
Seit dem Aufkommen von ChatGPT Ende 2022 rückt künstliche Intelligenz erneut in den Fokus der Welt und KI auf Basis großer Sprachmodelle (LLM) hat sich zu einem „heißen Huhn“ im Bereich der künstlichen Intelligenz entwickelt. Im darauffolgenden Jahr haben wir den rasanten Fortschritt der KI in den Bereichen Wensheng-Text und Wensheng-Bilder erlebt, während die Entwicklung im Bereich Wensheng-Video relativ langsam verlief. Anfang 2024 veröffentlichte OpenAI erneut einen Blockbuster – Vincents Videomodell Sora. Das letzte Puzzleteil zur Content-Erstellung wurde von AI fertiggestellt.
Vor einem Jahr ging in den sozialen Medien ein Video viral, in dem Smith Nudeln aß. Auf dem Bild hatte der Schauspieler ein abscheuliches Gesicht, deformierte Gesichtszüge und aß Spaghetti in verdrehter Haltung. Dieses schreckliche Bild erinnert uns daran, dass die Technologie der KI-generierten Videos damals noch in den Kinderschuhen steckte.

Nur ein Jahr später sorgte ein von Sora erstelltes KI-Video von „modischen Frauen, die durch die Straßen von Tokio gehen“ erneut für Aufsehen in den sozialen Medien. Im darauffolgenden März schloss sich Sora mit Künstlern aus der ganzen Welt zusammen, um offiziell eine Reihe surrealer Kunstkurzfilme zu starten, die die Tradition unterwandern. Der folgende Kurzfilm „Air Head“ wurde von den berühmten Regisseuren Walter und Sora geschaffen. Das Bild ist exquisit und lebensecht, und der Inhalt ist wild und fantasievoll. Man kann sagen, dass Sora bei seinem Debüt Mainstream-KI-Videomodelle wie Gen-2, Pika und Stable Video Diffusion „vernichtet“ hat.

Die Entwicklung der KI verläuft weitaus schneller als erwartet. Wir können leicht vorhersehen, dass die bestehende Industriestruktur, einschließlich Kurzvideos, Spiele, Film und Fernsehen, Werbung usw., in naher Zukunft umgestaltet wird. Soras Ankunft scheint uns einem Modell für den Aufbau der Welt einen Schritt näher zu bringen.
Warum verfügt Sora über so mächtige Magie? Welche magischen Technologien nutzt es? Nach Durchsicht des offiziellen technischen Berichts und vieler zugehöriger Dokumente erläutert der Autor in diesem Artikel die technischen Prinzipien hinter Sora und den Schlüssel zu seinem Erfolg.
1 Welches Kernproblem möchte Sora lösen?
Um es in einem Satz zusammenzufassen: Die Herausforderung für Sora besteht darin, mehrere Arten visueller Daten in eine einheitliche Darstellungsmethode umzuwandeln, damit ein einheitliches Training durchgeführt werden kann.
Warum brauchen wir eine einheitliche Ausbildung? Bevor wir diese Frage beantworten, werfen wir zunächst einen Blick auf Soras bisherige Ideen zur Mainstream-KI-Videogenerierung.
1.1 KI-Videogenerierungsmethode in der Zeit vor Sora
- Erweitern Sie basierend auf dem Bildinhalt eines Einzelbilds
Erweiterungen, die auf Einzelbildbildern basieren, verwenden den Inhalt des aktuellen Bildes, um das nächste Bild vorherzusagen. Jedes Bild ist eine Fortsetzung des vorherigen Bildes und bildet so einen kontinuierlichen Videostream (das Wesentliche an einem Video ist ein Bild, das kontinuierlich Bild für Bild angezeigt wird). .
Dabei werden in der Regel Textbeschreibungen zur Generierung von Bildern verwendet und anschließend werden auf Basis der Bilder Videos generiert. Allerdings gibt es bei dieser Idee ein Problem: Die Verwendung von Text zur Generierung von Bildern selbst ist zufällig. Diese Zufälligkeit wird bei der Verwendung von Bildern zur Generierung von Videos doppelt verstärkt, und die Kontrollierbarkeit und Stabilität des endgültigen Videos sind sehr gering.
