
Jeder ist herzlich willkommen, uns auf GitHub zu markieren:
Verteiltes Volllink-Kausallernsystem OpenASCE: https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
Großer modellgesteuerter Wissensgraph OpenSPG: https://github.com/OpenSPG/openspg
Groß angelegtes Graphenlernsystem OpenAGL: https://github.com/TuGraph-family/TuGraph-AntGraphLearning
Titel des Papiers: PEACE: Prototype lEarning Augmented übertragbares Framework für domänenübergreifende Empfehlungen
Organisationseinheit: Ant Group
Zulassungskonferenz: WSDM 2024
Link zum Papier : https://arxiv.org/abs/2312.0191 6
Der Autor dieses Artikels: Gan Chunjing. Die Hauptforschungsrichtungen sind Graphalgorithmen, Empfehlungsalgorithmen, große Sprachmodelle und die Anwendung von Wissensgraphen. Die Forschungsergebnisse werden in Mainstream-Konferenzen zum Thema maschinelles Lernen (WSDM/SIGIR/AAAI) einbezogen. Die Hauptarbeit des Teams im vergangenen Jahr bestand aus vorab trainierten Empfehlungsmodellen auf Basis von Wissensgraphen, großen Sprachmodellen auf Basis von Wissenserweiterung und deren Anwendungen, einschließlich des Graph-Neuronalen-Netzwerk-Frameworks auf Basis von Multigranularitätsentkopplung im Finanzmanagementszenario veröffentlicht in SIGIR'23 MGDL, dem Prototyp eines lernbasierten Entity Graph Pre-Training Cross-Domain-Empfehlungsframeworks PEACE, veröffentlicht bei WSDM'24.
Hintergrund
Mit der Entwicklung des Miniprogramm-Ökosystems von Alipay haben immer mehr Händler damit begonnen, Miniprogramme auf Alipay zu betreiben. Gleichzeitig hofft Alipay auch, durch Miniprogramm-Ökologie und Händler-Selbstbetrieb eine dezentrale Strategie zu erreichen.
Im Prozess der Selbstbedienung durch Händler haben immer mehr kleine und mittlere Händler einen Bedarf an digitalen und intelligenten Abläufen, wie z. B. der Verbesserung der Marketingeffizienz ihrer Mini-Programm-Privatdomain-Positionen durch personalisierte Empfehlungsfunktionen, aber für kleine und mittlere Unternehmen Bei mittelgroßen Handelsunternehmen sind die technischen Kosten und Arbeitskosten für den Aufbau selbst erstellter personalisierter KI-Empfehlungsfunktionen sehr hoch.
In diesem Zusammenhang hoffen wir, Händlern sichtbare, aber nicht zugängliche personalisierte Empfehlungs- und Suchfunktionen bereitzustellen, die auf den umfangreichen Daten zum Benutzerverhalten von Ant basieren, um Händlern dabei zu helfen, intelligente Miniprogramme zu erstellen, um den Umsatz der Händler auf der Alipay-Plattform zu steigern und den Benutzern ein besseres personalisiertes Erlebnis zu bieten Verbessern Sie die Benutzerbindung bei Alipay und können Sie außerdem gemeinsame technische Lösungen bündeln, um das Händler-/Benutzererlebnis weiter zu optimieren.
In der Branche gibt es viele erfolgreiche Anwendungsfälle, die Daten aus verhaltensorientierten Szenarien verwenden, um den Empfehlungseffekt in Mid- und Long-Tail-Szenarien zu verbessern. Beispielsweise verwendet Taobao die Verhaltensdaten der ersten Schätzung, um den Empfehlungseffekt in anderen kleinen Szenarien zu verbessern Fliggy nutzt die App und kleine Alipay-Szenarien, um den Empfehlungseffekt zu verbessern. Das Terminal modelliert gemeinsam den Gesamtempfehlungseffekt.
