
Auf der gerade vergangenen Frühjahrskonferenz 2024 brachte Kangaroo Cloud eine neue Version der V6.2-Version des Datenstack-Produkts . Unter anderem repräsentiert EasyMR als Schlüsselfunktion im Datenstapel V6.2 das tiefgreifende Verständnis und die kontinuierliche Innovation von Kangaroo Cloud im Big-Data-Ökosystem.
EasyMR (im Folgenden gemeinsam als EMR bezeichnet) ist eine von Kangaroo Cloud entwickelte Elastic-Computing-Engine , die auf Open-Source-Komponenten wie Hadoop, Hive, Spark, Flink und HBase basiert und eine sichere, zuverlässige, elastisch skalierbare und kostengünstige Lösung bietet Datenspeicherung und Computerdienstleistungen . Unter anderem unterstützt die unabhängig entwickelte Big-Data-Betriebs- und Wartungsmanagementplattform EasyManager auf Unternehmensebene die Erstellungs-, Verwaltungs-, Bereitstellungs-, Betriebs-, Wartungs- und Überwachungsfunktionen von Hadoop-Clustern aus einer Hand und bietet eine effiziente Rechenzentrumslösung.
Angesichts der wachsenden Datenverarbeitungs- und Analyseanforderungen von Unternehmen bietet die Version EMR6.2 den Benutzern bessere Betriebs- und Wartungsdienste für große Datenmengen sowie eine Optimierung der Rechenleistung. Im Folgenden finden Sie eine detaillierte Einführung in die Optimierung der vier Hauptfunktionen der EMR6.2-Version, um den Benutzern ein umfassendes Verständnis dieses innovativen Produkts zu ermöglichen.
Komplett erneuerte und aktualisierte Benutzeroberfläche: einfaches und komfortables interaktives Erlebnis
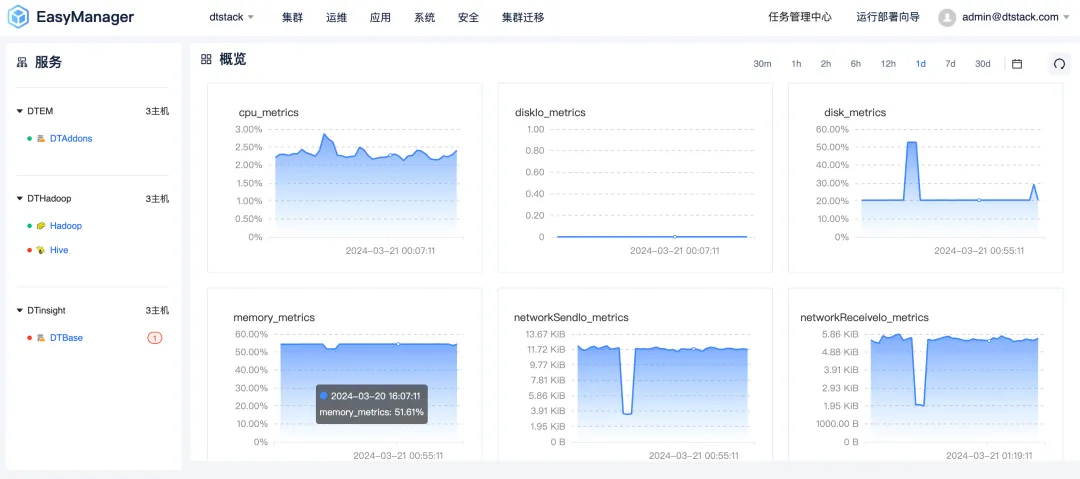
Kangaroo Cloud ist sich der Bedeutung der Benutzererfahrung bewusst und hat daher in der EMR6.2-Version die Benutzeroberfläche umfassend aktualisiert und aktualisiert. Das neue Interface-Design folgt einem einfachen, aber eleganten Stil und zielt darauf ab, Benutzern ein intuitives und komfortables interaktives Erlebnis zu bieten. Unabhängig davon, ob Sie ein Anfänger oder ein erfahrener Benutzer sind, können Sie schnell loslegen und komplexe Big-Data-Cluster problemlos verwalten.
