
Autor: Huan Xiang
Die Manbang Group kümmert sich als „Internet + Logistik“-Plattformunternehmen auf der einen Seite um die Versandbedürfnisse der Verlader und verbindet sich auf der anderen Seite mit LKW-Fahrern, um die Effizienz der Frachtlogistik zu verbessern. Es wird 2021 an der US-Börse notiert und ist damit die erste digitale Frachtplattform, die gelistet ist. Dem Jahresbericht des Unternehmens zufolge haben im Jahr 2021 mehr als 3,5 Millionen Lkw-Fahrer mehr als 128,3 Millionen Bestellungen auf der Plattform abgewickelt und dabei einen Gesamttransaktionswert von 262,3 Milliarden Yuan GTV erzielt, was mehr als 60 % des Anteils von Chinas digitaler Frachtplattform ausmacht. Im Oktober 2022 erreichte die MAU der Fahrerversion von Yunmanman 9,4921 Millionen, und die MAU der Fahrerversion von Wagonmanman betrug 3,9991 Millionen; die MAU der Besitzerversion von Yunmanman betrug 2,1868 Millionen und die MAU der Wagonbang-Frachtbesitzerversion betrug 637.800. (Der folgende Inhalt wurde von Zikui und Congyan zusammengestellt und ausgegeben.)
Das Geschäftswachstum stellt die Servicestabilität in Frage
Die Manbang Group hat ein eigenes Microservice-Gateway in der Geschäftsproduktionsumgebung aufgebaut, das für die Planung des Nord-Süd-Verkehrs, den Sicherheitsschutz und die Microservice-Governance verantwortlich ist. Gleichzeitig werden unter Berücksichtigung der Multi-Active-Disaster-Recovery-Fähigkeit auch Dienste wie z B. Prioritätsanrufe im selben Computerraum, Disaster Recovery-Anrufe zwischen Computerräumen usw. Mechanismus. Als Front-End-Komponente der Microservice-Architektur dient das Microservice-Gateway als Verkehrseingang für alle Microservices. Wenn eine Client-Anfrage eingeht, trifft sie zuerst auf den ALB (Lastausgleich), geht dann zum internen Gateway und wird dann über das Gateway an das spezifische Geschäftsdienstmodul weitergeleitet.
Daher muss das Gateway ein Service-Registrierungscenter verwenden, um alle in der aktuellen Produktionsumgebung bereitgestellten Microservice-Instanzen dynamisch zu erkennen. Wenn einige Service-Instanzen aufgrund von Fehlern keine Dienste bereitstellen können, kann das Gateway auch mit dem Service-Registrierungscenter zusammenarbeiten, um automatisch weiterzuleiten Bei Dienstinstanzen werden Failover und Elastizität erreicht, und ein selbst entwickeltes Framework wird verwendet, um mit dem Dienstregistrierungszentrum zusammenzuarbeiten, um Anrufe zwischen Diensten zu realisieren Um das Konfigurationsmanagement und den Change Push zu implementieren, hat die Manbang Group als erstes Unternehmen die Open-Source-Lösungen Eureka und ZooKeeper eingeführt, um ein Cluster-Implementierungs- und Konfigurationszentrum aufzubauen.
Mit zunehmendem Geschäftsvolumen gibt es jedoch immer mehr Geschäftsmodule und die Anzahl der Dienstregistrierungsinstanzen nimmt explosionsartig zu . Die Stabilitätsprobleme des selbst erstellten Eureka-Dienstregistrierungscenter-Clusters und des ZooKeeper-Clusters in dieser Architektur werden immer offensichtlicher .
Während des Betriebs und der Wartung stellten Studenten der Manbang Group fest, dass einige Knoten aufgrund der Synchronisierung der Instanzregistrierungsinformationen zwischen Eureka-Clusterknoten diese nicht verarbeiten konnten, als die Anzahl der Dienstregistrierungsinstanzen im selbst erstellten Eureka-Cluster 2000+ erreichte Es kommt sehr leicht zu Problemen, wenn Knoten keine Dienste bereitstellen und es schließlich zu Ausfällen kommt. Häufige GCs im ZooKeeper-Cluster verursachen Jitter bei Aufrufen zwischen Diensten und Konfigurationsfreigaben, was sich außerdem auf die allgemeine Stabilität auswirkt Aufgrund der standardmäßig aktivierten Konfigurationsspeicherung bestehen Sicherheitsrisiken. Diese Probleme stellen auch große Herausforderungen für die stabile und dauerhafte Entwicklung des Unternehmens dar.
