
Jeder ist herzlich willkommen, uns auf GitHub zu markieren:
Verteiltes Volllink-Kausallernsystem OpenASCE: https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
Großer modellgesteuerter Wissensgraph OpenSPG: https://github.com/OpenSPG/openspg
Groß angelegtes Graphenlernsystem OpenAGL: https://github.com/TuGraph-family/TuGraph-AntGraphLearning
Am 25. und 26. April fand im Hyatt Regency Global Harbor Hotel in Shanghai die Global Machine Learning Technology Conference statt! Wang Qinlong, Leiter von Open Source DLRover bei der Ant Group, hielt auf der Konferenz eine Grundsatzrede zum Thema „DLRover Training Fault Self-Healing: Significantly Improving the Computing Power Efficiency of Large-Scale AI Training“ und erläuterte, wie man sich schnell von selbst heilen kann Wang Qinlong stellte die technischen Prinzipien und Anwendungsfälle von DLRover sowie die praktischen Auswirkungen von DLRover auf große Community-Modelle vor.

Wang Qinlong, der sich seit langem mit der Forschung und Entwicklung der KI-Infrastruktur bei Ant beschäftigt, leitete den Aufbau der elastischen Fehlertoleranz und der automatischen Expansions- und Kontraktionsprojekte des verteilten Ant-Trainings. Er hat an mehreren Open-Source-Projekten wie ElasticDL und DLRover teilgenommen, wurde 2023 Vibrant Open Source Contributor der Open Atomic Foundation und 2022 T-Star Outstanding Engineer der Ant Group. Derzeit ist er Architekt des Open-Source-Projekts DLRover Ant AI Infra, dessen Schwerpunkt auf dem Aufbau stabiler, skalierbarer und effizienter verteilter Trainingssysteme im großen Maßstab liegt.
Großes Modelltraining und Herausforderungen
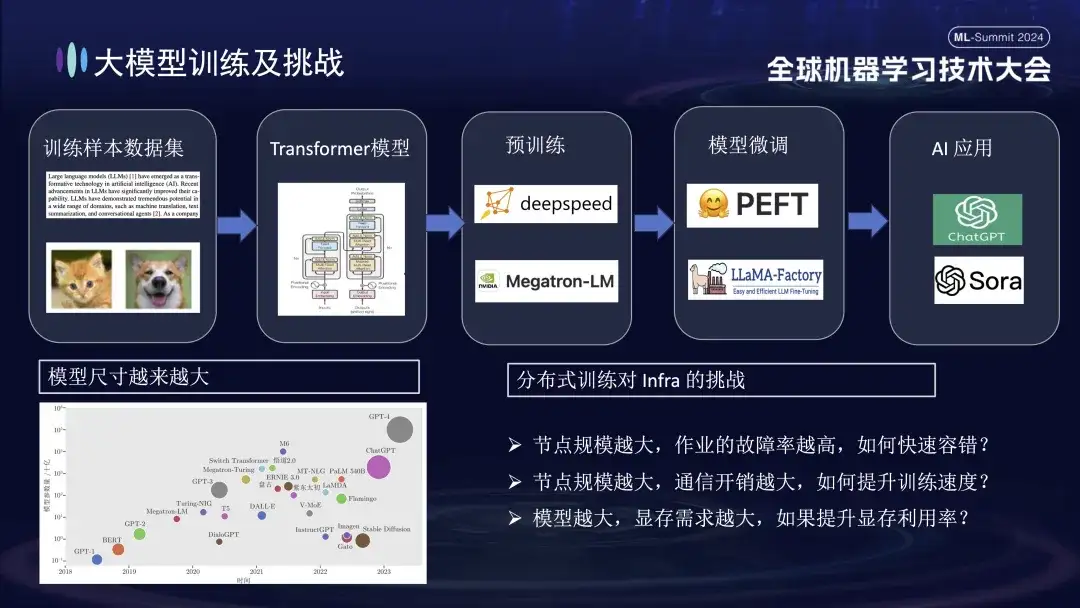
Der grundlegende Prozess des Trainings großer Modelle ist in der obigen Abbildung dargestellt. Er erfordert die Vorbereitung von Trainingsbeispieldatensätzen, die Erstellung des Transformer-Modells, das Vortraining, die Feinabstimmung des Modells und schließlich die Erstellung einer Benutzer-KI-Anwendung. Da große Modelle von einer Milliarde Parametern auf eine Billion Parameter umsteigen, hat die Zunahme des Trainingsumfangs zu einem Anstieg der Clusterkosten geführt und auch die Stabilität des Systems beeinträchtigt. Die hohen Betriebs- und Wartungskosten, die ein so großes System mit sich bringt, sind zu einem dringenden Problem geworden, das beim Training großer Modelle gelöst werden muss.
- Je größer die Knotengröße, desto höher ist die Job-Fehlerrate. Wie kann man Fehler schnell tolerieren ?
- Je größer die Knotengröße, desto größer der Kommunikationsaufwand. Wie kann die Trainingsgeschwindigkeit verbessert werden ?
- Je größer die Knotengröße, desto größer der Speicherbedarf. Wie kann die Speicherauslastung verbessert werden ?
Ant AI Engineering-Technologie-Stack
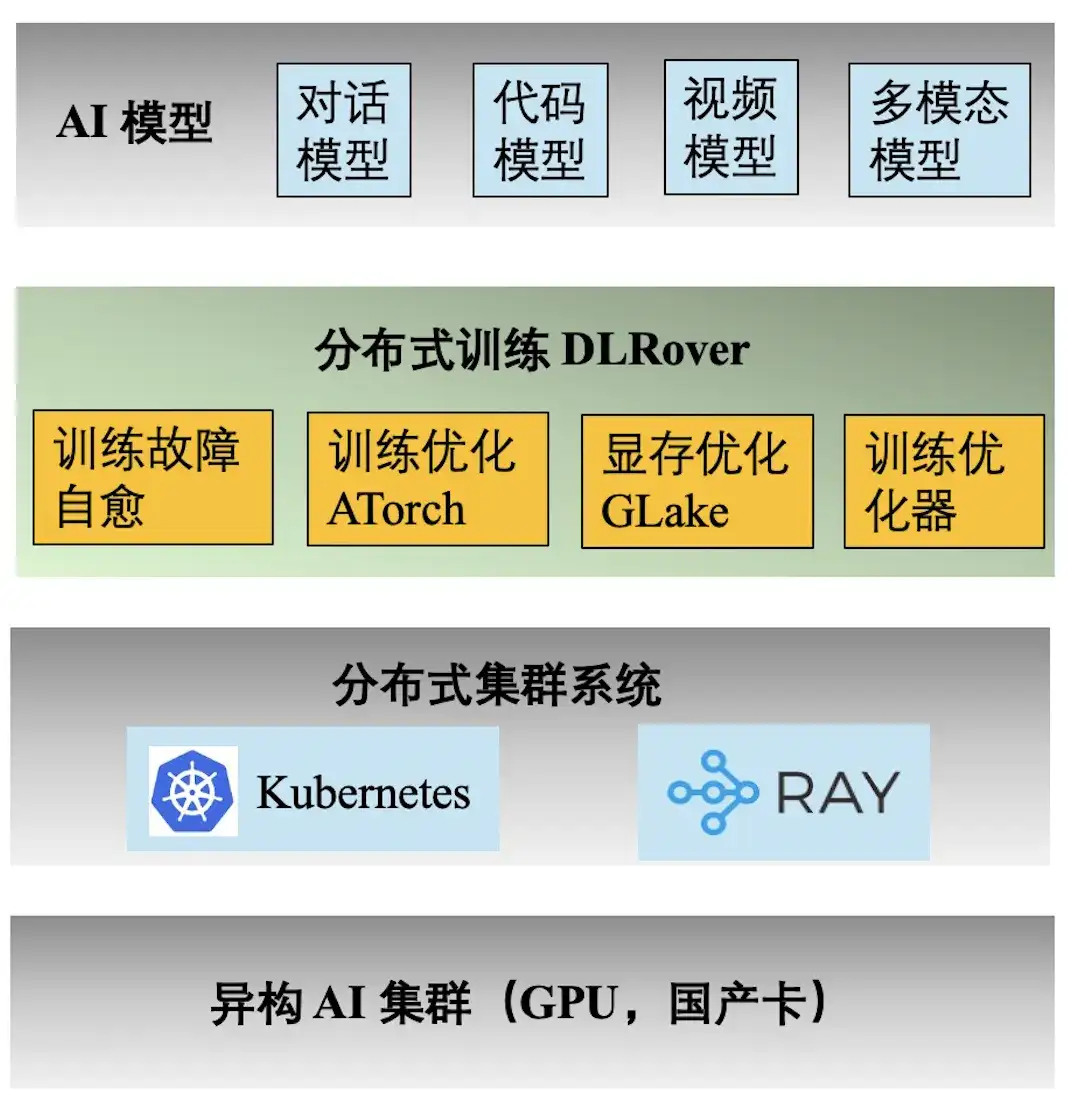
Die obige Abbildung zeigt den technischen Technologie-Stack des Ant-KI-Trainings. Die verteilte Trainings-Engine DLRover unterstützt eine Vielzahl von Trainingsaufgaben für die Dialog-, Code-, Video- und multimodalen Modelle von Ant. Im Folgenden sind die Hauptfunktionen von DLRover aufgeführt:
- **Selbstheilung von Trainingsfehlern:** Erhöhen Sie die effektive Zeit des Kilokalorien-verteilten Trainings auf >97 %, wodurch die Rechenleistungskosten für groß angelegte Trainingsfehler gesenkt werden;