Darüber hinaus haben wir auch die Reaktionsgeschwindigkeit und den Betriebsfluss der Schnittstelle optimiert, um sicherzustellen, dass Benutzer während des Betriebs und der Wartung des Clusters ein reibungsloseres Betriebserlebnis genießen können .
Differenzierte Konfiguration: Erfüllen Sie unterschiedliche Anforderungen
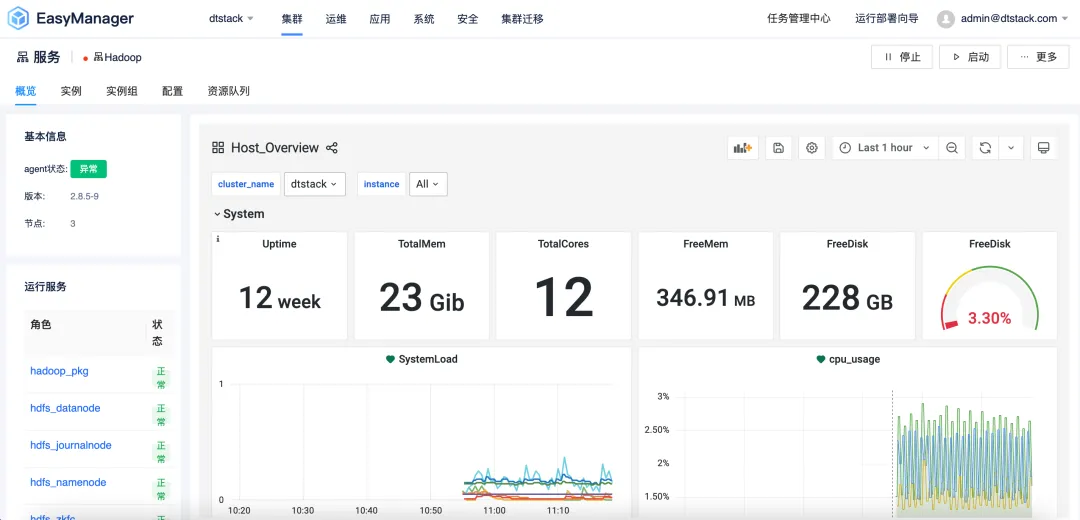
Die EMR6.2-Version führt die instanzgruppendifferenzierte Konfigurationsfunktion ein , mit der Benutzer die Clusterkonfiguration entsprechend ihren spezifischen Anforderungen anpassen können. Benutzer können unabhängige Instanzgruppen aus verschiedenen Knoten im EMR-Cluster erstellen und spezifische Konfigurationsparameter in der Instanzgruppe festlegen, um eine bessere Leistung, Ressourcennutzung und Aufgabenplanung zu erreichen.
Ganz gleich, ob es sich um ein kostenbewusstes Start-up oder ein großes Unternehmen mit höheren Leistungsanforderungen handelt, EMR6.2 bietet flexible Konfigurationsoptionen, um den Anforderungen verschiedener Benutzer gerecht zu werden.
