
Autor: Li Ruifeng
Papiertitel
Prototypenlernen für automatisches Auschecken
Papierquelle
IEEE TMM
Link zum Papier
https://ieeexplore.ieee.org/document/10049664/
Code-Link
https://github.com/msfuxian/PLACO
Als Open-Source-KI-Framework bietet MindSpore Industrie, Universitätsforschung und Entwicklern ein umfassendes Szenario für die Zusammenarbeit zwischen Geräten, Edge und Cloud, minimalistische Entwicklung, ultimative Leistung, extrem umfangreiches KI-Vortraining, minimalistische Entwicklung sowie eine sichere und vertrauenswürdige Lösung Erfahrung, 2020.3.28 Open Source hat mehr als 5 Millionen Downloads unterstützt, ist in die Lehre von über 100 Universitäten eingestiegen und ist über HMS auf über 5000 Apps erhältlich Entwickler und ist in den Bereichen KI-Rechenzentrum, Finanzen, intelligente Fertigung, Finanzen, Cloud, Wireless, Datenkommunikation, Energie, Verbraucher 1+8+N, intelligente Autos und andere End-Edge-Cloud-Autoszenarien weit verbreitet verwendet und ist die Open-Source-Software mit dem höchsten Gitee-Index. Jeder ist herzlich willkommen, an Open-Source-Beiträgen, Kits, Model-Crowd-Intelligence, Brancheninnovationen und -anwendungen, Algorithmusinnovationen, akademischer Zusammenarbeit, KI-Buchkooperation usw. teilzunehmen und Ihre Anwendungsfälle auf der Cloud-Seite, Geräteseite, Edge-Seite und anderen beizutragen Sicherheitsbereiche.
Mit der umfassenden Unterstützung von SunSilicon MindSpore aus der wissenschaftlichen und technologischen Gemeinschaft, der akademischen Welt und der Industrie machten KI-Artikel, die auf SunSilicon MindSpore basieren, im Jahr 2023 7 % aller KI-Frameworks aus und belegten damit zwei Jahre in Folge den zweiten Platz weltweit. Vielen Dank an CAAI und alle Universitäten Mit der Unterstützung der Lehrkräfte werden wir weiterhin hart zusammenarbeiten, um KI-Forschung und -Innovation zu betreiben. Die MindSpore-Community unterstützt die Forschung zu erstklassigen Konferenzbeiträgen und erstellt weiterhin originelle KI-Ergebnisse. Ich werde gelegentlich einige hervorragende Artikel zur Förderung und Interpretation auswählen. Ich hoffe, dass mehr Experten aus Industrie, Wissenschaft und Forschung mit MindSpore zusammenarbeiten, um die ursprüngliche KI-Forschung zu fördern. Dieser Artikel ist von Shengsi MindSpore. Für den 16. Artikel der AI-Konferenzpapierreihe habe ich mich entschieden, einen Artikel des Teams von Dr. Wei Xiushen von der School of Computer Science and Engineering der Nanjing University of Science and Technology zu interpretieren Ich möchte mich bei allen Experten, Professoren und Kommilitonen für ihre Beiträge bedanken.
MindSpore zielt darauf ab, drei Hauptziele zu erreichen: einfache Entwicklung, effiziente Ausführung und vollständige Szenarioabdeckung. Durch die Nutzungserfahrung entwickelt sich MindSpore, ein Deep-Learning-Framework, schnell weiter und das Design seiner verschiedenen APIs wird ständig in eine vernünftigere, vollständigere und leistungsfähigere Richtung optimiert. Darüber hinaus unterstützen verschiedene Entwicklungstools, die ständig aus Shengsi hervorgehen, dieses Ökosystem dabei, komfortablere und leistungsfähigere Entwicklungsmethoden zu erstellen, wie z. B. MindSpore Insight, das die Modellarchitektur in Form eines Diagramms darstellen und auch verschiedene Aspekte dynamisch überwachen kann Änderungen an Indikatoren und Parametern machen den Entwicklungsprozess komfortabler.
