
Sowohl Alibaba Cloud als auch Tencent Cloud haben Situationen erlebt, in denen alle Verfügbarkeitszonen aufgrund eines Komponentenausfalls gleichzeitig lahmgelegt waren. In diesem Artikel wird untersucht, wie die Fehlerdomäne aus Sicht des Architekturdesigns reduziert und Geschäftsverluste minimiert werden können, wenn Fehler auftreten. Außerdem wird die Stabilitätspraxis von Sealos als Beispiel für den Erfahrungs- und Lehrenaustausch herangezogen.
Geben Sie Master-Slave auf und nutzen Sie die Peer-to-Peer-Architektur
Aus dem Tencent Cloud-Fehlerbericht geht hervor, dass der gleichzeitige Ausfall mehrerer Verfügbarkeitszonen im Wesentlichen durch einige zentralisierte Komponenten wie eine einheitliche API, eine einheitliche Authentifizierung und andere Systemfehler verursacht wird.
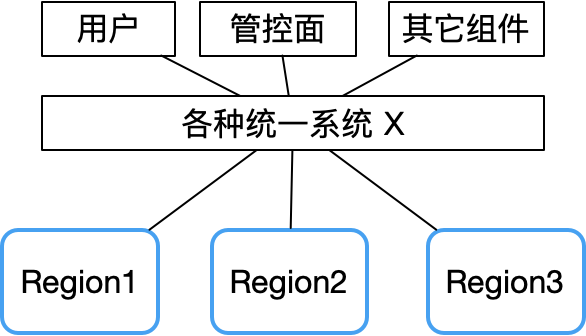
Daher ist die Fehlerdomäne sehr groß, sobald das X-System ausfällt.
Im Gegensatz dazu kann eine dezentrale Peer-to-Peer-Architektur dieses Risiko gut vermeiden. Nehmen wir als Beispiel das Bitcoin-Netzwerk. Da es keinen zentralen Knoten gibt, ist seine Stabilität viel höher als die eines herkömmlichen Master-Slave-Clusters und es ist fast schwierig, ihn aufzuhängen.
Daher hat Sealos die Lehren von Alibaba Cloud und Tencent Cloud vollständig übernommen und eine eigentümerlose Architektur übernommen. Das Hauptproblem besteht darin, wie Daten wie Benutzerkonten in mehreren Verfügbarkeitszonen gespeichert werden Problem. Es entstand eine Struktur wie diese:
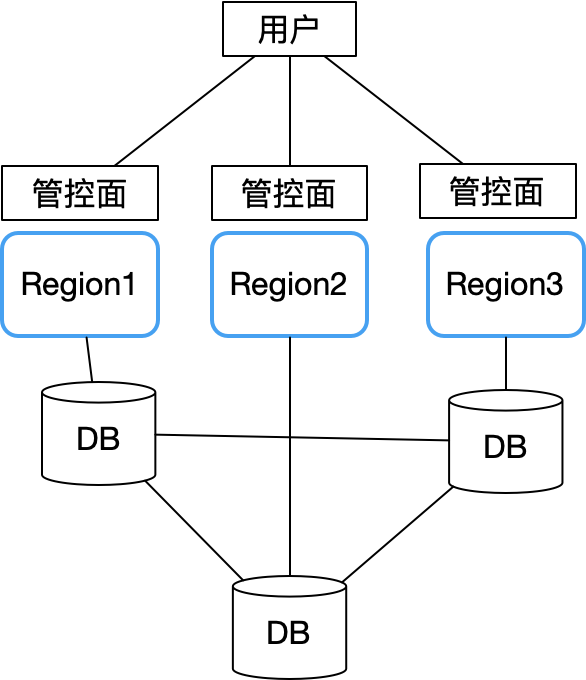
Jede Verfügbarkeitszone ist völlig autonom und synchronisiert nur wichtige gemeinsame Daten (z. B. Benutzerkontoinformationen) über eine überregionale verteilte Datenbank (wir verwenden CockroachDB). Jede Verfügbarkeitszone ist mit dem lokalen Knoten der verteilten Datenbank CockroachDB verbunden.
Auf diese Weise hat ein Ausfall in einer einzelnen Availability Zone keine Auswirkungen auf die Geschäftskontinuität in anderen Regionen. Erst wenn im verteilten Datenbankcluster ein Gesamtproblem auftritt, ist die Steuerungsebene aller Verfügbarkeitszonen nicht mehr verfügbar. Glücklicherweise verfügt CockroachDB selbst über eine hervorragende Leistung in Bezug auf Fehlertoleranz, Notfallwiederherstellung und Reaktion auf Netzwerkpartitionen, was die Wahrscheinlichkeit, dass diese Situation eintritt, erheblich verringert. Auf diese Weise ist die Gesamtarchitektur einfach. Konzentrieren Sie sich einfach auf die Verbesserung der Stabilität der Datenbank, die Überwachung und destruktive Tests.