Reibungslose Migration der Geschäftsarchitektur
Vor dem oben genannten Geschäftshintergrund entschieden sich Manbang-Studenten für eine dringende Migration in die Cloud und verwendeten die Produkte Alibaba Cloud MSE Nacos und MSE ZooKeeper, um die ursprünglichen Eureka- und Zookeeper-Cluster zu ersetzen. Wie können wir jedoch auch kostengünstige und schnelle Architektur-Upgrades erreichen? Wie sieht es mit der verlustfreien und reibungslosen Migration des Datenverkehrs für das Unternehmen aus?
In dieser Hinsicht hat MSE Nacos die volle Kompatibilität mit dem nativen Open-Source-Protokoll Eureka erreicht. Der Kernel wird weiterhin von Nacos gesteuert. Die Geschäftsanpassungsschicht bildet das Eureka-InstanceInfo-Datenmodell und das Nacos-Datenmodell (Dienst und Instanz) nacheinander ab. All dies ist für die Geschäftsparteien völlig transparent, dass die Manbang Group den selbst aufgebauten Eureka-Cluster übernommen hat.
Dies bedeutet, dass die ursprüngliche Geschäftsseite nicht auf Codeebene geändert werden muss. Sie müssen lediglich die Endpunktkonfiguration der Serverinstanz ändern, die vom Eureka-Client mit dem Endpunkt von MSE Nacos verbunden ist. Es ist auch sehr flexibel in der Verwendung. Sie können weiterhin das native Eureka-Protokoll verwenden, um die MSE-Nacos-Instanz als Eureka-Cluster zu verwenden, oder Sie können die beiden Protokolle Nacos und Eureka-Client für die Koexistenz verwenden Konvertierung, wodurch die Konnektivität von Geschäfts-Microservice-Aufrufen sichergestellt wird.
Darüber hinaus stellte MSE während des Cloud-Migrationsprozesses offiziell die MSE-Sync-Lösung zur Verfügung, bei der es sich um ein optimiertes, die Migration unterstützendes Datensynchronisierungstool basierend auf dem Open-Source-Programm Nacos-Sync handelt. Es unterstützt bidirektionale Synchronisierung, automatische Pull-Dienste und One-Click Synchronisationsfunktionen. Durch MSE-Sync können Manbang-Studenten die vorhandenen Online-Service-Registrierungsbestandsdaten auf dem ursprünglichen selbst erstellten Eureka-Cluster einfach mit einem Klick auf den neuen MSE Nacos-Cluster migrieren. Gleichzeitig können die inkrementellen Daten auf dem alten Cluster neu registriert werden Die Migration erfolgt ebenfalls mit einem Klick und wird kontinuierlich und automatisch mit dem neuen Cluster synchronisiert. Dadurch wird sichergestellt, dass die Informationen zur Cluster-Service-Registrierungsinstanz auf beiden Seiten vor der eigentlichen Geschäftsflussmigration immer vollständig konsistent sind. Nachdem die Datensynchronisierungsprüfung bestanden wurde, ersetzen Sie die ursprüngliche Eureka Client Endpoint-Konfiguration, veröffentlichen und aktualisieren Sie sie erneut und migrieren Sie erfolgreich auf den neuen MSE Nacos-Cluster.