- **Trainingsoptimierung ATorch:** Wählen Sie automatisch die optimale verteilte Trainingsstrategie basierend auf Modell und Hardware aus. Erhöhen Sie die Rechenleistungsauslastung der Kcal (A100)-Cluster-Hardware auf >60 %;
- **Trainingsoptimierer:** Der Optimierer entspricht der Navigation der Modelliteration und kann uns dabei helfen, das Ziel auf dem kürzesten Weg zu erreichen. Unser Optimierer verbessert die Konvergenzbeschleunigung um das 1,5-fache im Vergleich zu AdamW. Relevante Ergebnisse wurden in ECML PKDD '21, KDD'23, NeurIPS '23 veröffentlicht;
- **Videospeicher- und Übertragungsoptimierung GLake: **Während des Trainingsprozesses großer Modelle werden viele Videospeicherfragmente generiert, was die Nutzung der Videospeicherressourcen erheblich reduziert. Wir reduzieren den Trainingsspeicherbedarf um das Zwei- bis Zehnfache durch integrierte Speicher- und Übertragungsoptimierung sowie globale Speicheroptimierung. Die Ergebnisse wurden auf ASPLOS'24 veröffentlicht.
Warum Ausfälle zu einer Verschwendung von Rechenleistung führen
Der Grund, warum Ant dem Problem von Trainingsfehlern besondere Aufmerksamkeit schenkt, liegt hauptsächlich darin, dass Maschinenausfälle während des Trainingsprozesses die Trainingskosten erheblich erhöhen. Meta gab beispielsweise die tatsächlichen Daten für sein großes Modelltraining im Jahr 2022 bekannt. Beim Training des OPT-175B-Modells wurden 992 80-GB-A100-GPUs verwendet, insgesamt 124 8-Karten-Maschinen, was laut AWS-GPU-Preisen etwa 700.000 kostet pro Tag. . Aufgrund des Ausfalls wurde der Trainingszyklus um mehr als 20 Tage verlängert, wodurch sich die Kosten für die Rechenleistung um mehrere zehn Millionen Yuan erhöhten.

Das Bild unten zeigt die Verteilung der Fehler, die beim Training großer Modelle auf Alibaba Cloud-Clustern auftreten. Einige dieser Fehler können durch einen Neustart behoben werden, während andere nicht durch einen Neustart behoben werden können. Zum Beispiel das Karten-Drop-Problem, weil die fehlerhafte Karte nach dem Neustart immer noch beschädigt ist. Die beschädigte Maschine muss ausgetauscht werden, bevor das System neu gestartet und wiederhergestellt werden kann.
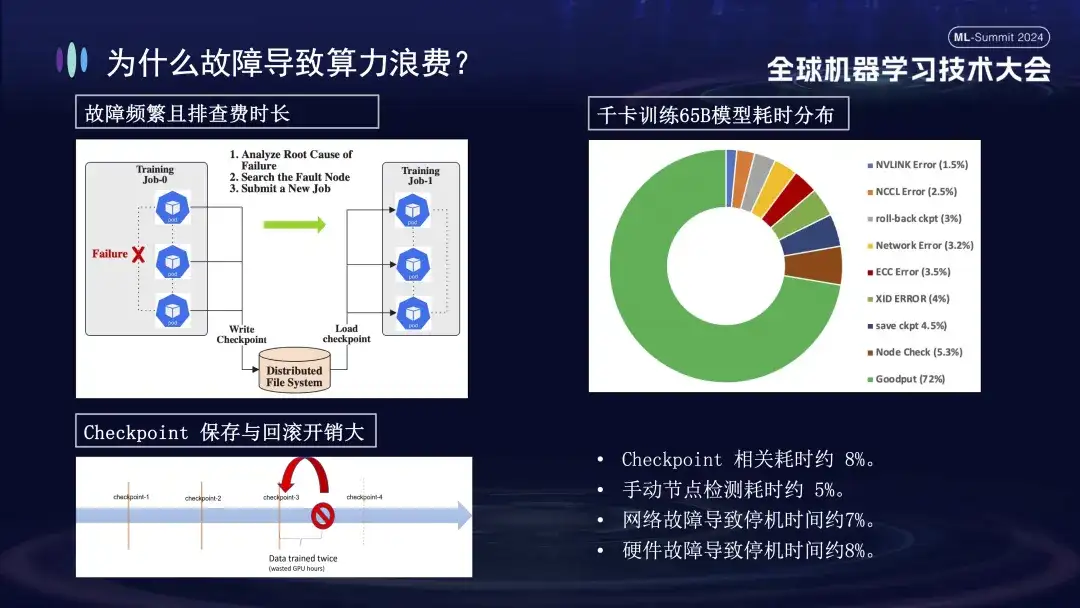
Warum haben Trainingsausfälle so große Auswirkungen? Zunächst erfordert das verteilte Training die Zusammenarbeit mehrerer Knoten. Wenn ein Knoten ausfällt (sei es ein Software-, Hardware-, Netzwerkkarten- oder GPU-Problem), muss der gesamte Trainingsprozess angehalten werden. Zweitens ist die Fehlerbehebung nach einem Trainingsfehler zeitaufwändig und mühsam. Beispielsweise erfordert die häufig verwendete manuelle Inspektionsmethode jetzt mindestens 1-2 Stunden für die einmalige Überprüfung. Schließlich ist das Training zustandsbehaftet, Sie müssen den vorherigen Trainingszustand wiederherstellen, bevor Sie fortfahren, und der Trainingszustand muss nach einer gewissen Zeit gespeichert werden. Der Speichervorgang dauert lange und ein fehlgeschlagenes Rollback führt ebenfalls zu einer Verschwendung von Berechnungen. Das rechte Bild oben zeigt die Verteilung der Trainingszeit, bevor wir online gehen, um die Selbstheilung durchzuführen. Es ist ersichtlich, dass die relevante Zeit des Checkpoints etwa 8 % beträgt, die Zeit der manuellen Knotenerkennung etwa 5 % und die verursachte Ausfallzeit Durch Netzwerkausfälle entstehen etwa 7 %, Hardwareausfälle verursachen etwa 8 % der Ausfallzeiten und die endgültige effektive Trainingszeit beträgt nur etwa 72 %.
