
Autor|Invisible (Xing Ying), leitender Datenbank-Kernel-Ingenieur bei NetEase
Bearbeitung und Fertigstellung|Technisches Team von SelectDB
Einleitung: Als wichtige Geschäftsbereiche von NetEase haben Lingxi Office und Yunxin die Lingxi Eagle-Überwachungsplattform bzw. die Yunxin-Datenplattform entwickelt, um die Herausforderungen der Verarbeitung und Analyse umfangreicher Protokoll-/Zeitreihendaten zu bewältigen. Dieser Artikel konzentriert sich auf die Anwendung von Apache Doris in NetEase-Protokollen und Zeitreihenszenarien sowie auf die Verwendung von Apache Doris als Ersatz für Elasticsearch und InfluxDB, wodurch geringere Serverressourcen und eine höhere Abfrageleistung erreicht werden. Im Vergleich zu Elasticsearch ist die Abfragegeschwindigkeit von Apache Doris höher mindestens um das 11-fache verbessert, wodurch Speicherressourcen um bis zu 70 % gespart werden.
Mit der rasanten Entwicklung der Informationstechnologie ist die Menge an Unternehmensdaten explodiert. Für ein großes Internetunternehmen wie NetEase werden täglich große Mengen an Protokollen und Zeitreihendaten generiert, egal ob es sich um interne Bürosysteme oder extern bereitgestellte Dienste handelt. Diese Daten sind zu einem wichtigen Eckpfeiler für die Fehlerbehebung, Problemdiagnose, Sicherheitsüberwachung, Risikowarnung, Benutzerverhaltensanalyse und Erlebnisoptimierung geworden. Die vollständige Ausschöpfung des Werts dieser Daten wird dazu beitragen, die Produktzuverlässigkeit, Leistung, Sicherheit und Benutzerzufriedenheit zu verbessern.
Als wichtige Geschäftsbereiche von NetEase haben Lingxi Office und Yunxin die Lingxi Eagle-Überwachungsplattform bzw. die Yunxin-Datenplattform entwickelt, um die Herausforderungen zu bewältigen, die die Verarbeitung und Analyse umfangreicher Protokoll-/Zeitreihendaten mit sich bringt. Mit der weiteren Expansion des Unternehmens sind auch die Protokoll-/Zeitreihendaten exponentiell gewachsen, was zu Problemen wie erhöhten Speicherkosten, längeren Abfragezeiten und einer Verschlechterung der Systemstabilität geführt hat. Die frühe Plattform war nicht nachhaltig, was NetEase dazu veranlasste, nach besseren Lösungen zu suchen.
Dieser Artikel konzentriert sich auf die Implementierung von Apache Doris in NetEase-Protokoll- und Zeitreihenszenarien, stellt die Architektur-Upgrade-Praxis von Apache Doris in NetEase Lingxi Office und NetEase Cloud Letter Business vor und teilt die Erfahrungen mit der Tabellenerstellung, dem Import, der Abfrage usw. basierend auf tatsächlichen Szenarien.
Frühe Architektur und Schwachstellen
01 Lingxi-Eagle-Überwachungsplattform
NetEase Lingxi Office ist eine neue Generation der kollaborativen E-Mail-Büroplattform. Integrieren Sie Module wie E-Mail, Kalender, Cloud-Dokumente, Instant Messaging und Kundenverwaltung. Die Eagle-Überwachungsplattform ist ein Full-Link-APM-System, das mehrdimensionale Leistungsanalysen mit unterschiedlicher Granularität für NetEase Lingxi Office bereitstellen kann.
Die Eagle-Überwachungsplattform speichert und analysiert hauptsächlich Geschäftsprotokolldaten wie Lingxi Office, Enterprise Email, Youdao Cloud Notes und Lingxi Documents. Die Protokolldaten werden zunächst über Logstash gesammelt und verarbeitet und dann in Elasticsearch gespeichert, das eine Echtzeitprotokollierung durchführt Es bietet auch Protokollsuche und vollständige Link-Protokollabfragedienste für Lingxi Office.

Mit der Zeit und der Zunahme der Protokolldaten treten bei der Verwendung von Elasticsearch nach und nach einige Probleme ans Licht:
- Hohe Abfragelatenz: Bei täglichen Abfragen ist die durchschnittliche Antwortlatenz von Elasticsearch hoch, was sich auf die Benutzererfahrung auswirkt. Dies wird hauptsächlich durch Faktoren wie die Größe der Daten, die Rationalität des Indexdesigns und die Hardwareressourcen eingeschränkt.
- Hohe Lagerkosten: Im Zusammenhang mit Kostensenkung und Effizienzsteigerung müssen Unternehmen ihre Lagerkosten immer dringender senken. Da Elasticsearch jedoch über mehrere Datenspeicher wie Vorwärtszeilen-, invertierte Zeilen- und Spaltenspeicher verfügt, ist der Grad der Datenredundanz hoch, was gewisse Herausforderungen bei der Kostenreduzierung und Effizienzsteigerung mit sich bringt.
02 Yunxin-Datenplattform
NetEase Yunxin ist ein Experte für konvergente Kommunikation und Cloud-native PaaS-Dienste, der auf der 26-jährigen Technologie von NetEase basiert. Das Unternehmen bietet konvergente Kommunikation und Cloud-native Kernprodukte und -lösungen, einschließlich IM Instant Messaging, Video Cloud, SMS, Qingzhou-Mikroservices und Middleware-PaaS . Warten.
Die Yunxin-Datenplattform analysiert hauptsächlich Zeitreihendaten, die von IM, RTC, SMS und anderen Diensten generiert werden. Die frühe Datenarchitektur basierte hauptsächlich auf der Zeitreihendatenbank InfluxDB. Die Datenquelle wurde zunächst über die Kafka-Nachrichtenwarteschlange gemeldet und nach der Feldanalyse und -bereinigung in der Zeitreihendatenbank InfluxDB gespeichert. Die Offline-Seite unterstützt die Offline-T+1-Datenanalyse, und die Echtzeit-Seite muss die Echtzeitgenerierung von Indikatorüberwachungsberichten und -rechnungen ermöglichen.
