
Autor: Jin Xuefeng
Hintergrund
Das Ausführen großer Sprachmodelle in statischen Diagrammen hat viele Vorteile, darunter:
-
Leistungsverbesserung durch Operator-Fusion-Optimierung/Ausführung des gesamten Diagramms; wenn es sich um Ascend handelt, können Sie auch die Ausführung der gesamten Diagrammsenke nutzen, um die Leistung weiter zu verbessern, und die Ausführung der gesamten Diagrammsenke wird nicht durch die Datenverarbeitungsausführung auf der Hostseite beeinflusst. und die Leistung ist stabil gut;
-
Die Orchestrierung des statischen Speichers ermöglicht eine hohe Speicherauslastung, keine Fragmentierung, erhöht die Stapelgröße und verbessert so die Trainingsleistung;
-
Optimieren Sie automatisch die Ausführungssequenz und erreichen Sie eine gute Kommunikations- und Berechnungsparallelität.
-
......
Allerdings gibt es auch Herausforderungen beim Ausführen großer Sprachmodelle auf statischen Bildern. Die größte Herausforderung ist die Kompilierungsleistung.
Der Kompilierungsprozess des neuronalen Netzwerkmodells wandelt den in Python ausgedrückten nn-Code tatsächlich in ein Datenflussberechnungsdiagramm um:
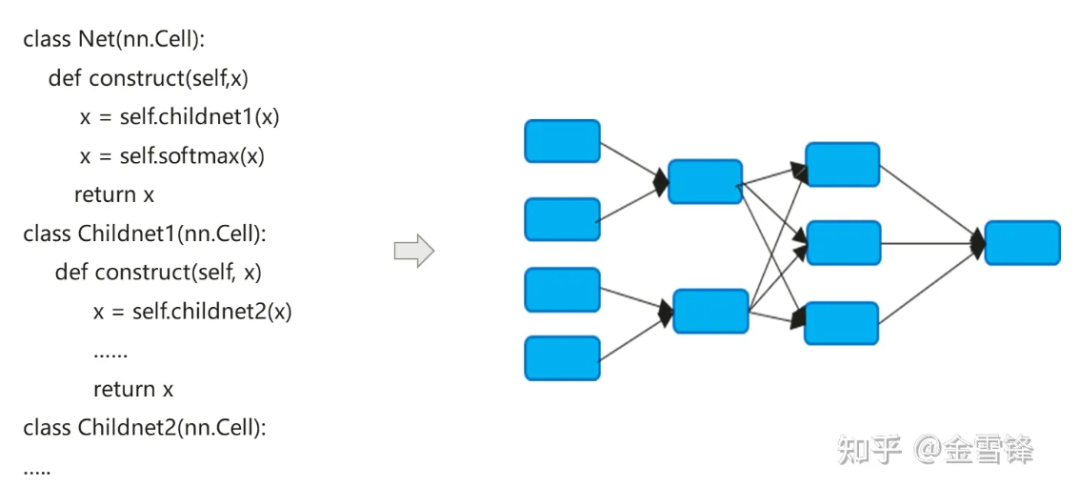
Der Kompilierungsprozess neuronaler Netzwerkmodelle unterscheidet sich ein wenig von herkömmlichen Compilern. Die standardmäßige Inline-Methode wird häufig verwendet, um den hierarchischen Codeausdruck schließlich in ein flaches Berechnungsdiagramm zu erweitern Andererseits kann es auch die automatische Differenzierung und Ausführungslogik vereinfachen.
