
Es bestehen umfangreiche Anforderungen an die Risikokontrolle in Aspekten wie dem Kreditzugang und der Transaktionsvermarktung von Finanzgeschäftsprodukten. Da die Geschäftsarten zunehmen, sind herkömmliche Expertenregeln und Scorecard-Modelle nicht mehr in der Lage, immer komplexere Risikokontrollszenarien zu bewältigen.
Im Kontext der traditionellen Risikokontrolle, bei der Expertenregelsysteme die Hauptanwendung sind, werden die Eingabegewohnheiten von Regelmodellen als „Variablen“ bezeichnet. Die auf Expertenregeln basierende Risikobewertung weist die Merkmale auf, dass es schwierig ist, die Auslöseschwelle der Regel zu quantifizieren, und dass es einen Engpass bei der Verbesserung der Genauigkeit von Regeltreffern gibt.
Mit der technischen Implementierung von Algorithmen für maschinelles Lernen und neuronale Netze werden immer mehr „Merkmale“ verwendet , um auf die Eingabeparameter zu verweisen, die dem Algorithmusmodell bereitgestellt werden . Insbesondere dienen „Features“ als Ausgabeparameter der Upstream-Fremdschnittstelle während ihres Ausgabeprozesses und als Eingabeparameter des Downstream-Regelmodells während des anwendungsseitigen Eingabeprozesses.
Bauhintergrund
Zu den Datenquellen für Merkmalsvariablen gehören grundlegende Kundeninformationen, Finanzstatus, Konsumverhalten und Diagramme für soziale Netzwerke usw., die in verschiedene Risikokontrollmodelle eingegeben werden , um den Kreditstatus und das Risikoniveau des Kreditnehmers widerzuspiegeln Datenbasis für Risikokontrollmaßnahmen.
In Finanzinstituten wie Banken und Versicherungen kommt es aufgrund der Komplexität der Organisationsstruktur von Risikogeschäftsquellen zwangsläufig zu einer schlotartigen Entwicklung charakteristischer Variablen zwischen verschiedenen Sparten. Der Datenbedarf von Strategiemodellierern ist häufig auf ein bestimmtes Maß beschränkt Das Produkt wurde entwickelt und bereitgestellt, hat jedoch keinen einheitlichen Verwaltungs- und Freigabeplattformmechanismus gebildet, was zu Abweichungen in der Konsistenz der Datennutzung und Richtlinienerstellung zwischen Unternehmen führt.
Daher ist es notwendig, die Abstraktion des Risikogeschäftsdatenprozesses weiter zu produktivisieren, um die Ableitung, Speicherung, den Aufruf und die Überwachung charakteristischer Variablen zu standardisieren, und es ist auch eine einheitliche Plattform für charakteristische Variablen zur Risikokontrolle entstanden.
Schmerzpunktanalyse
Im Entwicklungsszenario für Risikokontrollaufgaben ruft die Modellaufgabe Zahlen aus der vorab entwickelten Variablenspeichertabelle ab. In der tatsächlichen Entwicklung gibt es häufig geschäftliche und entwicklungsbezogene Schwachstellen, wie z. B. eine hohe Schwelle für die Entwicklung und Bereitstellung von Features, Schwierigkeiten beim Extrahieren komplexer Features, inkonsistente Feature-Anwendungskaliber und inkonsistente Feature-Verarbeitungsprozesse.
01 Der Schwellenwert für die Entwicklung von Echtzeit-Feature-Variablen ist hoch
Der Technologie-Stack geschäftsbezogener Strategiemodellierer basiert hauptsächlich auf Python- und SQL-Funktionen. Für die Flink-Entwicklung auf Basis der Java-Semantik fallen neben der Modellschulung und -bereitstellung auch Echtzeitfunktionen an Die Verarbeitungsmöglichkeiten sind unzureichend.