Diese Art von Methode sieht sich jedoch normalerweise mit mehreren Empfehlungsszenarien mit ähnlichen Mentalitäten konfrontiert und verwendet Szenariodaten mit reichhaltigem Verhalten, um den Empfehlungseffekt ähnlicher Szenarien mit spärlichem Verhalten wie Taobao, Fliggy usw. zu verbessern. Allerdings umfassen Super-APPs wie Alipay in der Regel verschiedene Miniprogramme wie Reisen, Regierungsangelegenheiten, Leasing, Reisen, Catering, Dinge des täglichen Bedarfs usw. Die mentalen Unterschiede zwischen den Benutzern in verschiedenen Miniprogrammen sind sehr groß, was uns ein Modell bietet Bringt großartig Herausforderungen:
- Die Miniprogramme von Alipay sind in vertikalen Branchen mit sehr unterschiedlichen Geschäftszweigen wie Regierungsangelegenheiten, Lebensmittel, Leasing, Einzelhandel und Finanzmanagement verstreut. Im Allgemeinen werden Informationen zwischen diesen Miniprogrammen nicht ausgetauscht, und ähnliche Elemente weisen möglicherweise keine ähnlichen Merkmale auf Durch die direkte Übertragung mehrerer Verhaltensweisen in der gesamten Domäne auf ein bestimmtes vertikales Klassenszenario, ohne solche domänenübergreifenden Unterschiede auszugleichen, ist es für das Modell schwierig, aus den gemischten Verhaltensweisen mehrerer vertikaler Klassen nützliches Wissen für die vertikale Klasse zu lernen, und es kann sogar sein, dass dies der Fall ist negative Migration herbeiführen;
- Obwohl eine Punkt-zu-Punkt-Migration des Benutzerverhaltens, beispielsweise in der Lebensmittelindustrie, nur das gastronomische Verhalten der Benutzer bei Alipay verwendet, kann die oben genannten Probleme bis zu einem gewissen Grad lindern, aber jedes Mal, wenn eine neue Branche hinzugefügt wird, ist ein manueller Eingriff erforderlich , was kostspielig ist und nicht die gesamte Kette realisieren kann, hoffen einige Händler auch, dass die Alipay-Plattform bei der ersten Verbindung personalisierte Plug-and-Play-Empfehlungslösungen bereitstellen kann, selbst wenn keine Daten zum Benutzerverhalten vorliegen . Ein solches Modell ist in dieser Situation nicht realisierbar.
Basierend auf den oben genannten Herausforderungen haben wir PEACE vorgeschlagen, ein auf Prototypenlernen basierendes Graph-Pre-Training-Framework zum Transferlernen mit mehreren Szenarien, das auf dem Problem großer Unterschiede zwischen vertikalen Industriedomänen basiert.
Wir haben den Entitätsgraphen eingeführt und hofften, den Entitätsgraphen als Brücke zu verwenden, um die Unterschiede zwischen verschiedenen Domänen zu verbinden und seine negativen Auswirkungen auf die Modellierung abzumildern. Der Entitätsgraph in der Produktionsumgebung ist jedoch normalerweise riesig, obwohl er eine große Anzahl enthält Allerdings führt die wahllose Aggregation von Strukturinformationen in der Entitätskarte normalerweise zu einer Verringerung der Robustheit des Modells. Daher haben wir Prototypenlernen eingeführt, um die Entitätsdarstellung zu verbessern einschränken.
Insgesamt ist das PEACE-Framework die Migrationsdesignidee von ONE FOR ALL. Wir verwenden das Multi-Source-Public-Domain-Verhalten der Benutzer in Alipay als Input für das Pre-Training-Modell und lernen die Interessen und Vorlieben der Benutzer aus mehreren Branchen kennen Eins durch die Idee der entkoppelten Darstellung, kombiniert mit dem Prototypennetzwerk, das Branchensignale erfasst, muss lediglich ein einheitliches Modell vorab trainiert werden, um die vielfältigen Interessen der Benutzer für personalisierte Empfehlungen adaptiv in verschiedene nachgelagerte vertikale Branchen zu migrieren ( normale Empfehlung + Nullschuss empfohlen).
PEACE – Entity Graph Pre-Training, domänenübergreifendes Empfehlungsframework basierend auf Prototyp-Lernen
Vorläufige domänenübergreifende Wissensausrichtung basierend auf einem Entitätsdiagramm
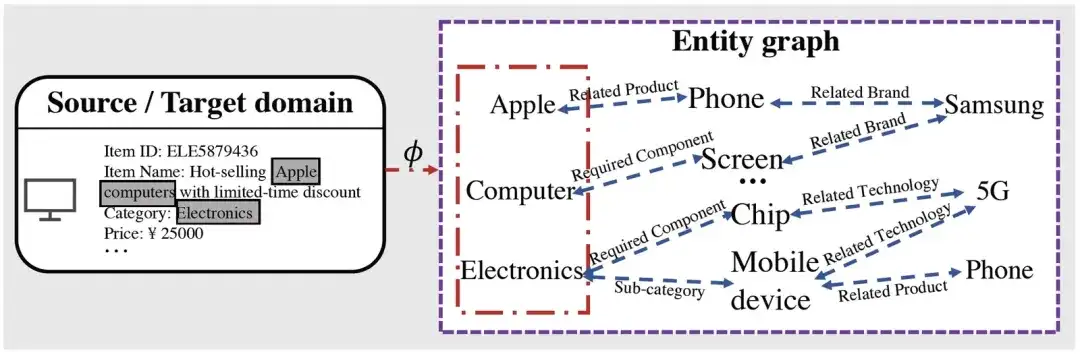

Es ist ersichtlich, dass wir nach dem Abrufen der Entität, die sich auf das entsprechende Element bezieht, auf der Grundlage des Diagrammbegründungsprozesses viele Informationen auf hoher Ebene erhalten können, die sich auf die zugeordnete Entität beziehen. Beispielsweise verfügt Apple über Mobiltelefonprodukte und Unternehmen im Zusammenhang mit Mobiltelefonprodukten Es gibt Samsung usw., was möglicherweise die Beziehung zu anderen verbundenen Unternehmen (z. B. von Samsung hergestellten Mobiltelefonen usw.) verkürzen kann.