Standardmäßig umfasst das nach Inline erstellte Berechnungsdiagramm alle Berechnungsknoten, und die Knoten verfügen nicht mehr über Unterberechnungsdiagrammpartitionen. Daher kann eine prozessinterne Optimierung in größerem Maßstab durchgeführt werden, z. B. konstante Faltung, Knotenfusion und parallele Analyse usw., und es kann die Speicherzuweisung besser realisieren und den Speicheranwendungs- und Leistungsaufwand beim Aufrufen zwischen Prozeduren reduzieren. Selbst für Recheneinheiten, die wiederholt aufgerufen werden, verwenden Compiler im KI-Bereich immer noch dieselbe Inline-Strategie. Sie zahlen zwar den Preis für die Erweiterung der Programmgröße und das Wachstum des ausführbaren Codes, können jedoch den Einsatz von Methoden zur Kompilierungsoptimierung maximieren, um die Laufzeitleistung zu verbessern.
Wie aus der obigen Beschreibung hervorgeht, ist die Inline-Optimierung sehr hilfreich bei der Verbesserung der Laufzeitleistung, aber dementsprechend bringt eine übermäßige Inline-Optimierung auch eine Belastung für die Kompilierung mit sich. Da der Teilberechnungsgraph in den gesamten Graphen integriert ist, nimmt aus globaler Sicht die Anzahl der Rechengraphenknoten, die der Compiler verarbeiten muss, schnell zu. Compiler verwenden im Allgemeinen den Pass-Mechanismus, um Optimierungsmethoden zu organisieren und anzuordnen. Verschiedene Optimierungsmethoden werden in Form von Pass in Reihe geschaltet, und ein Verarbeitungsprozess durchläuft jeden Knoten des Berechnungsdiagramms. Die Anzahl der Verarbeitungsdurchgänge hängt vom Matching- und Konvertierungsprozess des Knotens und des Durchgangs ab. Manchmal sind mehrere Durchgänge erforderlich, um die Verarbeitung abzuschließen. Wenn die Anzahl der Durchgänge M und die Anzahl der Knoten des Rechendiagramms N beträgt, hängt die Zeit des gesamten Kompilierungs- und Optimierungsprozesses im Allgemeinen direkt vom Wert M * N ab. Im Zeitalter großer Sprachmodelle ist dieses Problem aus zwei Hauptgründen stärker geworden: Erstens ist die Modellstruktur großer Sprachmodelle tief und weist zweitens beim Training großer Sprachmodelle auf Durch die Aktivierung der Pipeline-Parallelität werden der Modellmaßstab und die Anzahl der Knoten weiter verringert. Wenn die ursprüngliche Diagrammgröße O ist, wird die Pipeline-Parallelität aktiviert, und die Größe des Einzelknoten-Diagramms wird (O/X)*Y , wobei X die Anzahl der Stufen in der Pipeline und Y die Anzahl der Mikrobatches ist. Während des Konfigurationsprozesses ist Y viel größer als X. Beispielsweise ist X 16 und Y wird im Allgemeinen auf 64-192 eingestellt. Auf diese Weise erhöht sich der Umfang der Diagrammkompilierung nach der Aktivierung der Pipeline-Parallelisierung weiter auf das 4- bis 12-fache der ursprünglichen Größe.

Am Beispiel eines bestimmten 13B-Netzwerks mit mehreren zehn Milliarden Sprachmodellen erreicht die Anzahl der Rechenknoten im Berechnungsdiagramm 135.000, und eine einzelne Kompilierungszeit kann nahezu 3 Stunden betragen.
**1.** Optimierungsideen
Wir haben beobachtet, dass die neuronale Netzwerkstruktur des Deep Learning aus mehreren Schichten besteht. Unter dem großen Modellsprachenmodell sind diese Schichten Stapel von Transformer-Blöcken. Insbesondere wenn die Pipeline-Parallelität aktiviert ist, sind die Schichten jedes Mikrostapels genau gleich . Daher fragen wir uns, ob wir diese Layer-Strukturen ohne Inline oder Inline im Voraus beibehalten können, sodass die Kompilierungsleistung exponentiell verbessert werden kann. Wenn wir beispielsweise dem Mikrobatch als Grenze folgen und die Untergraphstruktur des Mikrobatches beibehalten, dann kann die Kompilierungszeit theoretisch das Einfache des ursprünglichen Y betragen (Y ist die Anzahl der Mikrobatches).
