
Dieser Artikel ist der erste einer Reihe zum zweiten Jahrestag von CloudWeGo.
Der heutige Austausch gliedert sich hauptsächlich in drei Teile. Der erste Teil ist die Leistungsverbesserung von Kitex. Werfen wir einen Blick auf einige Fortschritte in Bezug auf
Leistung
,
Funktionalität
und
Benutzerfreundlichkeit
im vergangenen Jahr. Der zweite ist der Fortschritt von Community-Kooperationsprojekten, insbesondere von zwei Schlüsselprojekten,
der Kitex-Dubbo-
Interoperabilität
und
der Konfigurationscenter-Integration
. Der dritte Punkt besteht darin, Ihnen ein paar Spoiler zu einigen der Dinge zu geben, die wir derzeit tun und planen.
Leistungserweiterung
Leistung
Im September 2021 haben wir einen Artikel „
ByteDance Go RPC Framework Kitex Performance Optimization Practice
“ veröffentlicht, der auf der offiziellen Website von CloudWeGo zu finden ist. Dieser Artikel stellt vor, wie man mit der selbst entwickelten Netzwerkbibliothek Netpoll und dem selbst entwickelten Thrift Decoder bearbeitet fastCodec zur Optimierung der Kitex-Leistung.
Seitdem war es sehr schwierig, die Leistung des Kitex-Kernanforderungslinks zu verbessern. Tatsächlich müssen wir hart daran arbeiten, Leistungseinbußen bei Kitex zu vermeiden und gleichzeitig ständig neue Funktionen hinzuzufügen.
Trotzdem haben wir nie aufgehört, die Leistung von Kitex zu optimieren. Innerhalb von Byte experimentieren und fördern wir bereits einige Leistungsverbesserungen bei Kernlinks, die wir Ihnen später vorstellen werden.
Generalisierter Aufruf basierend auf DynamicGo
Zunächst stellen wir eine veröffentlichte Leistungsoptimierung vor: verallgemeinerte Aufrufe basierend auf DynamicGo.
Der generische Aufruf
ist eine erweiterte Funktion von Kitex. Mit dem generischen Kitex-Client kann die API des Zieldienstes direkt aufgerufen werden, ohne dass SDK-Code (d. h. Kitex-Client) vorab generiert werden muss.
Beispielsweise verwenden die internen Schnittstellentesttools, API-Gateways usw. von ByteDance den generalisierten Client von Kitex, der eine HTTP-Anfrage empfangen kann (der Anforderungstext liegt im JSON-Format vor), sie in Thrift Binary konvertieren und an Kitex Server senden kann.
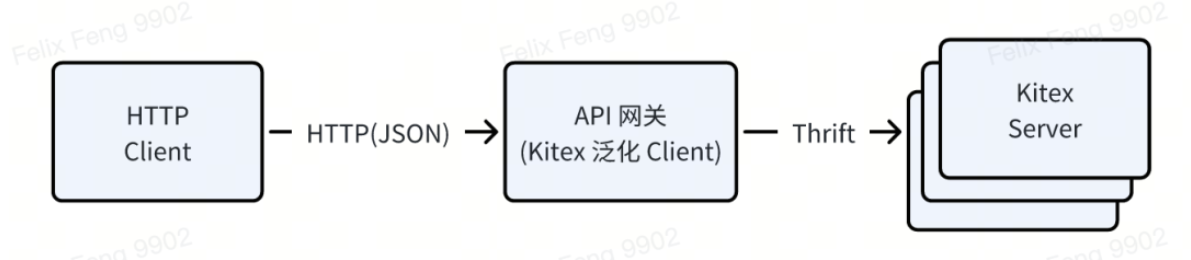
Der Implementierungsplan besteht darin, sich auf a
map[string]interface{}
als generischen Container zu verlassen, bei der Anforderung zunächst JSON in Map zu konvertieren und dann die Konvertierung von Map -> Thrift basierend auf Thrift IDL abzuschließen und die Antwort in umgekehrter Reihenfolge zu verarbeiten.