Übersicht über die Selbstheilungsfunktionen von DLRover-Trainingsfehlern

Das Bild oben zeigt die beiden Kernfunktionen von DLRover in der Fehlerselbstheilungstechnologie. Erstens kann Flash Checkpoint den Status schnell speichern, ohne den Trainingsprozess zu stoppen, und eine Hochfrequenzsicherung erreichen. Dies bedeutet, dass das System im Falle eines Ausfalls sofort vom letzten Prüfpunkt wiederhergestellt werden kann, wodurch Datenverluste und Trainingszeiten reduziert werden. Zweitens nutzt DLRover Kubernetes, um einen intelligenten elastischen Planungsmechanismus zu implementieren. Dieser Mechanismus kann automatisch auf Knotenausfälle reagieren. Wenn beispielsweise einer in einem Cluster von 100 Maschinen ausfällt, stellt sich das System automatisch auf 99 Maschinen ein, um das Training ohne manuelles Eingreifen fortzusetzen. Darüber hinaus ist es mit Kubeflow und PyTorchJob kompatibel und stärkt die Funktionen zur Überwachung des Knotenzustands, um sicherzustellen, dass Fehler schnell erkannt und innerhalb von 10 Minuten behoben werden, wodurch die Kontinuität und Stabilität des Trainingsbetriebs gewahrt bleibt.
DLRover elastisches Fehlertoleranztraining
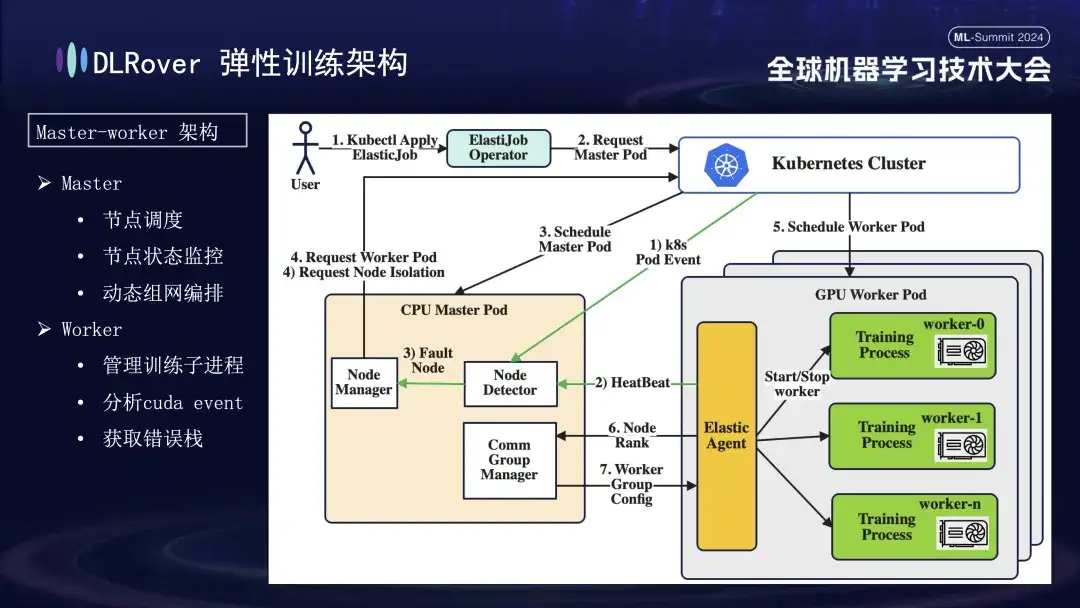
DLRover übernimmt eine Master-Worker-Architektur, die in den frühen Tagen des maschinellen Lernens nicht üblich war. Bei diesem Design dient der Master als Kontrollzentrum und ist für wichtige Aufgaben wie Knotenplanung, Statusüberwachung, Netzwerkkonfigurationsverwaltung und Fehlerprotokollanalyse verantwortlich, ohne dass der Trainingscode ausgeführt werden muss. Wird normalerweise auf CPU-Knoten bereitgestellt. Die Arbeiter tragen die eigentliche Trainingslast, und jeder Knoten führt mehrere Unterprozesse aus, um die mehreren GPUs des Knotens zur Beschleunigung von Rechenaufgaben zu nutzen. Um die Robustheit des Systems zu erhöhen, haben wir außerdem den Elastic Agent auf dem Worker angepasst und verbessert, um eine effektivere Fehlererkennung und -lokalisierung zu ermöglichen und Stabilität und Effizienz während des Trainingsprozesses sicherzustellen.
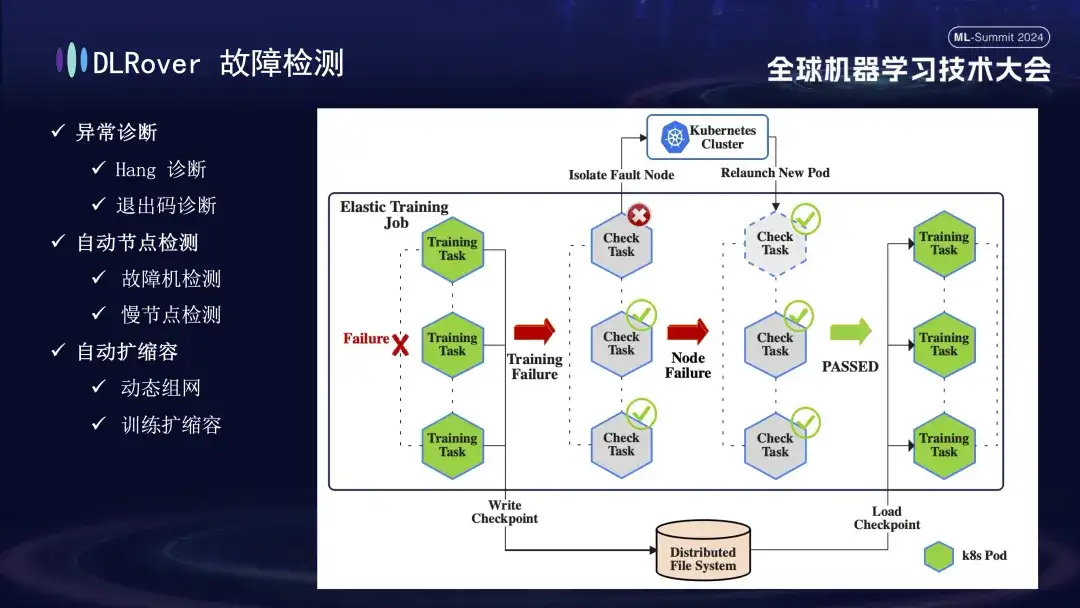
Als nächstes folgt der Fehlererkennungsprozess. Wenn während des Trainingsprozesses ein Fehler auftritt und die Aufgabe unterbrochen wird, besteht die intuitive Leistung darin, dass das Training unterbrochen wird, die spezifische Ursache und Quelle des Fehlers jedoch nicht direkt ersichtlich sind, da bei Auftreten eines Fehlers alle zugehörigen Maschinen gleichzeitig anhalten . Um dieses Problem zu lösen, haben wir das Erkennungsskript sofort nach dem Auftreten des Fehlers auf allen Computern ausgeführt. Sobald festgestellt wird, dass ein Knoten die Inspektion nicht besteht, wird der Kubernetes-Cluster sofort benachrichtigt, den ausgefallenen Knoten zu entfernen und einen neuen Ersatzknoten erneut bereitzustellen. Der neue Knoten führt weitere Gesundheitsprüfungen mit den vorhandenen Knoten durch. Nachdem alles korrekt ist, wird die Trainingsaufgabe automatisch neu gestartet. Es ist erwähnenswert, dass wir eine Reduzierungsstrategie implementieren (wird später ausführlich vorgestellt), wenn ein fehlerhafter Knoten isoliert wird und unzureichende Ressourcen verursacht. Wenn die ursprünglich fehlerhafte Maschine wieder in den Normalzustand zurückkehrt, führt das System automatisch Kapazitätserweiterungsvorgänge durch, um ein effizientes und kontinuierliches Training sicherzustellen.