Spezifisch für den im Modell geschriebenen Code können wir erkennen, dass die Wiederverwendung derselben Ebene im Allgemeinen eine Schleife oder ein iterativer Aufruf ist, der im Allgemeinen einem Element der sequentiellen Struktur im iterativen Prozess entspricht, d. h. Verwenden Sie eine Schleife oder iterieren Sie, um dieselbe Recheneinheit mehrmals aufzurufen, wie im folgenden Code gezeigt. Der Block entspricht einem Layer- oder Micro-Batch-Untergraphen.
class Block(nn.Cell):
def __init__(self, config):
.......
def construct(self, x, attention_mask, layer_past):
......
class GPT_Model(nn.Cell):
def __init__(self, config):
......
for i in range(config.num_layers):
self.blocks.append(Block)
......
self.num_layers = config.num_layers
def construct(self, input_ids, input_mask, layer_past):
......
present_layer = ()
for i in range(self.num_layers):
hidden_states, present = self.blocks[i](...)
present_layer = present_layer + (present,)
......
Wenn wir also den Schleifenkörper als häufig aufgerufenen Untergraphen betrachten und den Compiler anweisen, die Inline-Verarbeitung zu verschieben, indem er ihn als Lazy Inline markiert, können in den meisten Phasen der Kompilierung Leistungssteigerungen erzielt werden. Wenn das neuronale Netzwerk beispielsweise zyklisch dieselbe Untergraphenstruktur aufruft, erweitern wir den Untergraphen während der Kompilierungsphase nicht. Am Ende der Kompilierung wird dann die Inline-Optimierung ausgelöst, um die erforderliche Optimierung und Konvertierungsdurchlaufverarbeitung durchzuführen. Auf diese Weise handelt es sich für den Compiler meist um Code in kleinerem Maßstab und nicht um Code, der inline erweitert wurde, wodurch die Kompilierungsleistung erheblich verbessert wird.
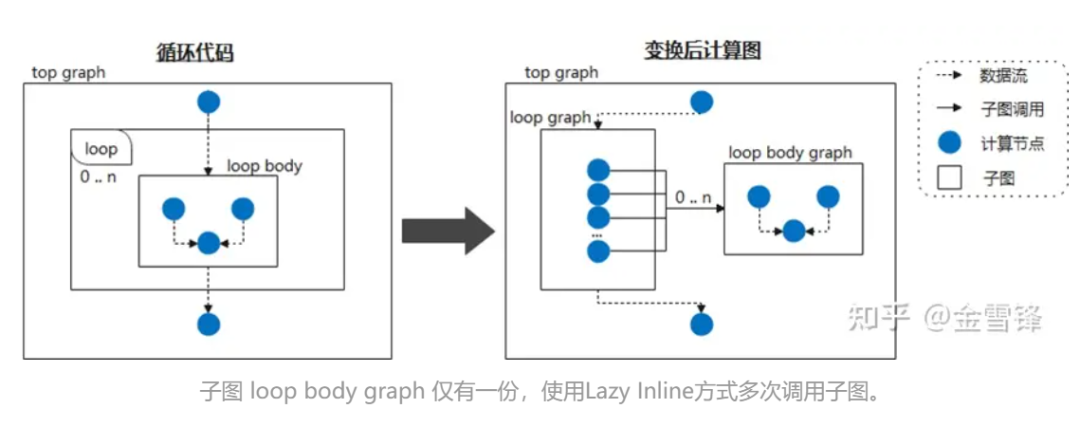
Während einer bestimmten Implementierung können Sie der entsprechenden Layer-Klasse eine Markierung wie @lazy-inline hinzufügen, um den Compiler aufzufordern. Unabhängig davon, ob die markierte Ebene im Schleifenkörper oder auf andere Weise aufgerufen wird, wird sie bei der Inline-Erweiterung nicht berücksichtigt wird erst vor der Ausführung durchgeführt.