02 Es ist schwierig, komplexe Merkmalsvariablen zu extrahieren
Die Rückgabenachrichten einiger externer Datenquellenschnittstellen weisen viele verschachtelte Ebenen auf, die Position der Parameter ist verwirrend, die Schnittstelle ist schwer zu erhalten und es fehlt eine einheitliche Plattformverwaltung und -wartung für extrahierte Funktionen.
03 Der Anwendungskaliber von Feature-Variablen ist inkonsistent
Beim Erstellen eines Risikokontrollmodells gelten für die Modellaufgaben dieselben Anforderungen an Funktionsvariablen. Es gibt jedoch Situationen, in denen die Feature-Engineering-Verarbeitung für dieselben Originaldaten in verschiedenen Teams oder Projekten wiederholt wird, was zu einer Konsistenz und Genauigkeit der entsprechenden SQL führt Die Funktionsvariablenlogik wurde geändert.
04 Es ist schwierig, den Verarbeitungsprozess für Merkmalsvariablen zu vereinheitlichen
Den Anforderungen für neue Feature-Variablen auf der Downstream-Strategie- und Modellseite fehlt ein konsistenter und standardisierter Verarbeitungspfad, was zu einer verwirrenden Benennung der eingehenden und ausgehenden Parameter in der entsprechenden Variablentabelle führt. Wenn die neuen Felder hinzugefügt werden, kann die Upstream-Tabelle nicht gelesen werden Das ursprüngliche SQL führt zu komplexeren verschachtelten Join-Operationen. Bei der Konfiguration abgeleiteter Features und Variablensätze sind Aufgabenumfang und Ressourcennutzung oft schwer zu kontrollieren.
Risikokontrollcharakteristik-Variablen-Systembauplan
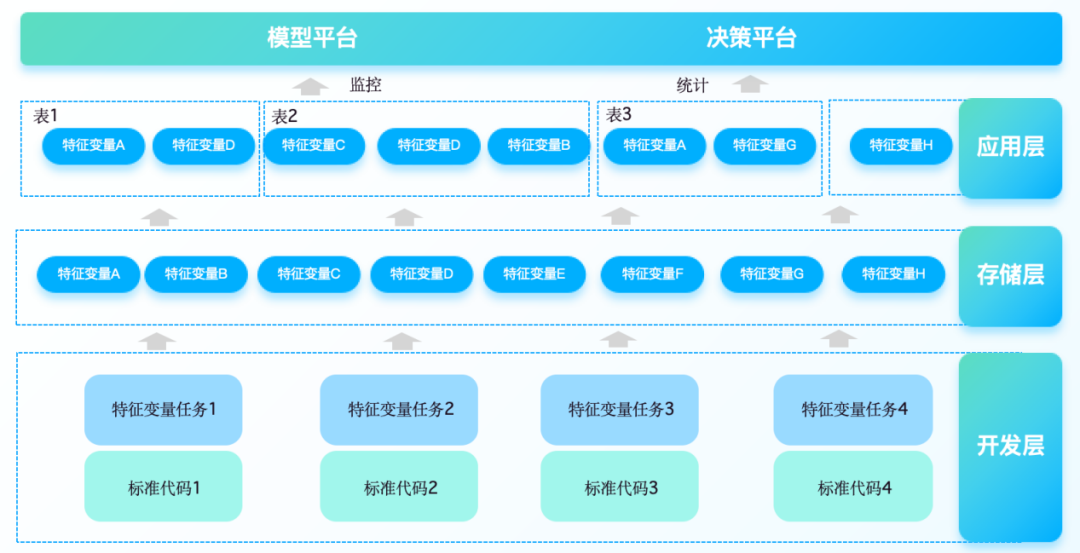
Der Aufbau eines Risikokontroll-Merkmalsvariablensystems konzentriert sich auf die Echtzeit-Risikoerkennung sowie -prävention und -kontrolle von Finanzinstituten . Durch Batch-Extraktion, Aggregation und abgeleitete Verarbeitung heterogener Daten aus mehreren Quellen entsteht eine einheitliche Plattform für Merkmalsvariablen, die standardisiert und leicht zu erweitern ist wird ausgefällt , um den Datenzugriff, die Generierung von Merkmalsvariablen und einen durchgängigen geschlossenen Regelkreis zu realisieren, der Daten für das nachgelagerte Modelltraining und die Entscheidungsausführung bereitstellt und so die Reaktionsgeschwindigkeit und Entscheidungsgenauigkeit bei Risikoereignissen verbessert.