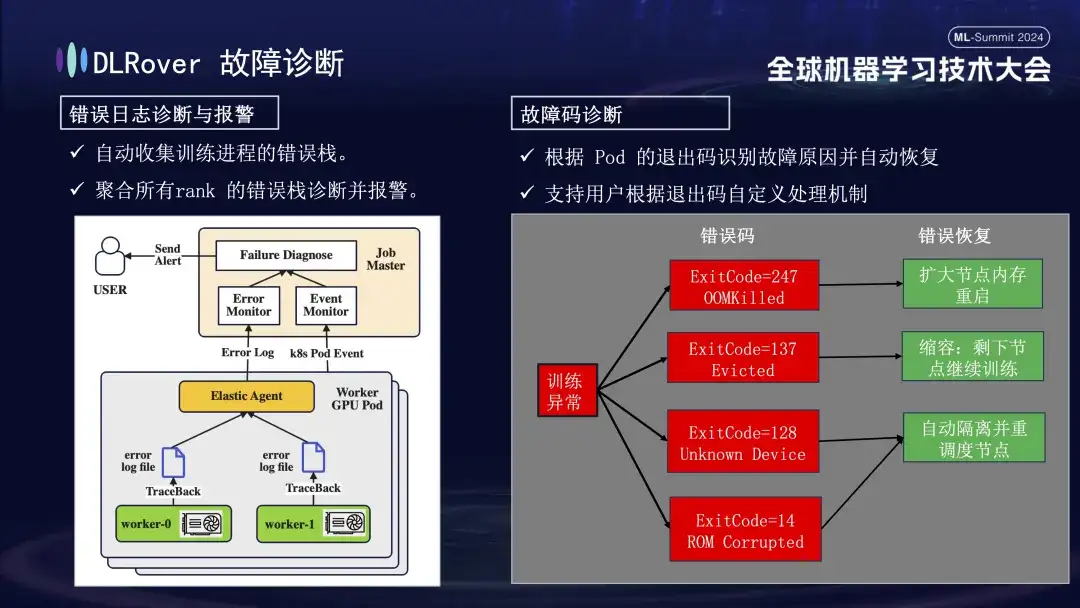
Als nächstes folgt der Fehlerdiagnoseprozess, der die folgenden umfassenden Methoden nutzt, um eine schnelle und genaue Fehlerlokalisierung und -bearbeitung zu erreichen:
- Zunächst sammelt der Agent Fehlerinformationen aus jedem Trainingsprozess und fasst diese Fehlerstapel im Masterknoten zusammen. Der Masterknoten analysiert dann die aggregierten Fehlerdaten, um die Maschine mit dem Problem zu lokalisieren. Zeigt beispielsweise ein Maschinenprotokoll einen ECC-Fehler, wird der Maschinenfehler direkt ermittelt und behoben.
- Darüber hinaus kann der Exit-Code von Kubernetes auch zur Unterstützung der Diagnose verwendet werden. Der Exit-Code 137 zeigt beispielsweise normalerweise an, dass die zugrunde liegende Computerplattform die Maschine aufgrund eines erkannten Problems beendet Möglicherweise ist der GPU-Treiber fehlerhaft. Es gibt auch eine große Anzahl von Fehlern, die nicht durch Exit-Codes erkannt werden können, darunter Netzwerk-Jitter-Timeouts.
- Es gibt auch viele Fehler, wie z. B. Zeitüberschreitungen aufgrund von Netzwerkschwankungen, die nicht allein durch Exit-Codes identifiziert werden können. Wir werden eine allgemeinere Strategie anwenden: Unabhängig von der spezifischen Art des Fehlers besteht das Hauptziel darin, den fehlerhaften Knoten schnell zu identifizieren und zu entfernen und dann den Master zu benachrichtigen, um genau zu ermitteln, wo das Problem liegt.
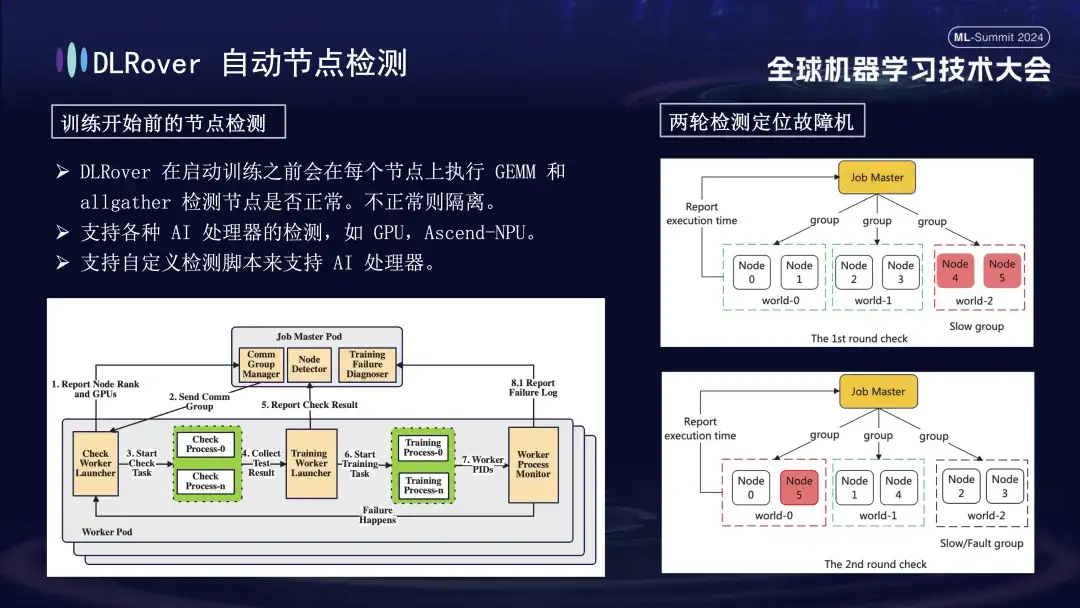
Zunächst wird an allen Knoten eine Matrixmultiplikation durchgeführt. Anschließend werden die Knoten gepaart und gruppiert. In einem Pod mit 6 Knoten werden die Knoten beispielsweise in drei Gruppen (0,1), (2,3) und (4,5) unterteilt, und die AllGather-Kommunikationserkennung erfolgt durchgeführt. Wenn zwischen Knoten 4 und 5 ein Kommunikationsfehler vorliegt, die Kommunikation in anderen Gruppen jedoch normal ist, kann daraus geschlossen werden, dass der Fehler in Knoten 4 oder 5 vorliegt. Als nächstes wird der mutmaßlich fehlerhafte Knoten für weitere Tests erneut mit dem bekannten normalen Knoten gepaart, indem beispielsweise 0 und 5 zur Erkennung kombiniert werden. Durch den Vergleich der Ergebnisse wird der fehlerhafte Knoten genau identifiziert. Dieser automatisierte Inspektionsprozess diagnostiziert eine fehlerhafte Maschine innerhalb von zehn Minuten genau.