**2. ** MindSpore-Praxis
Es scheint, dass die Prinzipien und Ideen von Lazy Inline nicht kompliziert sind, aber der vorhandene AI-Graph-Kompilierungsmechanismus ist im Allgemeinen nicht die Art von Compiler, der vollständige Kompilierungsfunktionen unterstützt, sodass es immer noch eine große Herausforderung ist, diese Funktion zu realisieren.
Glücklicherweise hat der Graph-Compiler von MindSpore beim Entwurf von IR auf Vielseitigkeit geachtet, einschließlich Unterfunktionsaufrufen, Abschlüssen und anderen Funktionen.
① Zellinstanzen werden zu wiederverwendbaren Berechnungsdiagrammen zusammengestellt
Zelle ist der Grundbaustein des neuronalen Netzwerks MindSpore und die Basisklasse aller neuronalen Netzwerke. Zelle kann eine einzelne neuronale Netzwerkeinheit wie conv2d, relu, batch_norm usw. sein, oder sie kann eine Kombination von Einheiten sein, die ein bilden Netzwerk. Im GRAPH_MODE (statischer Diagrammmodus) wird Cell in ein Berechnungsdiagramm kompiliert.
Wenn Sie das Netzwerk anpassen müssen, müssen Sie die Cell-Klasse erben und die Methoden __init__ und construction überschreiben. Die Cell-Klasse überschreibt die __call__-Methode. Wenn eine Cell-Klasseninstanz aufgerufen wird, wird die Konstruktormethode ausgeführt. Definieren Sie die Netzwerkstruktur in der Konstruktionsmethode.
Im folgenden Beispiel wird ein einfaches Netzwerk zur Implementierung der Faltungsberechnungsfunktion erstellt. Operatoren im Netzwerk werden in __init__ definiert und in der Konstruktmethode verwendet. Die Netzwerkstruktur des Falles ist: Conv2d -> BiasAdd.
Bei der Konstruktionsmethode sind x die Eingabedaten und die Ausgabe das Ergebnis, das nach der Berechnung der Netzwerkstruktur erhalten wird.
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Parameter
from mindspore.common.initializer import initializer
from mindspore._extends import lazy_inline
class MyNet(nn.Cell):
@lazy_inline
def __init__(self, in_channels=10, out_channels=20, kernel_size=3):
super(Net, self).__init__()
self.conv2d = ops.Conv2D(out_channels, kernel_size)
self.bias_add = ops.BiasAdd()
self.weight = Parameter(initializer('normal', [out_channels, in_channels, kernel_size, kernel_size]))
def construct(self, x):
output = self.conv2d(x, self.weight)
output = self.bias_add(output, self.bias)
return output
@Lazy_Inline ist der Dekorator von Cell::__init__. Seine Funktion besteht darin, alle Parameter von __init__ in den cell_init_args-Attributwert von Cell zu generieren, self.cell_init_args = type(self).__name__ + str(arguments). Das Attribut cell_init_args dient als eindeutige Kennung der Cell-Instanz in der MindSpore-Kompilierung. Der gleiche cell_init_args-Wert zeigt an, dass der Name der Zellklasse und die Initialisierungsparameterwerte identisch sind.
construction(self, x) definiert die Netzwerkstruktur, die mit der Cell-Klasse identisch ist. Die Netzwerkstruktur hängt von den Eingabeparametern self und x ab. Self enthält Parameter wie Gewichte oder die Ergebnisse des Trainings, sodass diese Gewichte für jede Cell-Instanz unterschiedlich sind. Andere Selbstattribute werden durch den Parameter __init__ bestimmt, und der Parameter __init__ wird von @lazy_inline berechnet, um die Zellinstanzidentifikation cell_init_args zu erhalten. Daher wird das Berechnungsdiagramm für die Zellinstanzkompilierung Konstrukt(self, x) in Konstrukt(x, self. cell_init_args, self.trainable_parameters() ) umgewandelt.