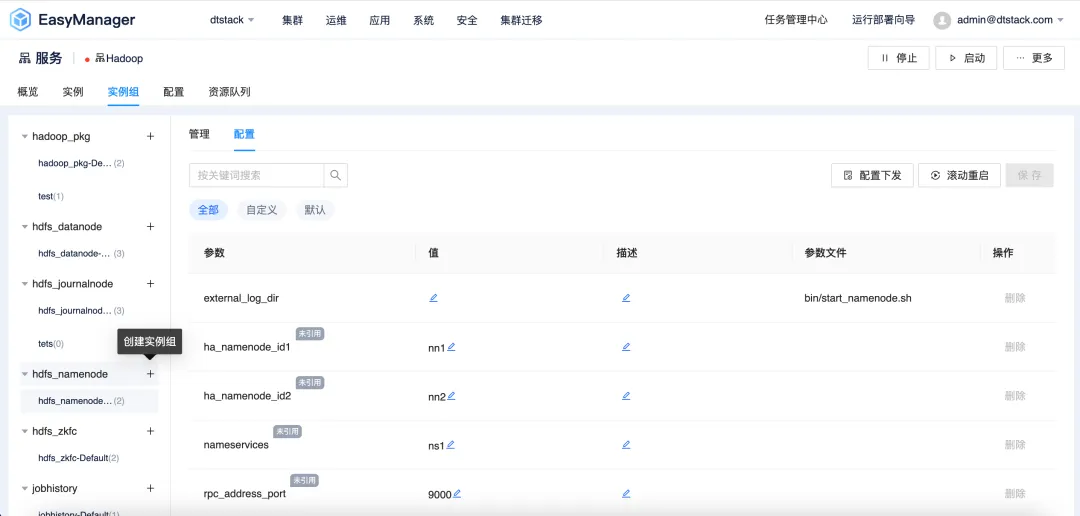
Zu den spezifischen Vorteilen der Implementierung differenzierter Konfigurationsstrategien für Instanzgruppen gehören unter anderem die folgenden:
● Ressourcenzuteilung
Durch eine differenzierte Konfiguration kann eine verfeinerte Ressourcenzuweisung entsprechend den individuellen Anforderungen verschiedener Aufgaben effektiv umgesetzt werden, wobei mehrere Ebenen wie Computer-, Speicher- und Netzwerkressourcen abgedeckt werden. Vermeiden Sie Ressourcenverschwendung und verbessern Sie die Ressourcennutzung, um sicherzustellen, dass alle Aufgaben im Cluster durch geeignete Ressourcen unterstützt werden.
●Optimierung der Aufgabenplanung
Für verschiedene Arten von Aufgaben oder Jobs können je nach ihren Merkmalen unterschiedliche Konfigurationsparameter festgelegt werden, um die Aufgabenplanung und Ausführungseffizienz zu optimieren.
● Fehlertoleranz und Stabilität
Durch differenzierte Konfiguration können die Fehlertoleranz und Stabilität des Clusters verbessert werden. Abhängig von der Wichtigkeit und Auslastung des Knotens oder der Instanzgruppe können unterschiedliche Fehlertoleranzmechanismen und Fehlerbehandlungsstrategien festgelegt werden, um sicherzustellen, dass der Cluster auch bei abnormalen Situationen einen stabilen Betrieb aufrechterhalten kann.
● Kostenmanagement
Eine differenzierte Konfiguration kann auch dabei helfen, die Kosten zu verwalten. Je nach Geschäftsanforderungen und Budgetbeschränkungen können verschiedene Instanzgruppen im Cluster sinnvoll konfiguriert werden, um Ressourcenverschwendung zu vermeiden, Betriebs- und Wartungskosten zu senken und ein Gleichgewicht zwischen Leistung und Kosten zu finden.
