

Wenn Sie ein Benutzer mit zwei verschiedenen RAG-Anwendungen sind, wie entscheiden Sie dann, welche besser ist? Wie können Entwickler die Leistung ihrer RAG-Anwendung quantitativ und iterativ verbessern?
Natürlich ist es sowohl für Benutzer als auch für Entwickler wichtig, die Leistung von RAG-Anwendungen genau zu bewerten. Ein einfacher Vergleich einiger weniger Beispiele kann die Antwortqualität von RAG-Anträgen jedoch nicht vollständig messen. Für die quantitative Bewertung von RAG-Anträgen müssen glaubwürdige und reproduzierbare Indikatoren verwendet werden.
In diesem Artikel wird erläutert, wie eine RAG-Anwendung sowohl aus Black-Box- als auch aus White-Box-Perspektive quantitativ bewertet werden kann.
01. Black-Box-Methode VS. White-Box-Methode
Wir vergleichen die Bewertung von RAG-Anwendungen mit dem Testen eines Softwaresystems. Es gibt zwei Möglichkeiten, die Qualität des RAG-Systems zu bewerten: die Black-Box-Methode und die White-Box-Methode.
Bei der Black-Box-Bewertung einer RAG-Anwendung können wir keinen Blick in das Innere der RAG-Anwendung werfen und die Wirkung von RAG nur anhand der in die RAG-Anwendung eingegebenen Informationen und der von ihr zurückgegebenen Informationen bewerten. Bei einem allgemeinen RAG-System können wir nur auf diese drei Informationen zugreifen: Benutzeranfrage, abgerufene Kontexte, die vom RAG-System abgerufen werden, und RAG-Antwort. Wir verwenden diese drei Informationen, um die Wirkung von RAG-Anwendungen zu bewerten. Die Black-Box-Methode ist eine End-to-End-Bewertungsmethode und eignet sich auch besser für die Bewertung von RAG-Anwendungen mit geschlossener Quelle.
Bei der White-Box-Bewertung einer RAG-Anwendung können wir alle internen Prozesse der RAG-Anwendung sehen. Daher können einige wichtige interne Komponenten die Leistung dieser RAG-Anwendung bestimmen. Am Beispiel des allgemeinen RAG-Bewerbungsprozesses umfassen einige Schlüsselkomponenten das Einbettungsmodell, das Reranking-Modell und LLM. Einige RAGs verfügen über Mehrkanal-Abruffunktionen und verfügen möglicherweise auch über Algorithmen zur Suche nach Begriffen. Das Ersetzen und Aktualisieren dieser Schlüsselkomponenten kann auch zu besseren Ergebnissen bei RAG-Anwendungen führen. Mit dem White-Box-Ansatz können Open-Source-RAG-Anwendungen evaluiert oder selbst entwickelte RAG-Anwendungen verbessert werden.
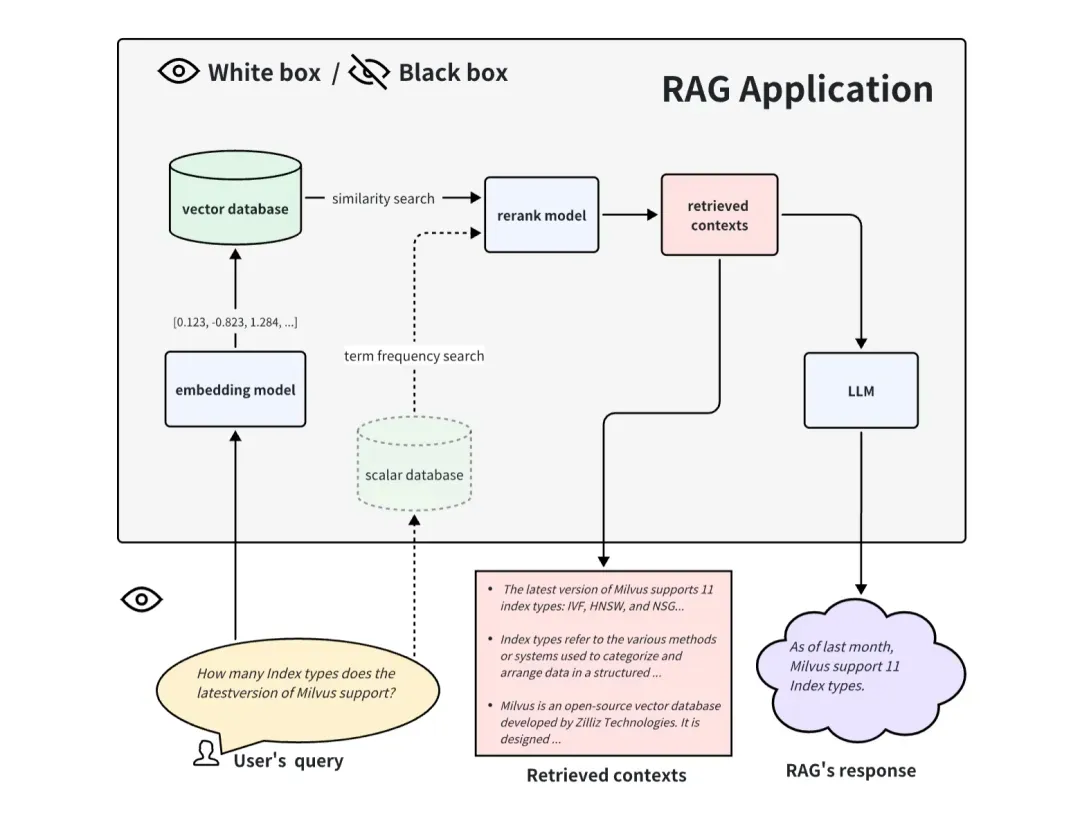
02.End-to-End-Bewertungsmethode der Black Box
Bewertungsindikatoren unter Black-Box-Bedingungen
Wenn es sich bei der RAG-Anwendung um eine Blackbox handelt, können wir nur auf diese drei Informationen zugreifen: Benutzeranfrage, abgerufene Kontexte, die vom RAG-System abgerufen werden, und RAG-Antwort. Sie sind das wichtigste Triplett im gesamten RAG-Prozess, und zwei von ihnen hemmen sich gegenseitig. Wir können die Wirkung einer RAG-Anwendung bewerten, indem wir die Korrelation zwischen zwei Elementen des Tripletts erkennen.