Wenn es sich um dieselbe Zellklasse handelt und die Parameter cell_init_args identisch sind, nennen wir diese Neuroneninstanzen wiederverwendbare Neuroneninstanzen, und das dieser Neuroneninstanz entsprechende Berechnungsdiagramm wird als wiederverwendbares Berechnungsdiagramm reuse_construct(X, self. trainable_parameters()) bezeichnet. Daraus lässt sich ableiten, dass das Berechnungsdiagramm jeder Zellinstanz konvertiert werden kann in:
def construct(self, x)
Reuse_construct(x, self.trainable_parameters())
Nach der Einführung wiederverwendbarer Computergraphen müssen Neuronenzellen (wiederverwendbare Computergraphen) mit denselben cell_init_args nur einmal zusammengestellt und kompiliert werden. Je mehr Zellen im Netzwerk vorhanden sind, desto besser kann die Leistung sein. Aber alles hat zwei Seiten. Wenn der Berechnungsgraph dieser Zellen zu klein oder zu groß ist, führt dies zu einer schlechten Kompilierung und Optimierung bestimmter Funktionen, wie z. B. Operatorfusion, Speichermultiplexierung, Senkung des gesamten Graphen und Aufrufen mehrerer Graphen usw .
Daher unterstützt die MindSpore-Version derzeit nur die manuelle Identifizierung, welche Zellkompilierungsstufen wiederverwendbare Berechnungsdiagramme generieren. Nachfolgende Versionen werden automatische Strategien zum Generieren wiederverwendbarer Berechnungsdiagramme planen, z. B. wie viele Operatoren eine Zelle enthält, wie oft eine Zelle verwendet wird und andere Faktoren, um abzuwägen, ob ein wiederverwendbares Berechnungsdiagramm erstellt werden soll, und Optimierungsvorschläge zu geben.
Im Folgenden wird die GPT-Struktur für eine abstrakte und vereinfachte Erklärung verwendet:
class Block(nn.Cell):
@lazy_inline
def __init__(self, config):
.......
def construct(self, x, attention_mask, layer_past):
......
class GPT_Model(nn.Cell):
def __init__(self, config):
......
for i in range(config.num_layers):
self.blocks.append(Block(config, None))
......
self.num_layers = config.num_layers
def construct(self, input_ids, input_mask, layer_past):
......
present_layer = ()
for i in range(self.num_layers):
hidden_states, present = self.blocks[i](...)
present_layer = present_layer + (present,)
......
GPT besteht aus mehreren Blockebenen. Die Initialisierungsparameter dieser Blöcke sind alle dieselbe Konfiguration, daher sind die Strukturen dieser Blöcke gleich und werden intern vom Compiler in die folgende Struktur konvertiert:
def Reuse_Block(x, attention_mask, layer_past,block_parameters) :
......
具体的Block 实例的计算图如下:
def construct(self, x, attention_mask, layer_past):
return Reuse_Block(x, attention_mask, layer_past,
self. trainable_parameters())
Bei dieser Struktur handelt es sich in der ersten Hälfte des Kompilierungsprozesses um einen unabhängigen Berechnungsgraphen, der nicht in den gesamten Berechnungsgraphen eingebunden wird. Nur der letzte kleine Teil der Pass-Optimierung wird in den großen Berechnungsgraphen eingebunden.
② Die Kombination aus L****azy Inline und automatischer Differenzierung/Parallel/Neuberechnung und anderen Funktionen
Nach der Einführung der Lösung von Lazy Inline wird es einige Auswirkungen auf den ursprünglichen Prozess haben und entsprechende Anpassungen erfordern, hauptsächlich automatische Differenzierung, Parallelität und Neuberechnung.
