13456 )
Abbildung: Generierungsprozess ( Bild von : https://arxiv.org/abs/2011.13456 )
Da der Generierungsfluss komplex und nichtlinear ist, muss der Generierungsprozess jeweils nur einen kleinen Schritt ausführen, um die Anhäufung von Gradientenfehlern zu reduzieren. Daher sind häufige Berechnungen des neuronalen Netzwerks erforderlich, weshalb der Berechnungsaufwand groß ist.
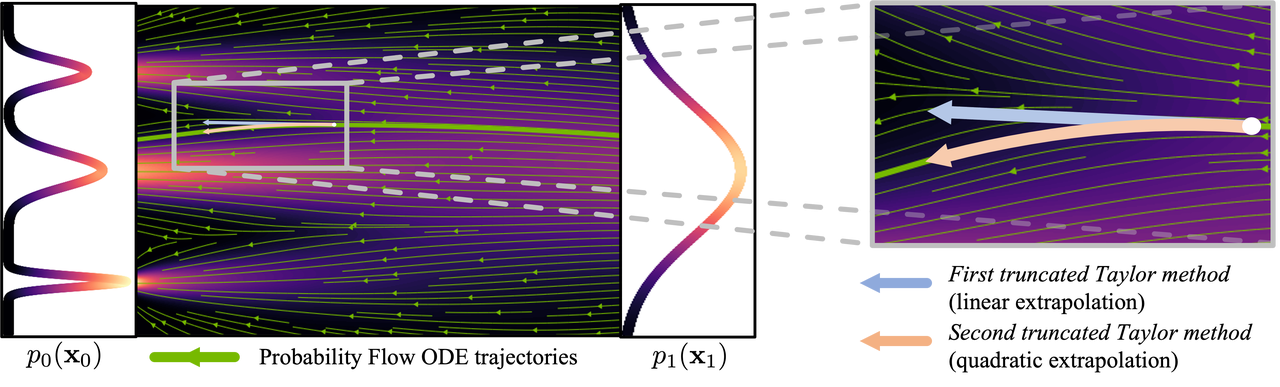 Abbildung: Kurvenprozess ( Bild von : https://arxiv.org/abs/2210.05475 )
Abbildung: Kurvenprozess ( Bild von : https://arxiv.org/abs/2210.05475 )
Um die Anzahl der zur Bilderzeugung erforderlichen Schritte zu reduzieren, wurde viel Forschung darauf verwendet, Lösungen zu finden. Einige Studien schlagen Stichprobenmethoden vor, die Fehler reduzieren, während andere versuchen, den erzeugten Fluss linearer zu gestalten. Trotz der Fortschritte bei diesen Methoden sind immer noch mehr als 10 Inferenzschritte erforderlich, um Bilder zu erzeugen.
Eine weitere Methode ist die Modelldestillation, die in weniger als 10 Inferenzschritten qualitativ hochwertige Bilder erzeugen kann. Anstatt den Gradienten an der aktuellen Fließposition zu berechnen, ändert die Modelldestillation das Ziel der Modellvorhersage, um die nächst weiter entfernte Fließposition direkt vorherzusagen. Konkret trainieren wir ein Schülernetzwerk, um das Ergebnis des Lehrernetzwerks nach Abschluss der mehrstufigen Argumentation direkt vorherzusagen. Eine solche Strategie kann die Anzahl der erforderlichen Inferenzschritte erheblich reduzieren. Durch die wiederholte Anwendung dieses Prozesses können wir die Anzahl der Inferenzschritte weiter reduzieren. Dieser Ansatz wurde in früheren Untersuchungen als progressive Destillation bezeichnet.
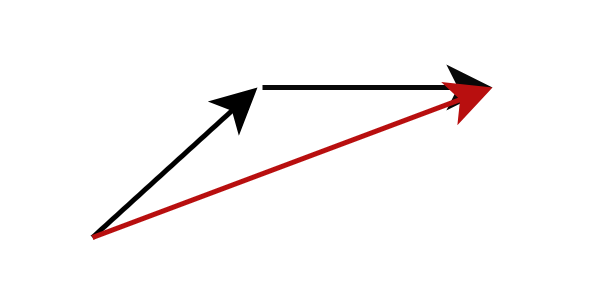 Abbildung: Progressive Destillation : Das Schülernetzwerk sagt das Ergebnis des Lehrernetzwerks nach mehreren Schritten voraus
Abbildung: Progressive Destillation : Das Schülernetzwerk sagt das Ergebnis des Lehrernetzwerks nach mehreren Schritten voraus
In der Praxis haben studentische Netzwerke häufig Schwierigkeiten, zukünftige Strömungspositionen genau vorherzusagen. Der Fehler verstärkt sich mit jedem Schritt, was dazu führt, dass die vom Modell erzeugten Bilder bei weniger als 8 Inferenzschritten unscharf werden.
Um dieses Problem zu lösen, besteht unsere Strategie nicht darin, das Schülernetzwerk zu zwingen, genau mit den Vorhersagen des Lehrernetzwerks übereinzustimmen, sondern das Schülernetzwerk hinsichtlich der Wahrscheinlichkeitsverteilung mit dem Lehrernetzwerk in Einklang zu bringen. Mit anderen Worten: Das Studentennetzwerk ist darauf trainiert, einen probabilistisch möglichen Standort vorherzusagen, und selbst wenn dieser Standort nicht ganz genau ist, bestrafen wir ihn nicht. Dieses Ziel wird durch kontradiktorisches Training erreicht, das ein zusätzliches diskriminierendes Netzwerk einführt, um eine Verteilungsanpassung der Ergebnisse des Schüler- und Lehrernetzwerks zu erreichen.
Dies ist ein kurzer Überblick über unsere Forschungsmethoden. In unserem technischen Artikel ( https://arxiv.org/abs/2402.13929 ) bieten wir eine tiefergehende theoretische Analyse, Trainingsstrategie und spezifische Formulierungsdetails des Modells.
Jenseits von SDXL-Lightning
Obwohl sich diese Studie hauptsächlich mit der Verwendung der SDXL-Lightning-Technologie zur Bilderzeugung befasst, ist das Anwendungspotenzial unserer vorgeschlagenen progressiven kontradiktorischen Destillationsmethode nicht auf statische Bilder beschränkt. Mit dieser innovativen Technologie können auch Video-, Audio- und andere multimodale Inhalte schnell und in hoher Qualität generiert werden. Wir laden Sie herzlich ein, SDXL-Lightning auf der HuggingFace-Plattform zu erleben und freuen uns auf Ihre wertvollen Kommentare und Rückmeldungen.
Modell: https://huggingface.co/ByteDance/SDXL-Lightning
Papier: https://arxiv.org/abs/2402.13929
Fellow Chicken „Open-Source“ -Deepin-IDE und endlich Bootstrapping erreicht! Guter Kerl, Tencent hat Switch wirklich in eine „denkende Lernmaschine“ verwandelt. Tencent Clouds Fehlerüberprüfung und Situationserklärung vom 8. April RustDesk-Remote-Desktop-Startup-Rekonstruktion Web-Client WeChats Open-Source-Terminaldatenbank basierend auf SQLite WCDB leitete ein großes Upgrade ein TIOBE April-Liste: PHP fiel auf ein Allzeittief, Fabrice Bellard, der Vater von FFmpeg, veröffentlichte das Audiokomprimierungstool TSAC , Google veröffentlichte ein großes Codemodell, CodeGemma , wird es dich umbringen? Es ist so gut, dass es Open Source ist – ein Open-Source-Bild- und Poster-Editor-Tool