-
Dies hat den Vorteil, dass es äußerst flexibel ist und nicht auf vorgenerierten statischen Code angewiesen ist. Sie benötigen lediglich IDL, um den Zieldienst anzufordern.
-
Der Preis ist jedoch eine schlechte Leistung, da ein solcher generischer Container auf die GC- und Speicherverwaltung von Go angewiesen ist. Er muss nicht nur viel Speicher zuweisen, sondern erfordert auch mehrere Datenkopien.
Aus diesem Grund haben wir DynamicGo entwickelt (Homepage:
http://github.com/cloudwego/dynamicgo
), mit dem die Leistung der Protokollkonvertierung verbessert werden kann. In der Projekteinführung gibt es eine sehr detaillierte Einführung. Hier werde ich Ihnen nur die Kernidee des Designs vorstellen: Basierend auf
dem ursprünglichen Byte-Stream
werden
die Datenverarbeitung und -konvertierung
vor Ort abgeschlossen .
Durch die Pooling-Technologie muss Dynamicgo Speicher nur einmal vorab zuweisen und nutzt SIMD-Befehlssätze wie SSE und AVX zur Beschleunigung, wodurch letztendlich erhebliche Leistungsverbesserungen erzielt werden.
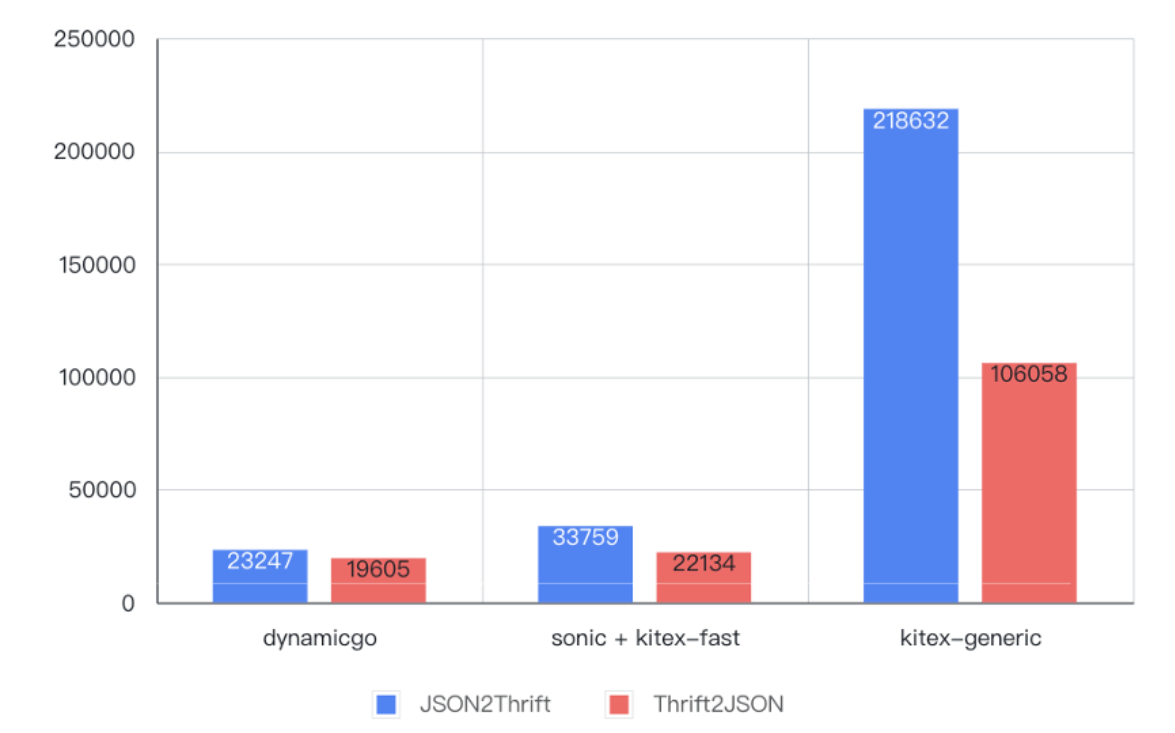
Wie in der folgenden Abbildung gezeigt, wurde die Leistung im Vergleich zur ursprünglichen Implementierung des verallgemeinerten Aufrufs beim Codierungs- und Decodierungstest von 6-KB-Daten um das
4- bis 9-fache
verbessert , sogar
besser als
beim vorgenerierten statischen Code.