- Trainieren Sie direkt am gesamten Video
Da der auf der Einzelbildableitung basierende Videoeffekt nicht gut ist, wird die Idee dahingehend geändert, das gesamte Video zu trainieren.
Hier wird in der Regel ein Videoclip von einigen Sekunden ausgewählt und dem Modell mitgeteilt, was das Video zeigt. Nach viel Training kann die KI lernen, Videoclips zu generieren, die stilistisch den Trainingsdaten ähneln. Der Fehler dieser Idee besteht darin, dass die von der KI gelernten Inhalte fragmentiert sind, es schwierig ist, lange Videos zu generieren, und die Kontinuität der Videos schlecht ist.
Manche Leute fragen sich vielleicht: Warum nicht längere Videos für das Training verwenden? Der Hauptgrund dafür ist, dass Videos im Vergleich zu Text und Bildern sehr groß sind und die Grafikkarte nur über einen begrenzten Videospeicher verfügt und längeres Videotraining nicht unterstützen kann. Unter verschiedenen Einschränkungen ist der Wissensumfang der KI äußerst begrenzt. Bei der Eingabe von Inhalten, die sie „nicht kennt“, sind die generierten Ergebnisse oft unbefriedigend.
Wenn Sie den Engpass von KI-Videos überwinden möchten, müssen Sie daher diese Kernprobleme lösen.
1.2 Herausforderungen beim Videomodelltraining
Videodaten gibt es in verschiedenen Formen, vom horizontalen bis zum vertikalen Bildschirm, von 240p bis 4K, mit unterschiedlichen Seitenverhältnissen, unterschiedlichen Auflösungen und unterschiedlichen Videoattributen. Die Komplexität und Vielfalt der Daten bringt große Schwierigkeiten beim KI-Training mit sich, was wiederum zu einer schlechten Modellleistung führt. Deshalb müssen diese Videodaten zunächst einheitlich dargestellt werden.
Die Kernaufgabe von Sora besteht darin, eine Möglichkeit zu finden, mehrere Arten visueller Daten in eine einheitliche Darstellungsmethode umzuwandeln, sodass alle Videodaten unter einem einheitlichen Framework effektiv trainiert werden können.
1.3 Sora: Meilensteine auf dem Weg zu AGI
Unsere Mission ist es, sicherzustellen, dass künstliche allgemeine Intelligenz der gesamten Menschheit zugute kommt. —— OpenAI
Das Ziel von OpenAI war schon immer klar, künstliche allgemeine Intelligenz (AGI) zu erreichen. Welche Bedeutung hat also die Geburt von Sora für das Erreichen des Ziels von OpenAI?
Um AGI zu implementieren, muss das große Modell die Welt verstehen. Während der gesamten Entwicklung von OpenAI ermöglichte das ursprüngliche GPT-Modell der KI das Verstehen von Text (eine Dimension, nur Länge), und das später eingeführte DALL·E-Modell ermöglichte der KI das Verstehen von Bildern (zwei Dimensionen, Länge und Breite), und jetzt das Sora-Modell ermöglicht es der KI, Videos zu verstehen (dreidimensional, Länge, Breite und Zeit).
