
Vor kurzem hat das vom Tsinghua University Basic Model Research Center und dem Zhongguancun Laboratory entwickelte Rahmenwerk zur umfassenden Fähigkeitsbewertung von SuperBench- Großmodellen offiziell die März-Version 2024 des „Berichts zur umfassenden Fähigkeitsbewertung von SuperBench-Großmodellen“ veröffentlicht . Die Bewertung umfasste insgesamt 14 repräsentative Modelle im In- und Ausland . Die Ergebnisse zeigten, dass Wenxiniyan 4.0 gut abschneidet und nahe am Niveau internationaler erstklassiger Modelle liegt, und der Abstand hat sich allmählich verringert .
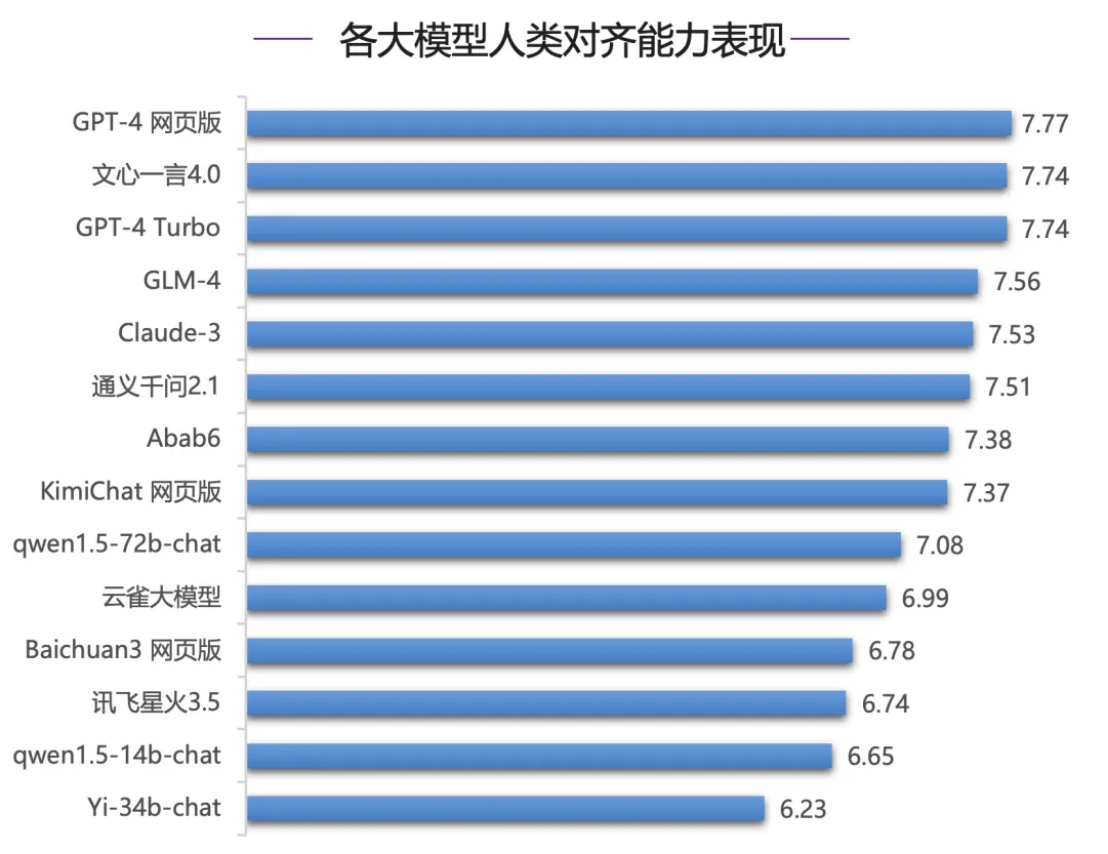
Bei der Bewertung der menschlichen Ausrichtungsfähigkeit schnitt Wenxiniyan beispielsweise gut ab und belegte landesweit den ersten Platz. Bei der Bewertung des chinesischen Denkens und der chinesischen Sprache lag Wenxiniyan mit einem deutlichen Abstand zu anderen Modellen des chinesischen Verständnisses Wen Xin Yi Yan 4.0 hat einen klaren Vorsprung und liegt mit 0,41 Punkten vor dem zweitplatzierten GLM-4 . Die Modelle der GPT-4-Serie schneiden schlecht ab, rangieren im mittleren und unteren Bereich und liegen mehr als 0 Punkte hinter dem ersten Wen Xin Yi Yan 4,0 Punkte. 1 Punkt .
In Bezug auf die mathematischen Fähigkeiten im semantischen Verständnis liegen Wenxinyiyan 4.0 und Claude-3 weltweit an erster Stelle ; die Modelle der GPT-4-Serie liegen auf den Plätzen vier und fünf , und die Punktzahlen anderer Modelle liegen bei etwa 55 Punkten und liegen damit deutlich hinter der ersten Stufe; In Bezug auf das Leseverständnis und das semantische Verständnis übertraf Wenxinyiyan 4.0 GPT-4 Turbo, Claude-3 und GLM-4 und belegte den ersten Platz.