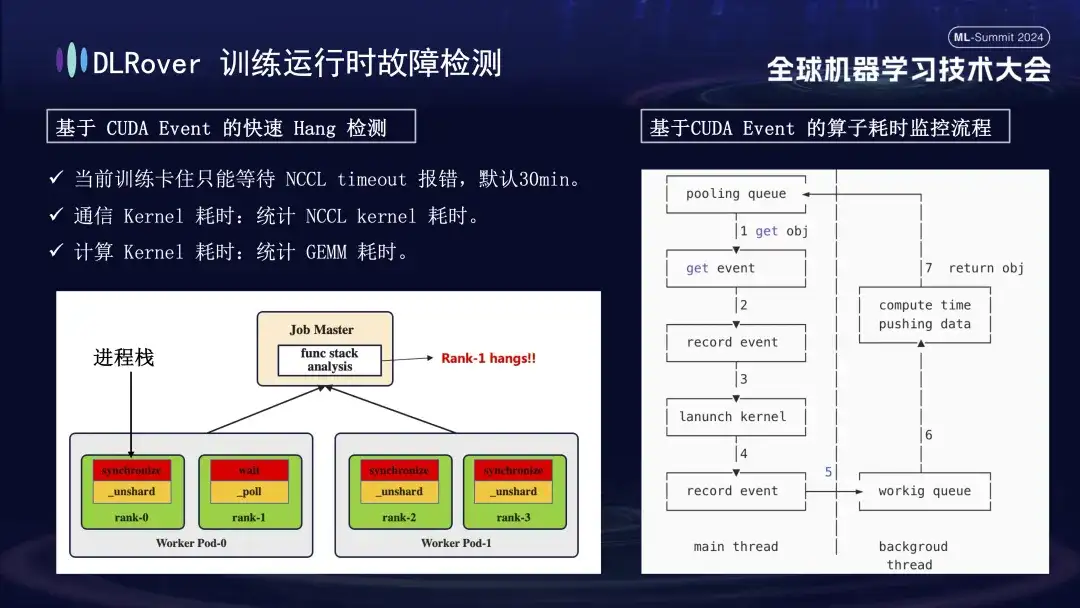
Die Situation der Systemunterbrechung und Fehlererkennung wurde bereits diskutiert, aber das Problem der Identifizierung festsitzender Maschinen muss gelöst werden. Das von NCCL festgelegte Standard-Timeout beträgt 30 Minuten, was die erneute Übertragung von Daten ermöglicht, um Fehlalarme zu reduzieren. Dies kann jedoch dazu führen, dass jede Karte 30 Minuten vergeblich wartet, wenn die Karte tatsächlich feststeckt, was zu enormen kumulativen Verlusten führt. Um ein Feststecken genau zu diagnostizieren, wird empfohlen, ein verfeinertes Profilierungstool zu verwenden. Wenn beispielsweise erkannt wird, dass das Programm angehalten ist und innerhalb einer Minute keine Änderung im Programmstapel erfolgt, werden die Stapelinformationen jeder Karte aufgezeichnet und die Unterschiede verglichen und analysiert. Wenn beispielsweise festgestellt wird, dass 3 von 4 Rängen den Synchronisierungsvorgang ausführen und 1 den Wartevorgang ausführt, können Sie ein Problem mit dem Gerät lokalisieren. Darüber hinaus haben wir den wichtigsten CUDA-Kommunikationskernel und den Computerkernel gekapert, eine Ereignisüberwachung vor und nach ihrer Ausführung eingefügt und anhand der Berechnung des Ereignisintervalls beurteilt, ob der Vorgang normal ausgeführt wurde. Wenn beispielsweise ein bestimmter Vorgang nicht innerhalb der erwarteten 30 Sekunden abgeschlossen wird, kann er als hängengeblieben betrachtet werden und die relevanten Protokolle und Aufrufstapel werden automatisch ausgegeben und zum Vergleich an den Master übermittelt, um die fehlerhafte Maschine schnell zu lokalisieren.
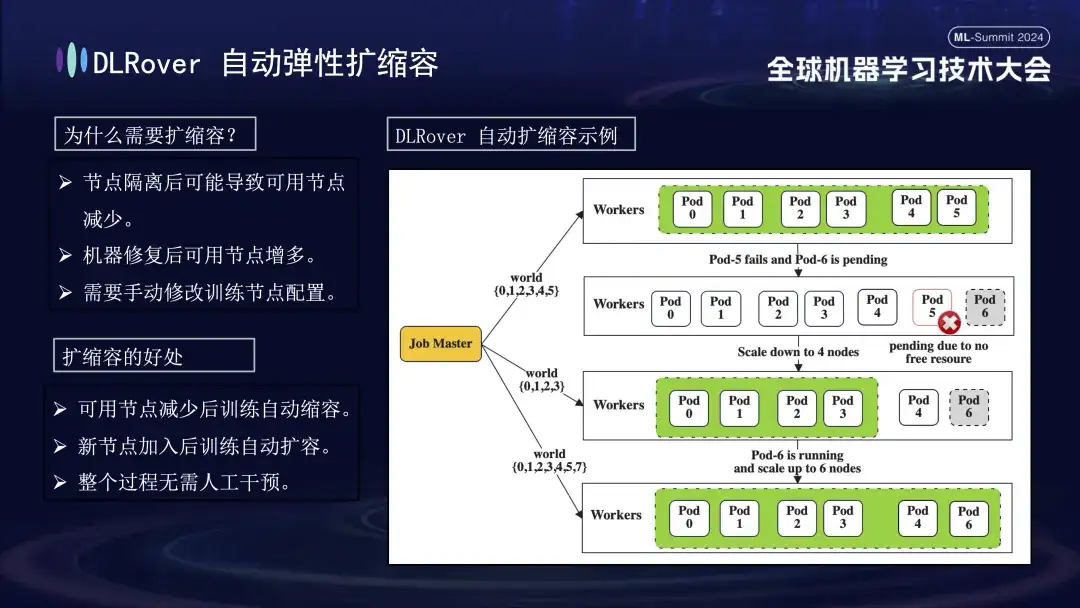
Nachdem die fehlerhafte Maschine identifiziert wurde, war die Anzahl unter Berücksichtigung von Kosten und Effizienz begrenzt, obwohl es in früheren Schulungen einen Backup-Mechanismus gab. Zu diesem Zeitpunkt ist es besonders wichtig, eine elastische Expansions- und Kontraktionsstrategie einzuführen. Angenommen, der ursprüngliche Cluster verfügt über 100 Knoten. Sobald ein Knoten ausfällt, können die verbleibenden 99 Knoten die Trainingsaufgabe fortsetzen, nachdem der ausgefallene Knoten repariert wurde. Das System kann den Betrieb automatisch auf 100 Knoten fortsetzen, und dieser Prozess erfordert keinen manuellen Eingriff. Gewährleistung einer effizienten und stabilen Trainingsumgebung.
DLRover Flash Checkpoint
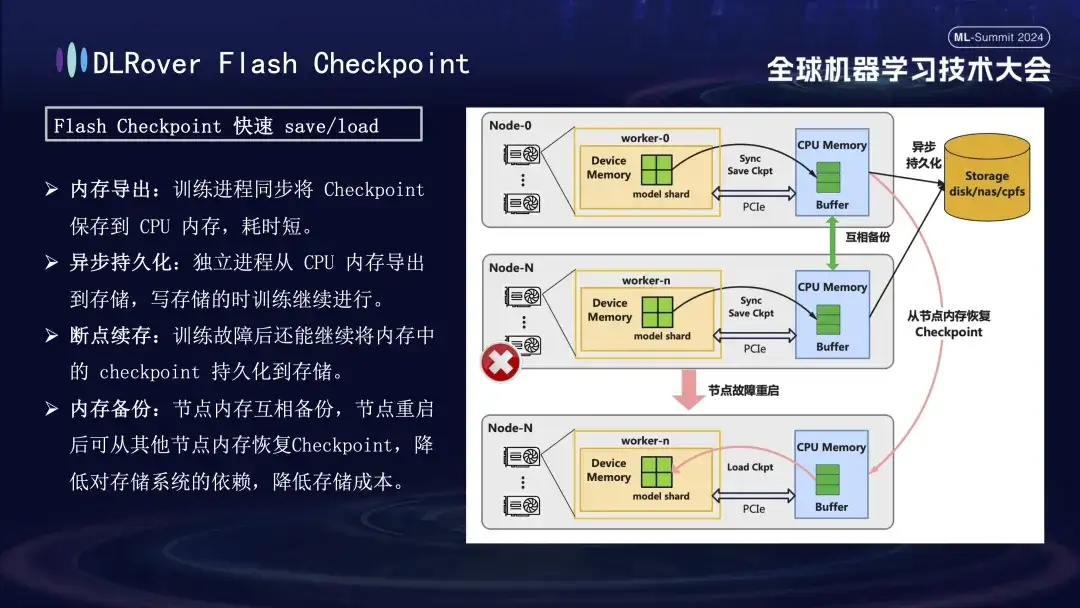
Bei der Wiederherstellung nach Trainingsfehlern besteht der Schlüssel darin, den Modellstatus zu speichern und wiederherzustellen. Die traditionelle Checkpoint-Methode führt aufgrund der langen Zeitersparnis oft zu einer geringen Trainingseffizienz. Um dieses Problem zu lösen, hat DLRover innovativ die Flash Checkpoint-Lösung vorgeschlagen, die den Modellstatus während des Trainingsprozesses nahezu in Echtzeit vom GPU-Speicher in den Speicher exportieren kann Fällt ein Knoten aus, kann der Trainingsstatus schnell aus dem Backup-Knotenspeicher wiederhergestellt werden, wodurch die Fehlerwiederherstellungszeit erheblich verkürzt wird. Für den häufig verwendeten Megatron-LM erfordert der Checkpoint-Exportprozess einen zentralisierten Prozess zur Koordinierung und Fertigstellung, was nicht nur zusätzlichen Kommunikationsaufwand und Speicherverbrauch mit sich bringt, sondern auch zu höheren Zeitkosten führt. DLRover hat nach der Optimierung einen innovativen Ansatz gewählt und eine verteilte Exportstrategie verwendet, sodass jeder Rechenknoten (Rang) seinen eigenen Checkpoint unabhängig speichern und laden kann, wodurch zusätzliche Kommunikations- und Speicheranforderungen effektiv vermieden und die Effizienz erheblich verbessert werden.