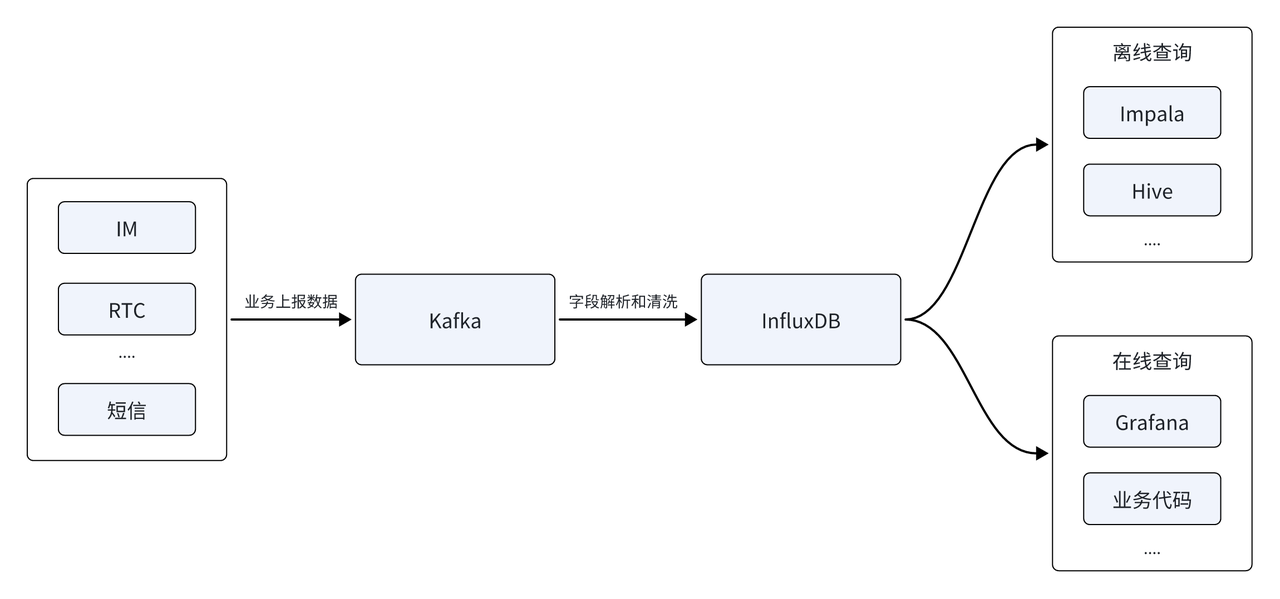
Mit der schnellen Abdeckung des Kundenumfangs nimmt die Anzahl der gemeldeten Datenquellen weiter zu, und InfluxDB steht auch vor einer Reihe neuer Herausforderungen:
- Speicherüberlauf OOM: Mit zunehmender Anzahl von Datenquellen muss eine Offline-Analyse auf der Grundlage mehrerer Datenquellen durchgeführt werden, und die Schwierigkeit der Analyse nimmt zu. Begrenzt durch die Abfragefunktionen von InfluxDB kann die aktuelle Architektur bei komplexen Abfragen aus mehreren Datenquellen zu einem Out-of-Memory (OOM) führen, was eine große Herausforderung für die Geschäftsverfügbarkeit und Systemstabilität darstellt.
- Hohe Speicherkosten: Die Geschäftsentwicklung hat auch zu einem kontinuierlichen Wachstum des Cluster-Datenvolumens geführt, und ein großer Teil der Daten im Cluster sind kalte und kalte Daten, die auf die gleiche Weise gespeichert werden, was zu hohen Speicherkosten führt. Dies ist mit Kostensenkungen nicht vereinbar und erhöht den Konflikt mit effektiven Unternehmenszielen.
Auswahl der Kernmotoren
Aus diesem Grund begann NetEase, nach neuen Datenbanklösungen zu suchen, um die Herausforderungen zu lösen, mit denen die beiden oben genannten großen Unternehmen in Protokoll-Timing-Szenarien konfrontiert sind. Gleichzeitig hofft NetEase, nur eine Datenbank zu verwenden, um sich an das Geschäftssystem und die technische Architektur der beiden Hauptanwendungsszenarien anzupassen und so den Upgrade-Anforderungen einer extremen Benutzerfreundlichkeit und geringen Investitionen gerecht zu werden. In dieser Hinsicht erfüllt Apache Doris unsere Auswahlanforderungen, insbesondere in den folgenden Aspekten:
- Optimierung der Speicherkosten : Apache Doris hat viele Optimierungen in der Speicherstruktur vorgenommen, um redundanten Speicher zu reduzieren. Es verfügt über ein höheres Komprimierungsverhältnis und unterstützt Hot- und Cold-Tier-Storage auf Basis von S3 und NOS (Netease Object Storage), wodurch die Speicherkosten effektiv gesenkt und die Datenspeichereffizienz verbessert werden können.
- Hoher Durchsatz und hohe Leistung : Apache Doris unterstützt spaltenbasiertes Festplattenschreiben mit hoher Leistung, sequentielle Komprimierung und Stream Load-effizienten Streaming-Import und kann das Schreiben von Daten im zweistelligen GB pro Sekunde unterstützen. Dies gewährleistet nicht nur das Schreiben von Protokolldaten in großem Umfang, sondern sorgt auch für Abfragetransparenz mit geringer Latenz.
- Protokollabruf in Echtzeit : Apache Doris unterstützt nicht nur den Volltextabruf von Protokolltexten, sondern ermöglicht auch die Abfrageantwort in Echtzeit. Doris unterstützt das interne Hinzufügen eines invertierten Index, der den Volltextabruf von Zeichenfolgentypen sowie den äquivalenten und Bereichsabruf von gewöhnlichen numerischen/Datumstypen erfüllen kann. Gleichzeitig kann die Abfrageleistung des invertierten Index weiter optimiert und verbessert werden Geeignet für die Protokolldatenanalyse.
- Unterstützen Sie die Isolation großer Mandanten : Doris kann Tausende von Datenbanken und Zehntausende Datentabellen hosten und einem Mandanten die unabhängige Nutzung einer Datenbank ermöglichen, wodurch die Anforderungen der Datenisolation mit mehreren Mandanten erfüllt und Datenschutz und Sicherheit gewährleistet werden.
Darüber hinaus hat sich Apache Doris im vergangenen Jahr weiter mit dem Protokollszenario befasst und eine Reihe von Kernfunktionen eingeführt, z. B. einen effizienten invertierten Index, einen flexiblen Variant-Datentyp usw., um eine bessere Protokoll-/Zeitverarbeitung und -analyse zu ermöglichen Seriendaten. Effiziente und flexible Lösungen . Aufgrund der oben genannten Vorteile entschied sich NetEase schließlich für die Einführung von Apache Doris als Kern-Engine der neuen Architektur.