Durch umfassendes Verständnis von Texten, Bildern und Videos kann KI die Welt nach und nach verstehen. Sora ist OpenAIs Außenposten zu AGI. Es ist mehr als nur ein Videogenerierungsmodell, wie der Titel seines technischen Berichts [1] sagt: „Ein Videogenerierungsmodell als Weltsimulator.“
Die Vision von Tuoshupai deckt sich mit dem Ziel von OpenAI. Die Extensionisten glauben, dass die Verwendung einer kleinen Anzahl von Symbolen und Rechenmodellen zur Modellierung der menschlichen Gesellschaft und der individuellen Intelligenz den Grundstein für die frühe KI legte, aber größere Dividenden hängen von größeren Datenmengen und höherer Rechenleistung ab. Wenn wir kein bahnbrechendes neues Modell erstellen können, können wir nach mehr Datensätzen suchen und eine größere Rechenleistung nutzen, um die Genauigkeit des Modells zu verbessern, Datenrechenleistung gegen Modellleistung einzutauschen und Innovationen bei Datenverarbeitungssystemen voranzutreiben. In dem von Tuoshupai veröffentlichten Großmodell-Datenverarbeitungssystem werden mathematische KI-Modelle, Daten und Berechnungen nahtlos miteinander verbunden und verstärken sich gegenseitig wie nie zuvor und werden zu einer neuen Produktivkraft, die eine qualitativ hochwertige Entwicklung der Gesellschaft fördert [2].
2 Interpretation des Sora-Prinzips
Sora ist nicht das erste Vincent-Videomodell, das veröffentlicht wird. Warum sorgt es also für so viel Aufsehen? Was ist das Geheimnis dahinter? Wenn Sie Soras Trainingsprozess in einem Satz beschreiben: Das Originalvideo wird durch einen visuellen Encoder in den latenten Raum komprimiert und in Raumzeit-Patches zerlegt, die mit Text kombiniert werden. Bedingte Einschränkungen werden verwendet, um das Diffusionstraining und die Generierung durch den Transformator durchzuführen Bildblöcke werden schließlich über den entsprechenden visuellen Decoder wieder dem Pixelraum zugeordnet.
2.1 Videokomprimierungsnetzwerk
Sora wandelt zunächst rohe Videodaten in niedrigdimensionale latente Raummerkmale um. Die Videodaten, die wir täglich ansehen, sind zu groß und müssen zunächst in niedrigdimensionale Vektoren umgewandelt werden, die von der KI verarbeitet werden können. Hier greift OpenAI auf ein klassisches Papier zurück: Latent Diffusion Models[3].
Der Kernpunkt dieses Artikels besteht darin, das Originalbild in ein latentes Raummerkmal zu verfeinern, das nicht nur die Schlüsselmerkmalsinformationen des Originalbilds beibehalten, sondern auch die Daten- und Informationsmenge stark komprimieren kann.
OpenAI hat wahrscheinlich den Variational Autoencoder (VAE) für Bilder in diesem Dokument aktualisiert, um die Verarbeitung von Videodaten zu unterstützen. Auf diese Weise kann Sora eine große Menge ursprünglicher Videodaten in niedrigdimensionale latente Raummerkmale umwandeln, dh die Kernschlüsselinformationen im Video extrahieren, die den Schlüsselinhalt des Videos darstellen können.
2.2 Raumzeit-Patches
Um ein groß angelegtes KI-Videotraining durchzuführen, muss zunächst die Grundeinheit der Trainingsdaten definiert werden. Im Large Language Model (LLM) ist die Grundeinheit des Trainings Token[4]. OpenAI lässt sich vom Erfolg von ChatGPT inspirieren: Der Token-Mechanismus vereint auf elegante Weise verschiedene Textformen – Code, mathematische Symbole und verschiedene natürliche Sprachen. Kann Sora sein „Token“ finden?
Dank früherer Forschungsergebnisse hat Sora endlich die Antwort gefunden – Patch.
- Vision Transformer (ViT)
Was ist ein Patch? Patch kann umgangssprachlich als Bildblock verstanden werden. Wenn die Auflösung des zu verarbeitenden Bildes zu groß ist, ist ein direktes Training nicht praktikabel. Daher wird im Artikel Vision Transformer [5] eine Methode vorgeschlagen: Teilen Sie das Originalbild in Bildblöcke (Patch) gleicher Größe auf, serialisieren Sie diese Bildblöcke und fügen Sie ihre Positionsinformationen hinzu (Position Embedding), sodass komplexe Bilder entstehen kann in die bekanntesten Sequenzen der Transformer-Architektur umgewandelt werden, wobei der Selbstaufmerksamkeitsmechanismus verwendet wird, um die Beziehung zwischen den einzelnen Bildblöcken zu erfassen und letztendlich den Inhalt des gesamten Bildes zu verstehen.
