
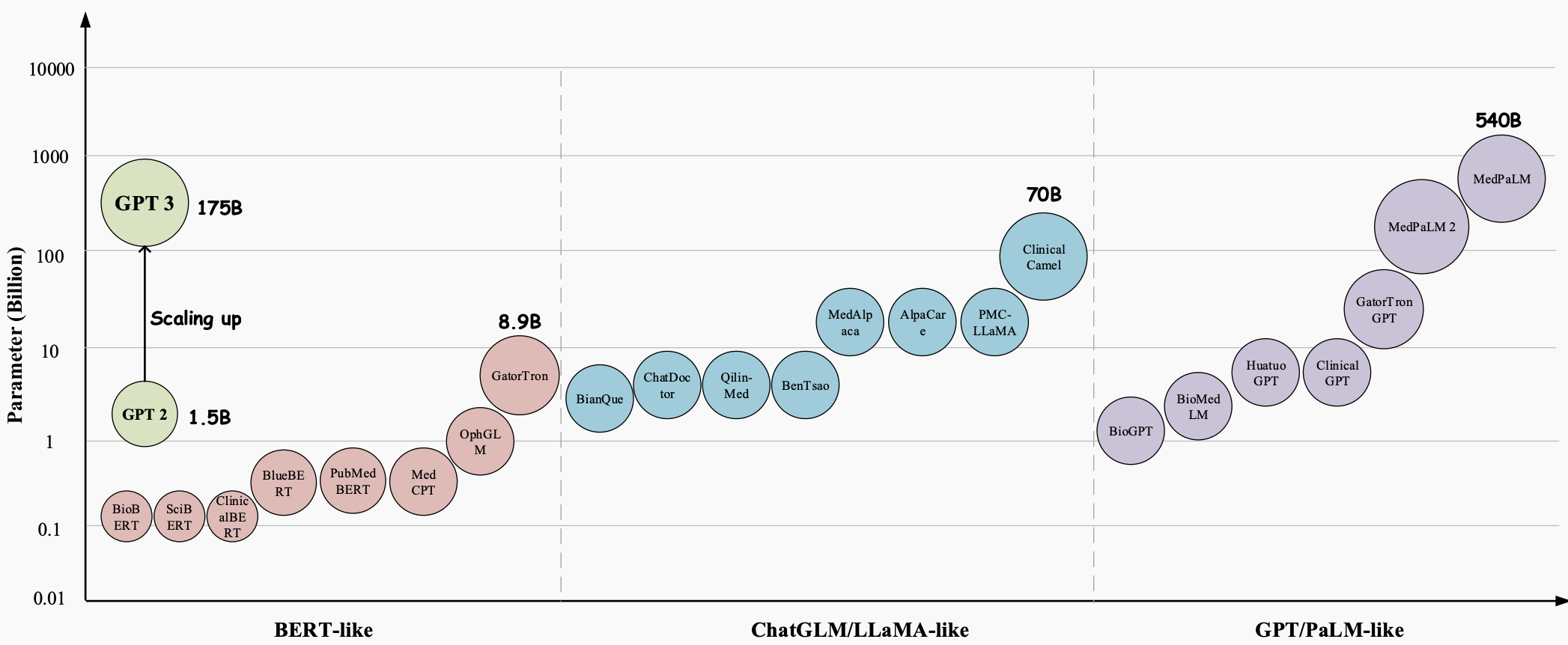
Im Laufe der Jahre haben sich Large Language Models (LLMs) zu einer bahnbrechenden Technologie mit großem Potenzial entwickelt, jeden Aspekt der Gesundheitsbranche zu revolutionieren. Diese Modelle, wie etwa GPT-3 , GPT-4 und Med-PaLM 2 , haben überlegene Fähigkeiten beim Verstehen und Generieren von menschenähnlichem Text gezeigt, was sie zu wertvollen Werkzeugen für die Bewältigung komplexer medizinischer Aufgaben und die Verbesserung der Patientenversorgung macht. Sie erweisen sich als vielversprechend für eine Vielzahl medizinischer Anwendungen, beispielsweise für die Beantwortung medizinischer Fragen (QA), Dialogsysteme und die Textgenerierung. Darüber hinaus können LLMs angesichts des exponentiellen Wachstums elektronischer Gesundheitsakten (EHRs), medizinischer Literatur und patientengenerierter Daten medizinischen Fachkräften dabei helfen, wertvolle Erkenntnisse zu gewinnen und fundierte Entscheidungen zu treffen.