Ein weiterer Vorteil besteht darin, dass es eine bequeme Graustufenfreigabe und differenzierte Vorgänge bietet. Beispielsweise können neue Funktionen zunächst mit geringem Datenverkehr in einigen Bereichen überprüft und dann nach der Stabilisierung vollständig eingeführt werden. In verschiedenen Bereichen können auch maßgeschneiderte Dienste basierend auf den Merkmalen der Kundengruppen bereitgestellt werden, ohne dass eine vollständige Konsistenz erforderlich ist.
Es gibt kein absolut stabiles System
Alle beschweren sich viel über die Stabilität der Cloud, aber ausnahmslos alle Cloud-Anbieter haben auch schon viele Ausfälle erlebt. Das Wichtigste dabei ist, wie die Konvergenz gelingen kann Managementfragen sind auch eine Kostenfrage, die ich Ihnen anhand konkreter Beispiele aus dem unternehmerischen Prozess erläutern werde.
Sealos Lehren aus Misserfolgen
Großer Laf-Ausfall am 17. März 2023
Dies war der erste große Misserfolg, den wir erlebten, als wir ein Unternehmen gründeten, nur zwei Tage nach der Einführung des Produkts. Der Grund, warum wir uns so genau an diese Zeit erinnern, ist, dass es sich um die Feierlichkeiten zum ersten Firmenjubiläum handelte , und wir hatten nicht einmal Zeit, den Kuchen anzuschneiden. Es dauerte bis etwa drei Uhr nachts.
Die letzte Ursache für den Fehler war sehr seltsam. Die kostengünstige Netzwerkvirtualisierung von Containern auf Lightweight-Servern führte letztendlich zu einem Paketverlust, sodass der gesamte Cluster auf einen normalen VPC-Server migriert wurde war stabil. Geschlecht und Kosten sind untrennbar miteinander verbunden.
Daher denken viele Leute, dass die öffentliche Cloud teuer ist. In vielen Fällen kostet es ein Vielfaches, die verbleibenden 10 % der Probleme zu lösen.
Laf stieß daraufhin auf eine Reihe datenbankbezogener Stabilitätsprobleme, da es ein Modell verwendete, bei dem mehrere Mandanten eine MongoDB-Bibliothek gemeinsam nutzten . Die endgültige Schlussfolgerung war, dass dieser Weg nicht funktionieren würde und es für uns schwierig war, die Datenbankisolation zu lösen Problem, also haben jetzt alle die unabhängige Datenbankmethode übernommen und das Problem wurde endlich gelöst.
Es gibt auch das Stabilitätsproblem des Gateways. Wir haben uns zunächst für einen unzuverlässigen Ingress-Controller entschieden , den ich nicht nennen werde. Schließlich haben wir ihn durch Higress ersetzt, der das Problem derzeit nicht vollständig gelöst hat Es beansprucht weniger Ressourcen und ist stabiler. Ich bin dem Alibaba Higress-Team auch sehr dankbar für die persönliche Unterstützung. Die von uns aufgedeckten Probleme haben Higress auch dabei geholfen, reifer zu werden, eine Win-Win-Situation.
Im Juni 2023 wurde unsere öffentliche Sealos-Cloud offiziell gestartet. Eines der größten Probleme, mit denen wir konfrontiert waren, war der Angriff auf CC-Angriffe mit großem Datenverkehr, der jedoch auch einen Kostenanstieg bedeutet Die beiden sind sehr verwirrend. Wenn Sie die Stabilität nicht verhindern, können Sie die Kosten nicht durch den Verkauf decken. Später, nachdem wir das Gateway ausgetauscht hatten, stellten wir fest, dass Envoy wirklich leistungsfähig war und dem Angriffsverkehr tatsächlich widerstehen konnte. Davor verwendeten wir Nginx, das alles aus einer Hand bot. Das Tolle an K8s ist außerdem seine starke Selbstheilungsfähigkeit. Selbst wenn das Gateway ausfällt, kann es sich innerhalb von 5 Minuten selbst reparieren, solange es nicht gleichzeitig ausfällt.