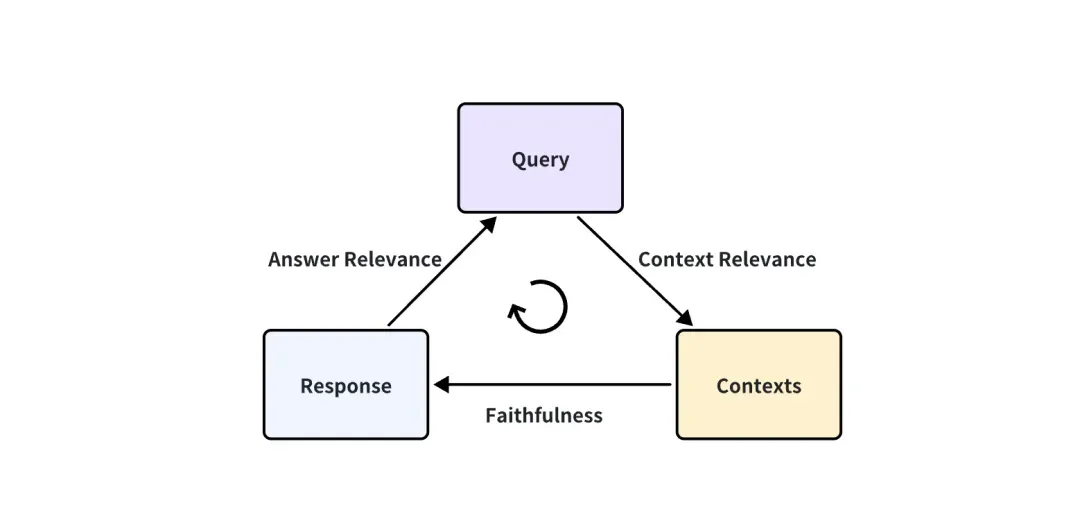
Die folgenden drei entsprechenden Indikatorwerte werden vorgeschlagen:
-
Kontextrelevanz: Misst das Ausmaß, in dem der abgerufene Kontext die Abfrage unterstützen kann. Wenn die Punktzahl niedrig ist, bedeutet dies, dass zu viele Inhalte abgerufen wurden, die für die Abfragefrage irrelevant sind, und dass diese fehlerhaften abgerufenen Kenntnisse einen gewissen Einfluss auf die endgültige Antwort von LLM haben werden.
-
Treue: Diese Metrik misst die sachliche Konsistenz der generierten Antworten in einem bestimmten Kontext. Er wird auf der Grundlage der Antwort und des abgerufenen Kontexts berechnet. Wenn dieser Wert niedrig ist und die Tatsache widerspiegelt, dass die Antwort des LLM nicht mit dem abgerufenen Wissen übereinstimmt, ist die Antwort eher illusorisch.
-
Antwortrelevanz: Konzentriert sich auf die Bewertung der Relevanz der generierten Antwort für eine bestimmte Abfrage. Schlechtere Noten erhalten Antworten, die unvollständig sind oder redundante Informationen enthalten.
Nehmen Sie als Beispiel die Antwortrelevanz:
Question: Where is France and what is it’s capital?
Low relevance answer: France is in western Europe.
High relevance answer: France is in western Europe and Paris is its capital.
Wie berechnet man diese Indikatoren quantitativ?
Auf die Frage „Wo liegt Frankreich und was ist seine Hauptstadt?“ lautet die Antwort von geringer Relevanz: „Frankreich liegt in Westeuropa.“ Gibt es eine Möglichkeit, dies zu quantifizieren? Punktzahl, diese Antwort ist 0,2 Punkte und die andere Antwort ist 0,4 Punkte? Und objektiv müssen wir sicherstellen, dass der Effekt von 0,4 Punkten tatsächlich besser ist als der von 0,2 Punkten.
