
Autor: Li Ruifeng
Papiertitel
StreamE: Leichte Aktualisierungen von Darstellungen für zeitliche Wissensgraphen in Streaming-Szenarien
Papierquelle
KUH 2023
Link zum Papier
https://dl.acm.org/doi/10.1145/3539618.3591772
Code-Link
https://github.com/zjs123/StreamE_MindSpore
Als Open-Source-KI-Framework bietet MindSpore Industrie, Universitätsforschung und Entwicklern ein umfassendes Szenario für die Zusammenarbeit zwischen Geräten, Edge und Cloud, minimalistische Entwicklung, ultimative Leistung, extrem umfangreiches KI-Vortraining, minimalistische Entwicklung sowie eine sichere und vertrauenswürdige Lösung Erfahrung, 2020.3.28 Open Source hat mehr als 5 Millionen Downloads, wurde an über 100 Top-Universitäten unterrichtet und ist über HMS auf über 5000 Apps erhältlich und ist in den Bereichen KI-Computing, Finanzen, intelligente Fertigung, Finanzen, Cloud, Wireless, Datenkommunikation, Energie, Verbraucher 1+8+N, Smart Cars und andere End-Edge-Cloud-Car-Szenarien weit verbreitet ist die Open-Source-Software mit dem höchsten Gitee-Index. Jeder ist herzlich willkommen, an Open-Source-Beiträgen, Kits, Model-Crowd-Intelligence, Brancheninnovationen und -anwendungen, Algorithmusinnovationen, akademischer Zusammenarbeit, KI-Buchkooperation usw. teilzunehmen und Ihre Anwendungsfälle auf der Cloud-Seite, Geräteseite, Edge-Seite und anderen beizutragen Sicherheitsbereiche.
Mit der umfassenden Unterstützung von SunSilicon MindSpore aus der wissenschaftlichen und technologischen Gemeinschaft, der akademischen Welt und der Industrie machten KI-Artikel, die auf SunSilicon MindSpore basieren, im Jahr 2023 7 % aller KI-Frameworks aus und belegten damit zwei Jahre in Folge den zweiten Platz weltweit. Vielen Dank an CAAI und alle Universitäten Mit der Unterstützung der Lehrkräfte werden wir weiterhin hart zusammenarbeiten, um KI-Forschung und -Innovation zu betreiben. Die MindSpore-Community unterstützt die Forschung zu erstklassigen Konferenzbeiträgen und erstellt weiterhin originelle KI-Ergebnisse. Ich werde gelegentlich einige hervorragende Artikel zur Förderung und Interpretation auswählen. Ich hoffe, dass mehr Experten aus Industrie, Wissenschaft und Forschung mit Shengsi MindSpore zusammenarbeiten, um die KI-Innovation und KI-Anwendungen weiter zu fördern ist von Shengsi. Für den 15. Artikel in der MindSpore AI Top-Konferenzbeitragsreihe habe ich mich entschieden, einen Beitrag des Lehrerteams Shao Jie von der School of Computer Science an der University of Electronic Science and Technology of China zu interpretieren allen Experten, Professoren und Kommilitonen für ihre Beiträge zu danken. Dieser Artikel wurde auf Zhihu hochgeladen. Klicken Sie hier, um den Originaltext anzuzeigen.
MindSpore zielt darauf ab, drei Hauptziele zu erreichen: einfache Entwicklung, effiziente Ausführung und vollständige Szenarioabdeckung. Durch die Nutzungserfahrung entwickelt sich MindSpore, ein Deep-Learning-Framework, schnell weiter und das Design seiner verschiedenen APIs wird ständig in eine vernünftigere, vollständigere und leistungsfähigere Richtung optimiert. Darüber hinaus unterstützen verschiedene Entwicklungstools, die ständig aus Shengsi hervorgehen, dieses Ökosystem dabei, komfortablere und leistungsfähigere Entwicklungsmethoden zu erstellen, wie z. B. MindSpore Insight, das die Modellarchitektur in Form eines Diagramms darstellen und auch verschiedene Aspekte dynamisch überwachen kann Änderungen an Indikatoren und Parametern machen den Entwicklungsprozess komfortabler.