Modellrahmen
In diesem Abschnitt stellen wir das in diesem Artikel vorgeschlagene domänenübergreifende Empfehlungsframework PEACE vor. Die folgende Abbildung zeigt die Gesamtarchitektur von PEACE. Insgesamt basiert unser Gesamtrahmen auf dem entitätsorientierten Vortrainingsmodul , um eine domänenübergreifende Ausrichtung zu erreichen und die Strukturinformationen im Entitätsdiagramm besser zu nutzen Um die Darstellung vor dem Training vielseitiger und übertragbarer zu machen, schlagen wir ein Modul zur Verbesserung der Entitätsdarstellung vor, das auf dem Prototyp-Kontrastlernen basiert, und ein Modul zur Verbesserung der Benutzerdarstellung, das auf dem Aufmerksamkeitsmechanismus zur Prototypenverbesserung basiert , um die Darstellung zu verbessern. Auf dieser Grundlage definieren wir Optimierungsziele und einfacher Online-Bereitstellungsprozess in der Vorschulungsphase und der Feinabstimmungsphase . Als nächstes stellen wir jedes Modul einzeln vor.
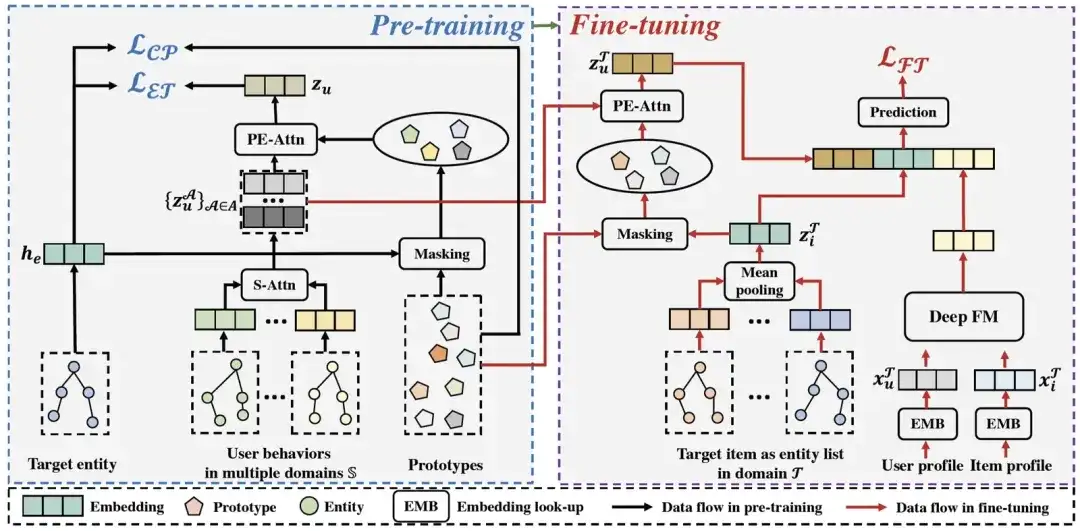
PEACE-Gesamtarchitektur
01. Entitätsorientiertes Vorschulungsmodul
Online-Dienstplattformen wie Alipay sammeln eine Vielzahl kleiner Programme/Szenarien, die von verschiedenen Dienstanbietern bereitgestellt werden. Im Allgemeinen sind die Informationen zwischen diesen Szenarien nicht interoperabel und es gibt daher kein gemeinsames Datensystem, selbst wenn sie von derselben Marke sind Kategorie: Die Attribute der aktuellen Produkte können nicht vollständig angepasst werden (z. B. haben iPhone 14, die in verschiedenen Mini-Programmen verkauft werden, unterschiedliche Produkt-IDs und Kategorienamen. Beispielsweise handelt es sich bei der Kategorie um elektronische Produkte in einem Mini-Programm und bei der Kategorie um Elektronik in ein weiteres Miniprogramm). Um die durch diese potenziellen Probleme verursachten Unterschiede und deren Auswirkungen auf die Modellierungsleistung zu verringern und gleichzeitig diese interaktiven Informationen besser zu nutzen, führen wir ein Vortraining basierend auf der Entitätskarte durch, in der Hoffnung, entitätsgranulare Informationen einzuführen Auf diese Weise erreichen Sie ein Vortraining mit stärkerer Generalisierung.


Nehmen wir als Beispiel Abbildung 1: Wenn es sich um Artikel → Entität → Entität handelt, können wir ausgehend von diesem Produkt für Apple nur wissen, dass es sich bei den zugehörigen Produkten um Telefone handelt, aber durch Vorschulung von Entität → Entität → Entität können wir es wissen dass Apple nicht nur mit verwandten Produkten wie Phone verwandt ist, können wir auch wissen, dass es mit dem Unternehmen Samsung verwandt ist, wodurch die Verallgemeinerung der Darstellungen, die wir gelernt haben, weiter verbessert wird.