In diesem Artikel geht es hauptsächlich um Probleme im Zusammenhang mit der Zielerkennung. Durch die Zielerkennung ist es möglich, Einzelhandelsprodukte verschiedener Kategorien und Mengen in einem Bild genau zu erkennen und schließlich eine Einkaufsliste zu erhalten, die der „Produktkategorie: Produktmenge“ entspricht. Ein Teil des Codes zur Zielerkennung kann auf der offiziellen Dokumentation von MindSpore oder dem von der Community bereitgestellten Code und den Modellen zur Zielerkennung basieren. Dadurch können die Anforderungen des Experiments dieses Artikels leicht umgesetzt werden, was sehr praktisch und schnell ist .
01
Forschungshintergrund
Die visuelle Abwicklung von Einzelhandelswaren ist ein Teilgebiet der Smart-Retail-Branche. Ihre häufigsten Anwendungsszenarien sind Bereiche mit unbemannten Kassen wie Supermärkten, Geschäften und Convenience-Stores. Kunden legen die Einzelhandelswaren, die sie kaufen möchten, auf die Kasse a Kameras mit fester Position erfassen Bilder dieser Einzelhandelsartikel, die ein automatisches visuelles Kassensystem durchlaufen, das Produktkategorien identifizieren und genau zählen kann, und schließlich eine vollständige Einkaufsliste mit dem Gesamtbetrag ausgibt.
Der Kern der visuellen Abrechnungsaufgabe für Einzelhandelsprodukte besteht darin, Einzelhandelsprodukte im Bild genau zu identifizieren und zu zählen. Bei dieser Aufgabe gibt es jedoch drei Hauptherausforderungen, nämlich umfangreiche Einzelhandelsproduktdaten, Domänenlücken zwischen einzelnen Produktbeispielen und Abrechnungsbildern und Produktkategorieunterschiede. Um diese Herausforderungen anzugehen, schlugen Wei et al. eine Basismethode für ein Objekterkennungs-Framework vor, das die Unterschiede und Lücken zwischen den beiden Domänen überbrückt, indem es Produkt-Checkout-Bilder aus segmentierten Einzelproduktbeispielen synthetisiert und rendert. In ähnlicher Weise verbessern IncreACO, DPNet und DPSNet die synthetische Rendering-Strategie von Wei et al., um eine bessere Domänenanpassungsfähigkeit zu erzielen und so die Verbesserung der ACO-Genauigkeit zu fördern. Darüber hinaus verwendet S2MC2 auch die Gradienteninversionsschicht als Methode zur Anpassung der Feature-Layer-Domäne und ersetzt so die synthetische Rendering-Strategie.