01
Forschungshintergrund
Die Einbettungsmethode für zeitliche Wissensgraphen zielt darauf ab, die Vektordarstellung der Elemente im zeitlichen Wissensgraphen auf der Grundlage der Beibehaltung der Zeitlichkeit des zeitlichen Wissensgraphen zu lernen. Obwohl bestehende Arbeiten zeitliche Wissensgraphen als niedrigdimensionale Vektoren darstellen können, gehen diese Arbeiten davon aus, dass zu zeitlichen Wissensgraphen kein neues Wissen hinzugefügt wird, was offensichtlich unvernünftig ist. Das Wissen in der realen Welt wird ständig aktualisiert, sodass dem Wissensgraphen kontinuierlich neues Wissen hinzugefügt wird. Dieses Szenario wird als Flow-Szenario bezeichnet. Bestehende Arbeiten sind bei der Anwendung auf Streaming-Szenarien vor allem mit den folgenden drei Problemen konfrontiert:
(1) Erstens sammeln sich im Wissensgraphen weiterhin neue Entitäten an, wenn das Wissen aktualisiert wird. Vorhandene Arbeiten lernen direkt die feste Einbettungsdarstellung jeder Entität, sodass sie keine Einbettungsdarstellungen für neue Entitäten generieren können.
(2) In der realen Welt treten ständig verschiedene Ereignisse auf, was zu sehr häufigen Aktualisierungen des Wissens führt. Bei bestehenden Arbeiten muss die eingebettete Darstellung des aktuellen Moments in jedem Moment von Grund auf neu generiert werden, was ihre Anwendung in der Realität erschwert -Lebensbereiche, die eine schnelle Reaktion erfordern, wie beispielsweise Krisenfrühwarnsysteme.
(3) Bestehende Arbeiten können nur Entitätseinbettungsdarstellungen mit relevanten Wissenszeitstempeln erhalten. Anforderungen in der realen Welt werden jedoch jederzeit generiert, und vorhandene Arbeiten geben bis zur nächsten Wissensaktualisierung immer die gleiche Einbettungsdarstellung zurück, was dazu führt, dass das Modell in diesem Zeitraum die gleiche Reaktion ausführt, was offensichtlich nicht richtig ist.
Obwohl bestehende Arbeiten einige Erfolge erzielt haben, kann keines davon auf Streaming-Szenarien angewendet werden, die in der realen Welt sehr verbreitet sind (z. B. Empfehlungssysteme, Krisenwarnsysteme usw.).
02
Teamvorstellung
Der Erstautor der Arbeit, Zhang Jiasheng, ist Doktorand im zweiten Jahr an der School of Computer Science der University of Electronic Science and Technology of China. Zu seinen Forschungsinteressen gehören dynamisches Graphendarstellungslernen, sequentielle Wissensgraphen und raumzeitliches Data Mining . Bisher wurden insgesamt 5 Artikel veröffentlicht, darunter 2 Konferenzbeiträge der CCF-Kategorie A, 1 Konferenzbeitrag der CCF-Kategorie B und C und 1 Zeitschriftenbeitrag in der ersten Region der Chinesischen Akademie der Wissenschaften. Er hat sich außerdem für 3 beworben nationale Erfindungspatente und 2 Software-Urheberrechte. Er leitete den Abschluss des Schlüsselprojekts des Innovations- und Unternehmertums-Seedling-Projekts der Abteilung für Wissenschaft und Technologie der Provinz Sichuan, „Forschung und Anwendung des Lernmodells zur Darstellung von Wissensgraphen unter Anleitung von sequentiellem Wissen“, und wurde in die DiDi-Zukunft aufgenommen Gemeinsames Talentschulungsprojekt von Eliteschule und Unternehmen. Er hat zahlreiche akademische Stipendien der University of Electronic Science and Technology of China und die Titel „Excellent Graduate Student“ und „Advanced Individual in Scientific and Technological Innovation“ gewonnen.
Dissertationsberater Shao Jie ist Professor und Doktorvater an der University of Electronic Science and Technology of China. Er hat mehr als 100 hochrangige wissenschaftliche Arbeiten veröffentlicht (einschließlich IEEE TKDE, IEEE TNNLS, IEEE TCYB, IEEE TMM, IEEE TGRS, IEEE). THMS, IEEE TCSVT, ACM TOIS und ACM-Zeitschriften wie TOMM und Konferenzen wie ACM MM, IEEE ICDE, VLDB, IJCAI und AAAI). Er leitete zwei allgemeine Projekte der National Natural Science Foundation of China und ein Schlüsselprojekt für Forschung und Entwicklung in der Provinz Sichuan. Als Leiter der Genossenschaftseinheit leitete er ein Schlüsselprojekt der National Natural Science Foundation of China -WAIM 2019, die vom Vorsitzenden des Programmausschusses der Computer Society of China empfohlene internationale Konferenz zum Thema Big Data. Gewann den zweiten Preis des Sichuan Provincial Science and Technology Progress Award 2021.
Das Future Media Research Center der University of Electronic Science and Technology of China, an dem sich der Autor des Artikels befindet, hat bestimmte Forschungen in Richtung multimodaler Wissensgraphen, zeitlicher Wissensgraphen und Konstruktion, Argumentation und Wissensgraphen durchgeführt Anwendung. Es gibt eine Reihe relevanter provinzieller, ministerieller und nationaler Projekte, die derzeit erforscht werden.