Doch trotz des enormen Potenzials großer Sprachmodelle (LLMs) im medizinischen Bereich gibt es noch einige wichtige und spezifische Herausforderungen, die gelöst werden müssen.
Wenn das Modell im Kontext von Unterhaltungsgesprächen verwendet wird, sind die Auswirkungen von Fehlern minimal. Dies ist jedoch nicht der Fall, wenn es im medizinischen Bereich verwendet wird, wo falsche Interpretationen und Antworten schwerwiegende Folgen für die Patientenversorgung und die Ergebnisse haben können. Die Genauigkeit und Zuverlässigkeit der von Sprachmodellen bereitgestellten Informationen kann über Leben und Tod entscheiden, da sie sich auf medizinische Entscheidungen, Diagnosen und Behandlungspläne auswirken können.
Als GPT-3 beispielsweise gefragt wurde, welche Medikamente schwangere Frauen einnehmen könnten, empfahl GPT-3 fälschlicherweise Tetracyclin, obwohl darin auch korrekt angegeben wurde, dass Tetracyclin schädlich für den Fötus ist und nicht von schwangeren Frauen eingenommen werden sollte. Wenn Sie diesen falschen Rat wirklich befolgen und schwangeren Frauen Medikamente verabreichen, kann dies dazu führen, dass die Knochen des Kindes in Zukunft schlecht wachsen.

Um solch große Sprachmodelle im medizinischen Bereich sinnvoll nutzen zu können, müssen diese Modelle entsprechend den Merkmalen der medizinischen Industrie entworfen und einem Benchmarking unterzogen werden. Da medizinische Daten und Anwendungen ihre Besonderheiten aufweisen, müssen diese berücksichtigt werden. Und es ist tatsächlich wichtig, Methoden zu entwickeln, um diese Modelle für medizinische Zwecke zu bewerten, und zwar nicht nur für Forschungszwecke, sondern auch, weil sie Risiken bergen könnten, wenn sie in der realen medizinischen Arbeit falsch verwendet werden.
Das Open Source Medical Large Model Ranking zielt darauf ab, diese Herausforderungen und Einschränkungen anzugehen, indem es eine standardisierte Plattform zur Bewertung und zum Vergleich der Leistung verschiedener großer Sprachmodelle für eine Vielzahl medizinischer Aufgaben und Datensätze bereitstellt. Durch die umfassende Bewertung des medizinischen Wissens und der Fähigkeit zur Beantwortung von Fragen jedes Modells fördert das Ranking die Entwicklung effektiverer und zuverlässigerer medizinischer Modelle.
Diese Plattform ermöglicht es Forschern und Praktikern, die Stärken und Schwächen verschiedener Ansätze zu identifizieren, die Weiterentwicklung auf diesem Gebiet voranzutreiben und letztendlich zur Verbesserung der Patientenergebnisse beizutragen.
Datensätze, Aufgaben und Bewertungseinstellungen
Das Medical Large Model Ranking umfasst eine Vielzahl von Aufgaben und verwendet die Genauigkeit als wichtigste Bewertungsmetrik (die Genauigkeit misst den Prozentsatz richtiger Antworten, die das Sprachmodell in verschiedenen medizinischen Frage- und Antwortdatensätzen liefert).
MedQA
Der MedQA -Datensatz enthält Multiple-Choice-Fragen aus der United States Medical Licensing Examination (USMLE). Es deckt ein breites Spektrum an medizinischem Wissen ab und umfasst 11.450 Fragen zum Trainingssatz und 1.273 Fragen zum Testsatz. Mit 4 oder 5 Antwortoptionen pro Frage ist dieser Datensatz darauf ausgelegt, die medizinischen Kenntnisse und Denkfähigkeiten zu bewerten, die für den Erhalt einer medizinischen Zulassung in den Vereinigten Staaten erforderlich sind.