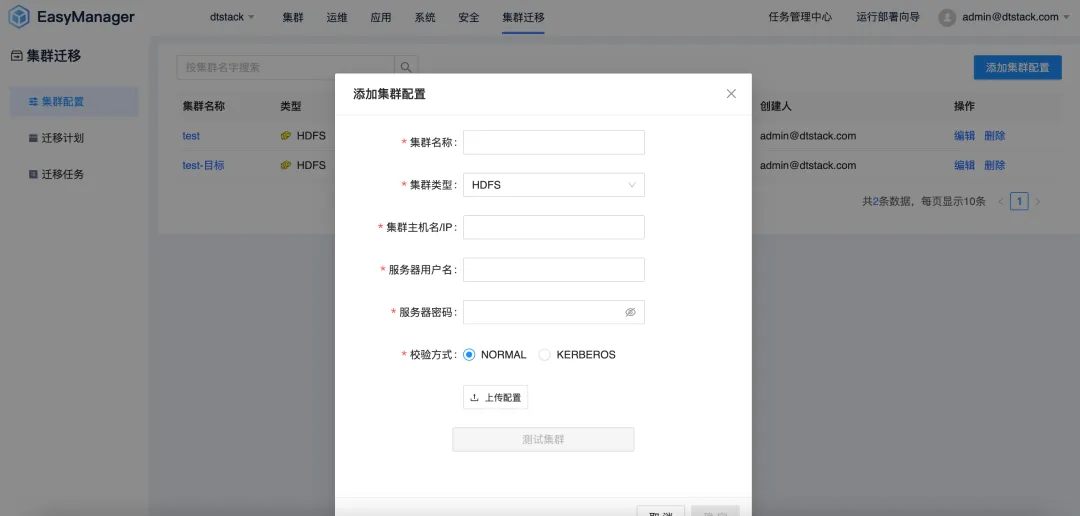
Clustermigration: nahtloser Übergang ohne Betriebsunterbrechung
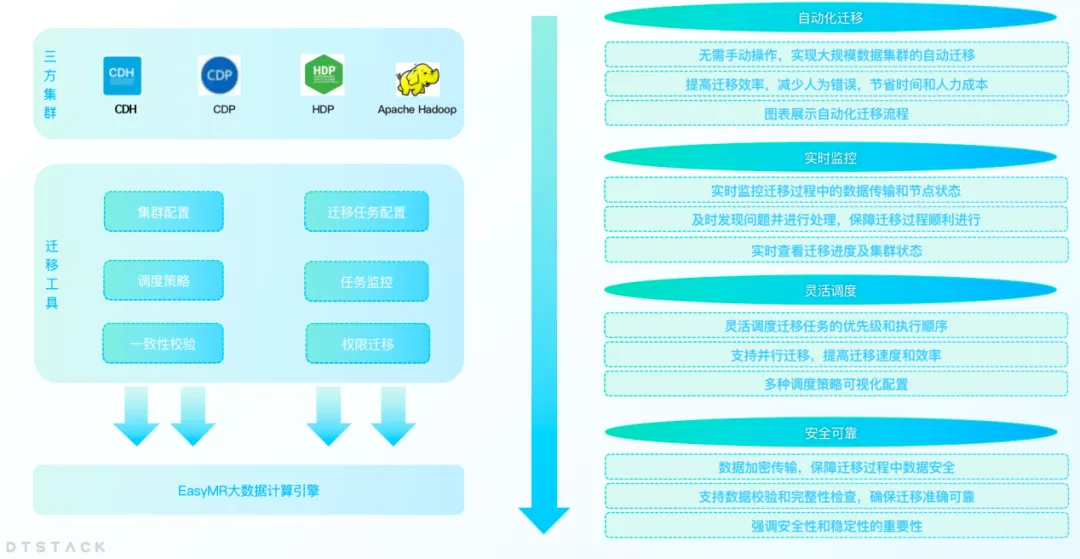
Mit der Weiterentwicklung des Geschäfts eines Unternehmens führt die wachsende Datenmenge häufig zu Problemen wie unzureichender Rechenzentrumskapazität oder Rechenzentrumsänderungen. Unternehmen müssen Daten von einem Rechenzentrum in ein anderes migrieren. Gleichzeitig migrieren im Zuge der Lokalisierungsablösung immer mehr Unternehmen Nicht-Innovationsplattformen wie CDH, HDP und CDP auf lokalisierte Big-Data-Plattformen. Aus diesem Grund hat EMR eine Big-Data-Cluster-Migrationsfunktion eingeführt, um Unternehmen bei der effizienten Durchführung der Rechenzentrumsmigration zu unterstützen.
Mit der Cluster-Migrationsfunktion können Benutzer ihre Big-Data-Cluster nahtlos zwischen verschiedenen Rechenzentren oder Cloud-Diensten migrieren, ohne sich Gedanken über Datenverlust oder Geschäftsunterbrechungen machen zu müssen. Durch diese Funktion können Unternehmen ihre IT-Infrastruktur flexibler anpassen, um sich an veränderte Marktanforderungen anzupassen.
