
Mit der rasanten Weiterentwicklung der Technologie der künstlichen Intelligenz hat sich OpenAI zu einem der führenden Unternehmen auf diesem Gebiet entwickelt. Es eignet sich gut für eine Vielzahl von Sprachverarbeitungsaufgaben, einschließlich maschineller Übersetzung, Textklassifizierung und Textgenerierung. Mit dem Aufstieg von OpenAI sind viele andere hochwertige Open-Source-Modelle für große Sprachen entstanden, wie z. B. Llama, ChatGLM, Qwen usw. Diese hervorragenden Open-Source-Modelle können Teams auch dabei helfen, schnell eine hervorragende LLM-Anwendung zu erstellen.
Aber wie können wir angesichts der großen Auswahl die OpenAI-Schnittstellen einheitlich nutzen und gleichzeitig die Entwicklungskosten senken? Wie kann die laufende Leistung von LLM-Anwendungen effizient und kontinuierlich überwacht werden, ohne dass sich die Entwicklungskomplexität erhöht? GreptimeAI und Xinference bieten praktische Lösungen für diese Probleme.
Was ist GreptimeAI?
GreptimeAI basiert auf der Open-Source-Zeitreihendatenbank GreptimeDB. Dabei handelt es sich um eine Reihe von Observability-Lösungen für Large Language Model (LLM)-Anwendungen. Derzeit werden die Ökosysteme LangChain und OpenAI unterstützt. GreptimeAI ermöglicht es Ihnen, in Echtzeit ein umfassendes Verständnis von Kosten, Leistung, Datenverkehr und Sicherheit zu erlangen und Teams dabei zu helfen, die Zuverlässigkeit von LLM-Anwendungen zu verbessern.
Was ist Xinference?
Xinference ist eine Open-Source-Modellinferenzplattform, die für große Sprachmodelle (LLM), Spracherkennungsmodelle und multimodale Modelle entwickelt wurde und die privatisierte Bereitstellung unterstützt. Xinference bietet eine RESTful-API, die mit der OpenAI-API kompatibel ist, und integriert Entwicklertools von Drittanbietern wie LangChain, LlamaIndex und Dify.AI , um die Modellintegration und -entwicklung zu erleichtern. Xinference integriert mehrere LLM-Inferenz-Engines (wie Transformers, vLLM und GGML), eignet sich für verschiedene Hardwareumgebungen und unterstützt die verteilte Bereitstellung mehrerer Maschinen. Es kann Modellinferenzaufgaben effizient auf mehrere Geräte oder Maschinen verteilen, um den Anforderungen mehrerer Geräte gerecht zu werden. Modell- und High-Speed-Computing-Anforderungen.
GreptimeAI + Xinference stellt LLM-Anwendungen bereit/überwacht
Als Nächstes nehmen wir das Qwen-14B-Modell als Beispiel, um detailliert vorzustellen, wie Xinference zum lokalen Bereitstellen und Ausführen des Modells verwendet wird. Hier wird ein Beispiel gezeigt, das eine dem OpenAI-Funktionsaufruf (Function Calling) ähnliche Methode zur Durchführung von Wetterabfragen verwendet und zeigt, wie GreptimeAI zur Überwachung der Nutzung von LLM-Anwendungen verwendet wird.
Registrieren Sie sich und erhalten Sie GreptimeAI-Konfigurationsinformationen
Besuchen Sie https://console.greptime.cloud, um den Dienst zu registrieren und den KI-Dienst zu erstellen. Klicken Sie nach dem Sprung zum KI-Dashboard auf die Setup-Seite, um die OpenAI-Konfigurationsinformationen zu erhalten.
Starten Sie den Xinference-Modelldienst
Es ist sehr einfach, den Xinference-Modelldienst lokal zu starten. Sie müssen lediglich den folgenden Befehl eingeben:
xinference-local -H 0.0.0.0
Xinference startet den Dienst standardmäßig lokal und der Standardport ist 9997. Der Prozess der lokalen Installation von Xinference entfällt hier. Informationen zur Installation finden Sie in diesem Artikel .
Starten des Modells über die Web-Benutzeroberfläche
Geben Sie nach dem Start von Xinference http://localhost:9997 in den Browser ein , um auf die Web-Benutzeroberfläche zuzugreifen.

Starten Sie das Modell über die Befehlszeile
Wir können auch das Befehlszeilentool von Xinference verwenden, um das Modell zu starten. Die Standard-Modell-UID ist qwen-chat (auf das Modell wird später über diese ID zugegriffen).
xinference launch -n qwen-chat -s 14 -f pytorch
Erhalten Sie Wetterinformationen über eine Schnittstelle im OpenAI-Stil
Angenommen, wir haben die Möglichkeit, get_current_weatherWetterinformationen für eine bestimmte Stadt zu erhalten, indem wir die Funktion mit den Parametern locationund aufrufen format.