02. Modul zur Verbesserung der Entitätsdarstellung basierend auf prototypischem kontrastivem Lernen

03. Modul zur Verbesserung der Benutzerdarstellung basierend auf dem Prototyp eines verbesserten Aufmerksamkeitsmechanismus
In der Vorschulungsphase enthalten die in der Quelldomäne gesammelten Daten Benutzerverhalten in verschiedenen Szenarien. Wenn Benutzer beispielsweise Reisepläne erstellen, besuchen sie reisebezogene Szenarien und bei der Jobsuche besuchen sie Online-Stellenangebote. Die im vorherigen Schritt erlernte benutzerspezifische Darstellung berücksichtigt jedoch nicht den Kontext, der sich auf den Benutzer und die Szene bezieht, was es unmöglich macht, die szenenbezogene Darstellung in verschiedenen Szenen zu erfassen Verwenden Sie den Aufmerksamkeitsmechanismus, um die Kontexterfassung zu verbessern und die Benutzerdarstellung zu verbessern.

04. Modelltraining und Vorhersage
- Link zum Vortraining der Quelldomäne
Durch die Kombination des entitätsorientierten Pre-Training-Moduls und des Prototyp-Learning-Enhancement-Moduls kann das Gesamtoptimierungsziel wie folgt definiert werden:
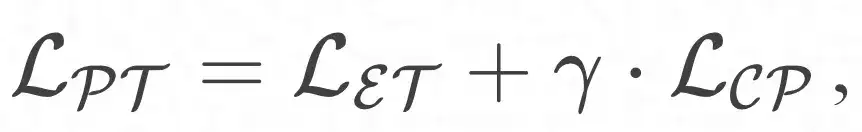

- Link zur Feinabstimmung der Zieldomäne

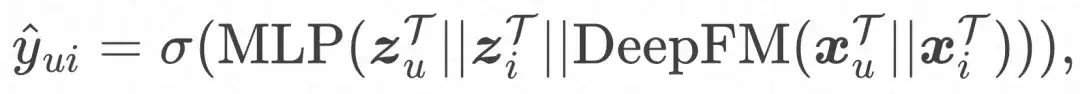
Und die endgültige Verlustfunktion:
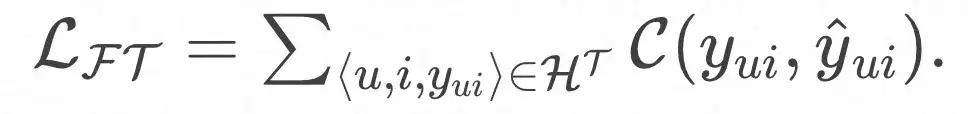

Online-Bereitstellung
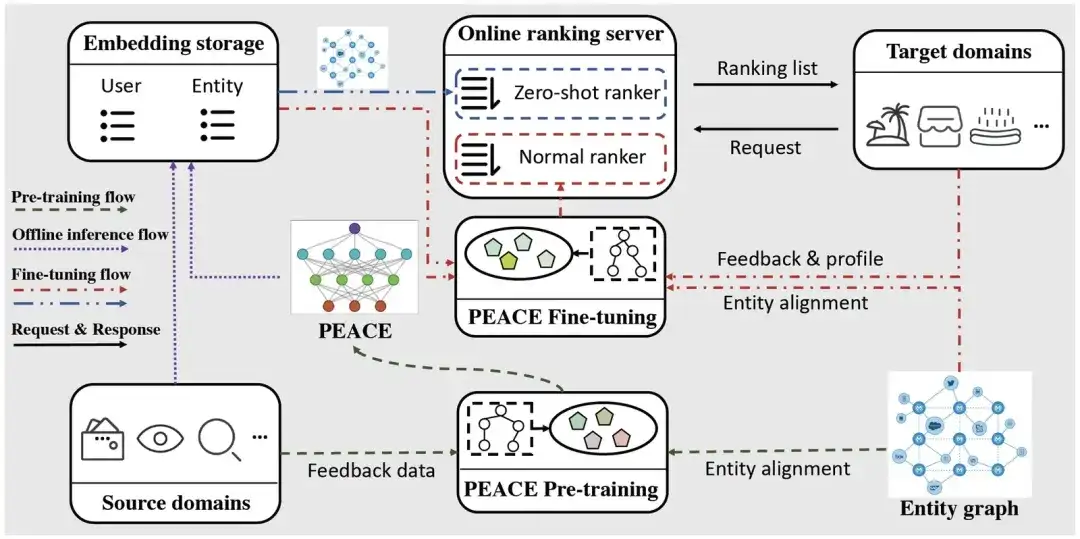
Um den Druck auf Online-Dienste zu verringern, verwenden wir eine einfache Methode zur Bereitstellung des PEACE-Modells. Der Bereitstellungsablauf ist hauptsächlich in drei Teile unterteilt:
- Ablauf vor dem Training: Basierend auf den gesammelten Verhaltensdaten und Entitätskarten aus mehreren Quellen aktualisieren wir das PEACE-Modell täglich, damit das Modell zeitkritisches und universell übertragbares Wissen erlernen kann. Das vorab trainierte Modell speichern wir in ModelHub, um das einfache Laden von Modellparametern für die nachgelagerte Verwendung zu erleichtern.