03
Einführung in die Arbeit
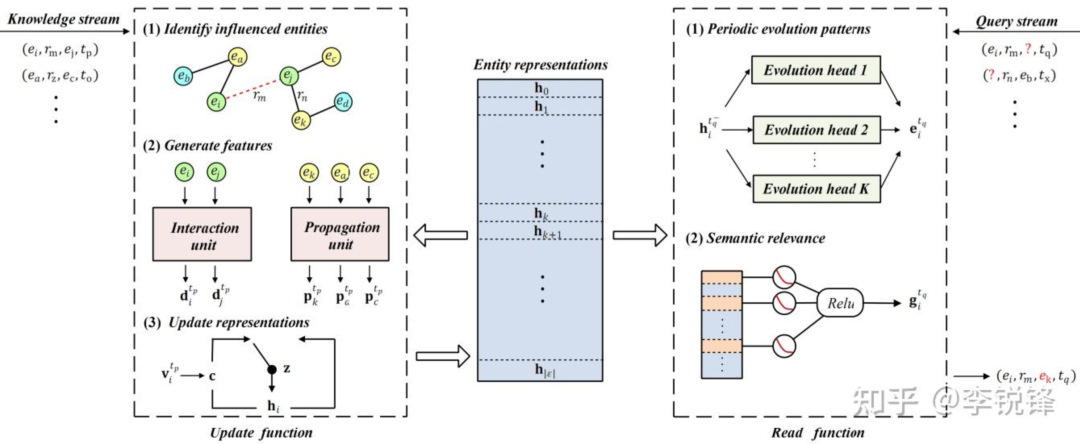
In diesem Artikel wird ein leichtgewichtiges Embedding Representation Framework (StreamE) vorgeschlagen, um das Problem zu lösen, dass frühere Einbettungsmethoden für zeitliche Wissensgraphen nicht auf Streaming-Szenarien angewendet werden können. Wir glauben, dass der Hauptgrund dafür, dass bestehende Werke schwierig an Streaming-Szenarien angepasst werden können, darin liegt, dass sie den Einbettungsgenerierungsprozess stark mit dem Vorhersageprozess koppeln, was es schwierig macht, Einbettungsdarstellungen jederzeit effizient zu generieren. Daher erreichen wir leichte Aktualisierungen eingebetteter Darstellungen in Streaming-Szenarien, indem wir die beiden oben genannten Prozesse entkoppeln.
Insbesondere verwenden wir die Entitätseinbettungsdarstellung als externes Speichermodul, um die historische Semantik zu bewahren und den Prozess der Generierung der Einbettungsdarstellung in eine Aktualisierungsfunktion und eine Lesefunktion zu entkoppeln. In der Aktualisierungsfunktion hört unser Framework auf das eingehende Wissen und aktualisiert die gespeicherte Einbettungsdarstellung basierend auf dem eingehenden Wissen. In der Lesefunktion hört unser Framework auf die Abfrageanforderungen des Benutzers und aktualisiert die gespeicherte Einbettungsdarstellung basierend auf dem eingehenden Wissen. Mithilfe der Trajektorienvorhersage werden zum Zeitpunkt der Abfrage Einbettungsdarstellungen generiert, um auf Abfrageanforderungen zu reagieren.
Um Entitätsdarstellungen genau zu aktualisieren, berücksichtigen wir sowohl die direkte Auswirkung neuen Wissens zwischen teilnehmenden Entitäten als auch die Ausbreitungswirkung neuen Wissens auf Entitäten, die an vergangenem verwandtem Wissen beteiligt sind. Für eine direkte Wirkung, inspiriert durch den Message-Passing-Mechanismus, glauben wir, dass Entitäten, die Wissen generieren, auch Informationen untereinander weitergeben. Gleichzeitig spiegelt die Semantik von Beziehungen die Korrelation zwischen Entitäten wider, weshalb wir Entitäten und Beziehungen dafür nutzen möchten Gleichzeitige Nachrichtenübermittlungsmechanismen zur Modellierung direkter Effekte. Da Pfade häufig zur Modellierung von Korrelationen höherer Ordnung zwischen Entitäten verwendet werden, glauben wir, dass Pfade, die aus neuem Wissen und in der Vergangenheit verwandten Entitäten bestehen, die Korrelation zwischen ihnen widerspiegeln können. Wir modellieren daher Ausbreitungseffekte pfadbasiert. Da der Gating-Mechanismus schließlich Informationen zur Aktualisierung adaptiv auswählen kann, verwenden wir ihn schließlich zur adaptiven Auswahl von Informationen mit direktem Einfluss und Ausbreitungseinfluss, um die eingebettete Darstellung der Entität zu aktualisieren.