Einheitliche Protokollspeicher- und Analyseplattform basierend auf Apache Doris
01 Lingxi-Eagle-Überwachungsplattform

Erstens hat NetEase in der Lingxi Office-Eagle-Überwachungsplattform Elasticsearch erfolgreich auf Apache Doris aktualisiert und so eine einheitliche Protokollspeicher- und Analyseplattform aufgebaut. Dieses Architektur-Upgrade verbessert nicht nur die Leistung und Stabilität der Plattform erheblich, sondern stellt ihr auch einen leistungsstarken und effizienten Protokollabrufdienst zur Verfügung. Spezifische Vorteile spiegeln sich wider in:
- Speicherressourcen werden um 70 % eingespart: Dank des hohen Komprimierungsverhältnisses von Doris-Spaltenspeicher und ZSTD benötigt Elasticsearch 100 T Speicherplatz zum Speichern derselben Protokolldaten, aber nur 30 T Speicherplatz zum Speichern in Doris, was einer Einsparung von 70 T entspricht % der Speicherressourcen . Aufgrund der erheblichen Einsparung von Speicherplatz kann bei gleichen Kosten eine SSD anstelle einer Festplatte zum Speichern heißer Daten verwendet werden, was auch zu einer größeren Verbesserung der Abfrageleistung führt.
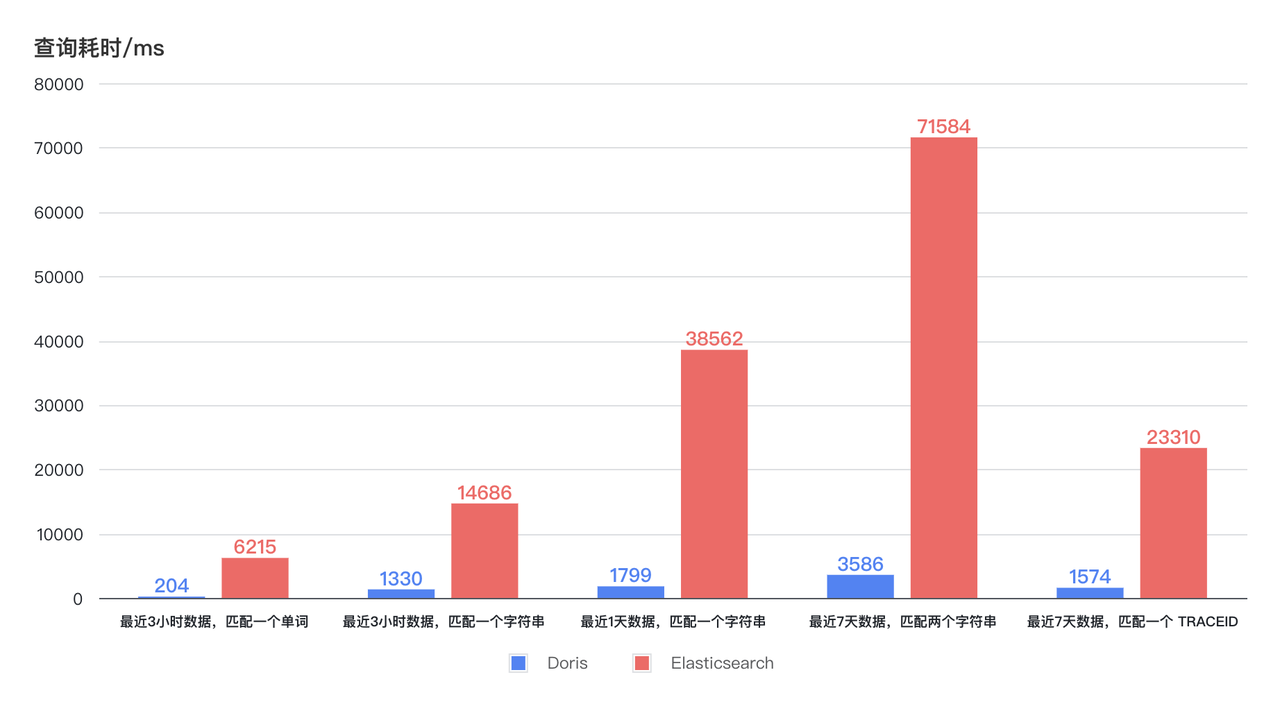
- Abfragen werden um das Elffache beschleunigt: Die neue Architektur führt zu einer um das Dutzendfache verbesserten Abfrageeffizienz bei geringerem CPU-Ressourcenverbrauch. Wie aus dem folgenden Diagramm ersichtlich ist, bleibt die Doris-Abfragezeit für den Protokollabruf in den letzten 3 Stunden, 1 Tag und 7 Tagen stabil und beträgt weniger als 4 Sekunden, und die schnellste Antwort kann innerhalb von 1 Sekunde erfolgen. Die Abfragezeit von Elasticsearch weist große Schwankungen auf, wobei die längste Zeit bis zu 75 Sekunden und selbst die kürzeste Zeit 6–7 Sekunden dauert. Bei geringerer Ressourcennutzung ist die Abfrageeffizienz von Doris mindestens elfmal so hoch wie die von Elasticsearch .
02 Yunxin-Datenplattform
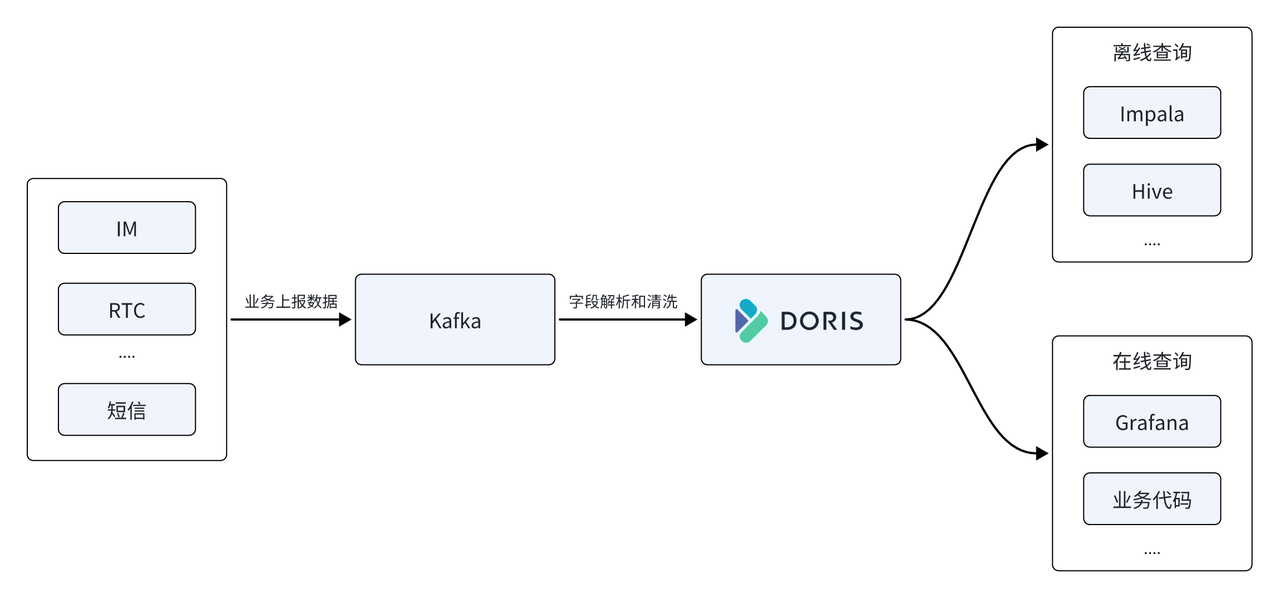
In der Yunxin-Datenplattform verwendet NetEase auch Apache Doris, um die Zeitreihendatenbank InfluxDB in der frühen Architektur zu ersetzen und sie als Kernspeicher- und Computer-Engine der Datenplattform zu verwenden, und Apache Doris bietet einheitliche Offline- und Echtzeit-Abfragedienste.