Für die automatische Differenzierung erscheint ein Vorwärtsknoten ähnlich der Aufruffunktion, und es muss eine Differenzierungsverarbeitung bereitgestellt werden.
Bei parallelen Prozessen besteht die Hauptsache darin, dass die Pipeline-Paralleldurchlaufverarbeitung an Nicht-Gesamtbildszenarien angepasst werden muss, da der vorherige Pipeline-Schnitt auf dem Gesamtbild basierte, jetzt jedoch auf der Grundlage des gemeinsam genutzten Untergraphen geschnitten werden muss. Der konkrete Plan besteht darin, zunächst entsprechend der Stufe einzufärben, die Knoten in der gemeinsam genutzten Zelle entsprechend der Stufe aufzuteilen, nur die Knoten beizubehalten, die der Stufe des aktuellen Prozesses entsprechen, den Send/Recv-Operator einzufügen und dann die Knoten aufzuteilen außerhalb der gemeinsam genutzten Zelle, wobei die entsprechenden Knoten des aktuellen Prozesses beibehalten werden. Der Stufenknoten übernimmt auch den Send/Recv-Operator in der gemeinsam genutzten Zelle aus der gemeinsam genutzten Zelle.
Für den Neuberechnungsprozess verarbeitet der alte Neuberechnungsprozess Operatoren im gesamten Diagramm nach Inline. Durch die Suche nach neu berechneten kontinuierlichen Operatorblöcken werden die Operatoren, die neu berechnet werden müssen, und die Neuberechnungsparameter entsprechend der Neuberechnungskonfiguration des Benutzers bestimmt Operator, von dem die berechnete Operatorausführung abhängt. Nach Lazy Inline befinden sich aufeinanderfolgende Neuberechnungsoperatoren möglicherweise in verschiedenen Untergraphen und es kann keine Verbindungsbeziehung zwischen dem Vorwärtsknoten und dem Rückwärtsknoten gefunden werden, sodass die ursprüngliche Suchstrategie, die auf dem gesamten Diagrammoperator basiert, fehlschlägt.
Unser Anpassungsplan besteht darin, neu berechnete Zellen oder Operatoren nach automatischer Differenzierung zu verarbeiten. Der automatische Differenzierungsprozess generiert einen Abschluss für den von Cell erzeugten Untergraphen oder einzelnen Operator, der die Vorwärtsausgabe und die Backpropagation-Funktion zurückgibt, und wir erhalten auch die Beziehung zwischen jedem Abschluss und dem ursprünglichen Vorwärtsteil, einer Zuordnung. Durch diese Informationen wird basierend auf der Neuberechnungskonfiguration des Benutzers jeder Abschluss als Grundeinheit verwendet, die Zelle und der Operator werden einheitlich verarbeitet, der ursprüngliche Vorwärtsteil wird zurück in das ursprüngliche Diagramm kopiert und die Abhängigkeitsbeziehung kann weitergegeben werden Durch den Abschluss in der Backpropagation-Funktion kann schließlich ein Neuberechnungsschema erreicht werden, das nicht auf Inline des gesamten Diagramms angewiesen ist.
③Backend- Verarbeitung und Auswirkungen
Die nach dem Einschalten von Lazy Inline am Front-End erzeugte IR wird an das Back-End gesendet, bevor sie durch Sub-Graph-Sinking auf dem Gerät ausgeführt werden kann. Nach Lazy Inline wird es jedoch immer noch einige Probleme bei der Ausführung des Subgraph-Senkens geben, z. B. die Unfähigkeit, die optimale Methode zur Speicherwiederverwendung und Stream-Zuweisung zu verwenden, und die Unfähigkeit, den internen Cache des Diagramms zur Kompilierungsbeschleunigung während der Kompilierung zu verwenden und die Unfähigkeit, eine graphübergreifende Optimierung durchzuführen (Speicheroptimierung, Kommunikationsfusion, Operatorfusion usw.) und andere Probleme.