- Offline-Inferenzfluss: Um die Belastung des Online-Dienstsystems durch das graphische neuronale Netzwerk zu verringern, werden wir die Darstellungen von Benutzer und Entität im Voraus ableiten und sie dann nur während der nachgelagerten Feinabstimmung in der ODPS-Tabelle speichern Das endgültige MLP Das Netzwerk wird feinabgestimmt, ohne den Informationsverbreitungsprozess im graphischen neuronalen Netzwerk erneut durchzuführen, wodurch die Latenz von Online-Diensten erheblich reduziert wird.
- Feinabstimmungsablauf: Da neu gestartete Miniprogramme/Dienste keine interaktiven Daten haben, stellt PEACE Empfehlungsdienste in den folgenden zwei Schritten bereit:
- Für das Kaltstartszenario können wir durch direktes Berechnen des inneren Produkts der Benutzer- und Artikeldarstellungen die Präferenz des Benutzers für verschiedene Artikel ermitteln und diese direkt sortieren.
- Für Nicht-Kaltstart-Szenarien, in denen eine bestimmte Datenmenge angesammelt wurde, führen wir eine Feinabstimmung auf der Grundlage der vorab trainierten Benutzer-/Artikeldarstellung und der Benutzer-/Artikel-Basisinformationen durch und verwenden dann das fein abgestimmte Modell für Online-Dienste.
Wirksamkeitsanalyse
Offline-Experiment
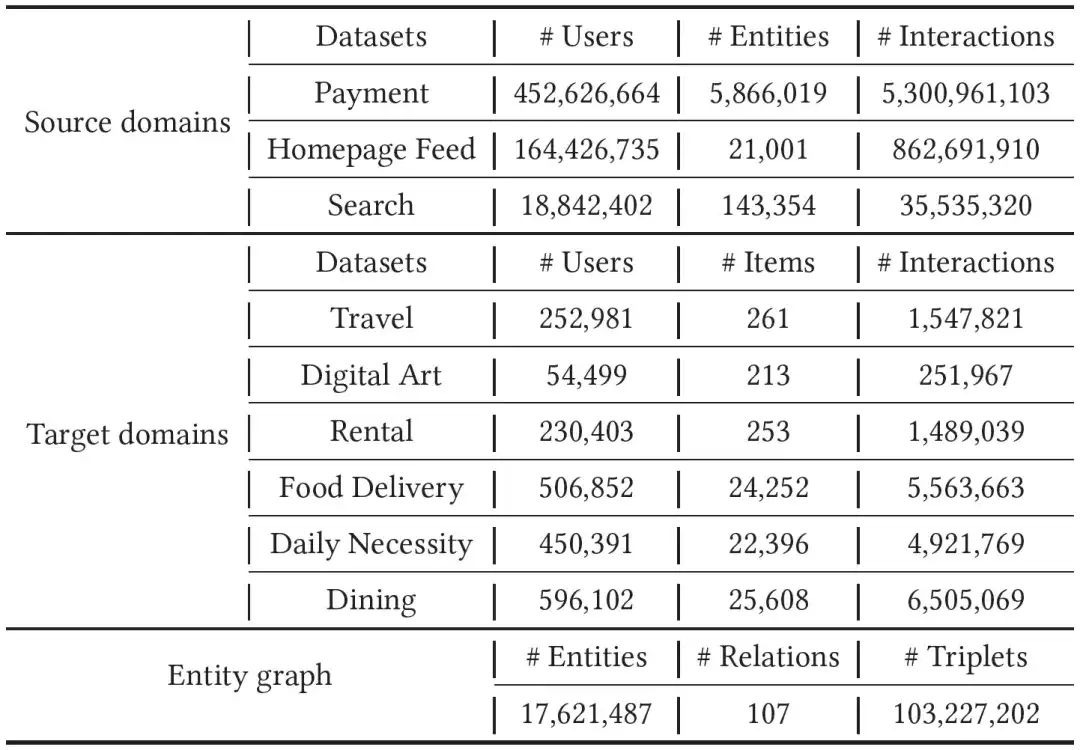
01. Dateneinführung
Wir haben die Alipay-Rechnungen, Fußabdrücke und Suchdaten eines Monats als Quelldomänendaten gesammelt. Für die Zieldomäne haben wir Experimente mit sechs Arten von Miniprogrammen durchgeführt, nämlich Vermietung, Reisen, digitale Sammlungen, Dinge des täglichen Bedarfs, Gourmetessen und Lebensmittellieferung . Da die Daten der Zieldomäne spärlicher sind als die der Quelldomäne, haben wir in den letzten zwei Monaten Verhaltensdaten für das Modelltraining gesammelt. Um die großen Unterschiede zwischen verschiedenen Domänen zu überbrücken, haben wir einen Entitätsgraphen mit mehreren zehn Millionen Knoten, Hunderten von Beziehungen und Milliarden von Kanten eingeführt. Spezifische Daten finden Sie in der folgenden Tabelle.