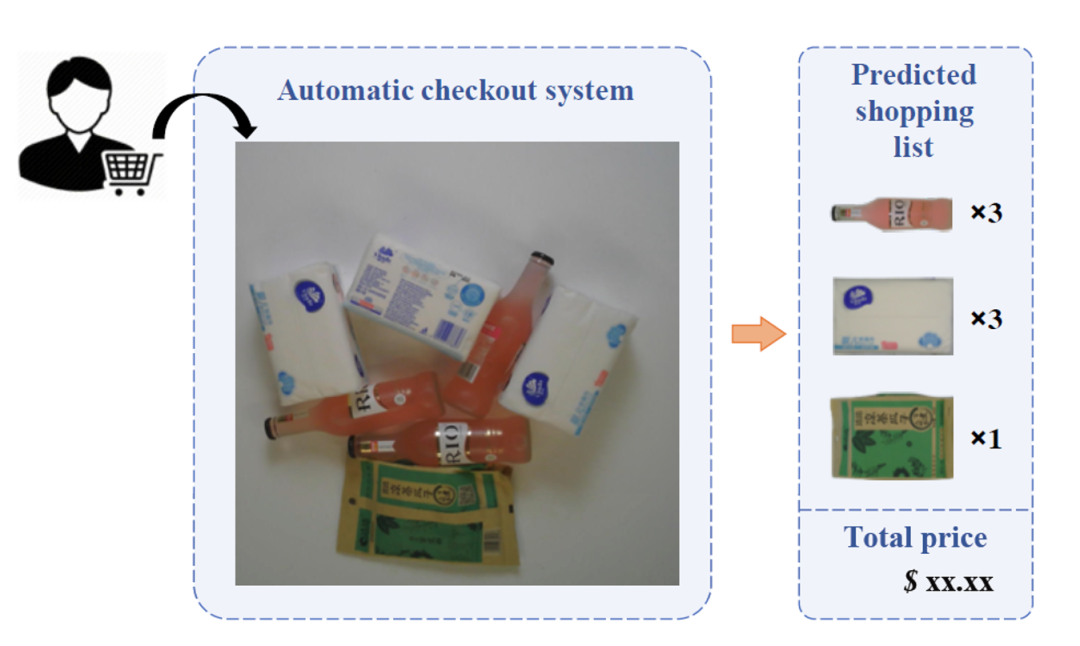
Abbildung 1 Schematische Darstellung der visuellen Abrechnung von Einzelhandelswaren
02
Teamvorstellung
Visual Intelligence & Perception (VIP)-Gruppe unter der Leitung von Professor Wei Xushen . Das Team hat in führenden internationalen Fachzeitschriften in verwandten Bereichen wie IEEE TPAMI, IEEE TIP, IEEE TNNLS, IEEE TKDE, Machine Learning Journal, „Chinese Science: Information Science“ usw. sowie auf führenden internationalen Konferenzen wie NeurIPS, CVPR, veröffentlicht. ICCV, ECCV, IJCAI, AAAI usw. Er hat mehr als fünfzig Artikel veröffentlicht und mit seinen Arbeiten insgesamt sieben Weltmeisterschaften in renommierten internationalen Wettbewerben im Bereich Computer Vision gewonnen, darunter DIGIX 2023, SnakeCLEF 2022, iWildCam 2020, iNaturalist 2019 und Apparent Personality Analysis 2016.
03
Einführung in die Arbeit
In diesem Artikel schlagen wir eine Methode namens „Prototype Learning for Retail Merchandise Visual Checkout (PLACO)“ vor, die versucht, Einzelartikelbeispiele (als Training) und das Abrechnungsbild (als Test) zu lösen, in der die Gesamtstruktur dargestellt ist Figur 2. Konkret ist ein Prototyp eine Vektordarstellung, die die Semantik einer Kategorie im visuellen Raum genau darstellt (d. h. eine echte Kategoriedarstellung), typischerweise implementiert durch kategoriespezifische Merkmalszentren. Ein weiterer Vorteil der Verwendung von Produktprototypen zur visuellen Abrechnung von Einzelhandelswaren besteht darin, dass sie nicht nur potenzielle Domänenunterschiede auflöst, sondern auch das Problem der Mehrfachansicht einzelner Produktbeispiele vermeidet. Kategorieprototypen stellen die Kategoriesemantik eines Produkts genauer dar als Beispielbilder mit einer oder mehreren Ansichten, was auch seine Allgemeingültigkeit und Robustheit beweist. Darüber hinaus haben wir ein Prototyp-Alignment-Modul als Lösung zur Domänenanpassung entworfen. Nachdem wir einzelne Produktbeispiele und Kategorieprototypen in der Siedlungsbilddomäne erhalten haben, erreichen wir eine Domänenanpassung, indem wir den Abstand zwischen homogenen Prototypen verringern und den Abstand zwischen heterogenen Prototypen vergrößern, um die Kompaktheit innerhalb der Kategorie und die Sparsamkeit zwischen den Kategorien zu verbessern.