01 Technische Möglichkeiten
Risikokontrollunternehmen stehen häufig vor Anforderungen an die Datenverarbeitung in Echtzeit . Bei Kundentransaktionen, Kreditgenehmigungen und anderen Szenarien kann Stream Computing Kundenbonitätsbewertungen, Limitkontrollen und andere Risikoinformationen in Echtzeit aktualisieren und so Funktionen zur systemübergreifenden Risikoerkennung in Echtzeit bereitstellen für nachgelagerte Entscheidungsprozesse.
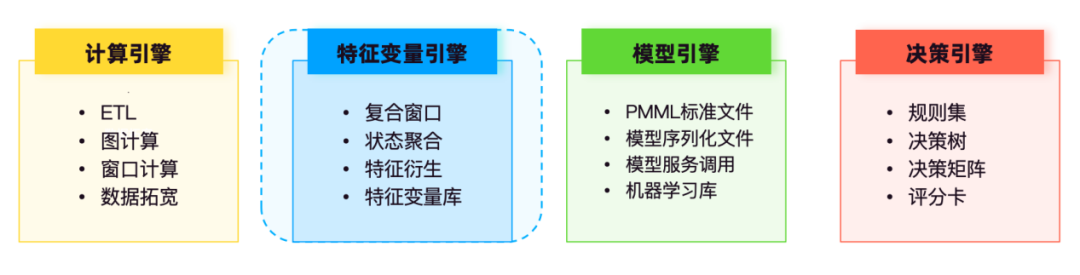
In der Systemarchitektur der Echtzeit-Risikokontrolltechnologie umfasst das Computing Batch-Computing, Stream-Computing und Graph-Computing. Am Beispiel von Stream-Computing-Funktionen bietet Flink zugrunde liegende Echtzeit-Feature-Computing-Funktionen, die hauptsächlich für Daten-ETL und Wide Table verwendet werden Verarbeitung und Fensterverarbeitung. Durch Vorberechnung, Zustandsaggregationsberechnung und andere Funktionen wird die Verarbeitung von Original-Feature-Variablen, Standard-Feature-Variablen und abgeleiteten Feature-Variablen realisiert , um Feature-Unterstützung bereitzustellen Entscheidungsmodelle.
Die Modell-Engine ist hauptsächlich für die Speicherung und Verwaltung verschiedener trainierter Modelle verantwortlich, z. B. Kreditbewertungsmodelle, Betrugserkennungsmodelle , Abwanderungswarnungsmodelle usw.
Die Entscheidungsmaschine verwaltet zentral Richtlinienmodelle wie Regelsätze, Entscheidungsbäume, Entscheidungsmatrizen und Scorecards. Der Regelsatz ruft den Funktionsvariablendienst und den Modelldienst der Modellmaschine auf, um an der logischen Operation des Entscheidungsflusses teilzunehmen.
Basierend auf heterogenen Datenquellen führt die Feature-Variable-Engine die Datenextraktion, -verarbeitung und -berechnung sowie eine standardisierte Verwaltung und Wartung durch und ermöglicht Self-Service-Abfragen durch Risikokontrollpersonal, wodurch der Abruf von Geschäftsdaten und die Datenanalyse bequemer und standardisiert werden.