Konfigurieren Sie OpenAI und rufen Sie die Schnittstelle auf
Greifen Sie über das Python SDK von OpenAI auf den lokalen Xinference-Port zu, verwenden Sie GreptimeAI zum Sammeln von Daten, verwenden Sie chat.completionsdie Schnittstelle zum Erstellen einer Konversation und verwenden Sie zum toolsAngeben der gerade definierten Funktionsliste.
from greptimeai import openai_patcher
from openai improt OpenAI
client = OpenAI(
base_url="http://127.0.0.1:9997/v1",
)
openai_patcher.setup(client=client)
messages = [
{"role": "system", "content": "你是一个有用的助手。不要对要函数调用的值做出假设。"},
{"role": "user", "content": "上海现在的天气怎么样?"}
]
chat_completion = client.chat.completions.create(
model="qwen-chat",
messages=messages,
tools=tools,
temperature=0.7
)
print('func_name', chat_completion.choices[0].message.tool_calls[0].function.name)
print('func_args', chat_completion.choices[0].message.tool_calls[0].function.arguments)
Details zu den Werkzeugen
Funktionsaufruf Die Funktionsliste (Werkzeugliste) wird unten definiert, wobei die erforderlichen Felder angegeben werden.
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "获取当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市,例如北京",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "使用的温度单位。从所在的城市进行推断。",
},
},
"required": ["location", "format"],
},
},
}
]
Die Ausgabe lautet wie folgt. Sie können sehen, dass wir chat_completionden vom Qwen-Modell generierten Funktionsaufruf erhalten haben durch:
func_name: get_current_weather
func_args: {"location": "上海", "format": "celsius"}
Rufen Sie das Ergebnis des Funktionsaufrufs ab und rufen Sie die Schnittstelle erneut auf
Hier wird davon ausgegangen, dass wir die Funktion mit den angegebenen Parametern aufgerufen get_current_weatherund das Ergebnis erhalten haben und das Ergebnis und den Kontext erneut an das Qwen-Modell senden:
messages.append(chat_completion.choices[0].message.model_dump())
messages.append({
"role": "tool",
"tool_call_id": messages[-1]["tool_calls"][0]["id"],
"name": messages[-1]["tool_calls"][0]["function"]["name"],
"content": str({"temperature": "10", "temperature_unit": "celsius"})
})
chat_completion = client.chat.completions.create(
model="qwen-chat",
messages=messages,
tools=tools,
temperature=0.7
)
print(chat_completion.choices[0].message.content)
Endgültige Ergebnisse
Das Qwen-Modell wird schließlich eine Antwort wie diese ausgeben:
上海现在的温度是 10 摄氏度。
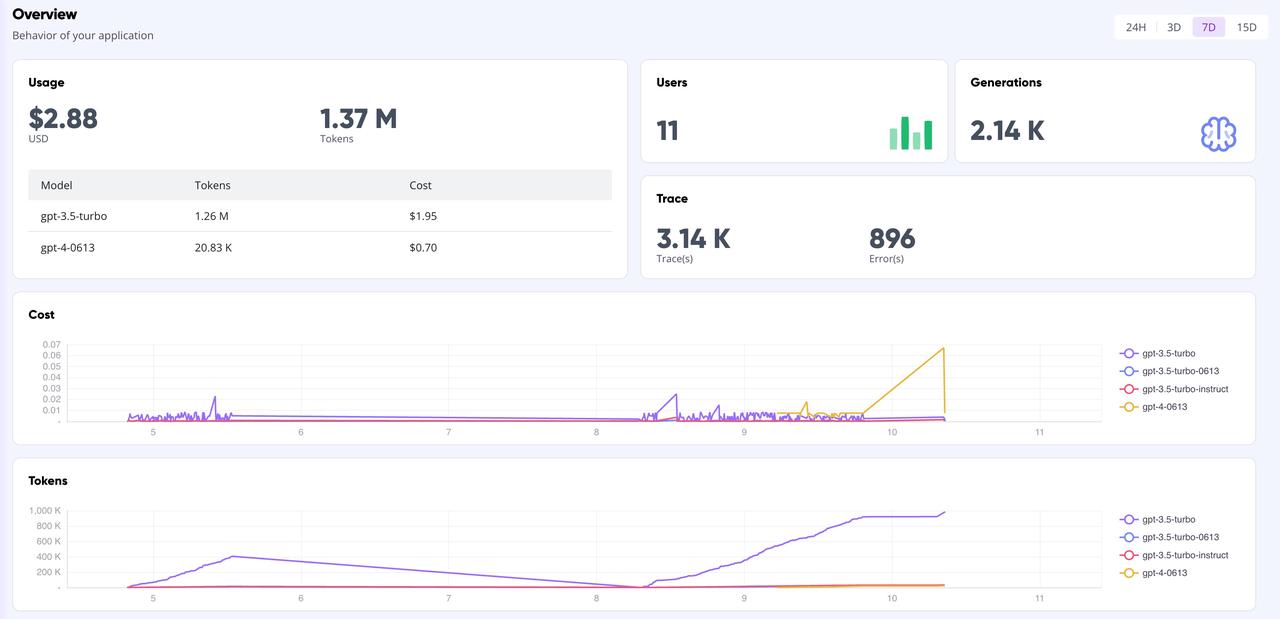
GreptimeAI-Werbetafel
Auf der GreptimeAI-Dashboard-Seite können Sie alle Anrufdaten basierend auf der OpenAI-Schnittstelle umfassend und in Echtzeit überwachen, einschließlich Schlüsselindikatoren wie Token, Kosten, Latenz, Trace usw. Unten sehen Sie die Übersichtsseite des Dashboards.