Wenn außerdem für jede Antwort eine Punktzahl von Menschen verlangt wird, muss ein großer Arbeitsaufwand organisiert und bestimmte Leitstandards formuliert werden, damit sie diese Richtlinie erlernen und sich daran halten können, um eine Punktzahl zu erzielen. Diese Methode ist zeitaufwändig und offensichtlich unrealistisch. Gibt es eine Möglichkeit, automatisch zu punkten?
Glücklicherweise können fortgeschrittene LLMs wie GPT-4 mittlerweile ein ähnliches Niveau wie menschliche Annotatoren erreichen. Es kann die beiden oben genannten Anforderungen gleichzeitig erfüllen. Zum einen kann es quantitativ, objektiv und fair punkten, zum anderen kann es automatisiert werden.
In diesem Artikel „LLM-as-a-Judge“ ( https://arxiv.org/abs/2306.05685) schlug der Autor die Möglichkeit eines LLM als Richter vor und führte auf dieser Grundlage eine große Anzahl von Experimenten durch. Die Ergebnisse zeigen, dass leistungsstarke LLM-Richter (wie GPT-4) Kontrolle und Crowdsourcing-Menschenpräferenzen gut aufeinander abstimmen können und eine Konsistenz von mehr als 80 % erreichen, was dem gleichen Maß an Konsistenz zwischen Menschen entspricht. Daher ist LLM als Richter eine skalierbare und interpretierbare Methode zur Annäherung an menschliche Präferenzen, deren Bewertung durch Menschen andernfalls sehr teuer wäre.
Sie denken vielleicht, dass die 80-prozentige Übereinstimmung zwischen LLM und menschlichen Bewertern nicht bedeutet, dass LLM und Menschen sehr konsistent sind. Sie sollten sich jedoch darüber im Klaren sein, dass zwei unterschiedliche Personen, die eine Beratung erhalten haben, bei der Bewertung solcher subjektiven Fragen möglicherweise keine 100-prozentige Übereinstimmung erzielen können. Daher zeigt die Tatsache, dass GPT-4 zu 80 % mit dem Menschen übereinstimmt, dass GPT-4 vollständig zu einem qualifizierten Richter werden kann.
Bezüglich der Bewertung von GPT-4 nehmen wir immer noch die Antwortrelevanz als Beispiel. Wir verwenden die folgende Eingabeaufforderung, um GPT-4-Fragen zu stellen:
There is an existing knowledge base chatbot application. I asked it a question and got a reply. Do you think this reply is a good answer to the question? Please rate this reply. The score is an integer between 0 and 10. 0 means that the reply cannot answer the question at all, and 10 means that the reply can answer the question perfectly.
Question: Where is France and what is it’s capital?
Reply: France is in western Europe and Paris is its capital.
Antwort von GPT-4:
10
Es ist ersichtlich, dass alle QA-Paare automatisch ausgewertet werden können, solange eine geeignete Eingabeaufforderung im Voraus entworfen wird, wie die Eingabeaufforderung im obigen Beispiel, und Frage und Antwort ersetzt werden. Daher ist auch die Gestaltung der Eingabeaufforderung sehr wichtig. Die Eingabeaufforderung im obigen Beispiel ist nur ein Beispiel. Die eigentliche Eingabeaufforderung ist oft sehr lang, um die GPT-Bewertung fairer und robuster zu gestalten. Dies erfordert den Einsatz einiger fortschrittlicher Prompt-Engineering-Techniken, wie z. B. Multi-Shot- oder CoT-Denkkettentechniken (Chain-of-Thought). Beim Entwerfen dieser Eingabeaufforderungen müssen manchmal einige Voreingenommenheiten von LLM berücksichtigt werden, wie z. B. die allgemeine Positionsverzerrung von LLM: Wenn die Eingabeaufforderung relativ lang ist, neigt LLM dazu, einen Teil des Inhalts am Anfang der Eingabeaufforderung zu bemerken und einen Teil des Inhalts darin zu ignorieren die Mitte.
Glücklicherweise müssen wir uns nicht allzu viele Gedanken über das zeitnahe Design machen. Die Evaluierungstools für diese RAG-Anwendungen wurden bereits entworfen und integriert. Gemeinschaft und Zeit können dabei helfen, zu testen, wie gut sie Eingabeaufforderungen entwerfen. Worüber wir uns mehr Sorgen machen müssen, ist, dass der Zugriff auf LLMs wie GPT-4 in großen Mengen den Verbrauch zu vieler API-Schlüssel erfordert. Ich hoffe, dass es in Zukunft einen günstigeren LLM oder einen lokalen LLM geben wird, der das Niveau eines guten Richters erreichen kann.
Muss ich die Grundwahrheit markieren?
Sie haben vielleicht bemerkt, dass im obigen Beispiel keine Grundwahrheit verwendet wird. Es handelt sich um eine von Menschen geschriebene Standardantwort zur Beantwortung der entsprechenden Fragen. Beispielsweise kann ein Indikator zwischen Grundwahrheit und Antwort definiert werden, der als Antwortkorrektheit bezeichnet wird und zur Messung der Richtigkeit von RAG-Antworten verwendet wird. Das Bewertungsprinzip ist dasselbe wie die oben beschriebene Art und Weise, wie Answer Relevance die LLM-Bewertung verwendet.