- Unterstützt das Schreiben mit hohem Durchsatz: durchschnittlicher Online-Schreibverkehr von 500 M/s, Spitzenwert 1 GB/s, InfluxDB nutzt 22 Server und die CPU-Ressourcenauslastung beträgt etwa 50 %, während Doris nur 11 Maschinen verwendet und die CPU-Auslastung etwa 50 % beträgt Der Gesamtressourcenverbrauch beträgt nur die Hälfte des vorherigen .
- Speicherressourcen um 67 % eingespart: 11 physische Doris-Maschinen wurden verwendet, um 22 InfluxDBs zu ersetzen. Um den gleichen Datenumfang zu speichern, benötigt InfluxDB 150T Speicherplatz, während die Speicherung in Doris nur 50T Speicherplatz erfordert, was 67% an Speicherressourcen spart .
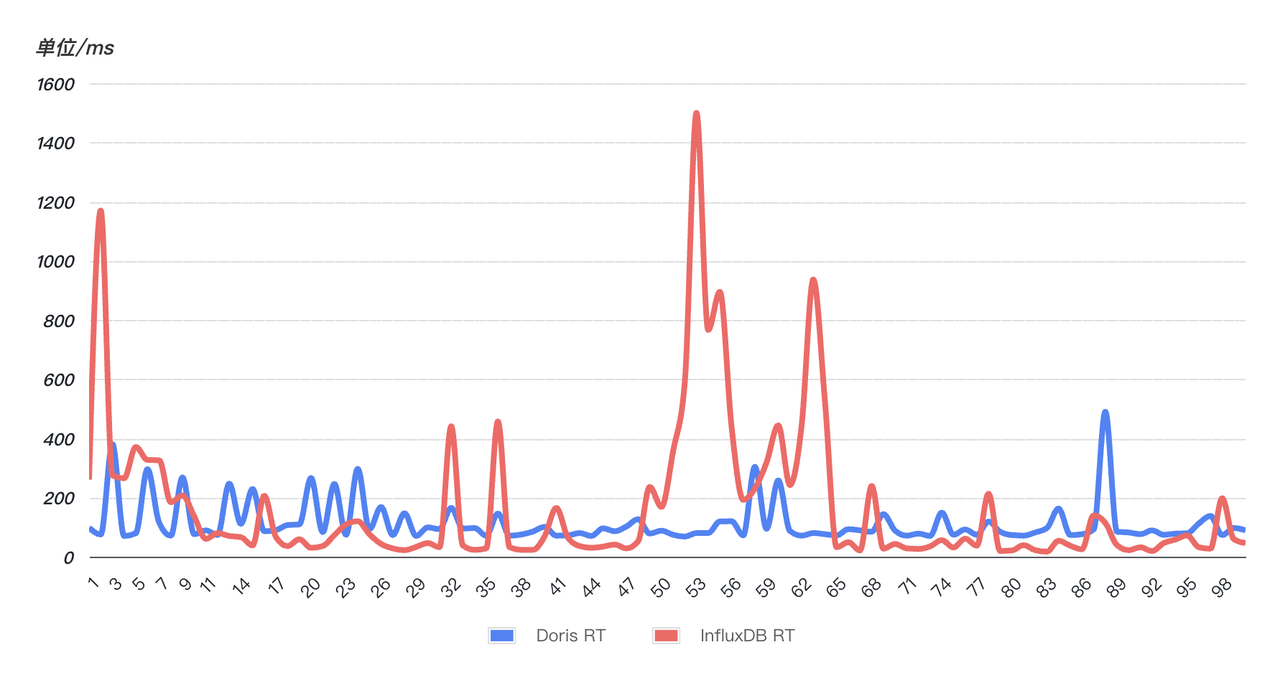
- Die Abfrageantwort ist schnell und stabiler: Um die Abfrageantwortgeschwindigkeit zu überprüfen, wurde eine Online-SQL zufällig ausgewählt (entspricht einer Zeichenfolge in den letzten 10 Minuten) und die SQL wurde 99 Mal kontinuierlich abgefragt. Wie aus der folgenden Abbildung ersichtlich ist, ist die Abfrageleistung von Doris (blau) stabiler als die von InfluxDB (rot). 99 Abfragen sind relativ stabil und weisen keine offensichtlichen Schwankungen auf Die Abfragezeit ist in die Höhe geschossen und die Abfragestabilität wurde erheblich beeinträchtigt.
Übung und Tuning
Im Prozess der Geschäftsimplementierung stieß NetEase auch auf einige Probleme und Herausforderungen. Ich möchte diese Gelegenheit nutzen, diese wertvollen Optimierungserfahrungen zusammenzustellen und zu teilen, in der Hoffnung, eine Anleitung und Hilfe für jedermann zu bieten.
01 Optimierung der Tabellenerstellung
Das Design des Datenbankschemas ist für die Leistung von entscheidender Bedeutung, und dies ist keine Ausnahme beim Umgang mit Protokoll- und Zeitreihendaten. Apache Doris bietet einige spezielle Optimierungsoptionen für diese beiden Szenarien. Daher ist es wichtig, diese Optimierungsoptionen während der Tabellenerstellung zu aktivieren. Hier sind die konkreten Optimierungsmöglichkeiten, die wir in der Praxis nutzen:
- Wenn Sie ein Zeitfeld vom Typ DATETIME als Primärschlüssel verwenden, wird die Geschwindigkeit der Abfrage der letzten n Protokolle erheblich verbessert.
- Nutzen Sie die RANGE-Partitionierung basierend auf Zeitfeldern und aktivieren Sie die dynamische Partitonierung, um Partitionen täglich automatisch zu verwalten und so die Flexibilität der Datenabfrage und -verwaltung zu verbessern.