Motor-Upgrade enthüllt: Leistungssprung, neues Erlebnis
Das Aufregendste ist, dass die EMR6.2-Version einen großen Durchbruch bei der Leistung der Computer-Engine erzielt hat. Wir haben nicht nur die vorhandenen Spark- und Flink-Computing-Engines optimiert, sondern auch neue Algorithmen und Technologien eingeführt, um die Datenverarbeitungsgeschwindigkeit und die Recheneffizienz zu verbessern. Dies bedeutet, dass Benutzer komplexere Datenanalyseaufgaben in kürzerer Zeit erledigen können, wodurch der Entscheidungsprozess beschleunigt und die Wettbewerbsfähigkeit des Unternehmens verbessert wird.
● Spark3 unterstützt die Z-Order-Indexoptimierung
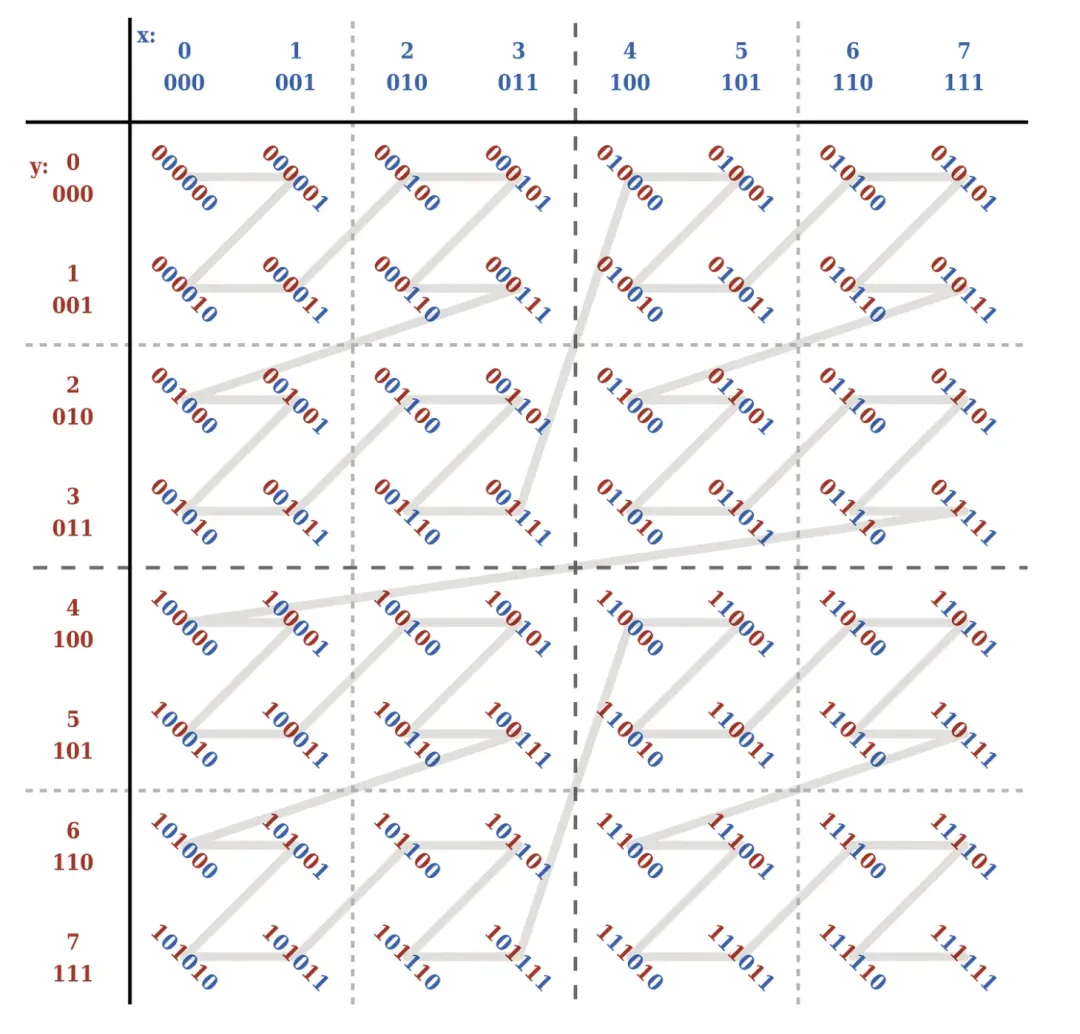
Z-Order ist eine Technologie, die mehrdimensionale Daten in eine Dimension komprimieren kann. Für ein Datenelement können wir seine mehreren zu sortierenden Felder als mehrere Dimensionen der Daten betrachten. Z-Order kann bestimmte Regeln übergeben eindimensionale Daten.