Durchbrechen des Leistungsengpasses der nativen Eureka-Cluster-Architektur
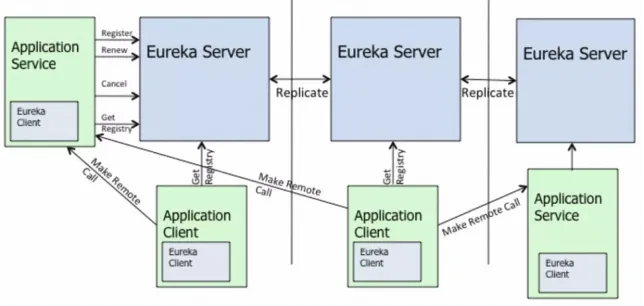
Als die Manbang Group feststellte , dass die technische Architektur des MSE-Teams verbessert wurde, bestand die wichtigste Anforderung darin, das ursprüngliche Problem des hohen Drucks bei der Synchronisierung von Dienstregistrierungsinformationen zwischen Eureka-Clustern zu lösen Gemäß dem Synchronisierungs-AP-Modell sind die Rollen jedes Serverknotens gleich und völlig gleichwertig. Für jede Änderung (Registrierung/Abmeldung/Heartbeat-Erneuerung/Dienststatusänderung usw.) wird eine entsprechende Synchronisierungsaufgabe zur Synchronisierung aller Instanzdaten generiert Auf diese Weise steigt die Anzahl der Synchronisierungsjobs in direktem Zusammenhang mit der Clustergröße und der Anzahl der Instanzen.
Durch die Praxis stellten Studenten der Manbang Group fest, dass die CPU-Belegungsrate und -Auslastung einiger Knoten sehr hoch war, als die Cluster-Service-Registrierungsskala 2000+ erreichte, und manchmal täuschten sie von Zeit zu Zeit den Tod vor, was zu geschäftlichen Nervosität führte. Dies wird auch in der offiziellen Eureka-Dokumentation erwähnt. Das Broadcast-Replikationsmodell von Open-Source-Eureka verursacht nicht nur seine eigene architektonische Schwachstelle, sondern wirkt sich auch auf die allgemeine horizontale Skalierbarkeit des Clusters aus.
Der Replikationsalgorithmus schränkt die Skalierbarkeit ein: Eureka folgt einem Broadcast-Replikationsmodell, dh alle Server replizieren Daten und Heartbeats an alle Peers. Dies ist einfach und effektiv für den Datensatz, den eureka enthält. Die Replikation wird jedoch implementiert, indem alle HTTP-Aufrufe, die ein Server empfängt, unverändert an alle Peers weitergeleitet werden. Dies schränkt die Skalierbarkeit ein, da jeder Knoten der gesamten Schreiblast auf Eureka standhalten muss.
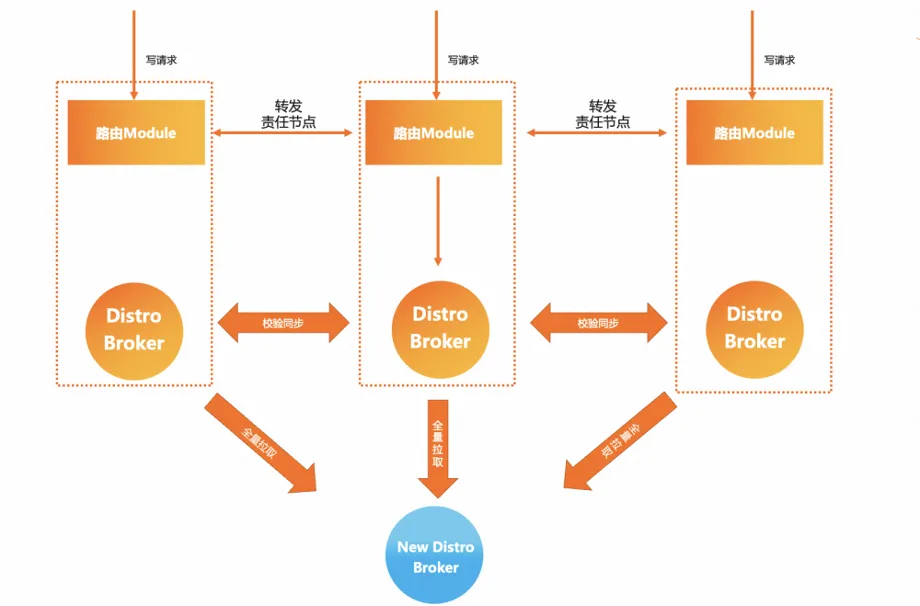
MSE Nacos hat dieses Problem bei der Architekturauswahl berücksichtigt und eine bessere Lösung bereitgestellt, nämlich das selbst entwickelte AP-Modell-Distro-Protokoll. Auf der Grundlage der Beibehaltung des Star-Synchronisationsmodells registriert Nacos Instanzdaten für alle Dienste Sharding wird durchgeführt, und jeder Serverknoten ist für die Synchronisierung und Erneuerung der Daten verantwortlich. Gleichzeitig ist die Granularität der Datensynchronisierung zwischen Clustern gewährleistet relativ Die Eureka ist auch kleiner. Dies hat den Vorteil, dass selbst bei umfangreichen Bereitstellungen und großen Dienstinstanzdaten die Menge der Synchronisierungsaufgaben zwischen Clustern relativ kontrollierbar ist . Je größer die Clustergröße, desto offensichtlicher ist die Leistungsverbesserung, die dieses Modell mit sich bringt.