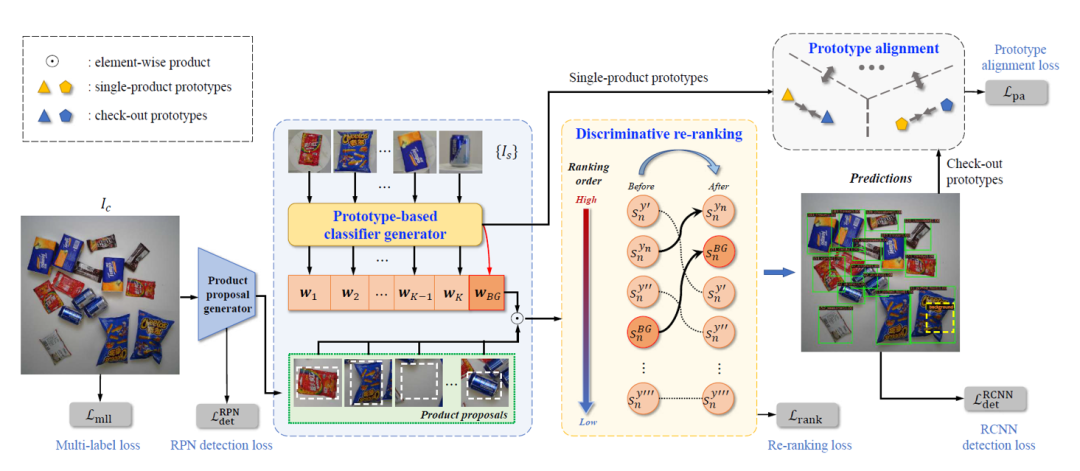
Abbildung 2 Schematische Darstellung des PLACO-Frameworks
Um die Unterscheidungsfähigkeit dieser erlernten Klassifikatoren weiter zu verbessern, entwickeln wir eine diskriminierende Neuordnungsmethode, um ihre Unterscheidungsfähigkeit durch Anpassen der Vorhersagewerte dieser Produktempfehlungen zu verbessern, siehe Abbildung 3. Konkret ordnen wir den Vorhersagewert der wahren Kategorie am höchsten ein, um die Vorhersagesicherheit zu verbessern, während wir den Hintergrundwert gemäß den Merkmalen des Hintergrundklassifikators, d. h. einer harten Neuordnungsstrategie, auf die zweite Position neu einordnen. Darüber hinaus führen wir unter Berücksichtigung der feinkörnigen Eigenschaften von Artikeln auch eine Slack-Variable als sanfte Neuordnungsstrategie ein, um angemessene Rankingmöglichkeiten für die Vorhersagewerte feinkörniger Produkte bereitzustellen. Darüber hinaus haben wir PLACO um einen Multi-Label-Erkennungsverlust erweitert, um das gleichzeitige Auftreten von Artikeln in Kassenbildern zu modellieren und so die Genauigkeit der visuellen Kasse von Einzelhandelsartikeln weiter zu verbessern.