02. Wirksamkeitsexperiment
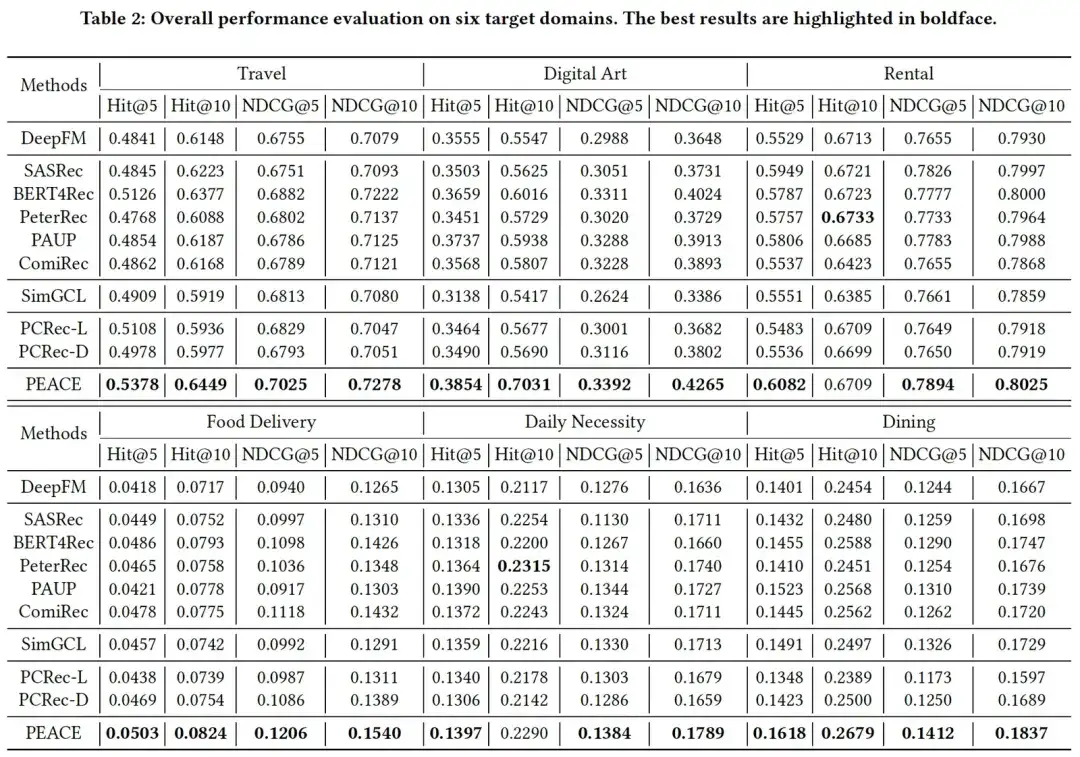
Wenn wir die experimentellen Ergebnisse in den beiden Tabellen kombinieren, können wir feststellen, dass die experimentellen Ergebnisse insgesamt Folgendes zeigen:
- PEACE hat im Vergleich zur Basislinie sowohl in Kaltstart- als auch in Nicht-Kaltstart-Szenarien erhebliche Verbesserungen erzielt, was die Wirksamkeit der Kombination von auf Entitätsgranularität basierenden Vortrainings- und prototypischen lernbasierten Verbesserungsmechanismen demonstriert;
- In den meisten Fällen weist das vorab trainierte + feinabgestimmte Modell eine größere Verbesserung auf als das Basismodell von DeepFM ohne Vortraining, was die Wirksamkeit der Einführung von Daten aus mehreren Quellen für das Vortraining verdeutlicht. In einigen Fällen ist die Leistung jedoch geringer Das Modell ist nicht so gut wie das Basismodell von DeepFM, und es gibt einen gewissen Grad an negativer Übertragung, was die Bedeutung der Vortrainingsmethoden weiter verdeutlicht.
- In vielen Fällen haben auf GNN basierende domänenübergreifende Empfehlungsmodelle keine guten experimentellen Ergebnisse erzielt. Dies ist größtenteils auf das große Rauschen im Entitätsdiagramm zurückzuführen, da wir durch Clustering ähnliche Entitäten erstellt haben haben ähnliche Abstände im Darstellungsraum, während der Abstand zwischen verschiedenen Entitäten weiter gedehnt wird, wodurch die negativen Auswirkungen dieser Geräusche auf das Modell abgemildert werden.