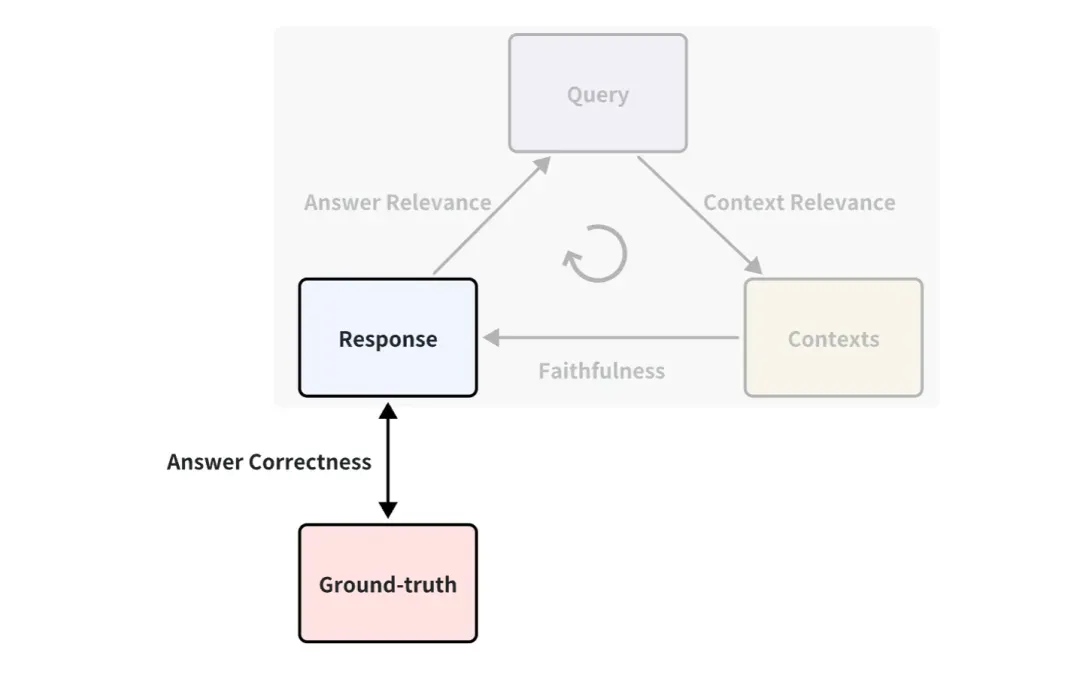
Daher sind die Bewertungsindikatoren umfangreicher, wenn es eine Grundwahrheit gibt, d. h. die Wirkung der RAG-Anwendung kann aus mehr Blickwinkeln gemessen werden. In den meisten Fällen ist es jedoch teuer, einen standardmäßig guten Ground-Truth-Datensatz zu erhalten, und es kann viel Personal und Zeit für die Kommentierung erforderlich sein. Gibt es eine Möglichkeit, eine schnelle Anmerkung zu erreichen?
Da LLM alles generieren kann, ist es möglich, LLM Abfragen und Grundwahrheiten auf der Grundlage von Wissensdokumenten generieren zu lassen. Beispielsweise gibt es einige integrierte Methoden in der synthetischen Testdatengenerierung von ragas und in der QuestionGeneration von llama-index, die direkt und bequem verwendet werden können.
Werfen wir einen Blick auf die Wirkung, die basierend auf Wissensdokumenten in Ragas erzielt wird:

Fragen und Antworten, die auf Basis von Wissensdokumenten generiert wurden ( https://docs.ragas.io/en/latest/concepts/testset_generation.html)
Wie Sie sehen können, generiert die obige Abbildung viele Abfragefragen und entsprechende Antworten, einschließlich der entsprechenden Kontextquellen. Um die Vielfalt der generierten Fragen sicherzustellen, können Sie auch den Anteil verschiedener generierter Fragetypen auswählen, z. B. den Anteil der einfachen Frage und der Begründungsfrage.
Auf diese Weise können wir diese generierten Fragen und die Grundwahrheit einfach und direkt zur quantitativen Bewertung einer RAG-Anwendung verwenden. Wir müssen nicht mehr online gehen, um verschiedene Basisdatensätze zu finden. Auf diese Weise können wir auch private oder interne Daten auswerten innerhalb des Unternehmens.
03. White-Box-Bewertungsmethode
RAG-Pipeline unter White-Box-Bedingungen
Wenn wir RAG-Anwendungen aus einer White-Box-Perspektive betrachten, können wir die interne Implementierungspipeline von RAG sehen. Am Beispiel des allgemeinen RAG-Bewerbungsprozesses umfassen einige Schlüsselkomponenten das Einbettungsmodell, das Reranking-Modell und LLM. Einige RAGs verfügen über Mehrkanal-Abruffunktionen und verfügen möglicherweise auch über Algorithmen zur Suche nach Begriffsfrequenzen. Natürlich kann das Testen dieser Schlüsselkomponenten auch die Wirksamkeit der RAG-Pipeline in einem bestimmten Schritt widerspiegeln. Das Ersetzen und Aktualisieren dieser Schlüsselkomponenten kann auch zu einer besseren Leistung von RAG-Anwendungen führen.