- Was die Bucketing-Strategie betrifft, können Sie RANDOM für zufälliges Bucketing verwenden und die Anzahl der Buckets wird ungefähr auf das Dreifache der Gesamtzahl der Cluster-Festplatten festgelegt.
- Für Felder, die häufig abgefragt werden, wird empfohlen, Indizes zu erstellen, um die Abfrageeffizienz zu verbessern. Für Felder, die einen Volltextabruf erfordern, sollte ein geeigneter Parser für Wortsegmentierungsparameter angegeben werden, um die Genauigkeit und Effizienz des Abrufs sicherzustellen.
- Für Log- und Zeitreihenszenarien kommt eine speziell optimierte Zeitreihenkomprimierungsstrategie zum Einsatz.
- Durch die Verwendung der ZSTD-Komprimierung können bessere Komprimierungseffekte erzielt und Speicherplatz gespart werden.
CREATE TABLE log
(
ts DATETIME,
host VARCHAR(20),
msg TEXT,
status INT,
size INT,
INDEX idx_size (size) USING INVERTED,
INDEX idx_status (status) USING INVERTED,
INDEX idx_host (host) USING INVERTED,
INDEX idx_msg (msg) USING INVERTED PROPERTIES("parser" = "unicode")
)
ENGINE = OLAP
DUPLICATE KEY(ts)
PARTITION BY RANGE(ts) ()
DISTRIBUTED BY RANDOM BUCKETS 250
PROPERTIES (
"compression"="zstd",
"compaction_policy" = "time_series",
"dynamic_partition.enable" = "true",
"dynamic_partition.create_history_partition" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-7",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "250"
);
02 Optimierung der Clusterkonfiguration
FE-Konfiguration
# 开启单副本导入提升导入性能
enable_single_replica_load = true
# 更加均衡的tablet分配和balance测量
enable_round_robin_create_tablet = true
tablet_rebalancer_type = partition
# 频繁导入相关的内存优化
max_running_txn_num_per_db = 10000
streaming_label_keep_max_second = 300
label_clean_interval_second = 300
BE-Konfiguration
write_buffer_size=1073741824
max_tablet_version_num = 20000
max_cumu_compaction_threads = 10(cpu的一半)
enable_write_index_searcher_cache = false
disable_storage_page_cache = true
enable_single_replica_load = true
streaming_load_json_max_mb=250
03 Optimierung des Stream-Load-Imports
In Spitzengeschäftszeiten ist die Yunxin-Datenplattform mit über 1 Million Schreib-TPS und 1 GB/s Schreibverkehr konfrontiert, was zweifellos extrem hohe Anforderungen an die Systemleistung stellt. Da es jedoch auf der Geschäftsseite viele kleine gleichzeitige Tabellen gibt und die Abfrageseite extrem hohe Echtzeitanforderungen an Daten stellt, ist es unmöglich, die Stapelverarbeitung in kurzer Zeit zu einem ausreichend großen Stapel zu akkumulieren. Nach der gemeinsamen Durchführung einer Reihe von Optimierungen mit Geschäftspartnern ist Stream Load immer noch nicht in der Lage, Daten in Kafka schnell zu verbrauchen, was zu einem immer schwerwiegenderen Datenrückstand in Kafka führt.
Nach eingehender Analyse wurde festgestellt, dass das Datenimportprogramm auf Unternehmensseite während der Spitzenzeit des Geschäfts unter Leistungsengpässen litt, die sich hauptsächlich in der übermäßigen Auslastung von CPU- und Speicherressourcen widerspiegelten. Die Leistung auf Doris-Seite hat jedoch noch keinen nennenswerten Engpass erlebt, die Reaktionszeit von Stream Load zeigt jedoch einen klaren Aufwärtstrend.
Da das Geschäftsprogramm Stream Load synchron aufruft, bedeutet dies, dass sich die Reaktionsgeschwindigkeit von Stream Load direkt auf die Gesamteffizienz der Datenverarbeitung auswirkt. Wenn daher die Antwortzeit einer einzelnen Stream-Last effektiv reduziert werden kann, wird der Durchsatz des gesamten Systems erheblich verbessert.