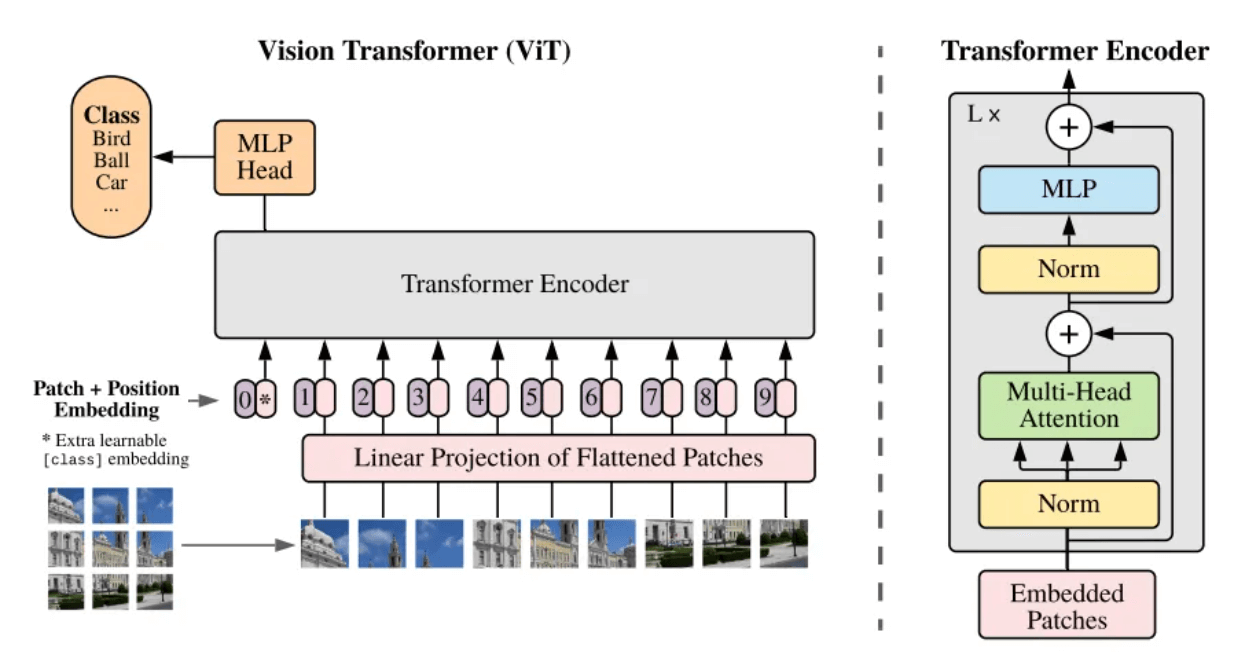
Rahmenstruktur des ViT-Modells[5]
Video kann als eine Folge von Bildern betrachtet werden, die entlang der Zeitachse verteilt sind. Daher fügt Sora die Dimension der Zeit hinzu und wertet statische Bildblöcke in Raumzeit-Bildfelder (Spacetime Patches) auf. Jeder räumlich-zeitliche Bildblock enthält sowohl zeitliche als auch räumliche Informationen im Video. Das heißt, ein räumlich-zeitlicher Bildblock stellt nicht nur einen kleinen räumlichen Bereich im Video dar, sondern stellt auch die Veränderungen in diesem räumlichen Bereich über einen Zeitraum von dar Zeit.