02 Datenquelle
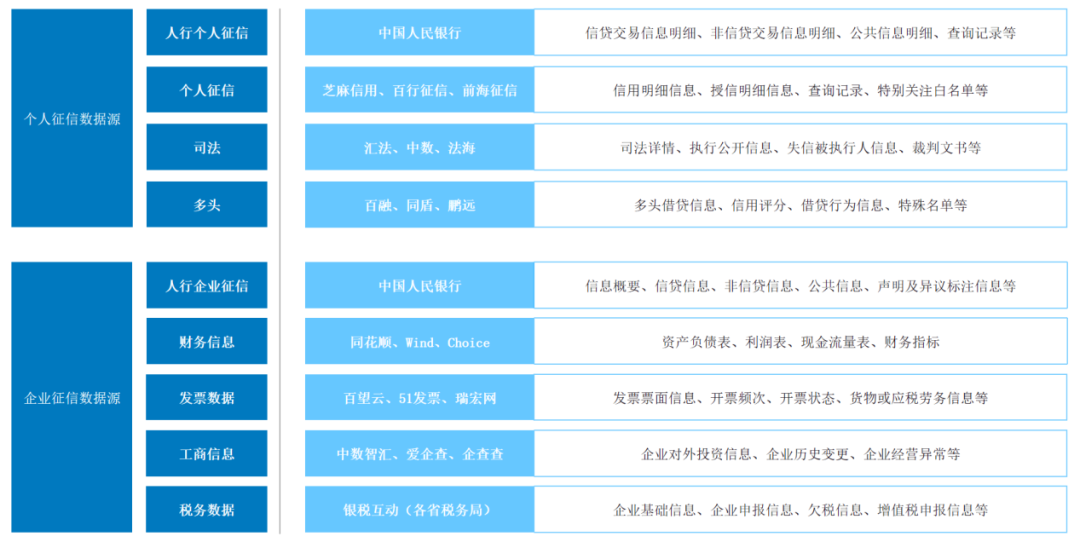
Am Beispiel der Kreditgeschäftsdatenquelle kann diese je nach Kreditinstitut in der Regel in „To C“-Privatkredite und „To B“-Unternehmenskredite unterteilt werden. Bei tatsächlichen Geschäftsüberprüfungen analysieren Kundenbetreuer in der Regel die Machbarkeit von Kundenkrediten anhand von zwei Indikatoren: Cashflow-Niveau und Schuldenstand.
Im Privatkreditszenario kann der Cashflow der Kunden in Einkommensströme aus Sozialversicherungszahlungen, Banken und Zahlungsplattformen Dritter unterteilt werden. Die Haftungshöhe ergibt sich hauptsächlich aus der Kreditauskunft der People's Bank of China, die alle von Finanzinstituten unter dem Namen einer Person vergebenen Kredite, Finanzprodukte mit Risikorisiken und externe Garantieinformationen abdeckt. Zusätzlich zu den Kreditauskunftsdaten der People's Bank of China Zu den Quellen gehören andere lizenzierte Kreditauskünfte Dritter, wie z. B. Baihang Credit Information, Pudao Credit Information und Qiantang Credit Information.
Im Unternehmenskreditszenario konzentrieren sich die Risikoquellen von Klein- und Mikro-Inklusivkrediten auf den eigentlichen Controller. Zusätzlich zum persönlichen Fluss des eigentlichen Controllers wird gleichzeitig der Cashflow-Level aus dem Firmenkontofluss und zusätzlich der Haftungslevel erfasst Zugriff auf den Unternehmenskreditbericht der People's Bank of China. Bei der Kreditvergabe an mittlere und große Unternehmen sowie bei branchenspezifischen Krediten ist es schwierig, das Risikoverhalten der wichtigsten Unternehmen direkt auf der Grundlage von Kreditsteuerdaten zu messen. Anders als bei integrativen Krediten für Klein- und Kleinstunternehmen ist eine weitere Offline-Due-Diligence erforderlich mit dem Bestand des Unternehmens vor Ort und den Betriebsbedingungen der angeschlossenen Unternehmen zu kombinieren.