Nach der Kommunikation mit Studenten der Apache Doris-Community erfuhr ich, dass Doris zwei wichtige Optimierungen der Importleistung für Protokoll- und Zeitszenarien eingeführt hat:
- Import einer einzelnen Kopie: Schreiben Sie zuerst in eine Kopie, und andere Kopien ziehen Daten aus der ersten Kopie. Mit dieser Methode kann der Mehraufwand vermieden werden, der durch wiederholtes Sortieren und Indexerstellen mehrerer Kopien entsteht.
- Einzel-Tablet-Import: Im Vergleich zur Schreibmethode, bei der Daten im Normalmodus auf mehrere Tablets verteilt werden, kann eine Strategie angewendet werden, bei der jeweils nur auf ein einzelnes Tablet geschrieben wird. Diese Optimierung reduziert die Anzahl kleiner Dateien und den beim Schreiben entstehenden E/A-Overhead und verbessert so die Gesamteffizienz des Imports. Diese Funktion kann aktiviert werden, indem
load_to_single_tabletder Parameter während des Imports auf gesetzt wird.true
Nach der Optimierung mit den oben genannten Methoden wurde die Importleistung deutlich verbessert:
- Die Geschwindigkeit des Kafka-Konsums wird um mehr als das Zweifache erhöht
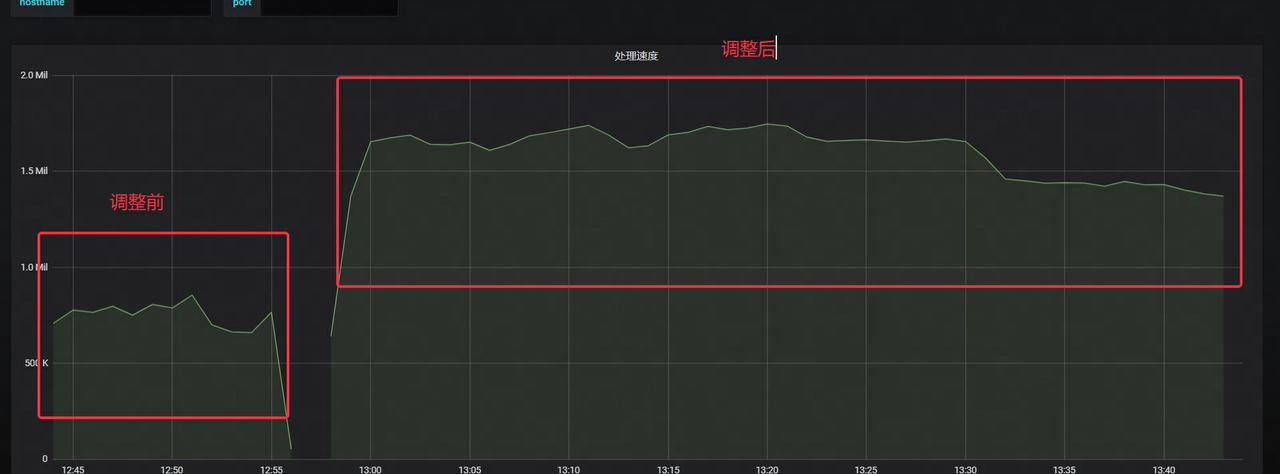
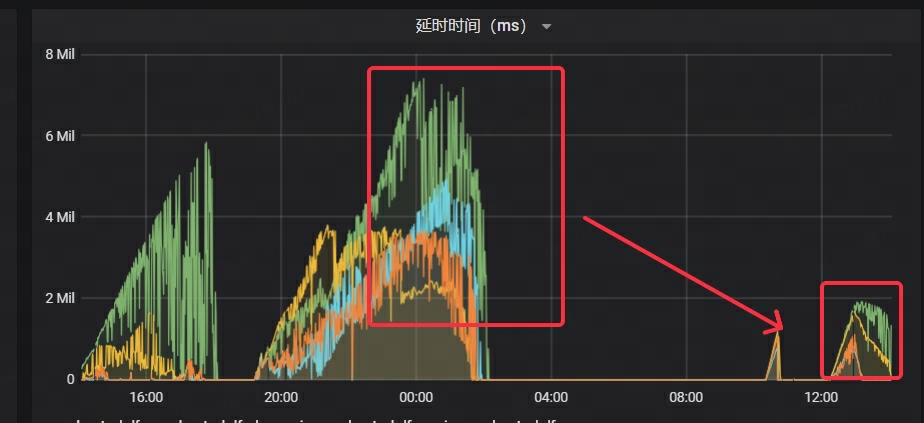
- Die Latenz von Kafka ist deutlich gesunken, auf nur noch ein Viertel der ursprünglichen Zeit
- Die RT der Stream-Last wird um etwa 70 % reduziert
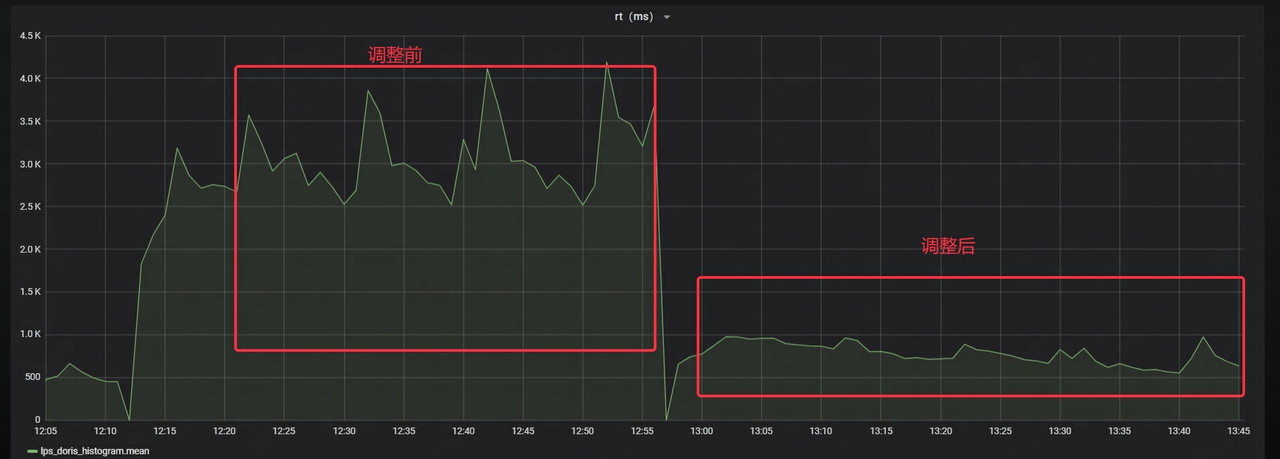
NetEase führte vor dem offiziellen Start außerdem umfangreiche Stresstests und einen Graustufen-Testbetrieb durch. Nach kontinuierlichen Optimierungsarbeiten konnte schließlich sichergestellt werden, dass das System in großen Szenarien stabil online laufen kann, was eine starke Unterstützung für das Unternehmen darstellt.
1. Stream-Ladezeitüberschreitung:
Zu Beginn des Stresstests gab es ein Problem mit häufigen Zeitüberschreitungen und Fehlerberichten beim Datenimport, und wenn der Prozess- und Clusterstatus normal war, konnte die Überwachung die BE-Metrikdaten nicht normal erfassen.
Erhalten Sie den Stapel von Doris BE über Pstack und analysieren Sie den Stapel mit PT-PMT. Es wurde festgestellt, dass der Hauptgrund darin lag, dass beim Initiieren einer Anfrage durch den Client weder die HTTP-Chunked-Kodierung noch die Content-Length festgelegt waren, was dazu führte, dass Doris fälschlicherweise glaubte, die Datenübertragung sei noch nicht beendet, und somit in der Warteschleife blieb Zustand. Nach dem Hinzufügen der Chunked-Codierungseinstellung auf dem Client verlief der Datenimport wieder normal.
2. Die von Stream Load auf einmal importierte Datenmenge überschreitet den Schwellenwert:
Das Problem wird durch Erhöhen streaming_load_json_max_mbdes Parameters auf 250 MB (Standard 100 MB) gelöst.
3. Unzureichende Kopien und Schreibfehler: alive replica num 0 < quorum replica num 1
Es show backendswurde festgestellt, dass ein BE einen abnormalen Status hat und als OFFLINE angezeigt wird. Überprüfen Sie die entsprechende be_customKonfigurationsdatei und stellen Sie fest, dass sie vorhanden ist broken_storage_path. Eine weitere Überprüfung des BE-Protokolls ergab, dass die Fehlermeldung „zu viele offene Dateien“ anzeigte. Dies bedeutet, dass die Anzahl der vom BE-Prozess geöffneten Dateihandles das vom System festgelegte Maximum überschritten hat, was dazu führte, dass der E/A-Vorgang fehlschlug.
Wenn das Doris-System diese Anomalie erkennt, markiert es die Festplatte als unbrauchbar. Da die Tabelle mit einer Einzelkopie-Strategie konfiguriert ist, können bei einem Problem mit der Festplatte, auf der sich die einzige Kopie befindet, die Daten nicht weiter geschrieben werden, da die Anzahl der Kopien nicht ausreicht.