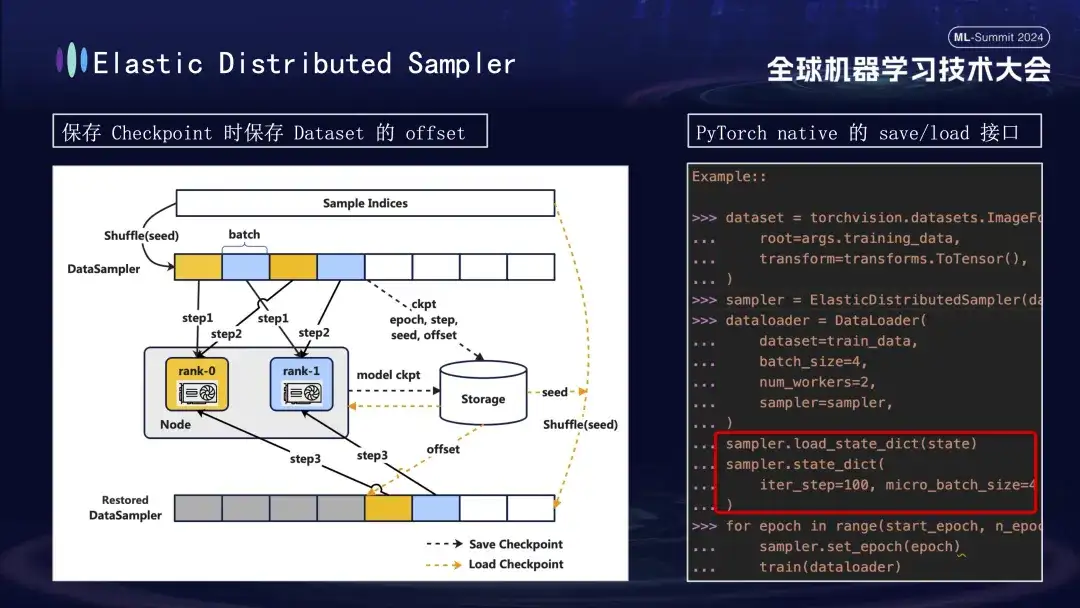
Bei der Erstellung des Modell-Checkpoints gibt es noch ein weiteres Detail, auf das es sich zu achten lohnt. Das Training des Modells basiert auf Daten, vorausgesetzt, wir speichern den Checkpoint bei Schritt 1000 des Trainingsprozesses. Wenn das Training später ohne Berücksichtigung des Datenfortschritts neu gestartet wird, führt die direkte Wiederaufnahme der Daten zu zwei Problemen: Nachfolgende neue Daten können übersehen werden und frühere Daten werden möglicherweise wiederverwendet. Um dieses Problem zu lösen, haben wir die Distributed Sampler-Strategie eingeführt. Beim Speichern des Checkpoints zeichnet diese Strategie nicht nur den Modellstatus auf, sondern speichert auch die Versatzposition des Datenlesens. Auf diese Weise wird beim Laden des Checkpoints zur Wiederaufnahme des Trainings der Datensatz weiterhin vom zuvor gespeicherten Versatzpunkt geladen und dann das Training vorangetrieben, wodurch die Kontinuität und Konsistenz der Modelltrainingsdaten sichergestellt und Datenfehler oder wiederholte Verarbeitung vermieden werden .
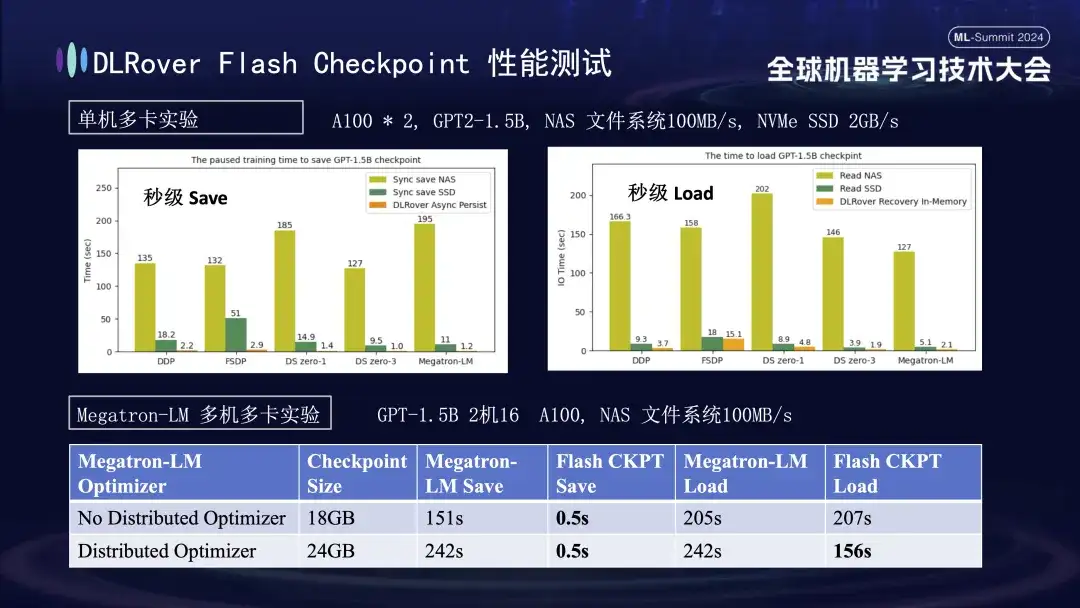
Im obigen Diagramm zeigen wir die experimentellen Ergebnisse in einer Umgebung mit einer einzelnen Maschine und mehreren GPUs (A100) mit dem Ziel, die Auswirkungen verschiedener Speicherlösungen auf die Blockierungszeit zu vergleichen, die durch Checkpoint-Speicherung während des Trainingsprozesses verursacht wird. Experimente zeigen, dass sich die Leistung des Speichersystems direkt auf die Effizienz auswirkt: Wenn eine weniger effiziente Speichermethode verwendet wird, um Checkpoints direkt auf die Festplatte zu schreiben, wird das Training erheblich blockiert und die Zeit verlängert. Insbesondere bei einem 1,5-B-Modell-Checkpoint mit einer Größe von etwa 20 GB beträgt die Schreibzeit bei Verwendung eines NAS-Speichers etwa 2 bis 3 Minuten. Dies bedeutet, dass die asynchrone vorübergehende Speicherung der Daten im Speicher erheblich verkürzt werden kann Dieser Vorgang dauert durchschnittlich nur etwa 1 Sekunde, was die Kontinuität und Effizienz des Trainings erheblich verbessert.

Die Flash Checkpoint-Funktion von DLRover ist weitgehend kompatibel mit den wichtigsten gängigen Trainings-Frameworks für große Modelle, einschließlich DDP, FSDP, DeepSpeed, Megatron-LM, Transformers.Trainer und Ascend-DDP. Es verfügt über angepasste APIs für jedes Framework, um eine äußerst einfache Verwendung für Benutzer zu gewährleisten Es ist selten erforderlich, vorhandenen Trainingscode anzupassen, es funktioniert sofort. Insbesondere müssen Benutzer des DeepSpeed-Frameworks beim Ausführen von Checkpoint nur die Speicherschnittstelle von DLRover aufrufen, während die Integration von Megatron-LM noch einfacher ist. Sie müssen lediglich die native Checkpoint-Importanweisung durch die von DLRover bereitgestellte Importmethode ersetzen . Dürfen.