Kontinuierliche iterative Optimierung strebt nach ultimativer Leistung
Nachdem MSE Nacos und MSE ZooKeeper das gesamte Microservice-Registrierungscenter-Geschäft der Manbang Group abgeschlossen hatten, setzten sie die iterative Optimierung in nachfolgenden aktualisierten Versionen fort und optimierten die Serverleistung in jedem Detail durch eine große Anzahl von Vergleichstests für Leistungsstresstests Aufgrund der Geschäftserfahrung werden die Optimierungspunkte der aktualisierten Version einzeln analysiert und eingeführt.
Dienstregistrierung, Hochverfügbarkeit, Disaster-Recovery-Schutz
Native Nacos bietet High-Level-Funktionen: Push-Schutz Der Dienstkonsument (Consumer) abonniert die Instanzliste des Dienstanbieters (Provider) über das Registrierungszentrum oder den Dienstanbieter Registrierungszentrum Wenn die Verbindung zwischen Zentren aufgrund von Netzwerk-, CPU- und anderen Faktoren zittert, kann es zu Abonnementausnahmen kommen, die dazu führen, dass Dienstkonsumenten eine leere Dienstanbieter-Instanzliste erhalten.
Um dieses Problem zu lösen, können Sie die Push-Schutzfunktion auf dem Nacos-Client oder MSE Nacos-Server aktivieren, um die Verfügbarkeit des gesamten Systems zu verbessern. Wir haben diese Stabilitätsfunktion auch in die Protokollunterstützung für Eureka eingeführt. Wenn die Daten des MSE Nacos-Servers abnormal sind und der Eureka-Client Daten vom Server abruft, erhält er standardmäßig Unterstützung für den Notfallwiederherstellungsschutz, um die geschäftliche Nutzung sicherzustellen Dadurch erhalten Sie keine Liste von Dienstanbieterinstanzen, die nicht den Erwartungen entsprechen und zu Geschäftsausfällen führen.
Darüber hinaus bieten MSE Nacos und MSE ZooKeeper mehrere Hochverfügbarkeitsgarantiemechanismen . Wenn die Geschäftsseite höhere Anforderungen an Zuverlässigkeit und Datensicherheit hat, können Sie sich beim Erstellen einer Instanz für die Bereitstellung mit nicht weniger als 3 Knoten entscheiden. Wenn eine der Instanzen ausfällt, ist der Wechsel zwischen den Knoten innerhalb von Sekunden abgeschlossen und der ausgefallene Knoten verlässt automatisch den Cluster. Gleichzeitig enthält jede MSE-Region mehrere Verfügbarkeitszonen. Die Netzwerkverzögerung zwischen verschiedenen Zonen in derselben Region ist sehr gering (innerhalb von 3 ms). , , wird der Verkehr in kurzer Zeit in eine andere Verfügbarkeitszone B umgeleitet. Die Geschäftsseite hat kein Bewusstsein für den gesamten Prozess, und die Anwendungscodeebene hat kein Bewusstsein und es sind keine Änderungen erforderlich. Dieser Mechanismus erfordert lediglich die Konfiguration der Bereitstellung mit mehreren Knoten, und MSE unterstützt Sie automatisch bei der Bereitstellung in mehreren Verfügbarkeitszonen für eine verstreute Notfallwiederherstellung.