Das eigentliche Prinzip ist sehr einfach: Generieren Sie einen Typdeskriptor basierend auf der IDL-Analyse und führen Sie den folgenden Protokollkonvertierungsprozess durch
-
Jedes Mal ein Schlüssel/Wert-Paar aus dem JSON-Byte-Stream lesen;
-
Suchen Sie das Thrift-Feld, das dem Schlüssel gemäß dem IDL-Deskriptor entspricht.
-
Vervollständigen Sie die Kodierung von Value gemäß der Thrift-Kodierungsspezifikation des entsprechenden Typs und schreiben Sie ihn in den Ausgabebyte-Stream.
-
Führen Sie diesen Vorgang in einer Schleife durch, bis der gesamte JSON verarbeitet ist.
Zusätzlich zur Optimierung der JSON/Thrift-Protokollkonvertierung bietet DynamicGo auch die Thrift-DOM-Methode, um die Leistung von Datenorchestrierungsszenarien zu optimieren. Beispielsweise muss ein Geschäftsteam von Douyin illegale Daten in der Anfrage löschen, die Verwendung der Thrift-DOM-API von DynamicGo ist jedoch sehr gut geeignet und kann eine zehnfache Leistungsverbesserung erreichen Die Dokumentation von DynamicGo wird hier nicht weiter erläutert.
Frugal – Ein leistungsstarker JIT-basierter Thrift-Codec
Frugal ist ein leistungsstarker Thrift-Codec, der auf
der JIT- Kompilierungstechnologie basiert.
Die offiziellen Standardcodecs von Thrift und Kitex basieren auf der Analyse von Thrift IDL und der Generierung des entsprechenden Codierungs- und Decodierungs-Go-Codes. Durch die JIT-Technologie können wir zur
Laufzeit dynamisch
Codierungs- und Decodierungscodes
mit besserer Leistung generieren : Kompakteren Maschinencode generieren, Cache-Fehler reduzieren, Verzweigungsfehler reduzieren,
SIMD-
Anweisungen zur Beschleunigung verwenden und registerbasierte Funktionsaufrufe verwenden (Go basiert auf der Standardeinstellung). auf Stapel).
Hier sind die Leistungsindikatoren der Kodierungs- und Dekodierungstests:

Wie man sieht, ist die Leistung von Frugal deutlich höher als bei herkömmlichen Methoden.
Neben den Leistungsvorteilen ergeben sich noch weitere Vorteile, da kein Codec-Code generiert wird.
Einerseits
ist das Lager übersichtlicher
. Nach der Umstellung auf sparsam ist der generierte Code nur noch 37 MB groß, was etwa 5 % der ursprünglichen Größe entspricht , und nach der Änderung des IDL-Codes wird nicht viel Code generiert, andererseits können auch
die Ladegeschwindigkeit der IDE und
die Kompilierungsgeschwindigkeit
des Projekts erheblich verbessert werden.
Tatsächlich wurde Frugal letztes Jahr veröffentlicht, aber die frühe Versionsabdeckung war zu diesem Zeitpunkt nicht ausreichend. Dieses Jahr haben wir uns auf die Optimierung der Stabilität konzentriert und alle bekannten Probleme behoben. Die kürzlich veröffentlichte Version v0.1.12 kann stabil im Produktionsbetrieb eingesetzt werden. Im E-Commerce-Geschäftsbereich von ByteDance liegt der Spitzen-QPS eines bestimmten Dienstes beispielsweise bei etwa 25.000. Er wurde vollständig auf Frugal umgestellt und läuft seit mehreren Monaten stabil.