Zusammenfassen
Wenn Sie Open-Source-Modelle zum Erstellen von LLM-Anwendungen verwenden und den OpenAI-Stil für API-Aufrufe verwenden möchten, ist die Verwendung von Xinference zur Verwaltung des Inferenzmodells und die Verwendung von GreptimeAI zur Überwachung des Modellbetriebs eine gute Wahl. Unabhängig davon, ob Sie komplexe Datenanalysen oder einfache tägliche Abfragen durchführen, bietet Xinference leistungsstarke und flexible Modellverwaltungsfunktionen. Gleichzeitig können Sie in Kombination mit der Überwachungsfunktion von GreptimeAI die Leistung und den Ressourcenverbrauch des Modells effizienter verstehen und optimieren.
Wir freuen uns auf Ihre Versuche und freuen uns über den Austausch von Erfahrungen und Erkenntnissen mit GreptimeAI und Xinference. Lassen Sie uns gemeinsam die unendlichen Möglichkeiten der künstlichen Intelligenz erkunden!
Wenig Wissen über Greptime:
Greptime Greptime Technology wurde 2022 gegründet und verbessert und baut derzeit drei Produkte: die Zeitreihendatenbank GreptimeDB, GreptimeCloud und das Observability-Tool GreptimeAI.
GreptimeDB ist eine in der Rust-Sprache geschriebene Zeitreihendatenbank. Sie ist Open Source, cloudnativ und hochkompatibel. Sie hilft Unternehmen, Zeitreihendaten in Echtzeit zu lesen, zu schreiben, zu verarbeiten und zu analysieren und gleichzeitig die langfristigen Speicherkosten zu senken Bereitstellung eines vollständig verwalteten DBaaS-Dienstes, der in hohem Maße in Observability, Internet of Things und andere Bereiche integriert werden kann. GreptimeAI ist maßgeschneidert für LLM und bietet eine umfassende Überwachung von Kosten, Leistung und Generierungsprozessen.
GreptimeCloud und GreptimeAI wurden offiziell getestet. Folgen Sie dem offiziellen Account oder der offiziellen Website für die neuesten Entwicklungen!

Offizielle Website: https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
Dokumentation: https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime/
Ein in den 1990er Jahren geborener Programmierer hat eine Videoportierungssoftware entwickelt und in weniger als einem Jahr über 7 Millionen verdient. Das Ende war sehr bestrafend! High-School-Schüler erstellen im Rahmen einer Coming-of-Age-Zeremonie ihre eigene Open-Source-Programmiersprache – scharfe Kommentare von Internetnutzern: Der inländische Dienst Taobao (taobao.com) verließ sich aufgrund des grassierenden Betrugs auf RustDesk und stellte die inländischen Dienste ein und startete die Arbeit zur Optimierung der Webversion von Java neu 17 ist die am häufigsten verwendete Java LTS-Version. Windows 11 erreicht weiterhin einen Rückgang. Open Source Daily unterstützt die Übernahme von Open Source Rabbit R1; Electric schließt die offene Plattform Apple veröffentlicht M4-Chip Google löscht Android Universal Kernel (ACK) Unterstützung für RISC-V-Architektur Yunfeng ist von Alibaba zurückgetreten und plant, in Zukunft unabhängige Spiele für Windows-Plattformen zu produzieren