
Anmerkung des Herausgebers: Derzeit sind große Sprachmodelle zu einem heißen Thema im Bereich der Verarbeitung natürlicher Sprache geworden. Sind LLMs wirklich „smart“? Welche Inspirationen haben sie uns gebracht? Als Antwort auf diese Fragen präsentiert uns Darveen Vijayan diesen zum Nachdenken anregenden Artikel.
Der Autor erklärt hauptsächlich zwei Punkte: Erstens sollten LLMs als Wortrechner betrachtet werden, der das nächste Wort vorhersagt, und sollten zu diesem Zeitpunkt nicht als „intelligent“ eingestuft werden. Zweitens bieten uns LLMs trotz ihrer derzeitigen Einschränkungen die Möglichkeit, über die Natur der menschlichen Intelligenz nachzudenken. Wir sollten einen offenen Geist bewahren, ständig nach neuem Wissen und neuen Wissensverständnissen streben und aktiv mit anderen kommunizieren, um unsere kognitiven Grenzen zu erweitern.
Ob LLMs smart sind oder nicht, ist wahrscheinlich immer noch umstritten. Aber eines ist sicher: Sie haben Innovationen auf dem Gebiet der Verarbeitung natürlicher Sprache gebracht und neue Dimensionen des Denkens über die Natur der menschlichen Intelligenz geschaffen. Es lohnt sich, diesen Artikel sorgfältig zu lesen und für jeden Benutzer großer Modellierungstools und KI-Praktiker durchzukauen.
Autor |. Darveen Vijayan
Zusammengestellt |. Yue Yang
Im frühen 17. Jahrhundert stand ein Mathematiker und Astronom namens Edmund Gaunt vor einer beispiellosen astronomischen Herausforderung: Um die komplexen Bewegungen der Planeten zu berechnen und Sonnenfinsternisse vorherzusagen, mussten sich Astronomen nicht nur auf ihre Intuition verlassen, sondern auch komplexe logarithmische und trigonometrische Operationen beherrschen Gleichungen. Also beschloss Gunter, wie jeder gute Innovator, ein analoges Computergerät zu erfinden! Das von ihm entwickelte Gerät wurde schließlich als Rechenschieber[1] bekannt.
Der Rechenschieber ist ein 30 cm langer rechteckiger Holzblock, der aus einem festen Rahmen und einem verschiebbaren Teil besteht. Der feste Rahmen beherbergt eine feste logarithmische Skala, während der verschiebbare Teil eine bewegliche Skala beherbergt. Um einen Rechenschieber verwenden zu können, müssen Sie die Grundprinzipien der Logarithmen verstehen und wissen, wie Sie die Skalen für Multiplikationen, Divisionen und andere mathematische Operationen ausrichten. Es ist notwendig, den beweglichen Teil so zu verschieben, dass die Zahlen ausgerichtet sind, das Ergebnis abzulesen und auf die Position des Dezimalpunkts zu achten. Ups, das ist wirklich zu kompliziert!
 Rechenschieber
Rechenschieber
Etwa 300 Jahre später, im Jahr 1961, stellte die Bell Punch Company den ersten elektronischen Tischrechner vor, den „ANITA Mk VII“. Im Laufe der Jahrzehnte wurden elektronische Rechenmaschinen immer komplexer und verfügten über immer mehr Funktionen. Aufgaben, die früher manuelle Berechnungen erforderten, nehmen weniger Zeit in Anspruch, sodass sich die Mitarbeiter auf analytischere und kreativere Arbeiten konzentrieren können. Daher machen moderne elektronische Rechenmaschinen nicht nur die Arbeit effizienter, sondern ermöglichen es den Menschen auch, Probleme besser zu lösen.
Der Taschenrechner stellte eine große Veränderung in der Art und Weise dar, wie Mathematik betrieben wurde, aber was ist mit der Sprache?
Überlegen Sie, wie Sie Ihre Sätze strukturieren. Zuerst müssen Sie eine Idee haben (was bedeutet dieser Satz). Als nächstes müssen Sie eine Menge Vokabeln beherrschen (genügend Vokabeln haben). Anschließend müssen Sie in der Lage sein, diese Wörter korrekt in Sätze zu setzen (Grammatik erforderlich). Ups, es ist immer noch so kompliziert!