Für die beiden oben genannten Arten von Kreditgeschäften erfasst die Merkmalsverarbeitung häufig die folgenden mehrdimensionalen Datenquellen:
03 Datenverarbeitung
Für Datenquellen in verschiedenen Risikokontrollszenarien werden variable Verarbeitungsmethoden verwendet, die Batch-, Stream-, Vorberechnungs- und andere Modi integrieren, um eine agile Entwicklung der Geschäftsanforderungen sowie eine Kontrolle der Speicher- und Berechnungskosten zu erreichen.
Batch-Computing: Bei großen historischen Datensätzen wird die Batch- Verarbeitung zur Verarbeitung von Merkmalsvariablen verwendet. Probleme wie fehlende Werte und Ausreißer in den Daten werden mithilfe von Methoden wie Interpolation und Glättung verarbeitet, um die Datenqualität sicherzustellen.
Stream-Computing: Für Echtzeit-Datenströme wird der Stream-Verarbeitungsmodus für die Verarbeitung von Merkmalsvariablen verwendet. Durch die Echtzeit-Stream-Verarbeitungstechnologie wird eine Echtzeitanalyse von Daten realisiert, um den Echtzeitanforderungen von Risikokontrollszenarien gerecht zu werden. Gleichzeitig wird eine ereignisgesteuerte Architektur eingeführt, um die Effizienz und Flexibilität der Datenverarbeitung sicherzustellen.
Vorberechnung: Berechnen und speichern Sie Feature-Variablen für Geschäftssystemdaten entsprechend ihrer Änderungshäufigkeit vor, wodurch die Kosten für die Flussberechnung effektiv gesenkt und die Effizienz des Entscheidungssystems beim Abrufen von Daten aus der Feature-Engine verbessert werden können.
04 Plattformbau
Insbesondere muss die Plattform für charakteristische Variablen Daten aus mehreren Quellen wie Kreditauskunftssystemen, Datenquellen von Drittanbietern und internen Unternehmenssystemen integrieren und eine abgeleitete Verarbeitung von Batch-Funktionen durchführen, um die Eingabeanforderungen von Risikokontrollmodellen zu unterstützen verschiedene Geschäftsszenarien. Unterstützt konfigurierbare, geschäftsorientierte Low-Code-Verarbeitungsmethoden für Feature-Variablen unterschiedlicher Komplexität. Daher umfasst der Aufbau einer Feature-Variablen-Plattform normalerweise die folgenden Aspekte:
1. Extraktion und Generierung von Merkmalsvariablen, automatisierte Datenbereinigung und Vorverarbeitung, Umwandlung von Rohdaten in Merkmale, die für die Modellierung verwendet werden können. Bietet ein Canvas + komponentenbasiertes One-Stop-WEB-IDE-Modell zur Verbesserung der Entwicklungseffizienz und unterstützt benutzerdefinierte oder systemintegrierte Funktionsberechnungslogik.
2. Speicherung und Verwaltung von Funktionsvariablen
Basierend auf einem verteilten Speichermechanismus speichert es umfangreiche historische und charakteristische Echtzeitdaten. Implementieren Sie die Feature-Versionskontrolle, zeichnen Sie den Änderungsverlauf der Feature-Berechnungslogik auf und stellen Sie sicher, dass das Modelltraining auf eine bestimmte Datenversion zurückgeführt werden kann.
3. Servitisierung charakteristischer Variablen
Bietet eine Feature-Service-Schnittstelle zur Bereitstellung von Echtzeit- oder Batch-Feature-Abfragediensten für verschiedene Modelltrainings-, Vorhersage- und Entscheidungs-Engines. Über die Ausgabekomponente können Sie schnell eine Verbindung zu nachgelagerten Regel-Engines, Echtzeit-Data-Warehouses und Nachrichtenwarteschlangen herstellen, um die Leistungsanforderungen für geringe Latenz und hohen gleichzeitigen Zugriff in komplexen Geschäftsszenarien zu erfüllen.
4. Erforschung und Analyse charakteristischer Variablen
Bietet eine Fülle statistischer Analysetools , die Analysten helfen, die Verteilung von Merkmalsvariablen, Korrelationsbeziehungen usw. schnell zu verstehen. Die visuelle Benutzeroberfläche zeigt die Wichtigkeit, den Einfluss und andere Indikatoren von Features an, um die Feature-Auswahl und -Iteration zu unterstützen.