Durch die Einführung des Patch-Konzepts kann die räumliche Korrelation für räumlich-zeitliche Bildblöcke an verschiedenen Positionen in einem einzelnen Bild berechnet werden. Die zeitliche Korrelation kann für räumlich-zeitliche Bildblöcke an derselben Position in aufeinanderfolgenden Bildern berechnet werden. Jeder Bildblock existiert nicht mehr isoliert, sondern ist eng mit umgebenden Elementen verbunden. Auf diese Weise ist Sora in der Lage, Videoinhalte mit reichhaltigen räumlichen Details und zeitlicher Dynamik zu verstehen und zu generieren.

Zerlegen Sie Sequenzbilder in räumlich-zeitliche Bildblöcke
- Native Auflösung (NaViT)
Allerdings hat das ViT-Modell einen sehr großen Nachteil: Das Originalbild muss quadratisch sein und jeder Bildblock hat die gleiche feste Größe. Tägliche Videos sind nur breit oder hoch und es gibt keine quadratischen Videos.
Deshalb hat OpenAI eine andere Lösung gefunden: die „Patch n‘ Pack“-Technologie [6] in NaViT , die Eingabeinhalte jeder Auflösung und jedes Seitenverhältnisses verarbeiten kann.
Diese Technologie teilt Inhalte mit unterschiedlichen Seitenverhältnissen und Auflösungen in Bildblöcke auf, die je nach Bedarf angepasst werden können. Bildblöcke aus verschiedenen Bildern können für ein einheitliches Training flexibel gepackt werden. Darüber hinaus kann diese Technologie aufgrund der Ähnlichkeit der Bilder auch identische Bildblöcke verwerfen, wodurch die Schulungskosten erheblich gesenkt und eine schnellere Schulung erreicht werden.
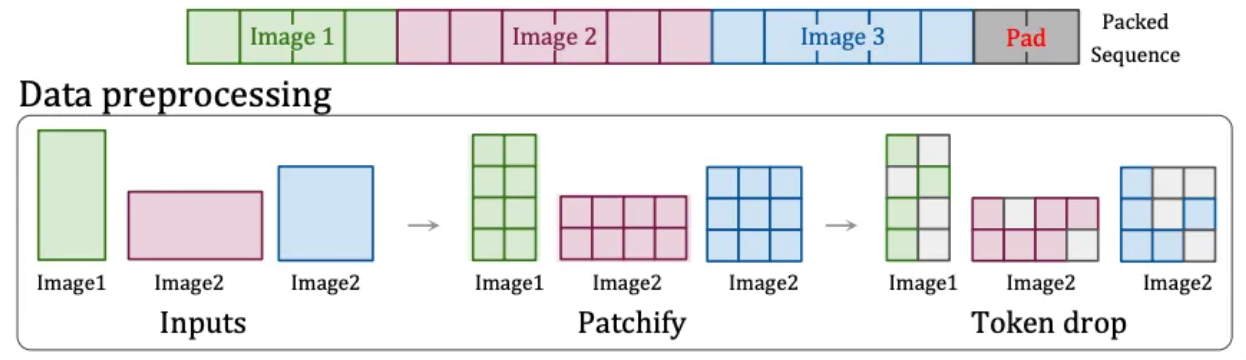
Patch n'Pack-Technologie[6]
Aus diesem Grund kann Sora die Erstellung von Videos mit unterschiedlichen Auflösungen und Seitenverhältnissen unterstützen. Darüber hinaus kann das Training mit dem nativen Seitenverhältnis die Komposition und den Rahmen des Ausgabevideos verbessern, da beim Zuschneiden unweigerlich Informationen verloren gehen und das Modell den Hauptinhalt des Originalbilds leicht falsch versteht, was zu einem Bild führt, das nur einen Teil des Hauptinhalts enthält Körper.
Die Rolle von Spacetime Patches ist dieselbe wie die von Token im großen Sprachmodell. Es ist die Grundeinheit von Video. Wenn wir ein Video in eine Reihe von raumzeitlichen Patches komprimieren, konvertieren wir tatsächlich die kontinuierlichen visuellen Informationen Eine Reihe diskreter Einheiten, die vom Modell verarbeitet werden können und die Grundlage für das Lernen und Generieren von Modellen bilden.