Bereits vor 50.000 Jahren, als der moderne Homo sapiens zum ersten Mal die Sprache schuf, ist die Art und Weise, wie wir Wörter für die Sprache erzeugen, weitgehend unverändert geblieben.
Wir sind wohl immer noch wie Gunter, der beim Satzbau einen Rechenschieber verwendet!
Man kann mit Fug und Recht sagen, dass wir uns immer noch in Gunthers Ära befinden, in der er beim Bilden von Sätzen einen Rechenschieber verwendet!
Wenn Sie darüber nachdenken, bedeutet die Verwendung des richtigen Vokabulars und der korrekten Grammatik, dass Sie den Regeln der Sprache folgen.
Es ist ähnlich wie in der Mathematik. Die Mathematik ist voller Regeln, sodass ich 1+1=2 und die Funktionsweise des Taschenrechners herausfinden kann!
Wir brauchen einen Taschenrechner für Wörter!
Was wir brauchen, ist ein Taschenrechner, außer für Worte!
Ja, verschiedene Sprachen müssen unterschiedliche Regeln befolgen, aber nur durch Befolgen der Sprachregeln kann die Sprache verstanden werden. Ein klarer Unterschied zwischen Sprache und Mathematik besteht darin, dass es in der Mathematik feste und bestimmte Antworten gibt, während es viele vernünftige Wörter geben kann, die in einen Satz passen.
Versuchen Sie, den folgenden Satz auszufüllen: Ich habe ein _________ gegessen. (Ich habe ein _________ gegessen.) Stellen Sie sich die Wörter vor, die als nächstes kommen könnten. Es gibt etwa 1 Million Wörter in der englischen Sprache. Hier könnten viele Wörter verwendet werden, aber sicherlich nicht alle.
Die Antwort „Schwarzes Loch“ ist gleichbedeutend mit der Aussage 2+2=5. Außerdem ist die Antwort „Apfel“ ungenau. Warum? Wegen grammatikalischer Einschränkungen!

In den letzten Monaten haben Large Language Models (LLMs) [2] die Welt im Sturm erobert. Manche nennen es einen großen Durchbruch auf dem Gebiet der Verarbeitung natürlicher Sprache, andere betrachten es als den Beginn einer neuen Ära der künstlichen Intelligenz (KI).
LLM hat sich als sehr gut bei der Generierung menschenähnlicher Texte erwiesen, was die Messlatte für sprachbasierte KI-Anwendungen höher legt. Mit seiner umfangreichen Wissensbasis und seinem hervorragenden Kontextverständnis kann LLM in verschiedenen Bereichen eingesetzt werden, von der Sprachübersetzung und der Inhaltserstellung bis hin zu virtuellen Assistenten und Chatbots für den Kundensupport.
Befinden wir uns heute an einem ähnlichen Wendepunkt wie bei den elektronischen Taschenrechnern in den 1960er-Jahren?
Bevor wir diese Frage beantworten, wollen wir zunächst verstehen, wie LLM funktioniert. LLM basiert auf einem neuronalen Transformer-Netzwerk und wird verwendet, um das nächstbeste Wort in einem Satz zu berechnen und vorherzusagen. Um ein leistungsstarkes neuronales Transformer-Netzwerk aufzubauen, muss es anhand einer großen Menge an Textdaten trainiert werden. Aus diesem Grund funktioniert der Ansatz „Nächstes Wort oder Token vorhersagen“ so gut: Weil es viele leicht verfügbare Trainingsdaten gibt. LLM nimmt eine ganze Folge von Wörtern als Eingabe und sagt das nächstwahrscheinlichste Wort voraus. Um das wahrscheinlichste nächste Wort zu lernen, haben sie sich aufgewärmt, indem sie alle Wikipedia-Daten, dann Stapel von Büchern und schließlich das gesamte Internet verschlungen haben.
Wir haben bereits früher festgestellt, dass Sprache Regeln und Muster enthält. Das Modell lernt diese Regeln implizit durch alle diese Sätze, um die Aufgabe der Vorhersage des nächsten Wortes abzuschließen.