Best Practices für Stabilitätskonvergenz
Fehlerbehebungsprozess
Um die Systemstabilität kontinuierlich zu verbessern, hat Sealos intern einen strengen Fehlermanagementprozess etabliert:
Jeder auftretende Fehler muss detailliert erfasst und kontinuierlich nachverfolgt werden. Viele Unternehmen beenden den Prozess der Fehlerüberprüfung, aber eigentlich ist die Überprüfung nicht der Zweck. Der Schlüssel besteht darin, praktische Korrekturmaßnahmen zu formulieren und diese umzusetzen, um die Wiederholung ähnlicher Fehler vollständig zu verhindern. Nachdem die Fehlerbehandlung abgeschlossen ist, müssen Sie sie noch eine Zeit lang weiter beobachten, bis bestätigt wird, dass das Problem nicht mehr auftritt.
Hinsichtlich der Managementziele haben wir das Ziel der Stabilität und Konvergenz im OKR Q1 2024 zunächst wie folgt definiert:

Später stellte ich fest, dass diese allgemeine OKR im Slogan-Stil unzuverlässig war und die Konvergenz der Stabilität konkreter sein musste. Das Ergebnis dieser KR war, dass wir sie nicht erreichen konnten und sie fast keine Wirkung hatte. Im Konvergenzprozess müssen Sie sich nicht jedes Quartal vollständig auf einige Kernpunkte konzentrieren und einige Quartale lang iterieren, dann wird die Konvergenz sehr gut sein.
Deshalb haben wir uns im zweiten Quartal konkretere Ziele gesetzt:

Die Festlegung der Stabilität darf sich nicht auf die Festlegung eines Indikators beschränken und darf auch nicht zu allgemein sein. Sie erfordert konkrete und sichtbare Maßnahmen und spezifische Messmethoden.
Wenn beispielsweise 99,9 % festgelegt sind, wie kann dies erreicht werden? Wie ist also die aktuelle Verfügbarkeit? Was sind die Kernthemen? Wie misst man? Was getan werden muss? Wer wird es tun? Die Einstellungen sind nicht auf die verfügbare Zeit beschränkt, sondern sollten detailliert aufgeführt werden, wie z. B. Fehlerstufe, Anzahl der Fehler, Fehlerdauer, große Kundenfehlerbeobachtung usw.
Es ist notwendig, spezielle Kategorien zu trennen und die Prioritäten aufzulisten, wie zum Beispiel: Datenbankstabilität, Gateway-Stabilität, große Kundendienstverfügbarkeitsindikatoren, CPU-/Speicherressourcenüberlastungsfehler.
Wir sollten uns auch auf die Überwachung großer Kunden konzentrieren, wie Auto Chess, kommerzielle Kunden von FastGPT, Chongchunxue Studio usw. (monatliche Nutzung von mehr als 30 Kernen, wählen Sie 5 typische aus).
Es gibt nur eine begrenzte Anzahl an Stabilitätsproblemen, wenn diese großen Kunden erst einmal gut bedient sind. Verfolgen Sie nicht zu viele, sondern konzentrieren Sie sich auf die Lösung der aktuellen Kernstabilitätsprobleme und richten Sie dann einen vollständigen Tracking-Prozess ein.
Studierende, die Störungen verursachen, können mit Strafen, dem Abzug von Prämien oder sogar der Exmatrikulation rechnen. Als Start-up-Unternehmen setzen wir in der Regel keine Strafmaßnahmen ein , da die Beteiligten keine Störungen verursachen wollen und jeder wirklich hart daran arbeitet, das Problem zu lösen Bevorzugen Sie positive Anreize, z. B. Wenn die vierteljährliche Ausfallhäufigkeit abnimmt, geben Sie entsprechende Anreize .
Einfaches architektonisches Design
Die Systemarchitektur hängt von Anfang an mit der Stabilität zusammen. Je komplexer die Architektur, desto einfacher ist es, Probleme zu haben. Daher achten viele Unternehmen häufig nicht auf das Design und die Überprüfung der Unternehmensarchitektur Dass das Design für mich zu komplex ist, ist meiner Meinung nach ein sehr gutes Beispiel dafür, wie man eine komplexe Sache in ein einfaches CRUD umwandeln kann. Das Design der Datenbanktabellenstruktur ist einfach und viele Stabilitätsprobleme werden in der Wiege gelöst.
Das Gleiche gilt für unser Messsystem. Wir haben es ursprünglich für mehr als ein Dutzend CRDs konzipiert, aber nachdem wir mehr als ein halbes Jahr lang gekämpft hatten, konnten wir das System neu entwerfen und auswählen Die Entwicklung dauerte zwei Wochen und innerhalb eines Monats war es stabil online.
Deshalb: Einfaches Design ist entscheidend für die Stabilität!