MedMCQA
MedMCQA ist ein umfangreicher Multiple-Choice-Frage-Antwort-Datensatz, der aus der indischen medizinischen Aufnahmeprüfung (AIIMS/NEET) abgeleitet ist. Es deckt 2400 medizinische Fachthemen und 21 medizinische Fächer ab, mit mehr als 187.000 Fragen im Trainingssatz und 6.100 Fragen im Testsatz. Zu jeder Frage gibt es 4 Antwortmöglichkeiten mit Erläuterungen. MedMCQA bewertet das allgemeine medizinische Wissen und die Denkfähigkeit eines Modells.

PubMedQA
PubMedQA ist ein Frage-Antwort-Datensatz mit geschlossenem Bereich, in dem jede Frage durch Betrachtung des relevanten Kontexts beantwortet werden kann (PubMub-Zusammenfassung). Es enthält 1.000 von Experten gekennzeichnete Frage-Antwort-Paare. Jeder Frage liegt eine PubMed-Zusammenfassung für den Kontext bei. Die Aufgabe besteht darin, auf der Grundlage der zusammenfassenden Informationen eine Ja/Nein/Vielleicht-Antwort zu geben. Der Datensatz ist in 500 Trainingsfragen und 500 Testfragen unterteilt. PubMedQA bewertet die Fähigkeit eines Modells, wissenschaftliche biomedizinische Literatur zu verstehen und zu argumentieren.

MMLU-Untergruppe (Medizin und Biologie)
Der MMLU-Benchmark (Measuring Large-Scale Multi-Task Language Understanding) enthält Multiple-Choice-Fragen aus verschiedenen Bereichen. Für die Rangliste der Open-Source-Medizin-Großmodelle konzentrieren wir uns auf die Teilmenge, die für das medizinische Wissen am relevantesten ist:
- Klinisches Wissen: 265 Fragen zur Bewertung des klinischen Wissens und der Entscheidungskompetenz.
- Medizinische Genetik: 100 Fragen zu Themen im Zusammenhang mit der medizinischen Genetik.
- Anatomie: 135 Fragen zur Bewertung der Kenntnisse der menschlichen Anatomie.
- Professionelle Medizin: 272 Fragen, die das erforderliche Wissen von Medizinern bewerten.
- Hochschulbiologie: 144 Fragen zu Biologiekonzepten auf Hochschulniveau.
- Hochschulmedizin: 173 Fragen zur Bewertung medizinischer Kenntnisse auf Hochschulniveau. Jede MMLU-Untergruppe enthält Multiple-Choice-Fragen mit vier Antwortoptionen, mit denen das Verständnis des Modells für einen bestimmten medizinischen und biologischen Bereich beurteilt werden soll.

Die Open-Source-Rangliste medizinischer Großmodelle bietet eine fundierte Bewertung der Modellleistung in verschiedenen Aspekten des medizinischen Wissens und Denkens.
Einblicke und Analysen
Das Open Source Medical Large Model Ranking bewertet die Leistung verschiedener Large Language Models (LLMs) bei einer Reihe von Aufgaben zur Beantwortung medizinischer Fragen. Hier sind einige unserer wichtigsten Erkenntnisse:
- Kommerzielle Modelle wie GPT-4-base und Med-PaLM-2 erzielen bei verschiedenen medizinischen Datensätzen durchweg hohe Genauigkeitswerte und demonstrieren damit eine starke Leistung in verschiedenen medizinischen Bereichen.
- Open-Source-Modelle wie Starling-LM-7B , gemma-7b , Mistral-7B-v0.1 und Hermes-2-Pro-Mistral-7B schneiden bei bestimmten Daten gut ab, obwohl die Anzahl der Parameter nur etwa 7 Milliarden beträgt Sätze und Aufgaben lieferten wettbewerbsfähige Leistungen.
- Kommerzielle und Open-Source-Modelle eignen sich gut für Aufgaben wie das Verstehen und Nachdenken über wissenschaftliche biomedizinische Literatur (PubMedQA) und die Anwendung von klinischem Wissen und Entscheidungskompetenzen (MMLU-Teilmenge des klinischen Wissens).