Frugal unterstützt derzeit Go1.16 ~ Go1.21, unterstützt derzeit nur die AMD64-Architektur und wird in Zukunft auch die ARM64-Architektur unterstützen. Möglicherweise wird Frugal in einer zukünftigen Version als Standardcodec von Kitex verwendet.
Funktion
Kitex wurde im vergangenen Jahr von v0.4.3 auf v0.7.2 aktualisiert. Es gibt mehr als 40 funktionsbezogene Pull-Anfragen, die
Befehlszeilentools
,
gRPC
,
Thrift-
Kodierung und -Dekodierung, Wiederholungsversuche , allgemeine Aufrufe und Service-Governance-Konfigurationen abdecken
.
In vielerlei Hinsicht konzentrieren wir uns hier auf einige weitere wichtige Funktionen.
Fallback – benutzerdefiniertes Business-Downgrade
Die erste ist die von Kitex in Version v0.5.0 hinzugefügte Fallback-Funktion.
Der Nachfragehintergrund besteht darin, dass der Geschäftscode häufig einige Downgrade-Strategien implementieren muss, wenn die RPC-Anforderung fehlschlägt und die Antwort nicht abgerufen werden kann.
Wenn beispielsweise im Informationsflussgeschäft die API-Zugriffsschicht beim Anfordern empfohlener Dienste auf einen gelegentlichen Fehler (z. B. eine Zeitüberschreitung) stößt, besteht der einfache und grobe Ansatz darin, dem Benutzer mitzuteilen, dass ein Fehler aufgetreten ist, und ihn es erneut versuchen zu lassen Dies wird zu einer schlechten Erfahrung führen. Eine bessere Downgrade-Strategie besteht darin, zu versuchen, einige beliebte Artikel zurückzugeben. Die Benutzer werden davon fast keine Ahnung haben und das Erlebnis wird viel besser sein.
Das Problem mit der alten Version von Kitex besteht darin, dass die geschäftsspezifische Middleware nach der integrierten Middleware wie Leistungsschalter und Timeout nicht implementiert werden kann. Die einzige Möglichkeit besteht darin, den Geschäftscode direkt zu ändern, was ziemlich aufdringlich ist Erfordert die Änderung jeder Methode. Wird leicht übersehen. Beim Hinzufügen einer Geschäftslogik, die eine bestimmte Methode aufruft, gibt es keinen Mechanismus, der sicherstellt, dass diese nicht übersehen wird.
Durch die neue Fallback-Funktion
kann das Unternehmen bei der Initialisierung des Clients eine Fallback-Methode angeben, um die Downgrade-Strategie umzusetzen
.
Hier ist ein einfaches Anwendungsbeispiel:

Diese beim Initialisieren des Clients angegebene Methode wird vor dem Ende jeder Anfrage aufgerufen. Der Kontext, die Anfrageparameter und die Antwort dieser Anfrage können abgerufen werden. Auf dieser Grundlage kann eine benutzerdefinierte Downgrade-Strategie implementiert werden, wodurch die Implementierung konvergiert wird Strategie.
Thrift FastCodec – unterstützt unbekannte Felder
In tatsächlichen Geschäftsszenarien umfasst ein Anforderungslink häufig mehrere Knoten.
Am Beispiel der Verbindung A -> B -> C -> D muss eine bestimmte Struktur von Knoten A transparent über B und C an Knoten D übertragen werden. Wenn in der vorherigen Implementierung beispielsweise ein neues Feld zu A hinzugefügt wird
Extra
, muss ich die neue IDL
verwenden,
um den Code aller Knoten neu zu generieren und ihn erneut bereitzustellen, um den Wert des Extra-Felds in Knoten D zu erhalten. Der gesamte Prozess ist komplex und der Aktualisierungszyklus ist relativ lang. Handelt es sich bei dem Zwischenknoten um einen Dienst eines anderen Teams, ist eine teamübergreifende Koordination erforderlich, die sehr aufwändig ist.
In Kitex v0.5.2 haben wir die Funktion „Unbekannte Felder“ in unserem selbst entwickelten fastCodec implementiert, die dieses Problem sehr gut lösen kann.