Um eine optimale Leistung zu erzielen, muss das Backend die IR von Lazy Inline in eine Form verarbeiten, die für die Back-End-Sinking-Ausführung geeignet ist. Die Hauptaufgabe besteht darin, den durch automatische Differenzierung generierten Teiloperator in einen gewöhnlichen Untergraphenaufruf umzuwandeln und zu ändern Erfasste Variablen werden als gewöhnliche Parameter übergeben, sodass das gesamte Diagramm versenkt und das gesamte Netzwerk ausgeführt werden kann.
Im gesamten Graph-Sinking-Prozess verfügen diese Aufrufe über zwei Verarbeitungsmethoden: Inline im Diagramm und Inline in der Ausführungssequenz. Inline in der Grafik führt dazu, dass die Grafik erweitert wird und die anschließende Kompilierungsgeschwindigkeit langsamer wird. Die Inline-Ausführungssequenz führt jedoch dazu, dass der Speicherlebenszyklus eines Teils der Inline-Ausführungssequenz während der Speicherwiederverwendung besonders lang wird Am Ende wird der Speicher nicht ausreichen.
Letztendlich bestand die von uns gewählte Verarbeitungsmethode darin, den Inline-Prozess der Ausführungssequenz im Optimierungsdurchlauf, der Operatorauswahl, der Operatorkompilierung und anderen Prozessen wiederzuverwenden, um die Diagrammgröße so klein wie möglich zu machen und zu vermeiden, dass sich zu viele Diagrammknoten auf das Back-End auswirken Zusammenstellung der Diagrammzeit. Vor der Ausführung von Sequenzoptimierung, Stream-Zuweisung, Speicherwiederverwendung und anderen Prozessen werden diese Aufrufe an tatsächliche Knoten Inline gesendet, um den optimalen Effekt der Speicherwiederverwendung zu erzielen. Darüber hinaus ist es durch einige Speicher- und Kommunikationsoptimierungen, die Eliminierung redundanter Berechnungen und andere Methoden nach dem Inline-Graph möglich, keine Verschlechterung des Speichers und der Leistung zu erreichen.
Derzeit ist es nicht möglich, alle Optimierungen auf Diagrammebene zu erreichen. Die Einzelpunktidentifikation kann nur in der Phase nach Inline platziert werden, und es ist unmöglich, Zeit bei der Optimierung der Ausführungsreihenfolge, der Stream-Zuweisung und der Speicherwiederverwendung zu sparen.
④Erzielen Sie Effekte
Bei der Optimierung der Kompilierungsleistung großer Modelle wird die Lazy-Inline-Lösung verwendet, um die Kompilierungsleistung um das 3- bis 8-fache zu verbessern. Am Beispiel des 13B-Netzwerks des 10-Milliarden-Großmodells sank der Kompilierungsmaßstab des Berechnungsdiagramms von 130.000+ Knoten auf über 20.000 Knoten, die Kompilierungszeit wurde von 3 Stunden auf 20 Minuten reduziert und in Kombination mit der Zwischenspeicherung der Kompilierungsergebnisse wurde die Gesamteffizienz erheblich verbessert.
⑤Nutzungsbeschränkungen und nächste Schritte
1. Cell Der Bezeichner der Cell-Instanz wird basierend auf dem Cell-Klassennamen und dem Parameterwert __init__ generiert. Dies basiert auf der Annahme, dass die Parameter von init alle Eigenschaften von Cell bestimmen und dass die Cell-Eigenschaften zu Beginn der Konstruktzusammensetzung mit den Eigenschaften nach der Ausführung von init übereinstimmen. Daher können die Eigenschaften von Cell in Bezug auf die Zusammensetzung nicht geändert werden nachdem init ausgeführt wurde.