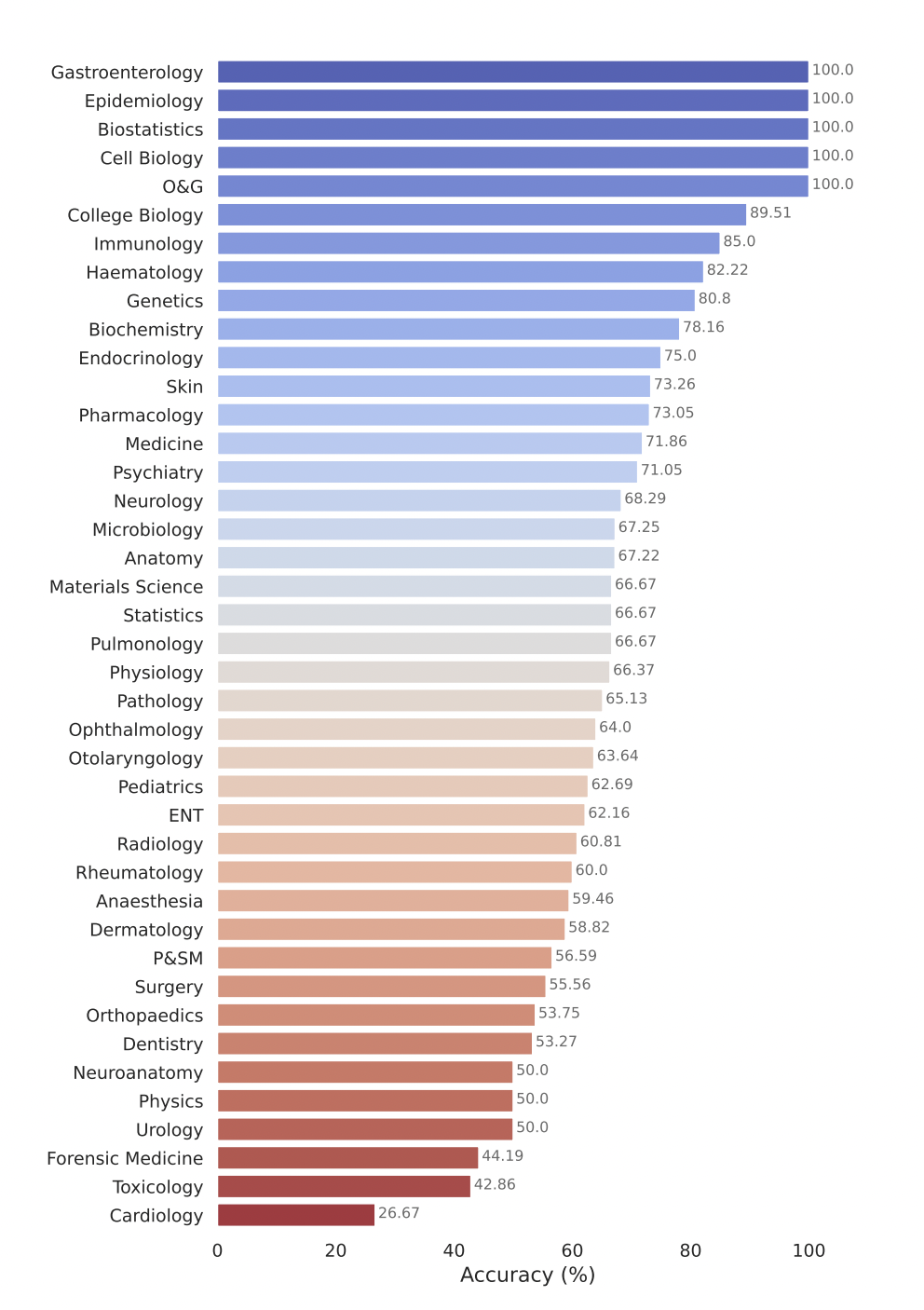
Das Modell Gemini Pro von Google hat in mehreren medizinischen Bereichen starke Leistungen gezeigt, insbesondere bei datenintensiven und verfahrenstechnischen Aufgaben wie Biostatistik, Zellbiologie sowie Geburtshilfe und Gynäkologie. In Schlüsselbereichen wie Anatomie, Kardiologie und Dermatologie zeigte es jedoch eine mäßige bis geringe Leistung, was Lücken aufdeckte, die weitere Verbesserungen für die Anwendung in einer umfassenderen Medizin erfordern.