Unterstützen Sie den Eureka-Client beim schrittweisen Abrufen von Daten
Nach der Migration der Manbang-Studenten zu MSE Nacos wurde das ursprüngliche Problem, dass die Serverinstanz angehalten war und keine Dienste bereitstellen konnte, gut gelöst. Es stellte sich jedoch heraus, dass die Netzwerkbandbreite des Computerraums zu hoch war und gelegentlich die Bandbreite voll war während der Hauptverkehrszeiten. Später stellte sich heraus, dass der Grund darin lag, dass der Eureka-Client jedes Mal, wenn er die Dienstregistrierungsinformationen von MSE Nacos abzog, nur den vollständigen Abruf unterstützte und regelmäßig Tausende von Datenebenen abgerufen wurden, was zu einem Anstieg der Anzahl der FGCs führte die Gateway-Ebene eine Menge.
Um dieses Problem zu lösen, hat MSE Nacos einen inkrementellen Pull-Mechanismus für die Registrierungsinformationen des Eureka-Dienstes eingeführt. In Verbindung mit der Anpassung der Client-Nutzung muss der Client die gesamte Datenmenge nur einmal nach dem ersten Start und danach abrufen Die gesamte Datenmenge muss auf der Grundlage der inkrementellen Daten abgerufen werden, um die Konsistenz lokaler Daten und Serverdaten aufrechtzuerhalten, und es sind keine regelmäßigen vollständigen Abrufe mehr erforderlich. Die inkrementelle Datenmenge, die in einer normalen Produktionsumgebung geändert wird, ist sehr groß klein, was den Druck auf die Exportbandbreite erheblich reduzieren kann. Nach dem Upgrade auf diese optimierte Version stellten Manbang-Studenten fest, dass die Bandbreite plötzlich von 40 MB/s vor dem Upgrade auf 200 KB/s sank und das Problem der vollen Bandbreite gelöst war.

Vollständiger Stresstest zur Optimierung der Serverleistung
Anschließend führte das MSE-Team einen größeren Leistungsstresstest für das Eureka-Szenario des MSE Nacos-Clusters durch, nutzte verschiedene Leistungsanalysetools, um Leistungsengpässe bei den Geschäftsverbindungen zu identifizieren, und führte eine weitere Leistungsoptimierung und Optimierung der ursprünglichen Funktionen durch. Feinabstimmung der Leistungsparameter.
- Auf der Serverseite wird Caching für die vollständigen und inkrementellen Datenregistrierungsinformationen eingeführt, und anhand des serverseitigen Daten-Hashs wird ermittelt, ob Änderungen aufgetreten sind. In Szenarien, in denen der Eureka-Server mehr liest und weniger schreibt, kann er den Leistungsaufwand für CPU-Berechnungen zur Generierung zurückgegebener Ergebnisse erheblich reduzieren.
- Es wurde festgestellt, dass der native StringHttpMessageConverter von SpringBoot bei der Verarbeitung umfangreicher Datenrückgaben einen Leistungsengpass aufwies, und EnhancedStringHttpMessageConverter wurde bereitgestellt, um die E/A-Übertragungsleistung von String-Daten zu optimieren.
- Die serverseitige Datenrückgabe unterstützt Chunked.
- Die Anzahl der Tomcat-Thread-Pools wird entsprechend der Containerkonfiguration adaptiv angepasst.
Nachdem die Manbang Group das iterative Upgrade der oben genannten Version abgeschlossen hat, haben verschiedene Parameter auf der Serverseite ebenfalls hervorragende Optimierungsergebnisse erzielt:
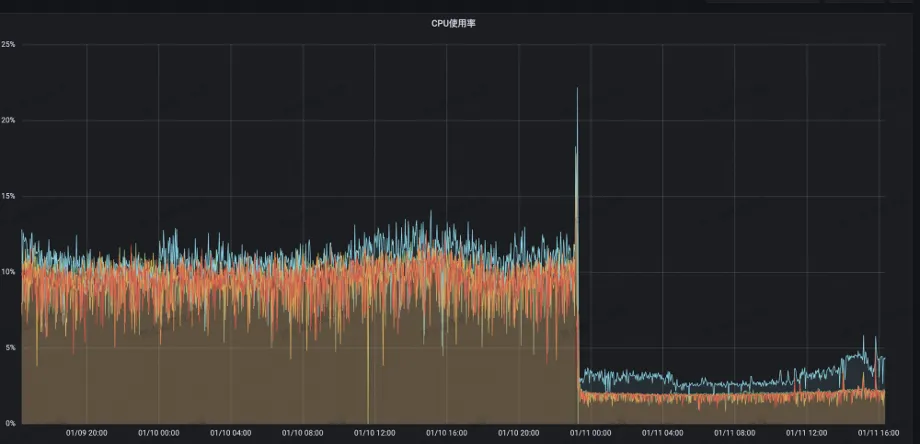
Die CPU-Auslastung des Servers sank von 13 % auf 2 %.