2. Die Parameter der Konstruktfunktion dürfen keine Standardwerte haben. Wenn die vorhandene MindSpore-Version über Standardwerte für die Konstruktfunktionsparameter verfügt, wird sie bei jeder Verwendung in ein neues Berechnungsdiagramm spezialisiert. Nachfolgende Versionen optimieren den ursprünglichen Spezialisierungsmechanismus.
3. Zelle besteht aus mehreren gemeinsam genutzten Cell_X-Instanzen, und jede Zelle_X besteht aus mehreren gemeinsam genutzten Cell_Y-Instanzen. Wenn die Init-Elemente von Cell_X und Cell_Y beide als @lazy_inline dekoriert sind, kann nur das äußerste Cell_X in ein wiederverwendetes Berechnungsdiagramm kompiliert werden, und das Berechnungsdiagramm des inneren Cell_Y ist immer noch Inline. Nachfolgende Versionen planen, dieses mehrstufige Lazy-Inline zu unterstützen Mechanismus.
Wie man Kunden beim Schreiben von Code mit hoher Kohäsion und geringer Kopplung unterstützt, ist auch eines der Ziele, die das MindSpore-Framework verfolgt. Beispielsweise wird dieser Block::__init__-Parameter verwendet, der den Layer-Index enthält Die anderen Parameter sind gleich, da der Layer-Index jeweils verwendet wird. Jeder Layer ist anders, was dazu führt, dass der Block aufgrund subtiler Unterschiede nicht wiederverwendbar ist. Beispielsweise ist der folgende Code in einem bestimmten GTP-Versionscode vorhanden:
class Block (nn.Cell):
"""
Self-Attention module for each layer
Args:
config(GPTConfig): the config of network
scale: scale factor for initialization
layer_idx: current layer index
"""
def __init__(self, config, scale=1.0, layer_idx=None):
......
if layer_idx is not None:
self.coeff = math.sqrt(layer_idx * math.sqrt(self.size_per_head))
self.coeff = Tensor(self.coeff)
......
def construct(self, x, attention_mask, layer_past=None):
......
Um den Block wiederverwendbar zu machen, können wir ihn optimieren, die mit dem Layer-Index verbundenen Berechnungen extrahieren und sie dann als Parameter von Construct verwenden, um sie in die ursprüngliche Zusammensetzung einzugeben, sodass die Initialisierungsparameter des Blocks dieselben sind.
Ändern Sie das obige Codesegment in das folgende Codesegment, löschen Sie die Teile, die sich auf Init und Layer Index beziehen, und fügen Sie den zu erstellenden Coeff-Parameter hinzu.
class Block (nn.Cell):
def __init__(self, config, scale=1.0):
......
def construct(self, x, attention_mask, layer_past, coeff):
......
In nachfolgenden Versionen von Shengsi MindSpore planen wir, solche subtil unterschiedlichen Blöcke zu identifizieren und Optimierungsvorschläge für diese Blöcke zur Optimierung und Verbesserung bereitzustellen.
Ein in den 1990er Jahren geborener Programmierer hat eine Videoportierungssoftware entwickelt und in weniger als einem Jahr über 7 Millionen verdient. Das Ende war sehr bestrafend! Google bestätigte Entlassungen, die den „35-jährigen Fluch“ chinesischer Programmierer in den Flutter-, Dart- und Teams- Python mit sich brachten stark und wird von GPT-4.5 vermutet; Tongyi Qianwen Open Source 8 Modelle Arc Browser für Windows 1.0 in 3 Monaten offiziell GA Windows 10 Marktanteil erreicht 70 %, Windows 11 GitHub veröffentlicht weiterhin KI-natives Entwicklungstool GitHub Copilot Workspace JAVA ist die einzige starke Abfrage, die OLTP+OLAP verarbeiten kann. Dies ist das beste ORM. Wir treffen uns zu spät.