Daher wurde die maximale Öffnungsgrenze des Prozesses FD auf 1 Million angepasst, be_custom.confdie Konfigurationsdatei gelöscht, der BE-Knoten neu gestartet und der Dienst schließlich den normalen Betrieb wieder aufgenommen.
4. FE-Speicherjitter
Beim Business-Graustufentest trat das Problem auf, dass keine Verbindung zu FE hergestellt werden konnte. Bei der Überprüfung der Überwachungsdaten wurde festgestellt, dass der 32G-Speicher der JVM erschöpft war und das BDB-Dateiverzeichnis im FE-Metaverzeichnis ungewöhnlich auf 50G erweitert wurde.
Da das Unternehmen hochgradig gleichzeitige Stream-Load-Datenimportvorgänge durchgeführt hat und FE während des Importvorgangs relevante Load-Informationen aufzeichnet, betragen die bei jedem Import generierten Speicherinformationen etwa 200 KB. Die Reinigungszeit dieser Speicherinformationen streaming_label_keep_max_secondwird durch Parameter gesteuert. Der Standardwert beträgt 12 Stunden. Nach dem Einstellen auf 5 Minuten wird jedoch festgestellt, dass der Speicher nicht erschöpft ist Jitter entsprechend dem 1-Stunden-Zyklus und die Spitzenspeicherauslastung Die Rate erreicht 80 %. Nach der Analyse des Codes haben wir festgestellt, dass der Thread zum Bereinigen von Etiketten label_clean_interval_secondjedes zweite Mal ausgeführt wird. Der Standardwert beträgt 1 Stunde. Nach der Anpassung auf 5 Minuten ist der FE-Speicher sehr stabil.
04 Abfrageoptimierung
Als die Lingxi-Eagle-Überwachungsplattform Abfragetests durchführte, wurde vermutet, dass sie Ergebnisse las, die die Übereinstimmungsbedingungen nicht erfüllten. Dieses Phänomen entsprach offensichtlich nicht der erwarteten Abruflogik. Wie im ersten Datensatz unten gezeigt:
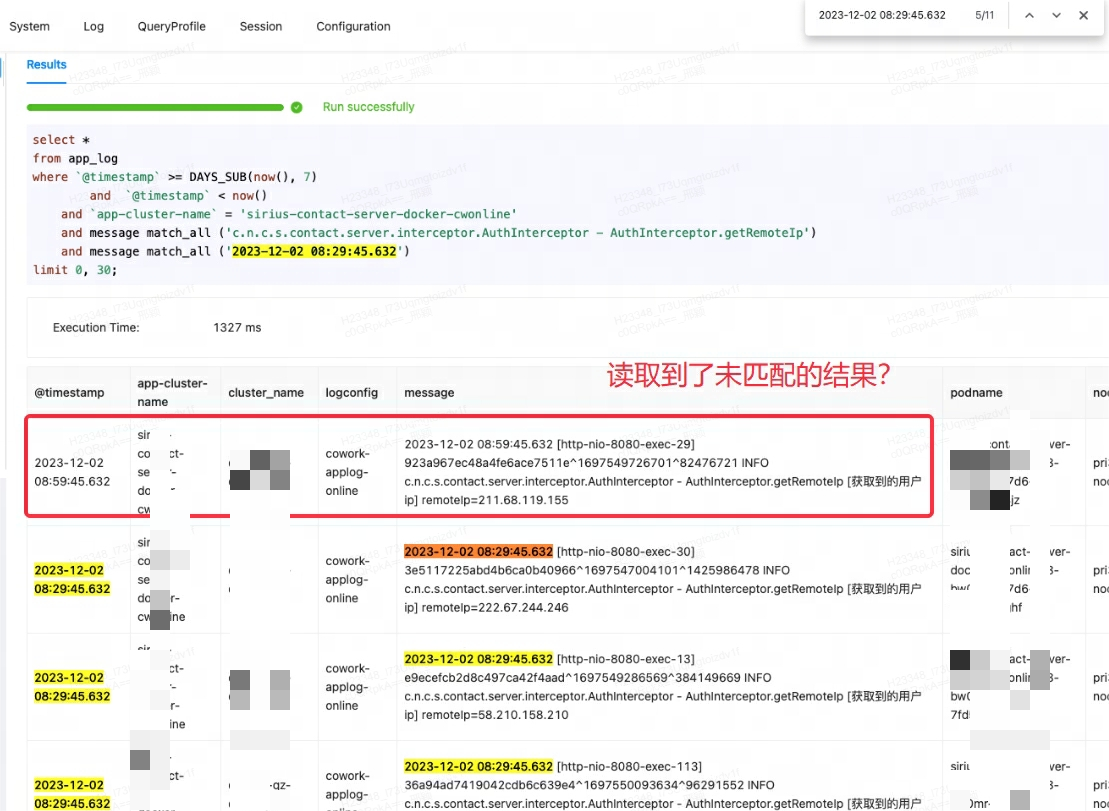
Zuerst dachte ich fälschlicherweise, dass es sich um einen Doris-Fehler handelte, also habe ich versucht, nach ähnlichen Problemen und Problemumgehungen zu suchen. Nach Rücksprache mit Community-Mitgliedern und sorgfältiger Durchsicht offizieller Dokumente stellte sich jedoch heraus, dass die Ursache des Problems in match_alleinem Missverständnis des Nutzungsszenarios lag.
match_allDas Arbeitsprinzip besteht darin, dass ein Abgleich durchgeführt werden kann, solange eine Wortsegmentierung vorhanden ist und die Wortsegmentierung auf Leerzeichen oder Satzzeichen basiert . In diesem Fall match_allwird die „29“ in mit der „29“ im nachfolgenden Inhalt des ersten Datensatzes abgeglichen, wodurch unerwartete Ergebnisse ausgegeben werden.