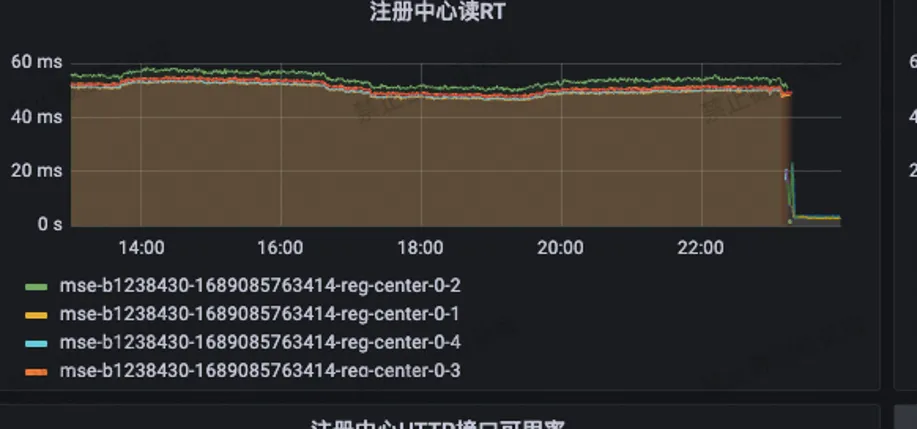
Die vom Registrierungszentrum angezeigte RT wurde von ursprünglich 55 ms auf weniger als 3 ms reduziert.

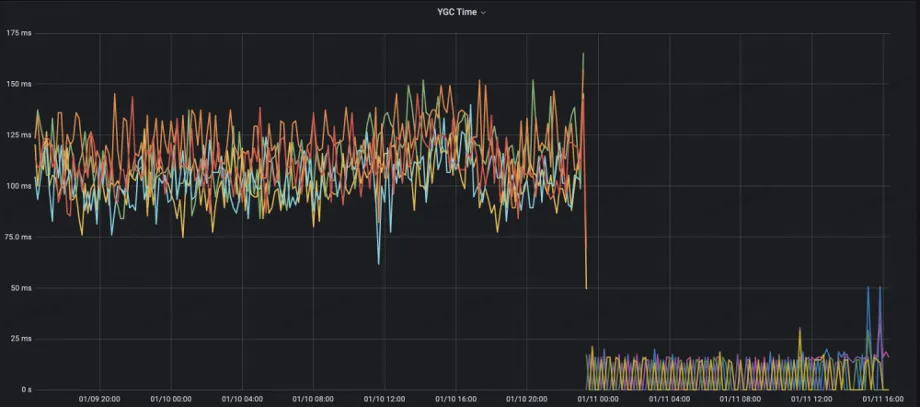
Die serverseitige YGC-Anzahl wurde von ursprünglich 10+ auf 1 reduziert
Die YGC-Zeit wurde von ursprünglich 125 ms auf weniger als 10 ms reduziert
Die Bypass-Optimierung gewährleistet die Stabilität des Clusters unter hohem Druck
Nachdem Manbang-Studenten für einen bestimmten Zeitraum zu MSE ZooKeeper migriert waren, kam es erneut zu einer vollständigen GC im Cluster, was dazu führte, dass der Cluster instabil wurde. Nach einer Notfalluntersuchung durch MSE wurde festgestellt, dass der Grund darin lag, dass ein überwachungsbezogener statistischer Indikator für Metriken vorhanden war ZooKeeper wurde während der Berechnung auf dem aktuellen Knoten gespeichert und die Überwachungsskala ist in einem solchen Szenario sehr groß Der letzte Cluster ist nicht in der Lage, qualifizierte Speicherressourcen zuzuweisen, und letztendlich ist der vollständige GC vorhanden.