Insbesondere wird der Z-Wert durch bestimmte Regeln erstellt . Der Z-Wert kann als die oben erwähnten eindimensionalen Daten verstanden werden. Zu diesem Zeitpunkt können wir basierend auf den eindimensionalen Daten sortieren. Wie nachfolgend dargestellt:
In Spark SQL hat Kangaroo Cloud die Syntax OPTIMIZE XX ZORDER BY hinzugefügt , um den Z-Order-Index zu unterstützen und so die Z-Order-Indexoptimierung von INSERT INTO-Tabellen, INSERT OVERWRITE-Tabellen, CREATE TABLE-Tabellen AS SELECT, DISTINCT und anderen SQL-Anweisungen zu realisieren.
Spark3 unterstützt die Optimierung der Z-Reihenfolge, was die Effizienz der Datenverarbeitung und -abfrage erheblich verbessert, den E/A-Overhead reduziert und die Jobausführung beschleunigt. Insbesondere in Szenarien, in denen große Datensätze und komplexe Abfragevorgänge verarbeitet werden müssen, kann die Optimierung der Z-Reihenfolge eine wichtige Rolle spielen. Bei der Lösung des Problems der Dateikomprimierungsrate ist die Dateikomprimierungsrate nach Verwendung der Z-Reihenfolge-Optimierung im Vergleich zur manuellen Optimierung um fast 20 % und im Vergleich zur ursprünglichen Aufgabe von Spark3 um fast das Zehnfache gestiegen Bei dieser Aufgabe ist die Leistung ebenfalls um fast 30 % gestiegen und hat die Leistung und Effizienz des Offline-Betriebs erheblich verbessert.
● Flink-Hot-Update für auftragsbezogene Aufgaben
Im tatsächlichen Produktionsbetrieb kommt es häufig zu Echtzeit-Änderungen von Aufgabenparametern oder zur Optimierung von Bedienern und Funktionen. Normalerweise kann zunächst nur die aktuelle Aufgabe abgebrochen werden, und dann wird CheckPoint zum Wiederherstellen oder erneuten Ausführen ausgewählt Warten Sie, was sehr schwierig ist. Eine große Zeitverschwendung für die Aufgabenentwicklung.
Um das durch Aufgabenaktualisierungen im herkömmlichen Pro-Job-Modus verursachte Problem der Dienstunterbrechung zu lösen, die Aufgabenstabilität und Systemverfügbarkeit zu verbessern und die Anforderungen an Geschäftskontinuität und Hochverfügbarkeit in der Produktionsumgebung zu erfüllen. Das Kangaroo Cloud Engine-Team hat relevante Untersuchungen und Verbesserungen des Quellcodes durchgeführt und den Hot-Neustart von Aufgaben im asynchronen Rückruf des Aufgabenabbruchs pro Job optimiert :
① Stellen Sie zunächst fest, ob derzeit ein neuer JobGraph-Cache vorhanden ist. Geben Sie die Hot-Restart-Logik ein.