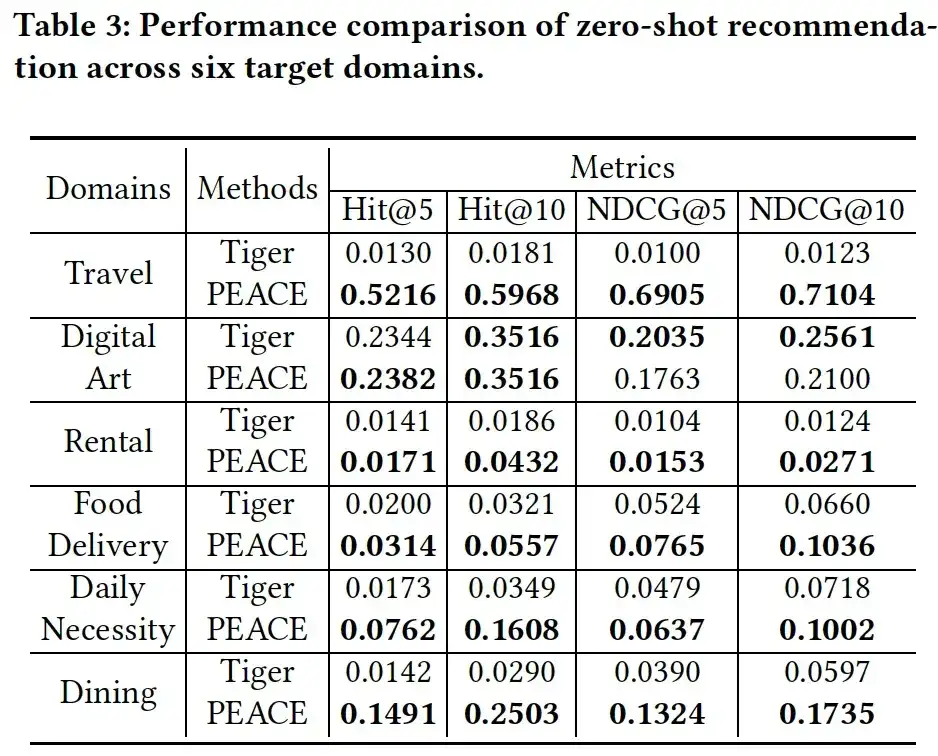
03. Ablationsanalyse
Um die Rolle jedes Moduls im PEACE-Modell weiter zu überprüfen, haben wir die folgenden drei Varianten vorbereitet, um die Wirksamkeit jedes Moduls zu bewerten:
- PEACE ohne GL, das Graph-Lernmodul, wenn Entitätsdarstellungen entfernt werden;
- PEACE ohne CPL, d. h. Entfernung des vergleichsbasierten Prototyp-Lernmoduls;
- PEACE ohne PEA, wodurch das Aufmerksamkeitsmechanismusmodul basierend auf der Prototypenverbesserung entfernt wird. Wie aus Abbildung 4 ersichtlich ist, sinkt die Modellleistung erheblich, wenn jedes Modul entfernt wird. Dies verdeutlicht die Bedeutung des prototypischen Lernens für die Erfassung allgemein übertragbaren Wissens.
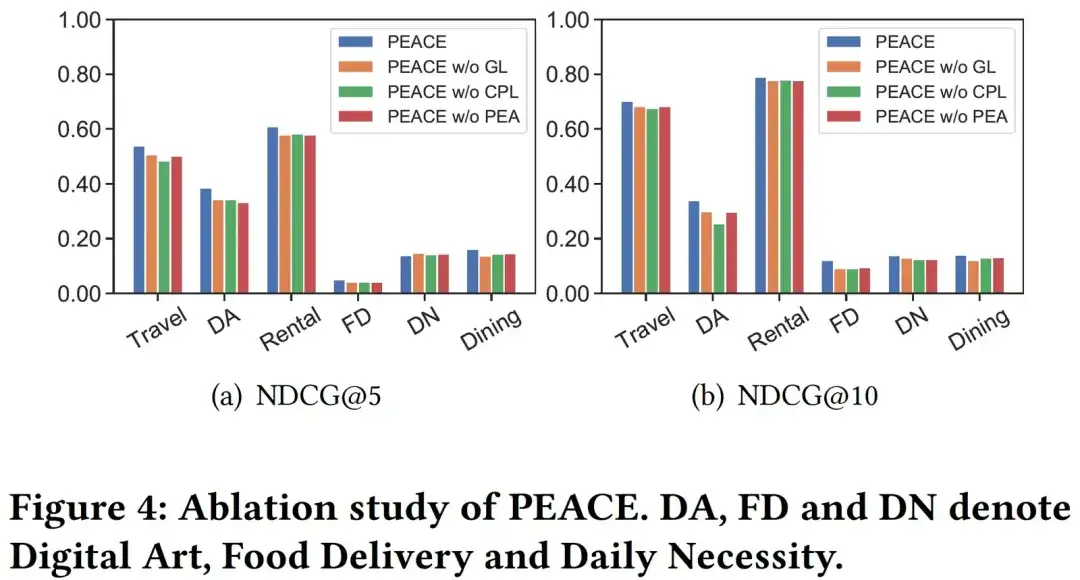
04. Visuelle Analyse
Um die Wirkung des CPL-Moduls genauer zu analysieren, haben wir zufällig 6000 Entitäten in der Entitätskarte ausgewählt und ihre Entitätsdarstellungen durch PEACE ohne CPL- und PEACE-Modelle gelernt, um sie zu visualisieren. Hier sind verschiedene Farben, die verschiedenen zugehörigen Prototypen entsprechen an verschiedene Entitäten. Aus Abbildung 5 können wir ersehen, dass im Vergleich zur von PEACE ohne CPL erlernten Entitätsdarstellung die vom vollständigen PEACE-Modell erlernte Darstellung eine bessere Kohärenz in den Clustering-Ergebnissen aufweist, was das CPL-Modul und seinen erlernten Prototyp veranschaulicht Das Modell verringert den Abstand zwischen ähnlichen Entitäten im Darstellungsraum und hilft so dem Modell besser, robusteres und universelleres Wissen zu erlernen.