2.3 Videotextbeschreibung
Durch die obige Erklärung haben wir den Prozess verstanden, bei dem Sora Originalvideos in endgültige trainierbare räumlich-zeitliche Vektoren umwandelt. Vor dem eigentlichen Training muss jedoch ein Problem gelöst werden: Dem Modell erklären, worum es in diesem Video geht.
Um ein Wensheng-Videomodell zu trainieren, muss eine Korrespondenz zwischen Text und Video hergestellt werden . Während des Trainings ist eine große Anzahl von Videos mit entsprechenden Textbeschreibungen erforderlich. Die Qualität der manuell kommentierten Beschreibungen ist jedoch gering und beeinträchtigt Trainingsergebnisse. Daher hat OpenAI die Re-Captioning-Technologie [7] von seinem eigenen DALL·E 3 übernommen und auf den Videobereich angewendet.
Konkret trainierte OpenAI zunächst ein hochbeschreibendes Untertitelgenerierungsmodell und generierte anhand dieses Modells detaillierte Beschreibungsinformationen für alle Videos im Trainingssatz gemäß den Spezifikationen. Dieser Teil der Textbeschreibungsinformationen wurde während des Finales mit den zuvor erwähnten räumlich-zeitlichen Bildfeldern kombiniert Nach dem Matching und Training kann Sora die Textbeschreibung und die Videobildblöcke verstehen und ihnen entsprechen.
Darüber hinaus wird OpenAI auch GPT verwenden, um die kurzen Eingabeaufforderungen des Benutzers in detailliertere Beschreibungssätze umzuwandeln, ähnlich denen während des Trainings, was es Sora ermöglicht, den Eingabeaufforderungen des Benutzers genau zu folgen und hochwertige Videos zu erstellen.
2.4 Videoschulung und -generierung
Im offiziellen technischen Bericht [1] wird deutlich erwähnt , dass Sora ein Diffusionstransformator ist, das heißt, Sora ist ein Diffusionsmodell mit Transformer als Backbone-Netzwerk.
- Broadcast Transformer (DiT)
Das Konzept der Diffusion stammt aus der Physik. Wenn beispielsweise ein Tropfen Tinte in Wasser fällt, breitet er sich im Laufe der Zeit langsam aus wird sich allmählich von einem Tropfen in verschiedene Teile des Wassers verteilen.
Inspiriert durch diesen Diffusionsprozess wurde das Diffusionsmodell geboren. Es handelt sich um ein klassisches „Zeichnungs“-Modell, auf dem Stable Diffusion und Midjourney basieren. Sein Grundprinzip besteht darin, dem Originalbild nach und nach Rauschen hinzuzufügen, so dass es allmählich zu einem vollständigen Rauschzustand wird, und diesen Vorgang dann umzukehren, d. h. durch Entrauschen (Denoise) das Bild wiederherzustellen. Indem das Modell eine große Anzahl an Umkehrerfahrungen erlernen lässt, lernt das Modell schließlich, aus dem Rauschbild spezifische Bildinhalte zu generieren.
Dem Bericht zufolge wird Soras Methode wahrscheinlich die U-Net-Architektur im ursprünglichen Diffusion-Modell durch die Transformer-Architektur ersetzen, mit der er am besten vertraut ist. Denn je nach Erfahrung bei anderen Deep-Learning-Aufgaben sind die Parameter der Transformer-Architektur im Vergleich zu U-Net hoch skalierbar. Mit zunehmender Anzahl von Parametern wird die Leistungsverbesserung der Transformer-Architektur deutlicher.