Im Folgenden stellen wir vor, wie diese drei typischen Schlüsselkomponenten bewertet werden:
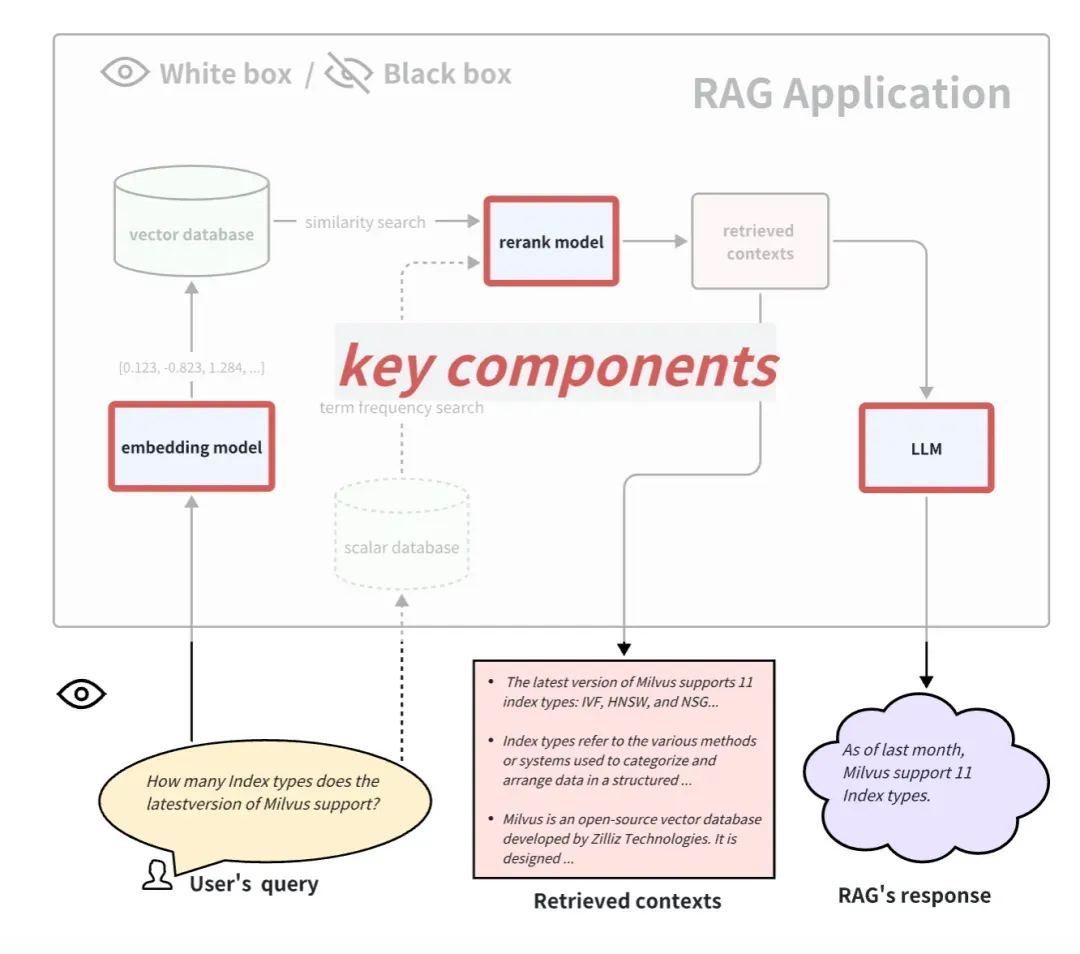
So bewerten Sie das Einbettungsmodell und ordnen das Modell neu ein
Einbettungsmodell und Reranking-Modell arbeiten zusammen, um die Abruffunktion verwandter Dokumente zu vervollständigen. Oben haben wir den Kontextrelevanz-Indikator eingeführt, mit dem die Relevanz zurückgerufener Dokumente bewertet werden kann. Aber im Allgemeinen verwenden Menschen bei Datensätzen mit Ground-Truth häufiger einige deterministische Indikatoren im Bereich des Informationsabrufs und -abrufs, um die Wirkung des Abrufs zu messen. Im Vergleich zu LLM-basierten Kontextrelevanzindikatoren sind diese Indikatoren schneller, kostengünstiger und deterministischer zu berechnen (sie müssen jedoch fundierte Kontexte liefern).
Häufig verwendete Indikatoren für den Informationsabruf
Im Bereich des Informationsabrufs und -abrufs gehören zu den häufig verwendeten Indikatoren Indikatoren, die das Ranking berücksichtigen, und Indikatoren, die das Ranking nicht berücksichtigen.
Der Index, der die Rangfolge berücksichtigt, reagiert empfindlich auf die Rangfolge der abgerufenen Ground-Truth-Dokumente unter allen abgerufenen Dokumenten. Das heißt, eine Änderung der Korrelationsreihenfolge unter allen abgerufenen Dokumenten führt dazu, dass sich die Bewertung dieses Indexes unabhängig von der Rangfolge ändert sind das Gegenteil.