Um dieses Problem zu lösen, ergreift MSE ZooKeeper Downgrade-Maßnahmen für unwichtige Metriken, um sicherzustellen, dass diese Metriken die Clusterstabilität nicht beeinträchtigen. Für Watch-Copy-Metriken wird eine dynamische Erfassungsstrategie angewendet, um Speicherfragmentierungsprobleme zu vermeiden, die durch Datenkopierberechnungen verursacht werden. Nach Anwendung dieser Optimierung werden die Zeit und die Anzahl der Young-GC-Cluster erheblich reduziert.
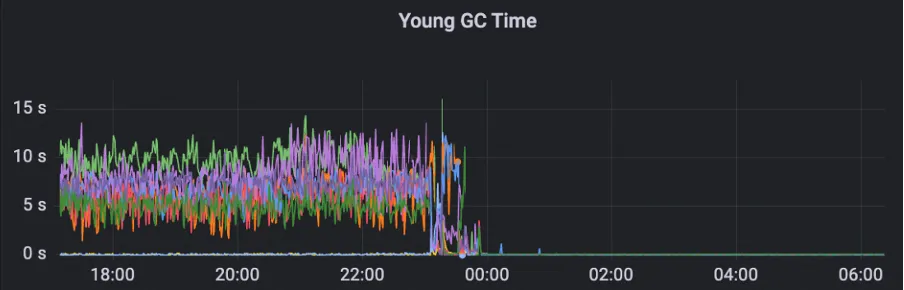

Nach der Optimierung kann der Cluster problemlos 200 W QPS verarbeiten und GC ist stabil.
Kontinuierliche Parameteroptimierung, um den besten Balancepunkt zwischen Latenz und Durchsatz zu finden
Nachdem Manbang-Studenten ihren selbst erstellten ZooKeeper auf MSE ZooKeeper migriert hatten, stellten sie fest, dass die Verzögerung des Clients beim Lesen der Daten in ZooKeeper zu groß war und das Zeitlimit für das Lesen der Anwendungsstartkonfiguration überschritten wurde, was zu einem Zeitlimit für den Anwendungsstart führte Um dieses Problem zu lösen, zeigt die gezielte Stresstestanalyse von MSE ZooKeeper, dass ZooKeeper in einem Full-Service-Szenario eine große Anzahl von Anforderungen verarbeiten muss, wenn die Anwendung freigegeben wird, und die durch die Anforderungen generierten Objekte zu häufigem Young GC in der vorhandenen Anwendung führen Aufbau.
Als Reaktion auf dieses Szenario passte das MSE-Team die Clusterkonfiguration durch mehrere Stresstestrunden an, um den optimalen Schnittpunkt zwischen Anforderungsverzögerung und TPS zu finden. Unter der Voraussetzung, die Verzögerungsanforderungen zu erfüllen, untersuchte das MSE-Team die optimale Leistung des Clusters und garantiert eine Anforderungsverzögerung von 20 ms. Unter der täglichen 10-W-QPS-Stufe des Clusters wird die CPU von 20 % auf 5 % reduziert und die Clusterlast deutlich reduziert.
Nachwort
Vor dem Hintergrund des harten Wettbewerbs in der digitalen Frachtbranche und der rasanten technologischen Entwicklung hat die Manbang Group ihre eigene technische Architektur erfolgreich aktualisiert und reibungslos vom selbstgebauten Eureka-Registrierungszentrum auf die effizientere und stabilere MSE Nacos-Plattform migriert. Dies stellt nicht nur die feste Entschlossenheit der Manbang Group in Bezug auf technologische Innovation und Geschäftsausweitung dar, sondern zeigt auch ihre weitreichenden Pläne für die zukünftige Entwicklung. Die Manbang Group betrachtet die Stabilität und hohe Leistung der Microservice-Architektur als den Kern ihrer digitalen Transformation. Die erhebliche Leistungsverbesserung und Stabilitätsverbesserung, die die neue Registrierungscenter-Architektur mit sich bringt, bieten Manbang eine starke Unterstützung und ermöglichen es der Plattform, besser auf das wachsende Geschäft vorbereitet zu sein Anforderungen gerecht zu werden und in der Lage zu sein, alle künftigen Herausforderungen zu meistern.