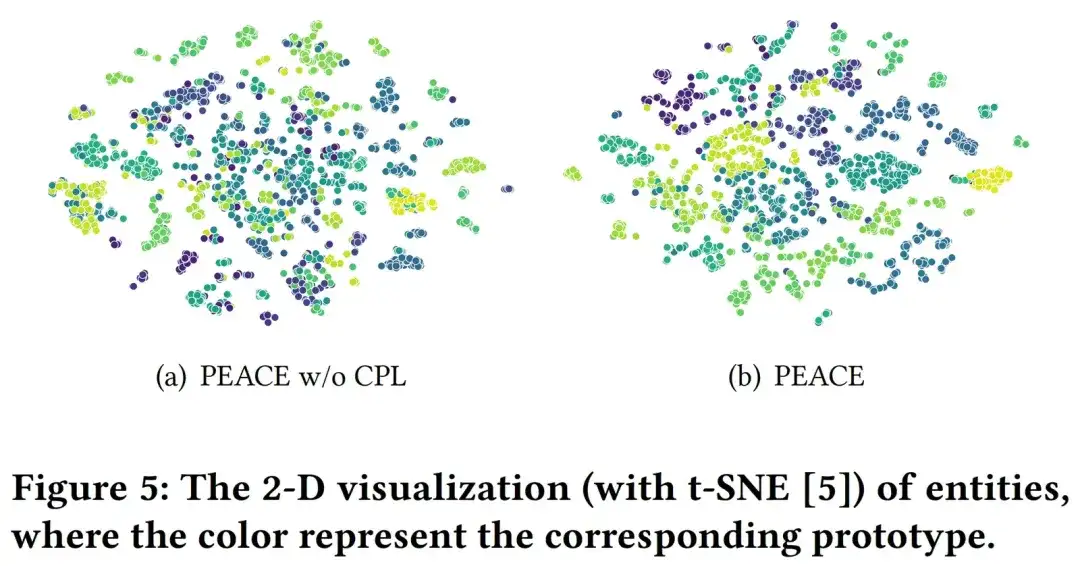
Online-Experimente und Geschäftsumsetzung
Um die Wirkung des Modells in der tatsächlichen Produktionsumgebung besser zu überprüfen, haben wir verfeinerte Online-AB-Experimente bei mehreren Händlern in verschiedenen vertikalen Kategorien durchgeführt. In mehreren Szenarien hat das PEACE-Modell im Vergleich zur Basisförderung effektive Ergebnisse erzielt. Insgesamt wurde das PEACE-basierte Pre-Training + Transfer-Learning-Empfehlungsmodell vollständig als Basismodell bei mehr als 50 Händlern angewendet, um personalisierte Empfehlungen bereitzustellen, nachdem es durch AB-Effekte bei wichtigen Händlern überprüft wurde.
Artikelempfehlungen
OpenSPG v0.0.3 wird veröffentlicht und bietet eine einheitliche Wissensextraktion und Diagrammvisualisierung für große Modelle als Open Source! Ant Group und die Zhejiang-Universität veröffentlichen gemeinsam OneKE, ein Open-Source-Framework zur Wissensextraktion großer Modelle
Paper Digest |. GPT-RE: Kontextlernen zur Beziehungsextraktion basierend auf großen Sprachmodellen
Folgen Sie uns
OpenSPG:
Offizielle Website: https://spg.openkg.cn
Github: https://github.com/OpenSPG/openspg
OpenASCE:
Quelle: https://openasce.openfinai.org/
GitHub: [https://github.com/Open-All-Scale-Causal-Engine/OpenASCE ]