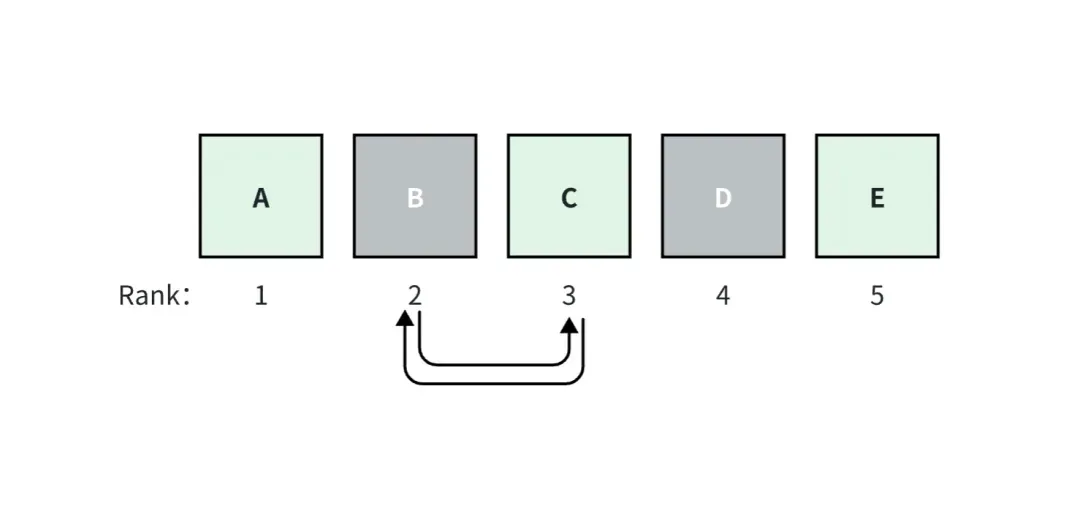
In der obigen Abbildung gehen wir beispielsweise davon aus, dass die RAG-Anwendung top_k=5 Dokumente abruft, darunter die Dokumente A, C und E, die der Grundwahrheit entsprechen. Dokument A hat den Rang 1, es hat die höchste Relevanzbewertung und die Bewertungen nehmen nach rechts ab.
Wenn die Dokumente B und C vertauscht werden, ändern sich die Bewertungen für die Metriken, die für das Ranking berücksichtigt werden, aber die Bewertungen für die Metriken, die nicht für das Ranking berücksichtigt werden, ändern sich nicht.
Hier sind einige häufige spezifische Indikatoren:
Indikatoren, die keine Rankings berücksichtigen
-
Kontextabruf: Der Umfang, in dem das System alle erforderlichen Dokumente vollständig abgerufen hat.
-
Kontextgenauigkeit: Wie gut das System das Signal abruft (im Vergleich zum Rauschen).
Für das Ranking berücksichtigte Metriken
-
Die durchschnittliche Präzision (AP) misst alle relevanten abgerufenen Blöcke und berechnet eine gewichtete Punktzahl. Der durchschnittliche AP über einen Datensatz wird oft als MAP bezeichnet.
-
Der reziproke Rang (RR) misst, wo der erste relevante Block in Ihrer Suche erscheint. Der durchschnittliche RR über einen Datensatz wird oft als MRR bezeichnet.
-
Der normalisierte diskontierte kumulative Gewinn (NDCG) berücksichtigt den Fall, dass Ihre Korrelationsklassifizierung nicht-binär ist.
Der gängigste Bewertungsmaßstab: MTBB
Der Massive Text Embedding Benchmark (MTEB) ist ein umfassender Benchmark zur Bewertung der Leistung von Texteinbettungsmodellen für eine Vielzahl von Aufgaben und Datensätzen. MTEB deckt 8 Einbettungsaufgaben ab, darunter zweisprachiges Mining (Bitext Mining), Klassifizierung, Clustering, paarweise Klassifizierung, Neuordnung, Abruf, semantische Textähnlichkeit (STS) und Zusammenfassung. Es deckt insgesamt 58 Datensätze in 112 Sprachen ab und ist damit einer der bisher umfassendsten Benchmarks zur Texteinbettung.