Senden Sie Ihr Modell zur Bewertung
Um Ihr Modell zur Bewertung im Open Source Healthcare Large Model Ranking einzureichen, führen Sie bitte die folgenden Schritte aus:
1. Konvertieren Sie Modellgewichte in das Safetensors-Format
Konvertieren Sie zunächst Ihre Modellgewichte in das Safetensors-Format. Safetensoren sind ein neues Format zur Aufbewahrung von Gewichten, die sich sicherer und schneller laden und verwenden lassen. Wenn Sie Ihr Modell in dieses Format konvertieren, kann die Rangliste auch die Anzahl der Parameter für Ihr Modell in der Haupttabelle anzeigen.
2. Stellen Sie die Kompatibilität mit AutoClasses sicher
Stellen Sie vor dem Einreichen des Modells sicher, dass Sie das Modell und den Tokenizer mithilfe von AutoClasses in der Transformers-Bibliothek laden können. Verwenden Sie den folgenden Codeausschnitt, um die Kompatibilität zu testen:
from transformers import AutoConfig, AutoModel, AutoTokenizer
config = AutoConfig.from_pretrained(MODEL_HUB_ID)
model = AutoModel.from_pretrained("your model name")
tokenizer = AutoTokenizer.from_pretrained("your model name")
Wenn Sie bei diesem Schritt fehlschlagen, befolgen Sie die Fehlermeldung, um Ihr Modell vor dem Absenden zu debuggen. Höchstwahrscheinlich wurde Ihr Modell nicht ordnungsgemäß hochgeladen.
3. Machen Sie Ihr Modell öffentlich
Stellen Sie sicher, dass Ihr Modell öffentlich zugänglich ist. In Bestenlisten können keine privaten Modelle oder Modelle bewertet werden, die einen besonderen Zugriff erfordern.
4. Remote-Codeausführung (bald verfügbar)
Derzeit unterstützen die Open-Source-Ranglisten für große medizinische Modelle die erforderlichen use_remote_code=TrueModelle nicht. Das Leaderboard-Team ist jedoch aktiv dabei, diese Funktion hinzuzufügen, also bleiben Sie auf dem Laufenden, um Updates zu erhalten.
5. Reichen Sie Ihr Modell über die Bestenlisten-Website ein
Sobald Ihr Modell in das Safetensors-Format konvertiert, mit AutoClasses kompatibel und öffentlich zugänglich ist, können Sie es mithilfe des Bereichs „Hier einreichen“ auf der Open Source Medical Large Model Ranking-Website bewerten. Geben Sie die erforderlichen Informationen ein, z. B. Modellname, Beschreibung und weitere Details, und klicken Sie auf die Schaltfläche „Senden“. Das Leaderboard-Team wird Ihre Einreichung bearbeiten und die Leistung Ihres Modells anhand verschiedener medizinischer Frage-und-Antwort-Datensätze bewerten. Sobald die Bewertung abgeschlossen ist, wird die Punktzahl Ihres Modells zur Bestenliste hinzugefügt und Sie können seine Leistung mit anderen Modellen vergleichen.
Was kommt als nächstes? Erweiterte Open-Source-Rankings für medizinische Großmodelle
Das Open Source Healthcare Large Model Ranking hat sich zum Ziel gesetzt, es zu erweitern und anzupassen, um den sich ändernden Anforderungen der Forschungsgemeinschaft und der Gesundheitsbranche gerecht zu werden. Zu den Schlüsselbereichen gehören:
- Integrieren Sie durch die Zusammenarbeit mit Forschern, Gesundheitsorganisationen und Industriepartnern umfassendere Gesundheitsdatensätze, die alle Aspekte der Pflege wie Radiologie, Pathologie und Genomik abdecken.
- Verbessern Sie Bewertungsmetriken und Berichtsfunktionen, indem Sie über die Genauigkeit hinaus zusätzliche Leistungskennzahlen untersuchen, wie z. B. Punkt-zu-Punkt-Scores und domänenspezifische Metriken, die die besonderen Anforderungen medizinischer Anwendungen erfassen.