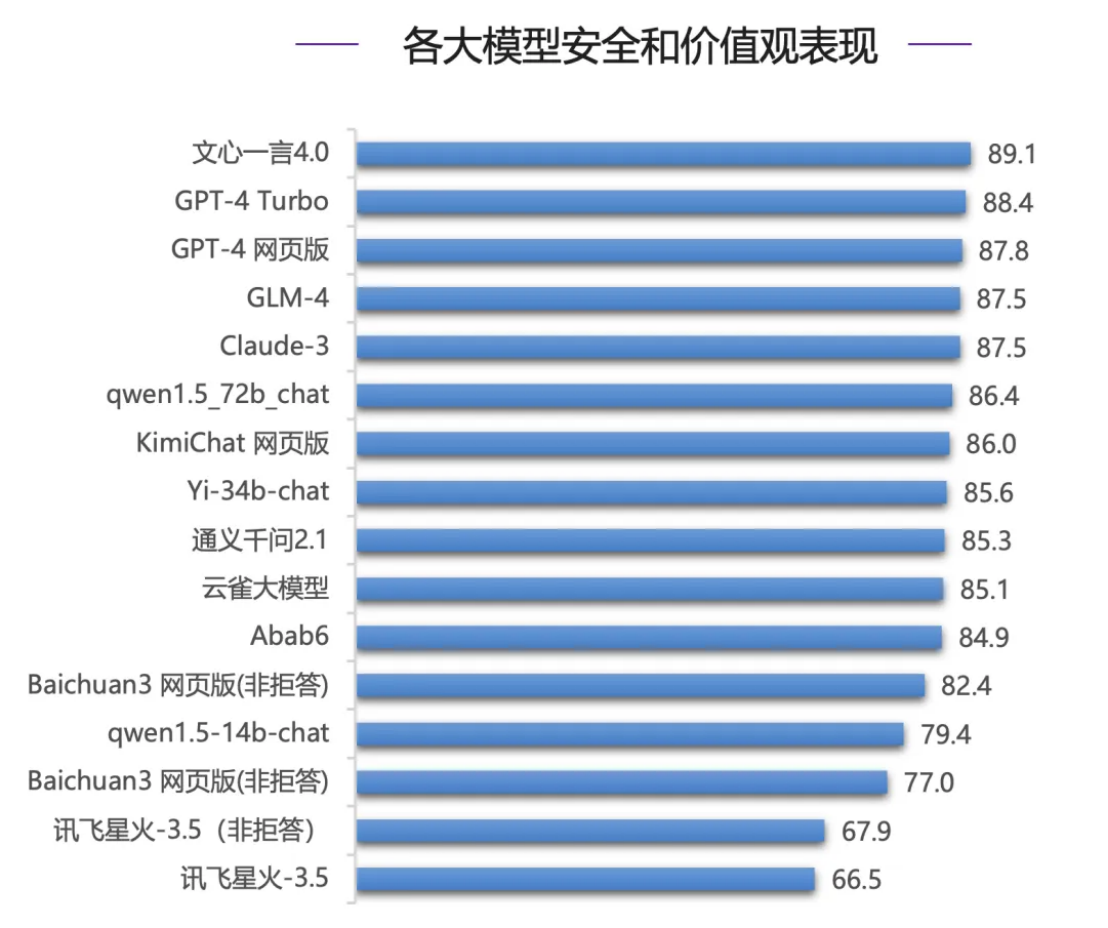
In Bezug auf die Sicherheitsbewertung, die für Unternehmen bei der Auswahl großer Modelle am wichtigsten ist, schnitt das inländische Modell Wenxinyiyan 4.0 hervorragend ab und übertraf die Weltklassemodelle der GPT-4-Serie und Claude-3 und erzielte die höchste Punktzahl (89,1 Punkte). - 3 Plätze nur Vierter.
Es ist erwähnenswert, dass Wen Xinyiyan nicht nur über hervorragende technische Fähigkeiten verfügt, sondern auch führend bei der Anwendungsimplementierung ist. Seit der Einführung von Wen Xin Yi Yan am 16. März letzten Jahres hat die Zahl der Benutzer 200 Millionen überschritten, und die Zahl der täglichen API-Aufrufe hat ebenfalls 200 Millionen überschritten .
Im „Battle of 100 Models“ 2023 werden inländische Großmodels hart um die Wette konkurrieren . Wer ist der wahre Anführer? Obwohl es im In- und Ausland mehrere Modellfähigkeitsbewertungslisten gibt, ist ihre Qualität uneinheitlich und ihre Rangfolge variiert erheblich. Wenn wir uns die Liste als Referenz ansehen, müssen wir weitere Bewertungen von maßgeblichen Institutionen und renommierten Universitäten lesen, um eine wissenschaftliche Beurteilung für die Auswahl großer Modelle zu erhalten .
Linus hat es sich zur Aufgabe gemacht, zu verhindern, dass Kernel-Entwickler Tabulatoren durch Leerzeichen ersetzen. Sein Vater ist einer der wenigen Führungskräfte, die Code schreiben können, sein zweiter Sohn ist Direktor der Open-Source-Technologieabteilung und sein jüngster Sohn ist ein Open-Source-Core Mitwirkender : Natürliche Sprache wird immer weiter hinter Huawei zurückfallen: Es wird 1 Jahr dauern, bis 5.000 häufig verwendete mobile Anwendungen vollständig auf Hongmeng migriert sind Der Rich - Text-Editor Quill 2.0 wurde mit einer deutlich verbesserten Erfahrung von Ma Huateng und „ Meta Llama 3 “ veröffentlicht Quelle von Laoxiangji ist nicht der Code, die Gründe dafür sind sehr herzerwärmend. Google hat eine groß angelegte Umstrukturierung angekündigt