Beispielsweise bleiben im selben Link A -> B -> C -> D die Codes der Knoten B und C unverändert (wie in der folgenden Abbildung gezeigt). Beim Parsen wird festgestellt, dass ein Feld vorhanden
id=2
ist Das entsprechende Feld kann in der Struktur nicht gefunden werden. Daher
_unknownFields
wird dieses nicht exportierte Feld (eigentlich ein Alias eines Byte-Slices) geschrieben.

Die A- und D-Dienste werden mit der neuen IDL neu generiert (wie in der Abbildung unten gezeigt) und enthalten
Extra
das Feld. Daher
id=2
können Sie beim Parsen des Felds in dieses
Extra
Feld schreiben und den Geschäftscode normal verwenden.

Darüber hinaus haben wir in Version 0.7.0 eine Leistungsoptimierung für diese Funktion durchgeführt und dabei „
keine
Serialisierung
“ (direktes Kopieren von Byteströmen) verwendet, um die Codierungs- und Decodierungsleistung unbekannter Felder um etwa
das Sechs- bis Siebenfache
zu verbessern .
Sitzungsbereitstellungsmechanismus basierend auf GLS
Eine weitere Funktion, die es wert ist, Ihnen vorgestellt zu werden, betrifft auch lange Links.
Innerhalb von Byte verwenden wir LogID, um die gesamte Anrufkette zu verfolgen, was erfordert, dass alle Knoten im Link dieses Ticket bei Bedarf transparent übertragen. In unserer Implementierung wird LogID nicht im Anfragetext platziert, sondern transparent in Form von Metadaten übermittelt.
Nehmen Sie als Beispiel den Link A -> B -> C. Wenn A die
A_Call_B
Methode von B aufruft, wird die eingehende LogID im Handler-Eingabeparameter gespeichert . Die korrekte Verwendung besteht darin, diese nur an die Methode
ctx
zu übergeben Auf diese Weise kann die LogID weitergegeben werden.
ctx
client
C.B_Call_C

Die tatsächliche Situation ist jedoch häufig, dass der Code, der den C-Dienst anfordert, in mehreren Schichten verpackt ist und
die transparente Übertragung von ctx leicht übersehen wird
. Die Situation, auf die wir gestoßen sind, ist problematischer. Die Anforderung für den C-Dienst wird
von einem Dritten ausgeführt Die Bibliothek
und die Schnittstelle der Bibliothek unterstützen keinen eingehenden Code
ctx
. Eine solche Codetransformation ist sehr kostspielig und erfordert möglicherweise die Koordination mehrerer Teams.
Um dieses Problem zu lösen, haben wir einen Sitzungsübertragungsmechanismus basierend auf GLS (Goroutine Local Storage) eingeführt. Der konkrete Plan ist:
-
Auf der Kitex-Serverseite wird nach Erhalt der Anforderung zunächst der Kontext in GLS gesichert und dann der Handler aufgerufen, bei dem es sich um den Geschäftscode handelt.
-
Wenn Sie den Client im Geschäftscode aufrufen, um eine Anfrage zu senden, prüfen Sie zunächst, ob der Eingabe-CTX das erwartete Ticket enthält. Wenn nicht, entnehmen Sie es aus der GLS-Sicherung und senden Sie dann die Anfrage.
Hier ist ein konkretes Beispiel:

veranschaulichen:
-
ContextBackupSchalten Sie den Schalter ein , wenn Sie den Server initialisieren -
Geben Sie einen an, wenn Sie den Client initialisieren
backupHandler -
Vor jeder Anfrage wird dieser Handler aufgerufen, um zu prüfen, ob die Eingabeparameter enthalten sind
LogID -
ctxWenn es nicht enthalten ist, lesen Sie es aus dem Backup , führen Sie es mit dem aktuellen zusammenctxund geben Sie es zurück (RückgabeuseNewCtx =truebedeutet, dass Kitex dieses neuectxzum Senden der Anfrage verwenden sollte).
Nach dem Aktivieren der obigen Einstellungen kann der gesamte Link in Reihe geschaltet werden, auch wenn der Geschäftscode den falschen Kontext verwendet.