DLRover verteilte Trainingspraxis
Wir haben für jedes Fehlerszenario eine Reihe von Experimenten durchgeführt, um die Fehlertoleranz des Systems, die Fähigkeit, mit langsamen Knoten umzugehen, und die Flexibilität bei der Vergrößerung und Verkleinerung zu bewerten. Die spezifischen Experimente sind wie folgt:
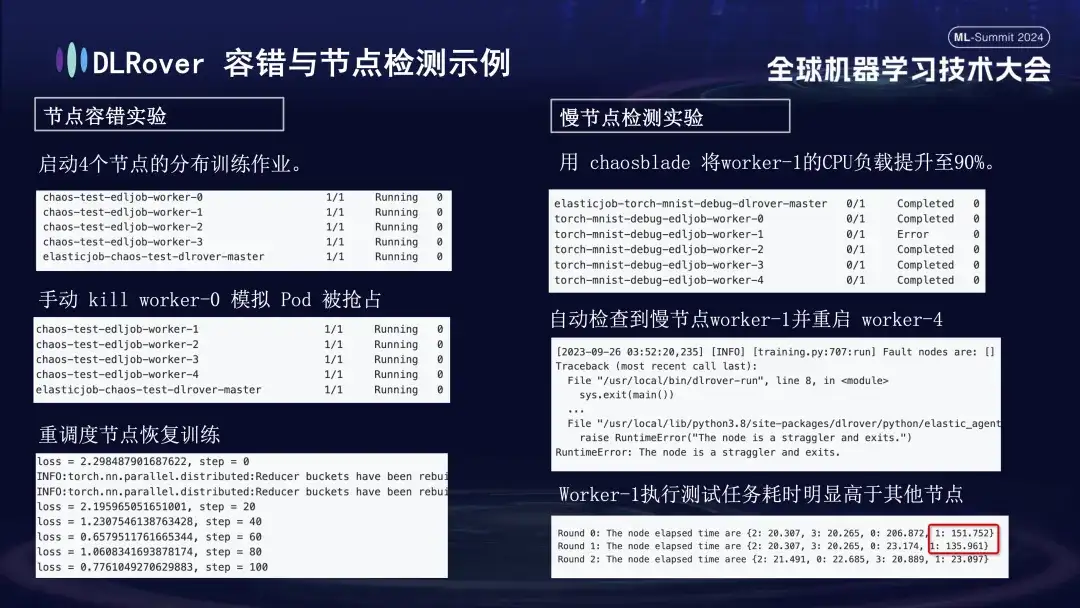
- Experiment zur Knotenfehlertoleranz: Fahren Sie einige Knoten manuell herunter, um zu testen, ob sich der Cluster schnell erholen kann.
- Experiment mit langsamen Knoten: Verwenden Sie das Chaosblade-Tool, um die CPU-Auslastung des Knotens auf 90 % zu erhöhen, um eine zeitaufwändige Situation mit langsamen Knoten zu simulieren.
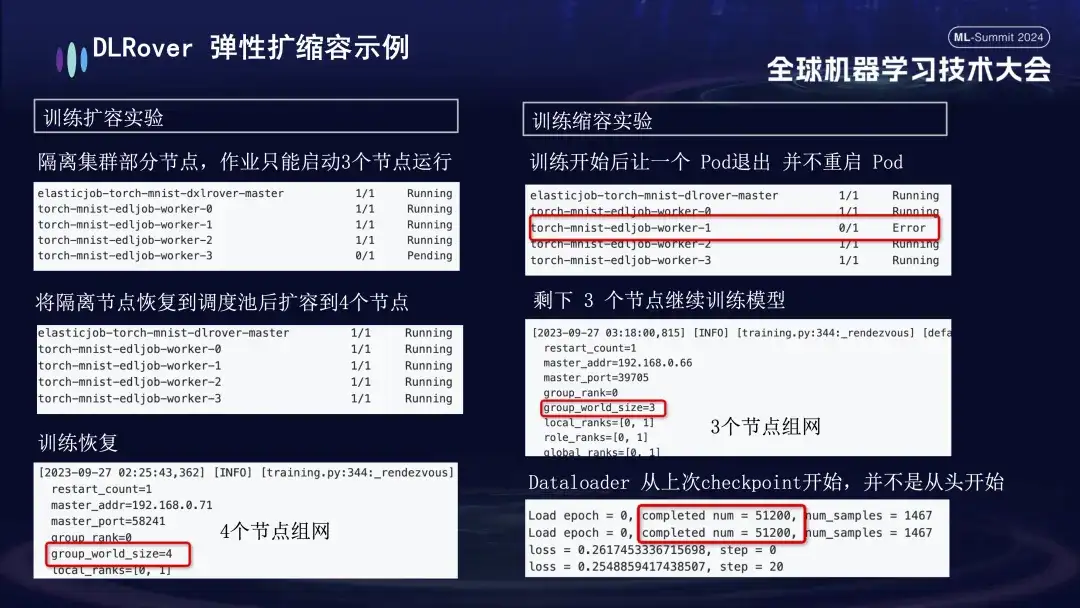
- Expansions- und Kontraktionsexperiment: Simuliert ein Szenario, in dem die Maschinenressourcen knapp sind. Wenn beispielsweise ein Job mit 4 Knoten konfiguriert ist, aber nur 3 tatsächlich gestartet werden, können diese 3 Knoten weiterhin normal trainiert werden. Nach einiger Zeit simulierten wir die Isolierung eines Knotens und die Anzahl der für das Training verfügbaren Pods wurde auf 3 reduziert. Wenn diese Maschine in die Planungswarteschlange zurückkehrt, kann die Anzahl der verfügbaren Pods auf 4 erhöht werden. Zu diesem Zeitpunkt setzt der Dataloader das Training vom letzten Kontrollpunkt fort, anstatt von vorne zu beginnen.
DLRover-Praxis bei inländischen Karten
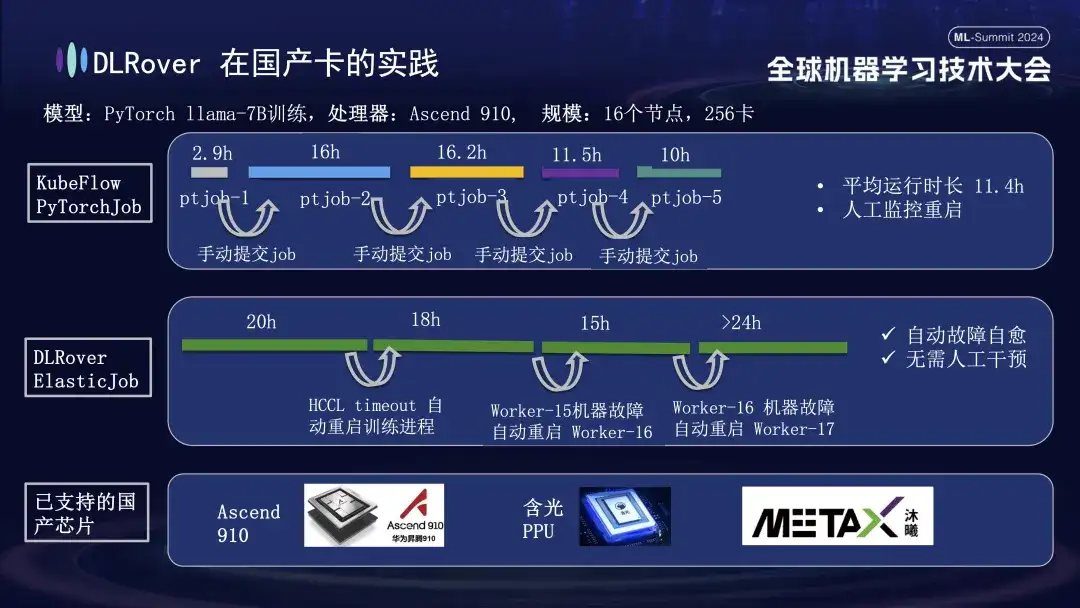
Neben der Unterstützung von GPUs unterstützt die DLRover-Fehlerselbstheilung auch das verteilte Training inländischer Beschleunigerkarten. Als wir beispielsweise das LLama-7B-Modell auf der Huawei Ascend 910-Plattform laufen ließen, verwendeten wir 256 Karten für groß angelegte Schulungen. Zuerst haben wir PyTorchJob von KubeFlow verwendet, aber dieses Tool hatte keine Fehlertoleranz, was dazu führte, dass der Trainingsprozess nach etwa zehn Stunden automatisch beendet wurde. Sobald dies geschah, musste der Benutzer die Aufgabe manuell erneut übermitteln Leerlauf. Das zweite Diagramm zeigt den gesamten Trainingsprozess mit aktivierter Selbstheilung von Trainingsfehlern. Als das Training 20 Stunden dauerte, trat ein Kommunikations-Timeout-Fehler auf. Zu diesem Zeitpunkt startete das System den Trainingsprozess automatisch neu und nahm das Training wieder auf. Ungefähr vierzig Stunden später wurde ein Hardwarefehler der Maschine festgestellt. Das System isolierte schnell die fehlerhafte Maschine und startete einen Pod neu, um das Training fortzusetzen. Neben der Unterstützung des Huawei Ascend 910 sind wir auch mit der Hanguang PPU von Alibaba kompatibel und arbeiten mit Muxi Technology zusammen, um DLRover zum Trainieren des LLAMA2-65B-Modells auf seiner unabhängig entwickelten Qianka-GPU zu nutzen.