5. Integration mit internen und externen Systemen
Integrieren Sie mehrere Datenquellen wie interne Handelssysteme, CRM-Systeme und ERP-Systeme von Finanzinstituten. Unterstützt die Verbindung mit anderen Risikokontrollkomponenten (wie Regel-Engines, Modellbibliotheken usw.) und externen Datendienstanbietern wie externen Kreditauskunfteien.
05 Baueinkommen
Bei der Umsetzung des Kundenmerkmalsvariablenprojekts einer Bank erfüllt die Plattform die Verarbeitungs- und Derivateverwaltungsanforderungen von Merkmalsvariablen in Kreditszenarien vor der Kreditvergabe und verbindet sich mit diversifizierten vorgelagerten Datenquellen, wie externen Betreibern, Industrie- und Handelsdaten sowie Justizdaten ; und die internen Kundenausrüstungsinformationen, Kontotransaktionsinformationen und vor der Kreditvergabe erfassten Limitberechnungsdaten. Durch Funktionen zur Berechnung von Merkmalsvariablen in Echtzeit kann es auf nachgelagerte Modelle wie Scorecards angewendet werden, um Daten bereitzustellen.
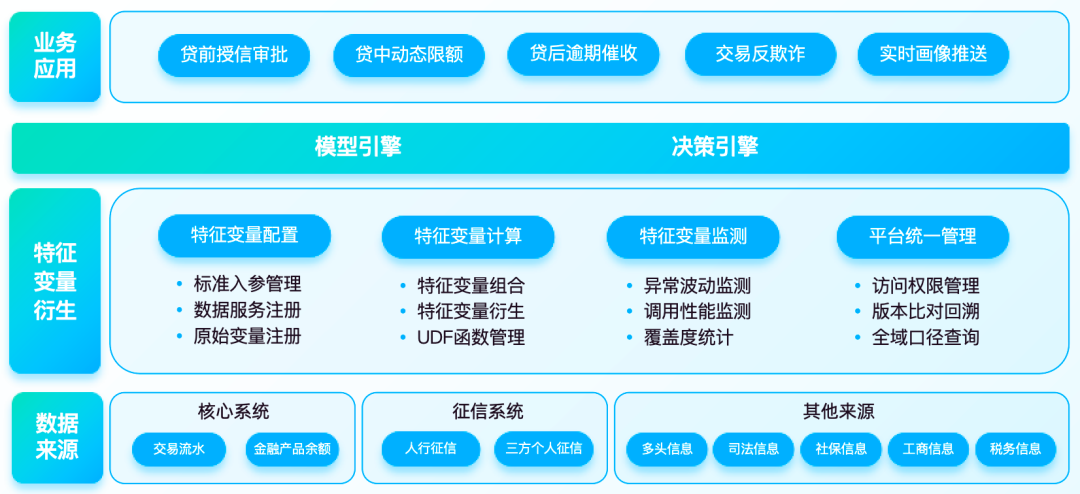
1. Komponentenbasierte Extraktion von Merkmalsvariablen
Die Plattform analysiert Feature-Variablen stapelweise aus SQL-Befehlen. Für die Datenerfassungsanforderungen von Modellaufgaben können Benutzer die erforderlichen Feature-Variablen auf der Plattform frei verarbeiten und kombinieren und zum Lesen und Verarbeiten in die entsprechende Themen-Hive-Tabelle schreiben.
2. Synchrone Aktualisierung von Feature-Variablensätzen
Die Seite unterstützt das Hinzufügen, Löschen und Bearbeiten von Feature-Variablensätzen und Plattformtabellenstrukturoperationen werden automatisch mit der physischen Modelltabelle synchronisiert. Wenn sich die Logik von Feature-Variablen ändert, müssen Sie nur den entsprechenden Standard-Feature-Variablen-Ableitungscode oder die ursprüngliche Feature-Variablen-Standardisierungsoperation bearbeiten, um die komplexe Entwicklung großer SQL-Funktionen zu vermeiden.