Lassen Sie uns abschließend den asynchronen Parameter der Serverinitialisierung vorstellen, der das Problem des Sendens von Anforderungen in einer neuen Goroutine im Handler löst. Da es sich nicht um dieselbe Goroutine handelt, kann der lokale Speicher nicht direkt gemeinsam genutzt werden. Wir lernen aus dem Mechanismus von pprof zum Färben von Goroutinen und übergeben das Backup
ctx
an die neue Goroutine, wodurch wir die Möglichkeit erkennen , Tickets implizit in
asynchronen
Szenarien
weiterzugeben .
Benutzerfreundlichkeit
Neben hoher Leistung und umfangreicher Funktionalität legen wir auch großen Wert auf die Verbesserung der Benutzerfreundlichkeit von Kitex.
Dokumentation |. Dokumentation
Wie wir alle wissen, gibt es zwei Dinge, die Programmierer am meisten hassen: Der eine ist das Schreiben von Dokumentation, der andere ist, dass andere keine Dokumentation schreiben. Deshalb legen wir großen Wert darauf, die Anlaufkosten für das Schreiben von Dokumenten zu senken und arbeiten hart daran, die Dokumentenerstellung zu fördern.
Innerhalb von ByteDance sind die Dokumente von Kitex in Form einer Feishu-Wissensdatenbank organisiert, die besser in die Suche von Byte-Mitarbeitern integriert werden kann und die Aktualisierung von Feishu-Dokumenten erleichtert Es werden neue Funktionen entwickelt, Dokumente werden oft zuerst in die Feishu-Wissensdatenbank geschrieben und einige werden nicht rechtzeitig mit der offiziellen Website synchronisiert. Verschiedene Gründe haben zu den wachsenden Unterschieden zwischen den inneren und äußeren Ästen geführt.
Aus diesem Grund haben wir in den letzten beiden Quartalen eine neue Runde der Dokumentenoptimierung gestartet: Basierend auf dem Feedback der Benutzer haben wir alle Dokumente neu organisiert und weitere Beispiele hinzugefügt. Wir haben alle Dokumente ins Englische übersetzt und mit der offiziellen Website synchronisiert. Diese Arbeiten werden voraussichtlich in diesem Jahr abgeschlossen sein. Auf der offiziellen Website können Sie bereits einige aktualisierte Dokumente einsehen, z. B. Timeout-Kontrolle, Frugal, Panikverarbeitung usw. Sie sind herzlich eingeladen, die offizielle Website zu besuchen und bei der Fehlersuche zu helfen.
Darüber hinaus bauen wir einen Mechanismus zur automatischen Synchronisierung interner Dokumente mit der offiziellen Website auf. Wir hoffen, dass Open-Source-Benutzer in Zukunft ebenso zeitnah aktualisierte Dokumente erhalten können.
Andere Optimierungen |. Verschiedenes
Neben der Dokumentation erledigt Kitex auch einige andere Arbeiten im Zusammenhang mit der Benutzerfreundlichkeit.
Wir haben ein Beispielprojekt „Note Service“ veröffentlicht, das die Verwendung verschiedener Funktionen wie Middleware, Strombegrenzung, Wiederholungsversuche, Timeout-Kontrolle usw. demonstriert und Kitex-Benutzern anhand realen Projektcodes Referenzen bietet Schauen Sie sich das Beispiel hier an: https://github.com/cloudwego/kitex-examples/tree/main/bizdemo/easy_note.
Zweitens arbeiten wir auch hart daran, die Effizienz der Fehlerbehebung zu verbessern. Beispielsweise haben wir der Fehlermeldung basierend auf den täglichen Bereitschaftsanforderungen spezifischere Kontextinformationen hinzugefügt (z. B. den spezifischen Grund für den Timeout-Fehler, den Methodennamen für die Panik). Nachricht und die Thrift-Codec-Fehlermeldung (spezifische Feldnamen usw.), um bestimmte Problempunkte schnell zu lokalisieren.