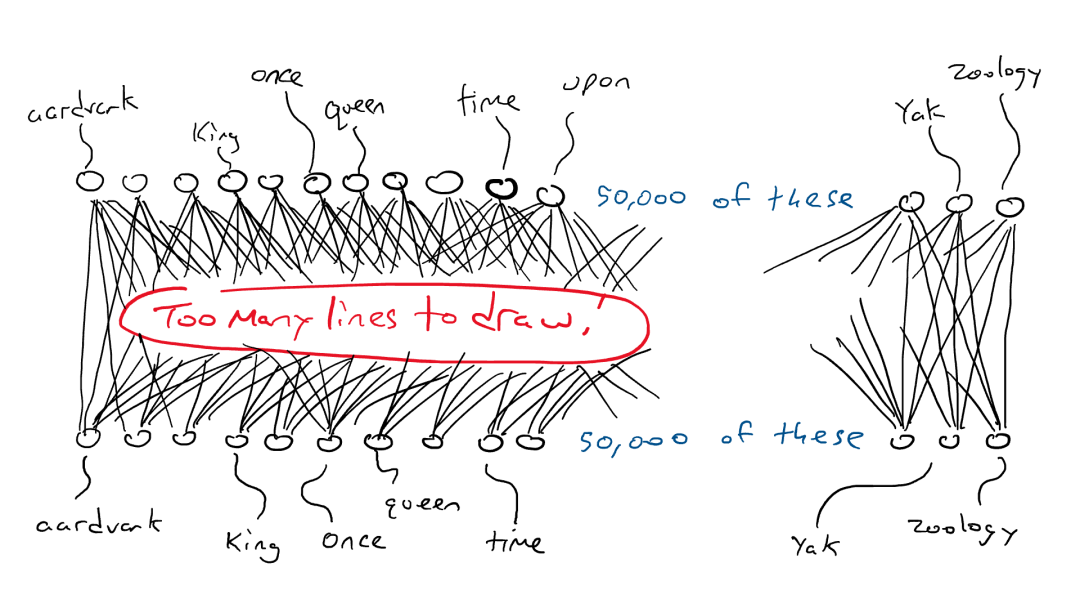
tiefes neuronales Netzwerk
Nach einem Substantiv im Singular steigt die Wahrscheinlichkeit, dass ein Verb im nächsten Wort auf „s“ endet. Ebenso steigt beim Lesen von Shakespeares Werken die Wahrscheinlichkeit, dass Wörter wie „doth“ und „when“ vorkommen.
Während des Trainings lernt das Modell diese Sprachmuster und wird schließlich zum Sprachexperten!
Aber ist es genug? Reicht es aus, einfach nur die Regeln einer Sprache zu lernen?
Aber reicht das? Reicht das Erlernen sprachlicher Regeln?

Sprache ist komplex und ein Wort kann je nach Kontext mehrere Bedeutungen haben.
Daher ist Selbstaufmerksamkeit erforderlich. Einfach ausgedrückt ist Selbstaufmerksamkeit eine Technik, die Sprachlerner nutzen, um die Beziehungen zwischen verschiedenen Wörtern in einem Satz oder Artikel zu verstehen. So wie Sie sich auf verschiedene Teile einer Geschichte konzentrieren würden, um sie zu verstehen, ermöglicht die Selbstaufmerksamkeit LLM, bei der Verarbeitung von Informationen mehr Gewicht auf bestimmte Wörter in einem Satz zu legen. Auf diese Weise kann das Modell die Gesamtbedeutung und den Kontext des Textes besser verstehen, anstatt blind das nächste Wort allein auf der Grundlage von Sprachregeln vorherzusagen.

Selbstaufmerksamkeitsmechanismus
Wenn ich mir ein großes Sprachmodell als einen Wortrechner vorstelle, der einfach das nächste Wort vorhersagt, wie kann es dann alle meine Fragen beantworten?
Wenn LLMs Rechner für Wörter sind, die nur das nächste Wort vorhersagen, wie können sie dann alle meine Fragen beantworten?