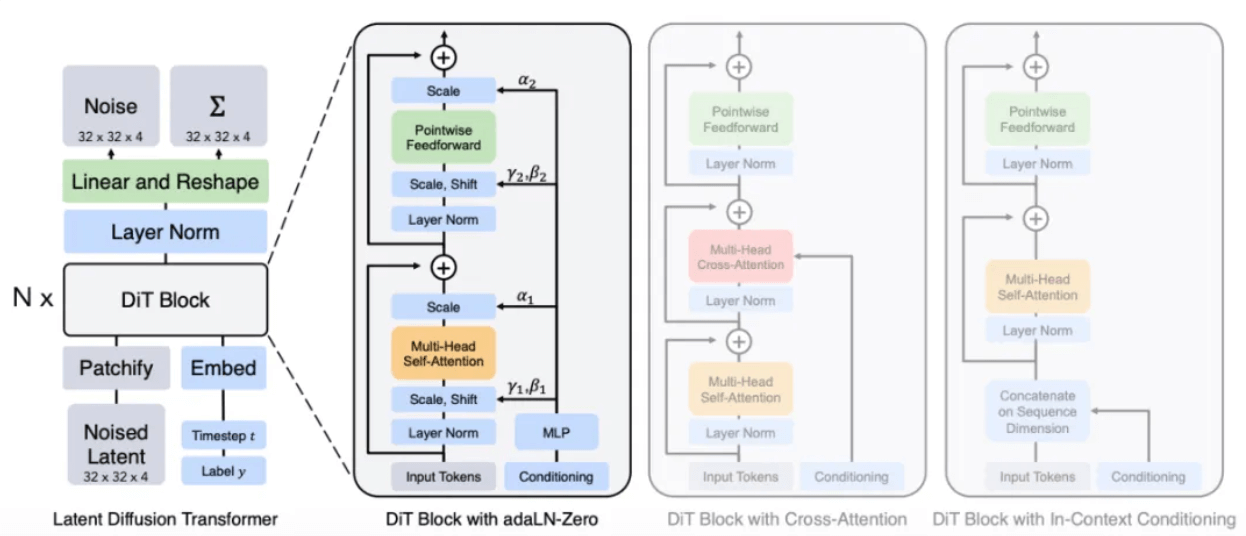
DiT-Modellarchitektur[8]
Durch einen dem Diffusionsmodell ähnlichen Prozess werden während des Trainings Rausch-Patches (und bedingte Informationen wie Textaufforderungen) bereitgestellt, Rauschen wird wiederholt hinzugefügt und entrauscht, und schließlich lernt das Modell, die ursprünglichen Patches vorherzusagen.

Stellen Sie den Rauschpatch auf den ursprünglichen Bildpatch wieder her
- Videogenerierungsprozess
Abschließend fassen wir den gesamten Prozess zusammen, bei dem Sora Videos aus Text generiert.
Wenn der Benutzer eine Textbeschreibung eingibt, ruft Sora zunächst das Modell auf, um es zu einem Standard-Videobeschreibungssatz zu erweitern, und generiert dann basierend auf der Beschreibung einen ersten räumlich-zeitlichen Bildblock aus dem Rauschen Basierend auf den vorhandenen räumlich-zeitlichen Bildblock- und Textbedingungen wird spekuliert, dass der nächste räumlich-zeitliche Bildblock generiert wird (ähnlich wie GPT das nächste Token basierend auf dem vorhandenen Token vorhersagt), und schließlich wird die generierte potenzielle Darstellung wieder abgebildet den Pixelraum durch den entsprechenden Decoder, um ein Video zu bilden.
3 Das Potenzial der Datenverarbeitung
Wenn wir uns den technischen Bericht von Sora ansehen, können wir feststellen, dass Sora tatsächlich keinen großen Durchbruch in der Technologie erzielt hat, aber die bisherige Forschungsarbeit gut integriert hat. Schließlich wird keine Technologie plötzlich auftauchen. Der wichtigere Grund für den Erfolg von Sora ist die Anhäufung von Rechenleistung und Daten.
Sora zeigt während des Trainingsprozesses offensichtliche Skaleneffekte. Die folgende Abbildung zeigt, dass sich die Qualität der generierten Stichproben bei festen Eingaben und Seeds mit zunehmendem Rechenaufwand deutlich verbessert.