Um den Entwicklungsverlauf der Entitätssemantik genau zu simulieren, haben wir zwei Aspekte berücksichtigt. Erstens weist die Semantik der meisten Entitäten zyklische Merkmale auf. Beispielsweise finden die Olympischen Spiele alle vier Jahre und der Europapokal alle zwei Jahre statt Zukunft. Zweitens haben wir herausgefunden, dass eine Entität nur mit einem Teil der Entitäten in der gesamten Entitätssammlung Wissen generiert und diese Entitäten natürlich starke Korrelationen aufweisen. Der zukünftige semantische Verlauf einer Entität sollte sich an die semantischen Änderungen ihrer zugehörigen Entitäten anpassen, um diese Korrelation aufrechtzuerhalten.
04
Experimentelle Ergebnisse
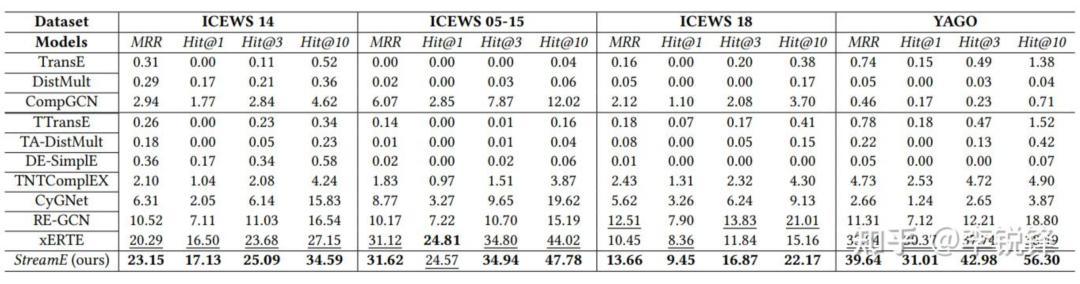
Wir haben die Wirksamkeit des auf Shengsi MindSpore implementierten StreamE-Frameworks bei der Aufgabe zur induktiven zukünftigen Linkvorhersage an vier Benchmark-Datensätzen überprüft. Wie in der Abbildung unten gezeigt, schnitt unser Framework bei allen Datensätzen besser ab sind Modelle mit besserer Leistung.
Gleichzeitig haben wir die Vorteile unseres vorgeschlagenen Frameworks in Bezug auf die Effizienz der eingebetteten Darstellungsgenerierung im Vergleich zu bestehenden Modellen überprüft. Wie in der folgenden Abbildung dargestellt, kann unser Framework ein sublineares Wachstum der Verbrauchszeit aufrechterhalten, wenn die Anzahl der Abfragen zunimmt, was deutlich effizienter ist als bestehende Modelle.

05
Zusammenfassung und Ausblick
In diesem Artikel untersuchen wir erstmals die technischen Herausforderungen zeitlicher Wissensgraphen in Streaming-Szenarien und schlagen ein leichtes Framework StreamE zur Aktualisierung von Einbettungsdarstellungen in Streaming-Szenarien vor. Wir haben das StreamE-Framework mithilfe des Shengsi MindSpore-Frameworks implementiert und seine Vorteile in Bezug auf Effizienz und Genauigkeit durch umfangreiche Experimente nachgewiesen. Als inländisches Deep-Learning-Framework bietet MindSpore eine große Anzahl sehr nützlicher Operatoren, was den Framework-Implementierungsprozess erheblich vereinfacht und gleichzeitig große Vorteile bei der Argumentationseffizienz bietet. Die Shengsi MindSpore-Community ist sehr aktiv und die Vorschläge anderer Benutzer und Huawei-Entwickler haben uns bei der Implementierung des Frameworks sehr geholfen. Wir glauben, dass Shengsi MindSpore unter der Anleitung einer so aktiven und professionellen Community immer perfekter werden wird.
Ein in den 1990er Jahren geborener Programmierer hat eine Videoportierungssoftware entwickelt und in weniger als einem Jahr über 7 Millionen verdient. Das Ende war sehr bestrafend! Google bestätigte Entlassungen, die den „35-jährigen Fluch“ chinesischer Programmierer in den Flutter-, Dart- und Teams- Python mit sich brachten stark und wird von GPT-4.5 vermutet; Tongyi Qianwen Open Source 8 Modelle Arc Browser für Windows 1.0 in 3 Monaten offiziell GA Windows 10 Marktanteil erreicht 70 %, Windows 11 GitHub veröffentlicht weiterhin KI-natives Entwicklungstool GitHub Copilot Workspace JAVA ist die einzige starke Abfrage, die OLTP+OLAP verarbeiten kann. Dies ist das beste ORM. Wir treffen uns zu spät.