Moderate Überwachung, gezielt
Überwachung ist ein zweischneidiges Schwert, zu viel ist nicht genug. Viele Sealos-Ausfälle wurden dadurch verursacht, dass Prometheus zu viele Ressourcen belegte und der API-Server überlastet war, was wiederum zu neuen Stabilitätsproblemen führte. Nachdem wir unsere Lektion gelernt hatten, wechselten wir zu einer einfacheren Überwachungslösung wie VictoriaMetrics und kontrollierten gleichzeitig die Anzahl der Überwachungsindikatoren streng. Tools wie Uptime Kuma sind sehr nützlich. Sie können sich gegenseitig über Regionen hinweg testen und Probleme rechtzeitig finden.
Das Gleiche gilt für den Bereitschaftsdienst. Es gibt jeden Tag Tausende von Alarmen. Hier fangen wir also grundsätzlich bei 0 an und addieren die Dinge langsam zusammen, beispielsweise unter dem Gesichtspunkt der „endgültigen Stabilität des Geschäfts des großen Kunden“, wenn beispielsweise ein Containerausfall vorliegt , das Telefon wird wahrscheinlich ununterbrochen klingeln. Fügen Sie dann langsam Dinge hinzu, z. B. „Der Host ist nicht bereit“. Theoretisch ist der Host nicht bereit und sollte das Geschäft nicht beeinträchtigen. Wenn das System allmählich ausgereift ist, wird es irgendwann möglich sein, den Host nicht bereit zu machen, ohne dass ein Bereitschaftsdienst erforderlich ist.
Haben Sie keine Angst vor Peinlichkeiten, wenn Sie Fehler melden
Der Überprüfungsbericht von Tencent Cloud war sehr gut. Er erläuterte wahrheitsgemäß die Gründe für den Fehler, analysierte objektiv, was nicht ausreichte, und versprach, das Problem aktiv zu beheben. Eine solche offene und verantwortungsvolle Haltung macht es tatsächlich einfacher, das Vertrauen der Nutzer zu gewinnen. Im Gegensatz dazu kommt es dem Verheimlichen des Themas aus Angst vor der Gärung der öffentlichen Meinung gleich, als würde man Gift trinken, um den Durst zu stillen. Vielmehr vermittelt es den Benutzern das Gefühl, dass es sich um eine undurchsichtige Blackbox handelt und sie nicht wissen, was in der Zukunft passieren wird . Kunden, die Ihre Produkte wirklich lieben und bereit sind, mit Ihnen zu wachsen, können prinzipienlose Fehler tolerieren. Der Schlüssel liegt darin, Aufrichtigkeit zu zeigen und Maßnahmen für eine echte Verbesserung zu ergreifen.
Zusammenfassen
Der öffentliche Cloud- Dienst von Sealos ist seit mehr als einem Jahr in Betrieb und hat mehr als 100.000 registrierte Benutzer. Aufgrund seiner hervorragenden Funktionen, Erfahrung und Kosteneffizienz ist es bei vielen Entwicklern beliebt und auch einige große Kunden haben begonnen, ihr Geschäft in unsere Sealos-Cloud zu migrieren. Darunter sind einige groß angelegte Internetprodukte, zum Beispiel das Spiel „Happy Auto Chess“, das mehr als 4 Millionen aktive Nutzer hat .
Mit Blick auf die Zukunft glauben wir, dass wir durch systematisches Fehlermanagement weiterhin Stabilität erreichen werden. Durch einfaches und effizientes Architekturdesign, eine stetige und stetige Überwachungsstrategie und ergänzt durch eine offene und ehrliche Kommunikationshaltung wird Sealos eine Cloud sein Von einem kleinen inländischen Open-Source-Unternehmen gefördert und entwickelt, wird es definitiv eine sehr fortschrittliche Cloud werden!
Linus nahm die Sache selbst in die Hand, um zu verhindern, dass Kernel-Entwickler Tabulatoren durch Leerzeichen ersetzen. Sein Vater ist einer der wenigen Führungskräfte, die Code schreiben können, sein zweiter Sohn ist Direktor der Open-Source-Technologieabteilung und sein jüngster Sohn ist ein Kern Mitwirkender bei Open Source: Es dauerte ein Jahr, 5.000 häufig verwendete mobile Anwendungen zu konvertieren. Java ist die Sprache, die am anfälligsten für Schwachstellen von Drittanbietern ist. Wang Chenglu, der Vater von Hongmeng: Open Source Hongmeng ist die einzige architektonische Innovation im Bereich der Basissoftware in China. Ma Huateng und Zhou Hongyi geben sich die Hand, um „den Groll zu beseitigen.“ Ehemaliger Microsoft-Entwickler: Die Leistung von Windows 11 ist „lächerlich schlecht“. sind sehr herzerwärmend . Meta Llama 3 wird offiziell veröffentlicht