Wenn Sie ein großes Sprachmodell mit der Bewältigung einer Aufgabe beauftragen, die Nachdenken erfordert, und es erfolgreich ist, liegt das wahrscheinlich daran, dass es die Aufgabe, die Sie ihm gegeben haben, in Tausenden von Beispielen gesehen hat. Auch wenn Sie einige sehr spezielle Anforderungen haben, wie zum Beispiel:
„Schreiben Sie ein Gedicht über einen Killerwal, der Hühnchen frisst“
Schreib mir ein Gedicht über einen Orca, der ein Huhn frisst
Auch große Sprachmodelle können die von Ihnen zugewiesenen Aufgaben erfolgreich erledigen:
Inmitten der Wellen ein ungesehener Anblick. Ein Orca jagt schnell und scharfsinnig. Im Reich des Ozeans beginnt der Tanz. Wie das Schicksal eines Huhns siegt der Orca.
Mit mächtigen Kiefern greift es nach der Beute, Federn schweben und treiben davon. Auf die Art und Weise der Natur wird eine Geschichte gesponnen, in der Leben und Tod eins werden.
~ ChatGPT
Nicht schlecht, oder? Dies ist seinem Selbstaufmerksamkeitsmechanismus zu verdanken, der es ihm ermöglicht, relevante Informationen effektiv zusammenzuführen und abzugleichen, um eine vernünftige und kohärente Antwort zu erstellen.
Während des Trainings lernen große Sprachmodelle (LLMs), Muster, Assoziationen und Beziehungen zwischen Wörtern (und Phrasen) in den Daten zu erkennen. Nach umfassender Schulung und Feinabstimmung kann LLM neue Funktionen wie Sprachübersetzung, Erstellung von Zusammenfassungen, Beantwortung von Fragen und sogar kreatives Schreiben bieten. Obwohl dem Modell bestimmte Aufgaben oder Fähigkeiten nicht direkt beigebracht werden, kann das Modell durch Lernen und Training auf großen Datenmengen Fähigkeiten zeigen, die die Erwartungen übertreffen, und eine hervorragende Leistung erbringen
Sind große Sprachmodelle also intelligent?
Sind große Sprachmodelle intelligent?
Elektronische Taschenrechner gibt es schon seit mehr als sechzig Jahren. Dieses Tool machte sprunghafte Fortschritte in der Technologie, galt aber nie als intelligent. Warum?
Der Turing-Test ist eine einfache Methode, um festzustellen, ob eine Maschine über menschliche Intelligenz verfügt: Wenn eine Maschine mit Menschen auf eine Weise kommunizieren kann, die sie nicht unterscheidbar macht, dann spricht man von menschlicher Intelligenz.
Ein Taschenrechner wurde noch nie einem Turing-Test unterzogen [3], da er nicht in derselben Sprache wie Menschen kommuniziert, sondern nur in der mathematischen Sprache. Große Sprachmodelle erzeugen jedoch menschliche Sprache. Sein gesamter Trainingsprozess dreht sich um die Nachahmung der menschlichen Sprache. Daher ist es nicht verwunderlich, dass es „auf eine Weise mit Menschen sprechen kann, die sie nicht mehr zu unterscheiden macht“.
Daher ist die Verwendung des Begriffs „intelligent“ zur Beschreibung großer Sprachmodelle etwas schwierig, da es keinen klaren Konsens über die wahre Definition von Intelligenz gibt. Ob etwas intelligent ist, lässt sich daran erkennen, ob es etwas Interessantes, Nützliches und mit einem bestimmten Grad an Komplexität oder Kreativität tun kann. Große Sprachmodelle passen sicherlich zu dieser Definition. Allerdings bin ich mit dieser Interpretation nicht ganz einverstanden.
Ich definiere Intelligenz als die Fähigkeit, die Grenzen des Wissens zu erweitern.
Ich definiere Intelligenz als die Fähigkeit, die Grenzen des Wissens zu erweitern.
Zum jetzigen Zeitpunkt können Maschinen, die das nächste Zeichen/Wort vorhersagen, die Grenzen des Wissens noch nicht erweitern.