3. Stabilitäts- und Anomalieüberwachung
Die von der Plattform bereitgestellte Überwachungs-Dashboard-Funktion unterstützt die Überwachung der Schwankung charakteristischer Variablen und den Aufruf von Variablensätzen. Die Überwachung charakteristischer Variablenwerte stellt sicher, dass die nachgelagerten Aufgaben rechtzeitig gestoppt werden, wenn die Upstream-Daten abnormal sind Maximierung der Möglichkeit, Probleme zu vermeiden, die durch übermäßige Unterschiede in den charakteristischen Variablen verursacht werden, wenn das Modell verwendet wird. Statistiken zum Aufrufstatus jedes Variablensatzes und Echtzeit- Push von Basisalarmen sowie Informationen zur Überprüfung starker und schwacher Regeln.
4. Einheitliche Plattformverwaltung und -kontrolle
Die Plattform bietet Mitgliederverwaltung, Genehmigungscenter, Anrufanalyse, automatische Archivierung, Aufgabenneustart und andere Verwaltungs- und Kontrollmethoden, unterstützt die Anpassung der Aufgabenpriorität und plant Aufgabenvorgänge einheitlich, um die Datendienstleistung und die Clusterressourcennutzung zu verbessern.
Die Plattform wurde online bereitgestellt und deckt und unterstützt mehr als 30 Kreditszenarien für Verbraucherkredite, Klein- und Mikrokredite und andere Unternehmen. Durch die Kombination mit der nachgeschalteten Regelmodell-Engine realisiert die Plattform für charakteristische Variablen die Implementierung von Echtzeit-Entscheidungsfunktionen in Risikokontrollszenarien, was dem Bedarf gerecht wird, das Kundenerlebnis der Benutzer und die Krediteffizienz bei der Beantragung von Kreditkarten und der Kreditgenehmigung zu verbessern Prozesse in Kreditszenarien vor der Kreditvergabe. Darüber hinaus werden Daten für den Post-Kredit-Einzug, die Betrugsbekämpfung bei Transaktionen und andere Szenarien bereitgestellt und unterstützen nachgelagerte Systeme bei der Überwachung des ungewöhnlichen Transaktionsverhaltens der Benutzer in Echtzeit sowie bei der Identifizierung von Identitäten zur Bekämpfung von Geldwäsche , und drücken Sie Echtzeitalarme.
Download-Adresse „Dutstack Product White Paper“: https://www.dtstack.com/resources/1004?src=szsm
Downloadadresse „Data Governance Industry Practice White Paper“: https://www.dtstack.com/resources/1001?src=szsm
Wenn Sie mehr über Big-Data-Produkte, Branchenlösungen und Kundenbeispiele erfahren oder sich beraten lassen möchten, besuchen Sie die offizielle Website von Kangaroo Cloud: https://www.dtstack.com/?src=szkyzg
Linus hat es sich zur Aufgabe gemacht, zu verhindern, dass Kernel-Entwickler Tabulatoren durch Leerzeichen ersetzen. Sein Vater ist einer der wenigen Führungskräfte, die Code schreiben können, sein zweiter Sohn ist Direktor der Open-Source-Technologieabteilung und sein jüngster Sohn ist ein Open-Source-Core Mitwirkender : Natürliche Sprache wird immer weiter hinter Huawei zurückfallen: Es wird 1 Jahr dauern, bis 5.000 häufig verwendete mobile Anwendungen vollständig auf Hongmeng migriert sind Der Rich - Text-Editor Quill 2.0 wurde mit einer deutlich verbesserten Erfahrung von Ma Huateng und „ Meta Llama 3 “ veröffentlicht Quelle von Laoxiangji ist nicht der Code, die Gründe dafür sind sehr herzerwärmend. Google hat eine groß angelegte Umstrukturierung angekündigt