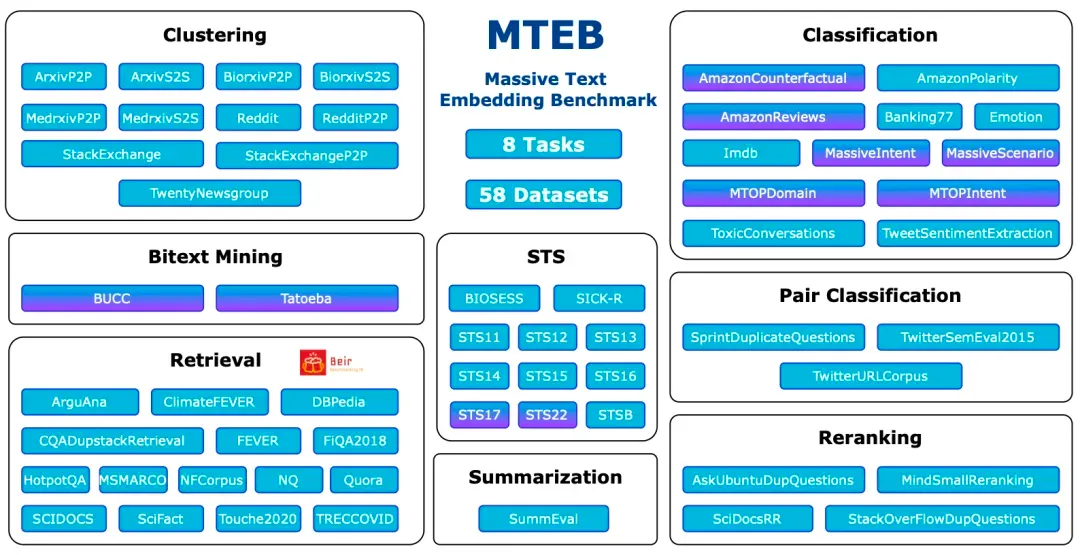
MTEB: Massive Text Embedding Benchmark
https://arxiv.org/abs/2210.07316
Es ist ersichtlich, dass MTEB Abrufaufgaben und Reranking-Aufgaben enthält. Konzentrieren Sie sich bei der Bewertung von Einbettungs- und Reranking-Modellen in RAG-Anwendungen auf die Modelle mit höheren Bewertungen in diesen beiden Aufgaben. In den Empfehlungen des MTEB-Papiers (https://arxiv.org/abs/2210.07316) ist NDCG der wichtigste Indikator, für das Rerank-Modell ist MAP der wichtigste Indikator.
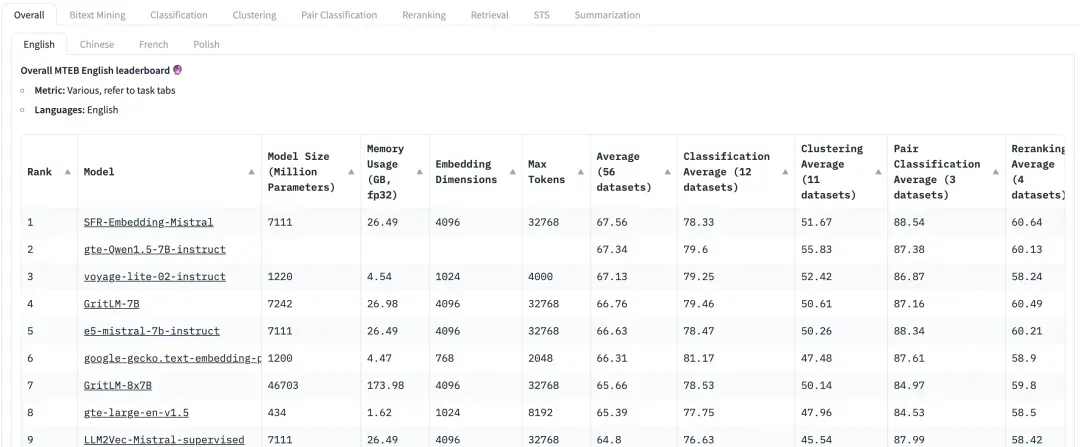
Auf HuggingFace ist MTEB die Bestenliste, der jeder große Aufmerksamkeit schenkt. Da der Datensatz jedoch öffentlich ist, kann es sein, dass einige Modelle diesen Datensatz bis zu einem gewissen Grad überangepasst haben, was die Leistung im tatsächlichen Datensatz beeinträchtigt. Daher muss bei der Bewertung des Rückrufeffekts auch der Bewertungsleistung bei geschäftsorientierten benutzerdefinierten Datensätzen mehr Aufmerksamkeit geschenkt werden.
Wie ist LLM zu bewerten?
Im Allgemeinen kann der Generierungsprozess direkt anhand des oben vorgestellten LLM-basierten Indikators für den Schritt vom Kontext zur Reaktion, nämlich der Treue, bewertet werden.
Aber für einige relativ einfache Abfragetests, beispielsweise solche, bei denen die Standardantworten nur einige einfache Phrasen enthalten, können auch einige klassische Indikatoren verwendet werden. Zum Beispiel ROUGE-L-Präzision, Token-Overlap-Präzision. Diese deterministische Bewertung erfordert auch einen annotierten Ground-Truth-Kontext.
ROUGE-L Precision misst die längste gemeinsame Teilsequenz zwischen der generierten Antwort und dem abgerufenen Kontext.
Genauigkeit der Token-Überlappung Berechnet die Genauigkeit der Token-Überlappung zwischen der generierten Antwort und dem abgerufenen Kontext.
Beispielsweise können die folgenden relativ einfachen Probleme immer noch mithilfe von Indikatoren wie ROUGE-L Precision und Token Overlap Precision bewertet werden.
Question: How many Index types does the latest version of Milvus support?
Reply: As of last month, Milvus support 11 Index types.
Ground-truth Context: In this version, Milvus support 11 Index types.
Allerdings ist zu beachten, dass diese Indikatoren für RAG-Szenarien mit komplexen Fragestellungen nicht geeignet sind. In diesem Fall müssen LLM-basierte Indikatoren zur Bewertung herangezogen werden. Zum Beispiel offene Fragen wie die folgenden:
Question: Please design a text search application based on the features of the latest version of Milvus and list the application usage scenarios.