Erwähnenswert ist, dass die agile Reaktion der Manbang Group während des gesamten Migrationsprozesses und die professionelle Ausführung ihres technischen Teams auch das Tempo des Architektur-Upgrades beschleunigten. Die erfolgreiche Transformation der Geschäftsplattform stärkt nicht nur das Vertrauen der Nutzer in die Dienste von Manbang, sondern stellt auch anderen Unternehmen wertvolle Erfahrungen zur Verfügung. Auch in Zukunft wird Manbang eng mit MSE zusammenarbeiten, um die Stabilität, Skalierbarkeit und Leistung der technischen Architektur weiter zu verbessern, weiterhin Maßstäbe für die Branche zu setzen und die digitale Transformation der gesamten Logistikbranche voranzutreiben.
Während dieses Migrationsprozesses konnte das Unternehmen reibungslos und verlustfrei migriert werden und die Leistung wurde deutlich verbessert, was die hervorragende Leistung und Zuverlässigkeit von MSE im Bereich der Service-Registrierungszentren unter Beweis stellte. Ich glaube, dass mit der kontinuierlichen Weiterentwicklung von MSE das kontinuierliche Streben nach Benutzerfreundlichkeit und Stabilität zweifellos mehr Unternehmen einen enormen kommerziellen Wert bringen und eine immer wichtigere Rolle im Digitalisierungsprozess von Unternehmen spielen wird.
Darüber hinaus unterstützt MSE auch vollständig Microservice-Governance-Funktionen, einschließlich Verkehrsschutz, Full-Link-Graustufenfreigabe usw. Durch die Anwendung vollständig konfigurierter Strombegrenzungsregeln vom Eingangs-Gateway bis zum Backend werden die durch plötzlichen Datenverkehr verursachten Systemstabilitätsrisiken effektiv gelöst, wodurch ein kontinuierlicher und stabiler Betrieb des Systems gewährleistet wird und Unternehmen sich mehr auf die Entwicklung ihres Kerngeschäfts konzentrieren können. Der erfolgreiche Fall der Manbang Group hat einen neuen Meilenstein für die Branche gesetzt. Wir freuen uns darauf, weitere Unternehmen auf ihrem digitalen Weg zu sehen.
Botschaft von Manbang CTO Wang Dong (Dongtian): Das vollständige Verständnis und die Nutzung der Möglichkeiten der Cloud kann das technische Team von Manbang von kontinuierlichen Investitionen auf der untersten Ebene befreien, sich auf Systemstabilität und technische Effizienz auf höherer Ebene konzentrieren und bessere Ergebnisse erzielen architektonisches Niveau. Hoher ROI.
Empfohlene Aktivitäten:

Klicken Sie hier, um sich für die erste Sitzung zur KI-nativen Anwendungsarchitektur des Feitian Technology Salon zu registrieren.
Das chinesische KI-Team hat zusammengepackt und ist mit Hunderten von Menschen in die USA gereist. Wie viel Umsatz kann Huawei offiziell bekannt geben, dass die Open-Source-Spiegelstation der Yu Chengdong- Universität angepasst wurde? Der offiziell eröffnete externe Netzwerkzugang nutzte TeamViewer, um 3,98 Millionen zu überweisen! Was sollten Remote-Desktop-Anbieter tun? Die erste Front-End-Visualisierungsbibliothek und Gründer von Baidus bekanntem Open-Source-Projekt ECharts – ein ehemaliger Mitarbeiter eines bekannten Open-Source-Unternehmens, der „zum Meer ging“, verbreitete die Nachricht: Nachdem er von seinen Untergebenen herausgefordert worden war, wurde der Techniker Der Anführer wurde wütend und unhöflich und entließ die schwangere Mitarbeiterin. OpenAI erwog, der Rust Foundation zu erlauben, 1 Million US-Dollar zu spenden. Bitte sagen Sie mir, welche Rolle time.sleep(6) spielt ?