DLRüber 1.000 Karten, 100 Milliarden Modelltrainingspraxis
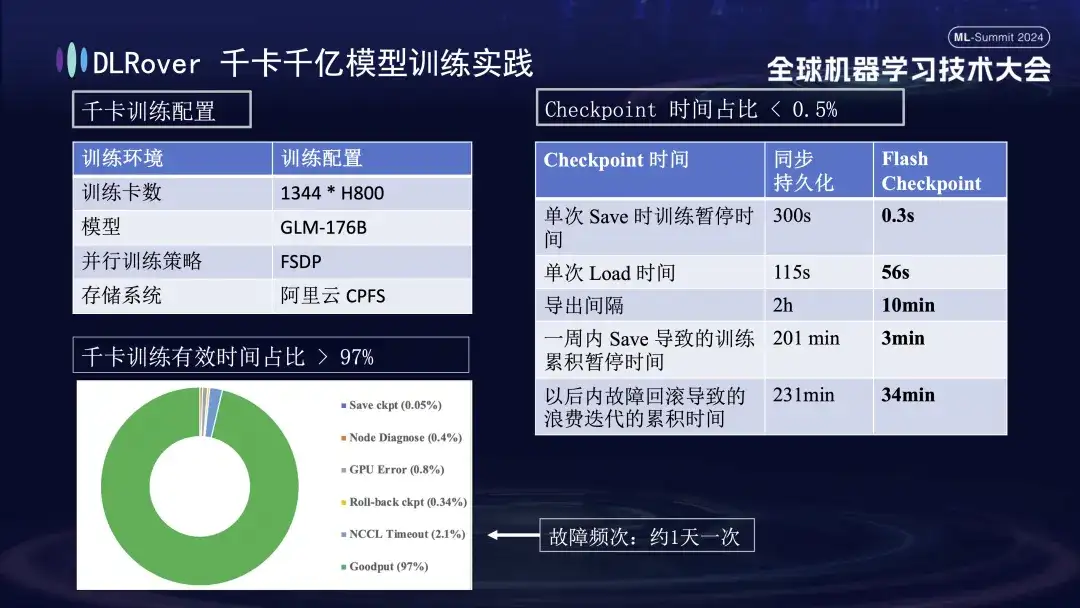
Die obige Abbildung zeigt die praktische Auswirkung der Selbstheilung von DLRover-Trainingsfehlern auf das Kilokartentraining: Mehr als 1.000 H800-Karten werden zum Ausführen eines groß angelegten Modelltrainings verwendet. Die Heilungsfunktion wird eingeführt, wobei die effektive Trainingszeit mehr als 97 % ausmacht. Die Vergleichstabelle rechts zeigt, dass bei Verwendung des Hochleistungsspeichers FSDP von Alibaba Cloud ein einzelner Speichervorgang immer noch etwa fünf Minuten dauert, während unsere Flash Checkpoint-Technologie nur 0,3 Sekunden benötigt. Darüber hinaus wurde durch die Optimierung die Knoteneffizienz um fast eine Minute verbessert. In Bezug auf das Exportintervall wurde der Exportvorgang ursprünglich alle 2 Stunden durchgeführt. Nach dem Start der Flash Checkpoint-Funktion kann jedoch alle 10 Minuten ein Hochfrequenzexport durchgeführt werden. Der kumulierte Zeitaufwand für Speichervorgänge innerhalb einer Woche ist nahezu vernachlässigbar. Gleichzeitig reduziert sich die Rollback-Zeit im Vergleich zu zuvor um etwa das Fünffache.
DLRover-Plan & Community-Aufbau

DLRover hat derzeit drei Hauptversionen veröffentlicht. Es wird erwartet, dass im Juni V0.4.0 veröffentlicht wird, die eine Laufzeitfehlererkennung basierend auf CUDA Event ermöglichen wird.
- V0.1.0 (2023/07): Elastische Fehlertoleranz und automatische Erweiterung und Kontraktion von TensorFlow PS auf k8s/ray;
- V0.2.0 (2023/09): Knotenerkennung und elastische Fehlertoleranz für synchrones PyTorch-Training auf k8s;
- V0.3.5 (2024/03): Flash Checkpoint und Erkennung von inländischen Kartenfehlern;
Im Hinblick auf die zukünftige Planung wird DLRover die Funktionen von DLRover in den Bereichen Knotenplanung und -verwaltung, Kompilierung und Optimierung von Lynx, Trainingsoptimierungs-Framework AToch und inländisches Kartentraining weiter optimieren und verbessern:
- **Knotenplanung und -verwaltung: **Kommunikationstopologie-bewusste Planung, Reduzierung des Kommunikationsverkehrs von Switches der obersten Ebene während der ringbasierten AllReduce-Hardware-Metrikerfassung und Fehlervorhersage;
- **Compilation-Optimierung Lynx: **Optimierung der Berechnungsdiagrammplanung, Erzielung einer optimalen Kommunikations- und Berechnungsüberlappung, Ausblenden der automatischen verteilten SPMD-Schulung;
- **Trainingsoptimierungs-Framework ATorch: **RLHF-Trainingsoptimierung; Initialisierungsbeschleunigung des verteilten Trainings; automatische Trainingsbeschleunigung;
- **Inländisches Kartentraining: **Erweitern Sie Funktionen wie Fehlerselbstheilung und Trainingsbeschleunigung auf inländische Karten und bieten Sie Best Practices für das inländische Kartentraining.

Technologischer Fortschritt beginnt mit offener Zusammenarbeit. Jeder ist herzlich eingeladen, unsere Open-Source-Projekte auf GitHub zu verfolgen und daran teilzunehmen.
DLRover:
https://github.com/intelligent-machine-learning/dlrover
GLAKE:
https://github.com/intelligent-machine-learning/glake
Unser öffentlicher WeChat-Account „AI Infra“ wird außerdem regelmäßig hochmoderne technische Artikel zur KI-Infrastruktur veröffentlichen, mit dem Ziel, die neuesten Forschungsergebnisse und technischen Erkenntnisse zu teilen. Um den weiteren Austausch und die Diskussionen zu fördern, haben wir gleichzeitig auch eine DingTalk-Gruppe eingerichtet. Jeder ist herzlich willkommen, hier Fragen zu stellen und entsprechende technische Themen zu diskutieren. Danke euch allen!
Artikelempfehlungen