② Rufen Sie die CheckPoint-Informationen der abgebrochenen Aufgabe ab und geben Sie sie in den neuen JobGraph ein
③Aktualisieren Sie JobGrap auf JobMaster und löschen Sie die Cache-Informationen von JobGraph
④Löschen Sie die von SloyPool verwalteten Ressourcen in JobMaster
⑤JobMaster erstellt ScheduleNg neu und plant seine Ausführung. Dadurch wird ein neuer JobGraph-Planungslauf gestartet.
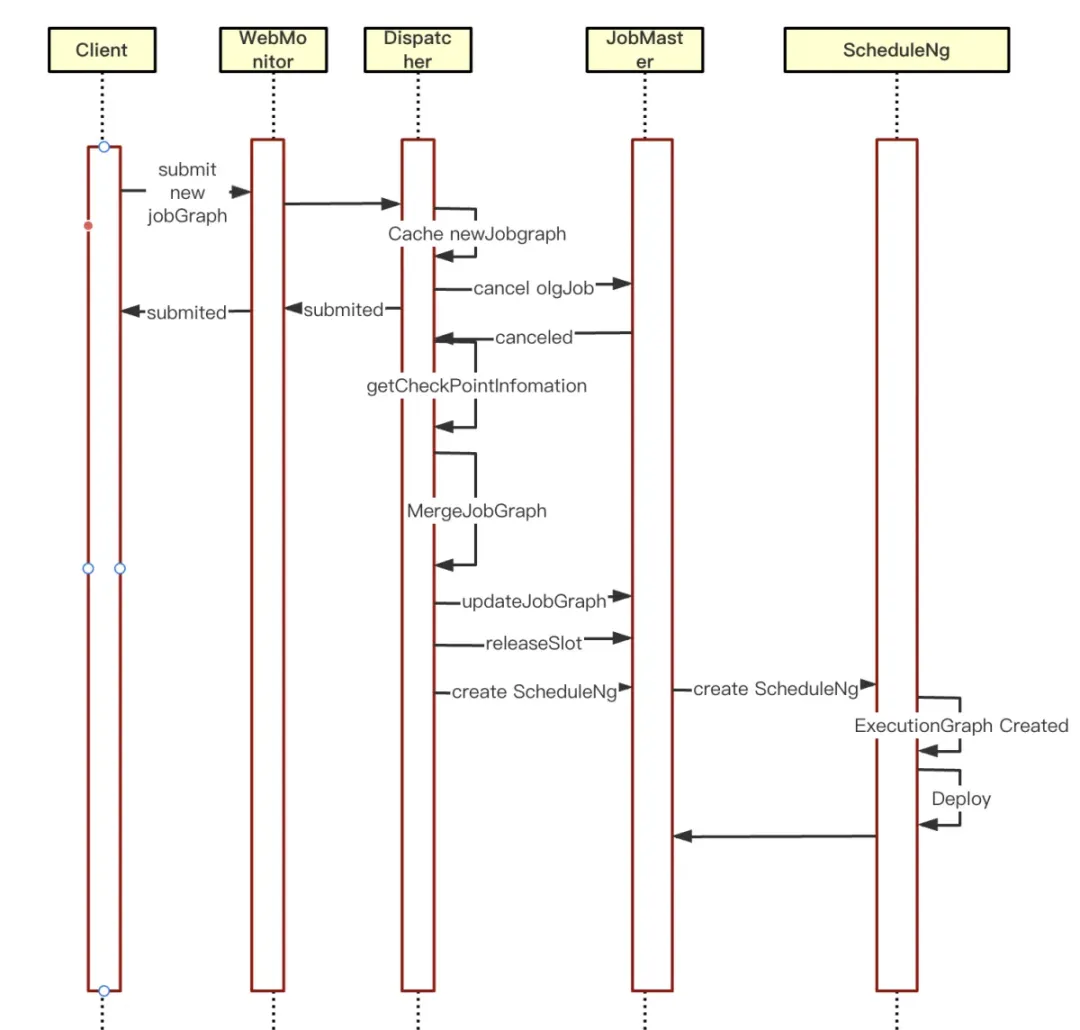
Die Hot-Update-Optimierung pro Jobaufgabe von Flink verbessert die Entwicklungseffizienz erheblich, reduziert Ausfallzeiten und verbessert die Anwendungsflexibilität und -zuverlässigkeit. Für Echtzeitanwendungen, die eine schnelle Iteration und dynamische Anpassung erfordern, bietet es das ultimative Effizienzerlebnis.