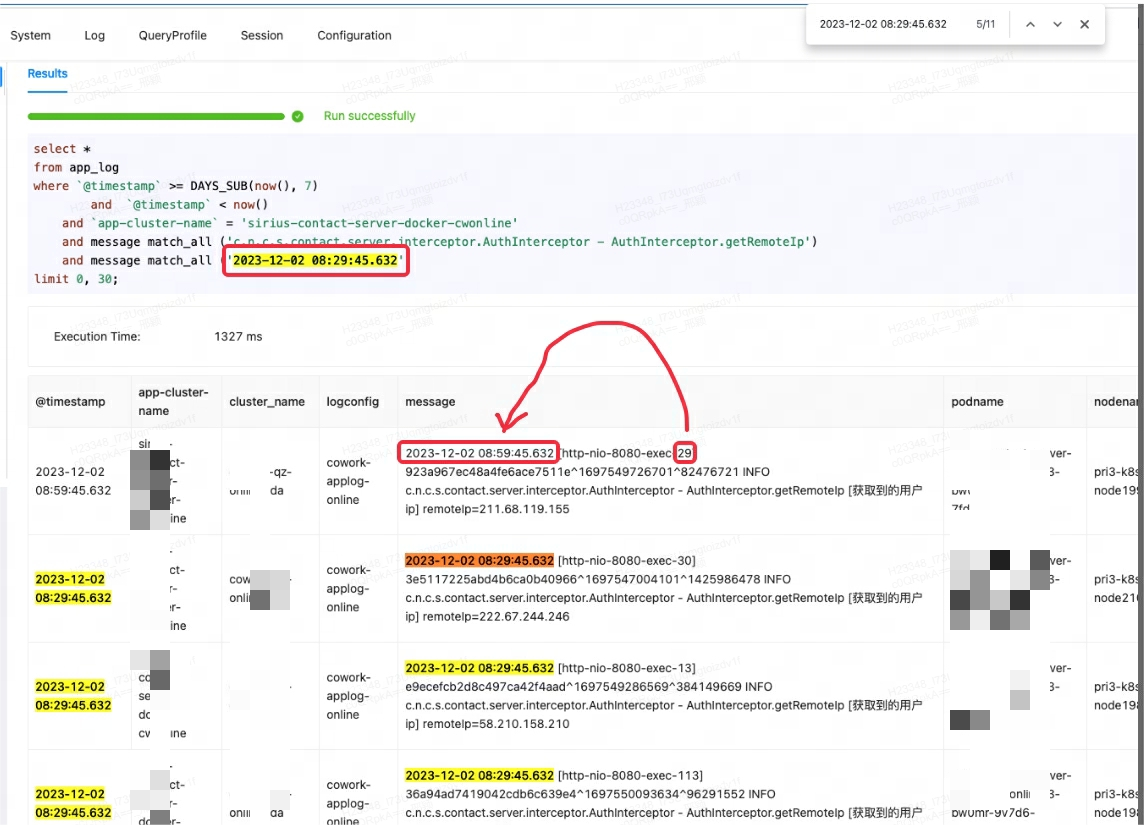
MATCH_PHRASEIn diesem Fall besteht die richtige Methode darin , den Abgleich zu verwenden , MATCH_PHRASEder die Bestellanforderungen im Text erfüllen kann.
-- 1.4 logmsg中同时包含keyword1和keyword2的行,并且按照keyword1在前,keyword2在后的顺序
SELECT * FROM table_name WHERE logmsg MATCH_PHRASE 'keyword1 keyword2';
Wenn Sie MATCH_PHRASEden Abgleich verwenden, müssen Sie ihn beim Erstellen des Index angeben support_phrase. Andernfalls führt das System einen vollständigen Tabellenscan und einen harten Abgleich durch, was zu einer schlechten Abfrageeffizienz führt.
INDEX idx_name4(column_name4) USING INVERTED PROPERTIES("parser" = "english|unicode|chinese", "support_phrase" = "true")
support_phraseFür Tabellen, die bereits Daten geschrieben haben, können Sie , wenn Sie es aktivieren möchten , DROP INDEXden alten Index löschen und dann ADD INDEXeinen neuen Index hinzufügen. Dieser Vorgang wird inkrementell für die vorhandene Tabelle ausgeführt, ohne die Daten der gesamten Tabelle neu zu schreiben, wodurch die Effizienz des Vorgangs sichergestellt wird.
Im Vergleich zu Elasticsearch ist die Indexverwaltungsmethode von Doris flexibler und kann je nach Geschäftsanforderungen schnell Indizes hinzufügen oder löschen, was mehr Komfort und Flexibilität bietet.
Abschluss
Die Einführung von Apache Doris erfüllt effektiv die Anforderungen von NetEase an Protokolle und Zeitszenarien und löst effektiv die Probleme der hohen Speicherkosten und der geringen Abfrageeffizienz der frühen Protokollverarbeitungs- und Analyseplattformen von NetEase Lingxi Office und NetEase Cloud Letter.
In tatsächlichen Anwendungen hat Apache Doris einen durchschnittlichen Online-Schreibverkehr von 500 MB/s und einen Spitzenwert von über 1 GB/s bei geringeren Serverressourcen. Gleichzeitig wurde die Abfrageantwort im Vergleich zu Elasticsearch erheblich verbessert und die Abfrageeffizienz um mindestens das Elffache gesteigert. Darüber hinaus verfügt Doris über ein höheres Komprimierungsverhältnis und kann im Vergleich zu früher 70 % der Speicherressourcen einsparen.
Abschließend möchte ich mich besonders beim technischen Team von SelectDB für die kontinuierliche Unterstützung bedanken. Auch in Zukunft wird NetEase Apache Doris weiter fördern und in anderen Big-Data-Szenarien von NetEase eingehend anwenden. Gleichzeitig freuen wir uns auch auf einen intensiven Austausch mit weiteren Business-Teams, die an Doris interessiert sind, um gemeinsam die Entwicklung von Apache Doris voranzutreiben.
Open-Source-Beiträge
Während des Prozesses der Geschäftsimplementierung und Problembehebung übten die NetEase-Studenten aktiv den Open-Source-Geist und steuerten eine Reihe wertvoller PRs zur Apache Doris-Community bei, um die Entwicklung und den Fortschritt der Community zu fördern:
- Fehlerbehebung beim Stream-Laden
- Stream-Load-Code-Optimierung
- Heiße und kalte Schichtung, um eine geeignete Rowset-Optimierung zu finden
- Durch die Warm- und Kaltschichtung wird die ungültige Durchquerung reduziert
- Optimierung der abgestuften Warm- und Kalt-Sperrintervalle
- Optimierung der heiß- und kaltgeschichteten Datenfilterung
- Optimierung der Beurteilung der Warm- und Kaltschichtungskapazität
- Optimierung der hierarchischen Warm- und Kaltsortierung
- Standardisierung der FE-Fehlerberichterstattung
- Neue
array_aggFunktion - Fehlerbehebung bei der Aggregationsfunktion
- Fehlerbehebung im Ausführungsplan
- TaskGroupManager-Optimierung
- BE Crash Repair
- Dokumentänderung:
- https://github.com/apache/doris/pull/26958
- https://github.com/apache/doris/pull/26410
- https://github.com/apache/doris/pull/25082
- https://github.com/apache/doris/pull/25075
- https://github.com/apache/doris/pull/31882
- https://github.com/apache/doris/pull/30654
- https://github.com/apache/doris/pull/30304
- https://github.com/apache/doris/pull/29268