- Es gibt bereits einige Arbeiten in dieser Richtung. Wenn Sie daran interessiert sind, an der nächsten Benchmark, die wir vorschlagen möchten, mitzuarbeiten, treten Sie bitte unserer Discord-Community bei , um mehr zu erfahren und sich zu engagieren. Wir würden gerne zusammenarbeiten und ein Brainstorming durchführen!
Wenn Sie sich für die Schnittstelle von KI und Gesundheitswesen begeistern, Modelle für das Gesundheitswesen entwickeln und sich für die Sicherheits- und Halluzinationsprobleme großer medizinischer Modelle interessieren, laden wir Sie ein, unserer aktiven Community auf Discord beizutreten .
Danksagungen

Besonderer Dank geht an alle, die dazu beigetragen haben, dies zu ermöglichen, einschließlich Clémentine Fourrier und dem Hugging Face-Team. Ich möchte Andreas Motzfeldt, Aryo Gema und Logesh Kumar Umapathi für die Diskussionen und das Feedback während der Entwicklung der Bestenliste danken. Wir möchten Professor Pasquale Minervini von der University of Edinburgh unseren aufrichtigen Dank für seine Zeit, technische Hilfe und GPU-Unterstützung aussprechen.
Über Open Life Sciences AI
Open Life Sciences AI ist ein Projekt, das darauf abzielt, die Anwendung künstlicher Intelligenz in den Lebenswissenschaften und der Medizin zu revolutionieren. Es dient als zentraler Knotenpunkt, der medizinische Modelle, Datensätze und Benchmarks auflistet und Konferenztermine verfolgt, um Zusammenarbeit, Innovation und Fortschritt im Bereich der KI-gestützten Gesundheitsversorgung zu fördern. Wir streben danach, Open Life Sciences AI als erstklassige Anlaufstelle für alle zu etablieren, die sich für die Schnittstelle zwischen KI und Gesundheitswesen interessieren. Wir bieten Forschern, Klinikern, politischen Entscheidungsträgern und Branchenexperten eine Plattform, um in den Dialog zu treten, Erkenntnisse auszutauschen und die neuesten Entwicklungen auf diesem Gebiet zu erkunden.

Zitat
Wenn Sie unsere Einschätzung nützlich finden, denken Sie bitte darüber nach, unsere Arbeit zu zitieren
Rangliste medizinischer Großmodelle
@misc{Medical-LLM Leaderboard,
author = {Ankit Pal, Pasquale Minervini, Andreas Geert Motzfeldt, Aryo Pradipta Gema and Beatrice Alex},
title = {openlifescienceai/open_medical_llm_leaderboard},
year = {2024},
publisher = {Hugging Face},
howpublished = "\url{https://huggingface.co/spaces/openlifescienceai/open_medical_llm_leaderboard}"
}
> Englischer Originaltext: https://hf.co/blog/leaderboard-medicalllm > Originalautor: Aaditya Ura (auf der Suche nach einem Doktortitel), Pasquale Minervini, Clémentine Fourrier > Übersetzer: innovation64
Ein in den 1990er Jahren geborener Programmierer hat eine Videoportierungssoftware entwickelt und in weniger als einem Jahr über 7 Millionen verdient. Das Ende war sehr bestrafend! High-School-Schüler erstellen im Rahmen einer Coming-of-Age-Zeremonie ihre eigene Open-Source-Programmiersprache – scharfe Kommentare von Internetnutzern: Der inländische Dienst Taobao (taobao.com) verließ sich aufgrund des grassierenden Betrugs auf RustDesk und stellte die inländischen Dienste ein und startete die Arbeit zur Optimierung der Webversion von Java neu 17 ist die am häufigsten verwendete Java LTS-Version. Windows 11 erreicht weiterhin einen Rückgang. Open Source Daily unterstützt die Übernahme von Open Source Rabbit R1; Electric schließt die offene Plattform Apple veröffentlicht M4-Chip Google löscht Android Universal Kernel (ACK) Unterstützung für RISC-V-Architektur Yunfeng ist von Alibaba zurückgetreten und plant, in Zukunft unabhängige Spiele auf der Windows-Plattform zu produzieren