Verbesserte Entwicklungseffizienz: Entwickler können Code schnell testen und iterieren, ohne den mühsamen Stopp- und Neustartprozess durchlaufen zu müssen, was die Entwicklungszyklen beschleunigt und häufigere Veröffentlichungen ermöglicht
· Ausfallzeiten reduzieren: Hot-Updates können Ausfallzeiten von Anwendungen minimieren und dadurch die Serviceverfügbarkeit erhöhen, was besonders wichtig für geschäftskritische und Echtzeitanwendungen ist.
· Parameter dynamisch anpassen: Jobkonfigurationsparameter wie Parallelität oder Bedienerparameter können dynamisch angepasst werden, ohne den Job neu zu starten, was flexible Anpassungen basierend auf Echtzeit-Datenfluss oder Lastbedingungen ermöglicht.
● Andere Funktionsentwicklung
Darüber hinaus haben wir auf der Engine-Seite auch Funktionen wie Spark Ranger Docking , Spark Materialized View Optimization und Flink Session Mode Class Loading Isolation entwickelt , um die Rechenleistung der Engine zu verbessern und gleichzeitig die Aufgabensicherheit und Skalierbarkeit der Engine zu verbessern.
Zusammenfassen
Zusammenfassend stellt die Veröffentlichung von EMR6.2 einen weiteren wichtigen Meilenstein für Kangaroo Cloud im Bereich Big-Data-Dienste dar. Durch die Optimierung von vier Hauptfunktionen, einschließlich umfassender Aktualisierung und Aktualisierung der Benutzeroberfläche, differenzierter Konfiguration, Cluster-Migration und Engine-Upgrade, bietet EMR6.2 Benutzern eine leistungsstärkere, flexiblere und effizientere Big-Data-Computing-Engine-Plattform und unterstützt Unternehmen bei der Datenverwaltung und A qualitativer Sprung in der Analyse.
Downloadadresse „Industry Indicator System White Paper“: https://www.dtstack.com/resources/1057?src=szsm
Download-Adresse „Dutstack Product White Paper“: https://www.dtstack.com/resources/1004?src=szsm
Downloadadresse „Data Governance Industry Practice White Paper“: https://www.dtstack.com/resources/1001?src=szsm
Wenn Sie mehr über Big-Data-Produkte, Branchenlösungen und Kundenbeispiele erfahren oder sich beraten lassen möchten, besuchen Sie die offizielle Website von Kangaroo Cloud: https://www.dtstack.com/?src=szkyzg
Linus hat es sich zur Aufgabe gemacht, zu verhindern, dass Kernel-Entwickler Tabulatoren durch Leerzeichen ersetzen. Sein Vater ist einer der wenigen Führungskräfte, die Code schreiben können, sein zweiter Sohn ist Direktor der Open-Source-Technologieabteilung und sein jüngster Sohn ist ein Open-Source-Core Mitwirkender : Natürliche Sprache wird immer weiter hinter Huawei zurückfallen: Es wird 1 Jahr dauern, bis 5.000 häufig verwendete mobile Anwendungen vollständig auf Hongmeng migriert sind Der Rich - Text-Editor Quill 2.0 wurde mit einer deutlich verbesserten Erfahrung von Ma Huateng und „ Meta Llama 3 “ veröffentlicht Quelle von Laoxiangji ist nicht der Code, die Gründe dafür sind sehr herzerwärmend. Google hat eine groß angelegte Umstrukturierung angekündigt