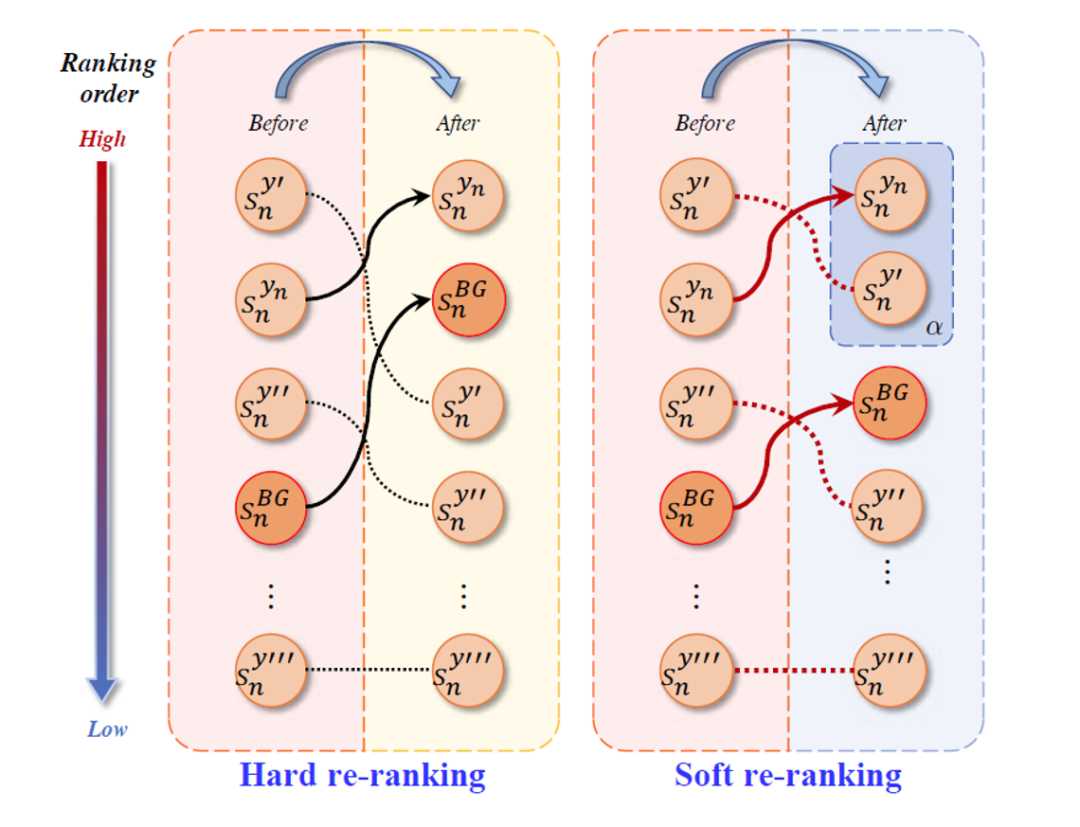
Abbildung 3 Schematische Darstellung zweier diskriminierender Umlagerungsmethoden
04
Experimentelle Ergebnisse
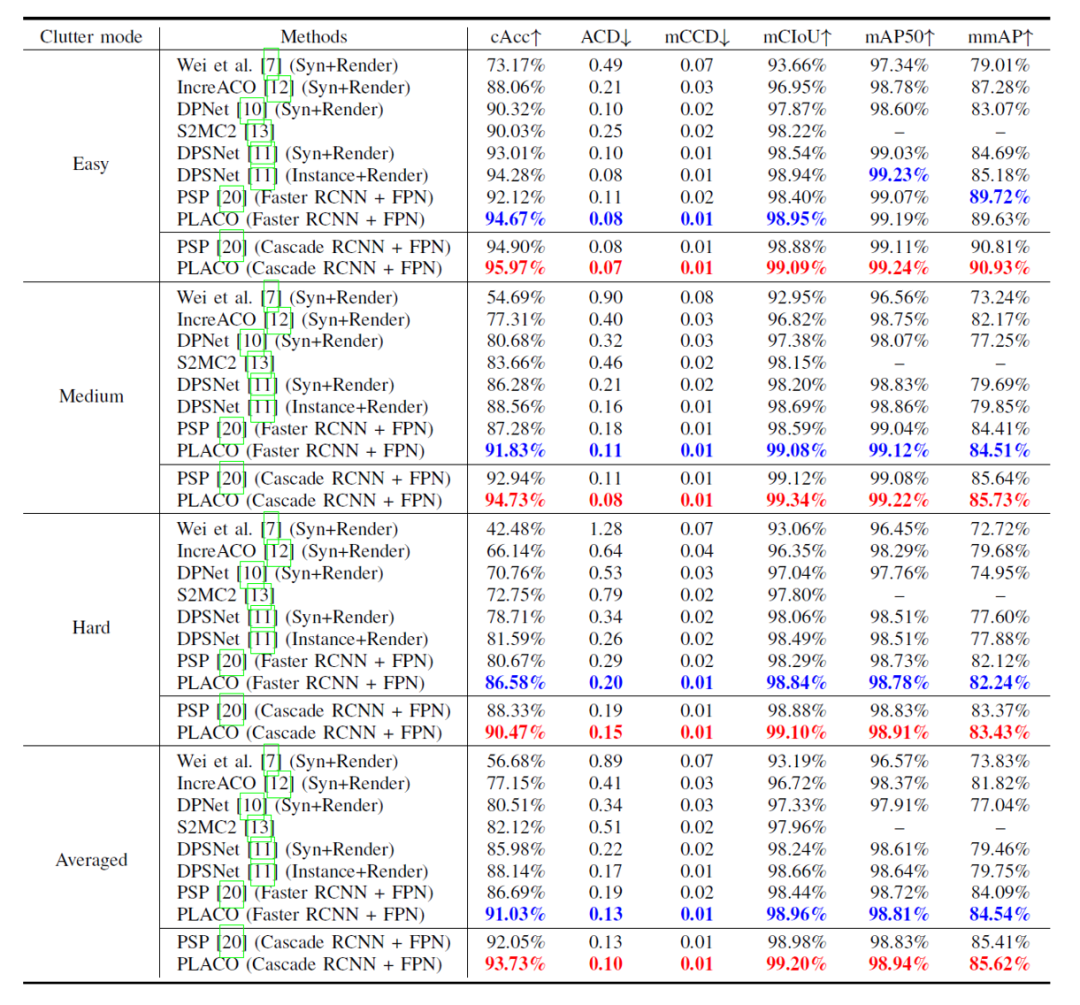
Wir haben Vergleichsexperimente zur visuellen Checkout-Leistung von sieben Methoden am RPC-Datensatz durchgeführt. Unter diesen verwenden die Methoden von Wei et al., IncreACO, DPNet und DPSNet alle synthetische Daten und Rendering-Daten, um gemeinsam zu trainieren. Das Zielerkennungs-Backbone-Framework dieser Methoden ist Faster RCNN oder Mask RCNN Überwachtes Training. Es handelt sich um eine Methode zum Zählen von Objekten auf Punktebene. PSP ist die Konferenzversionsmethode von PLACO. Beide Methoden verfügen über zwei Zielerkennungs-Backbones und Cascade RCNN Experimentelle Ergebnisse des Frameworks. Da die RPC-Daten je nach Kategorie und Menge der Einzelhandelsgüter im Bild in drei Stufen unterteilt sind: leicht, mittel und schwierig, berichten wir bei der Berichterstattung über die experimentellen Ergebnisse auch über die Ergebnisse dieser drei Stufen und das durchschnittliche Gesamtergebnis.