04. Einführung in häufig verwendete Bewertungstools
Mittlerweile sind in der Open-Source-Community professionelle Tools entstanden, mit deren Hilfe Anwender quantitative Bewertungen erleichtern und schnell durchführen können. Im Folgenden stellen wir die derzeit gängigen und benutzerfreundlichen RAG-Bewertungstools und einige ihrer Eigenschaften vor.
Ragas ( https://docs.ragas.io/en/latest/getstarted/index.html ): Ragas ist ein Tool, das sich auf die Bewertung von RAG-Anwendungen konzentriert. Die Bewertung kann über eine einfache Schnittstelle erfolgen. Ragas-Indikatoren sind vielfältig und stellen keine Anforderungen an den Rahmen der RAG-Anwendung. Sie können den Prozess jeder Bewertung auch über Langsmith ( https://www.langchain.com/langsmith) überwachen, um die Gründe für jede Bewertung zu analysieren und den Verbrauch von API-Schlüsseln zu beobachten.
Continuous Eval ( https://docs.relari.ai/v0.3) : Continuous-eval ist ein Open-Source-Softwarepaket zur Evaluierung von LLM-Anwendungspipelines mit Schwerpunkt auf Retrieval Augmented Generation (RAG)-Pipelines. Es bietet eine kostengünstigere und schnellere Bewertungsoption. Darüber hinaus ermöglicht es die Erstellung vertrauenswürdiger Ensemble-Bewertungspipelines mit mathematischen Garantien.
TruLens-Eval: Trulens-Eval ist ein Tool, das speziell zur Bewertung von RAG-Indikatoren verwendet wird. Es lässt sich relativ gut in LangChain und Llama-Index integrieren und kann problemlos zur Bewertung von RAG-Anwendungen verwendet werden, die mit diesen beiden Frameworks erstellt wurden. Darüber hinaus kann Trulens-Eval auch eine Seite im Browser zur visuellen Überwachung starten, die dabei hilft, die Gründe für jede Bewertung zu analysieren und den Verbrauch von API-Schlüsseln zu beobachten.
Llama-Index: Der Llama-Index eignet sich sehr gut zum Erstellen von RAG-Anwendungen. Seine aktuelle Ökologie ist relativ umfangreich und er durchläuft derzeit eine schnelle iterative Entwicklung. Es umfasst auch die Funktion zur Auswertung von RAG und zur Generierung synthetischer Datensätze. Benutzer können von Llama-Index selbst erstellte RAG-Anwendungen problemlos evaluieren.
Darüber hinaus gibt es einige Bewertungstools, deren Funktionen den oben genannten ähneln. Zum Beispiel Phoenix ( https://docs.arize.com/phoenix ), DeepEval (https://github.com/confident-ai/deepeval), LangSmith, OpenAI Evals ( https://github.com/openai/ Auswertungen). Die iterative Entwicklung dieser Bewertungstools erfolgt ebenfalls sehr schnell. Für bestimmte Funktionen und Verwendungsmethoden können Sie die entsprechenden offiziellen Dokumente überprüfen.
05. Zusammenfassung
Für Benutzer und Entwickler von RAG-Anwendungen ist es in der Praxis von entscheidender Bedeutung, die Leistung von RAG-Anwendungen zu bewerten. In diesem Artikel wird die Methode zur quantitativen Bewertung von RAG-Anwendungen sowohl aus Black-Box- als auch aus White-Box-Perspektive vorgestellt und einige praktische Bewertungstools vorgestellt, die den Lesern helfen sollen, die Bewertungstechnologie schnell zu verstehen und schnell loszulegen. Weitere Informationen zu RAG finden Sie in anderen Artikeln dieser Reihe „RAG-Kultivierungshandbuch | Ein Artikel, der die Technologie hinter RAG erklärt“ „RAG-Kultivierungshandbuch | Ist RAG der Todesstoß? Bedeutet der lange Kontext eines großen Modells, dass das Abrufen von Vektoren nicht mehr wichtig ist?
Linus nahm die Sache selbst in die Hand, um zu verhindern, dass Kernel-Entwickler Tabulatoren durch Leerzeichen ersetzen. Sein Vater ist einer der wenigen Führungskräfte, die Code schreiben können, sein zweiter Sohn ist Direktor der Open-Source-Technologieabteilung und sein jüngster Sohn ist ein Kern Mitwirkender bei Open Source: Es dauerte ein Jahr, 5.000 häufig verwendete mobile Anwendungen zu konvertieren. Java ist die Sprache, die am anfälligsten für Schwachstellen von Drittanbietern ist. Wang Chenglu, der Vater von Hongmeng: Open Source Hongmeng ist die einzige architektonische Innovation im Bereich der Basissoftware in China. Ma Huateng und Zhou Hongyi geben sich die Hand, um „den Groll zu beseitigen.“ Ehemaliger Microsoft-Entwickler: Die Leistung von Windows 11 ist „lächerlich schlecht“. sind sehr herzerwärmend . Meta Llama 3 wird offiziell veröffentlicht