Es kann jedoch auf Basis vorhandener Daten abgeleitet und ausgefüllt werden. Es kann weder die Logik hinter den Worten klar verstehen noch den vorhandenen Wissensbestand verstehen. Es kann keine innovativen Ideen oder tiefe Erkenntnisse hervorbringen. Es kann nur relativ allgemeine Antworten geben, aber keine bahnbrechenden Ideen hervorbringen.

Welche Auswirkungen oder Implikationen hat die Unfähigkeit von Maschinen, innovatives Denken und tiefgreifende Erkenntnisse zu generieren, auf uns Menschen?
Was bedeutet das also für uns Menschen?
Wir sollten uns große Sprachmodelle (LLMs) eher als Wortrechner vorstellen. Unser Denkprozess sollte nicht vollständig von großen Modellen abhängig sein, sondern als Hilfe für unser Denken und Ausdrucken und nicht als Ersatz betrachtet werden.
Gleichzeitig kann es sein, dass wir uns zunehmend überfordert und überfordert fühlen, wenn die Anzahl der Parameter in diesen großen Modellen exponentiell wächst. Mein Rat dazu ist, immer neugierig auf scheinbar unabhängige Ideen zu bleiben. Manchmal stoßen wir auf scheinbar nicht zusammenhängende oder widersprüchliche Ideen, aber durch unsere Beobachtung, Wahrnehmung, Erfahrung, unser Lernen und die Kommunikation mit anderen können wir feststellen, dass zwischen diesen Ideen möglicherweise ein Zusammenhang besteht oder dass diese Ideen vernünftig sein könnten. (Anmerkung des Übersetzers: Diese Verbindung kann aus unserer Beobachtung, unserem Verständnis und unserer Interpretation von Dingen oder aus neuen Ideen entstehen, die durch die Korrelation von Wissen und Konzepten in verschiedenen Bereichen entstehen. Wir sollten einen offenen Geist bewahren und uns nicht nur auf oberflächliche Intuitionen beschränken, sondern beobachten und wahrnehmen , erleben, lernen und mit anderen kommunizieren, um tiefere Bedeutungen und Zusammenhänge zu entdecken.) Wir sollten uns nicht damit zufrieden geben, nur im Bekannten zu bleiben, sondern sollten aktiv neue Bereiche erkunden und unsere kognitiven Grenzen ständig erweitern. Wir sollten auch ständig nach neuen Erkenntnissen oder neuen Erkenntnissen über bereits erworbenes Wissen suchen und diese mit vorhandenem Wissen kombinieren, um neue Erkenntnisse und Ideen zu schaffen.
Wenn Sie in der Lage sind, so zu denken und zu handeln, wie ich es beschreibe, werden alle Formen von Technologie, sei es ein Taschenrechner oder ein großes Sprachmodell, zu einem Werkzeug, das Sie nutzen können, und nicht zu einer existenziellen Bedrohung, über die Sie sich Sorgen machen müssen.
ENDE
Verweise
[3] https://en.wikipedia.org/wiki/Turing_test
Dieser Artikel wurde von Baihai IDP mit Genehmigung des ursprünglichen Autors zusammengestellt. Wenn Sie die Übersetzung erneut drucken müssen, kontaktieren Sie uns bitte für die Genehmigung.
Ursprünglicher Link:
https://medium.com/the-modern-scientist/large-lingual-models-a-calculator-for-words-7ab4099d0cc9
RustDesk stellt inländische Dienste wegen grassierendem Betrug ein. Apple veröffentlicht M4-Chip. Taobao (taobao.com) startet die Arbeit zur Optimierung der Webversion neu. Oberstufenschüler erstellen ihre eigene Open-Source-Programmiersprache als Geschenk für das Erwachsenwerden – kritische Kommentare von Internetnutzern: Verlassen Sie sich auf die Verteidigung Yunfeng ist von Alibaba zurückgetreten und plant , in Zukunft Java 17 als Ziel für unabhängige Spieleprogrammierer . Es ist die am häufigsten verwendete Java LTS-Version mit einem Marktanteil von 70 % und Windows 11 gehen weiter zurück. Google unterstützt die Übernahme von Open-Source-Rabbit. Microsoft hat die offene Plattform geschlossen