Aus den Ergebnissen ist ersichtlich, dass die PLACO-Methode in diesem Artikel grundsätzlich die besten Ergebnisse sowohl in den Backbone-Zielerkennungs-Frameworks Faster RCNN als auch Cascade RCNN erzielt hat, insbesondere in Bezug auf die Abrechnungsgenauigkeit des Haupterkennungsindikators (cAcc). „ ↑“ in der Tabelle zeigt an, dass die Leistung umso besser ist, je kleiner das Ergebnis ist. Die besten Ergebnisse basierend auf dem Faster RCNN-Framework werden in Fettdruck angezeigt Die besten Ergebnisse basierend auf dem Cascade RCNN-Framework sind rot hervorgehoben.
Tabelle 1 Vergleichsergebnisse der visuellen Abrechnung von Einzelhandelswaren mit sieben Methoden im RPC-Datensatz
05
Zusammenfassung und Ausblick
In diesem Artikel wird eine prototypische Lernmethode PLACO für den automatischen Checkout vorgeschlagen, einschließlich eines prototypbasierten Klassifikator-Lernmoduls, eines diskriminierenden Umlagerungsmoduls und eines Prototyp-Ausrichtungsmoduls. Das prototypbasierte Klassifikator-Lernmodul wurde entwickelt, um implizit die Domänenlücke zwischen den als Training verwendeten Beispielen und den als Test verwendeten Checkout-Bildern zu schließen. Darüber hinaus übernimmt dieser Artikel das Prototyp-Alignment-Modul als explizite Domänenanpassungslösung. In diesem Artikel wird eine diskriminierende Reranking-Methode entworfen, um die Leistung von PLACO zu verbessern, indem mehr diskriminierende Fähigkeiten beim Klassifikatorlernen und bei feinkörnigen Kategorien eingeführt werden. In diesem Artikel wird ein Multi-Label-Verlust angewendet, um das gleichzeitige Auftreten von Produkten in Kassenbildern zu simulieren. Beim groß angelegten Benchmark-RPC-Datensatz erreichte PLACO eine Abrechnungsgenauigkeit von 91,03 %, 2,89 % höher als die bisher beste Methode. Da es in diesem Artikel hauptsächlich um Probleme bei der Erkennung von Mu-Tabellen geht, können Sie die in diesem Artikel erforderlichen Experimente problemlos gemäß den offiziellen MindSpore-Dokumentfällen oder den von der Community bereitgestellten Codes und Modellen für die Zielerkennung implementieren, was sehr praktisch und schnell ist.
Ein in den 1990er Jahren geborener Programmierer hat eine Videoportierungssoftware entwickelt und in weniger als einem Jahr über 7 Millionen verdient. Das Ende war sehr bestrafend! Google bestätigte Entlassungen, die den „35-jährigen Fluch“ chinesischer Programmierer in den Flutter-, Dart- und Teams- Python mit sich brachten stark und wird von GPT-4.5 vermutet; Tongyi Qianwen Open Source 8 Modelle Arc Browser für Windows 1.0 in 3 Monaten offiziell GA Windows 10 Marktanteil erreicht 70 %, Windows 11 GitHub veröffentlicht weiterhin KI-natives Entwicklungstool GitHub Copilot Workspace JAVA ist die einzige starke Abfrage, die OLTP+OLAP verarbeiten kann. Dies ist das beste ORM. Wir treffen uns zu spät.