Vergleich der Effekte bei Basisrechenleistung, 4-facher Rechenleistung und 32-facher Rechenleistung
Darüber hinaus zeigte Sora durch das Lernen aus großen Datenmengen auch einige unerwartete Fähigkeiten.
➢ 3D-Konsistenz: Sora ist in der Lage, Videos mit dynamischen Kamerabewegungen zu generieren. Während sich die Kamera bewegt und dreht, behalten Charaktere und Szenenelemente stets konsistente Bewegungsmuster im dreidimensionalen Raum bei.
➢Langzeitkonsistenz und Objektpersistenz: Bei langen Aufnahmen behalten Menschen, Tiere und Objekte ihr einheitliches Erscheinungsbild bei, auch wenn sie verdeckt werden oder den Rahmen verlassen.
➢Weltinteraktivität : Sora kann auf einfache Weise Verhaltensweisen simulieren, die den Zustand der Welt beeinflussen. In dem Video, in dem das Malen beschrieben wird, hinterlässt beispielsweise jeder Strich eine Spur auf der Leinwand.
➢Simulieren Sie die digitale Welt: Sora kann auch Spielvideos wie „Minecraft“ simulieren.
Diese Eigenschaften erfordern keine explizite induktive Vorspannung für 3D-Objekte usw., sie sind lediglich ein Phänomen von Skaleneffekten.
4 Tuoshupai großes Modelldatenverarbeitungssystem
Der Erfolg von Sora beweist einmal mehr die Wirksamkeit der Strategie „Größere Leistung macht Wunder“ – die kontinuierliche Erweiterung des Modellmaßstabs wird direkt die Verbesserung der Leistung fördern, die in hohem Maße von einer großen Anzahl hochwertiger Datensätze und ultra-moderner Daten abhängt. Große Rechenleistung ist unverzichtbar.
Zu Beginn seiner Gründung formulierte Tuoshupai seine Mission als „Datenverarbeitung, nur für neue Entdeckungen“, und unser Ziel ist es, ein „unendliches Modellspiel“ zu entwickeln. Sein Datenverarbeitungssystem für große Modelle verwendet Cloud-native Technologie, um die Datenspeicherung und Datenverarbeitung mit einem Speicher und mehrmotoriger Datenverarbeitung zu rekonstruieren, wodurch KI-Modelle größer und schneller werden und das Big-Data-System umfassend auf die Ära großer Modelle aktualisiert wird.
Im Großmodell-Datenverarbeitungssystem kann alles in der Welt und seine Bewegungen in Daten umgewandelt werden. Die Daten können zum Trainieren des Ausgangsmodells verwendet werden und werden dann dem Datenverarbeitungssystem hinzugefügt Der Prozess iteriert weiter und erforscht die KI-Intelligenz endlos. In Zukunft wird Tuoshupai weiterhin im Bereich Daten forschen, die Kernkompetenzen der Technologieforschung stärken, mit Industriepartnern zusammenarbeiten, um Best Practices in der Datenelementbranche zu erkunden und die digitale intelligente Entscheidungsfindung zu fördern.
Hinweis: Der offizielle technische Bericht von OpenAI zeigt nur die allgemeine Modellierungsmethode und enthält keine Implementierungsdetails. Wenn dieser Artikel Fehler enthält, korrigieren Sie mich bitte und kommunizieren Sie mit mir.
Verweise:
- [1] Videogenerierungsmodelle als Weltsimulatoren
- [2] Großes Modelldatenverarbeitungssystem – Theorie
- [3] Hochauflösende Bildsynthese mit latenten Diffusionsmodellen
- [4] Aufmerksamkeit ist alles, was Sie brauchen
- [5] Ein Bild sagt mehr als 16×16 Worte: Transformatoren für die Bilderkennung im Maßstab
- [6] Patch n'Pack: NaViT, ein Vision Transformer für jedes Seitenverhältnis und jede Auflösung
- [7] Verbesserung der Bilderzeugung durch bessere Bildunterschriften
- [8] Skalierbare Diffusionsmodelle mit Transformatoren