Darüber hinaus werden die Kitex-Befehlszeilentools ständig verbessert.
-
Beispielsweise konnten viele Unternehmensbenutzer unter Windows keinen normalen Code generieren. Daher benötigten diese Benutzer auch eine Linux-Umgebung zur Unterstützung, was aufgrund des Feedbacks dieser Benutzer sehr unpraktisch war .
-
Wir haben auch ein IDL-Clipping-Tool implementiert, das nicht referenzierte Strukturen identifizieren und direkt beim Generieren von Code herausfiltern kann. Dies ist sehr hilfreich für einige alte Projekte, die hängen bleiben.
Gemeinschaftskooperationsprojekte
Im vergangenen Jahr haben wir mit der Unterstützung der CloudWeGo-Community auch viele Ergebnisse erzielt, insbesondere die beiden Projekte Dubbo-Interoperabilität und Konfigurationscenter-Integration.
Dubbo 互通 | Dubbo-Interkommunikation
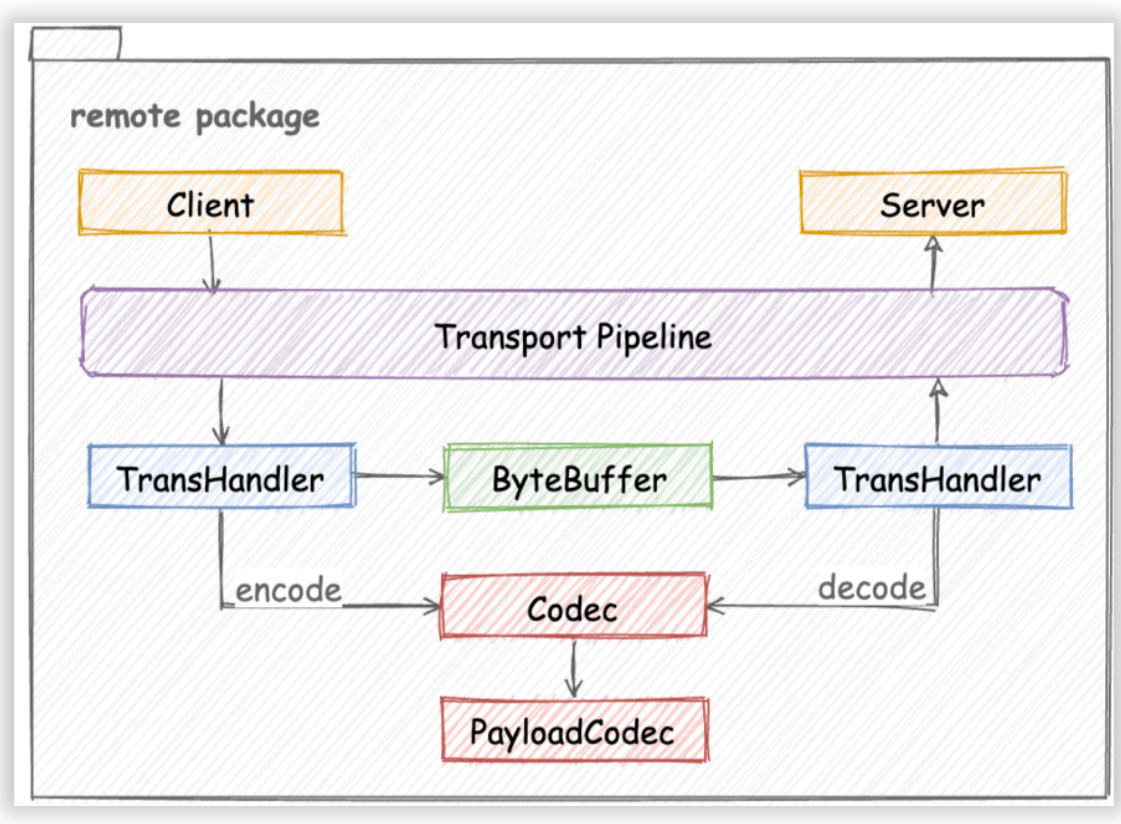
Obwohl Kitex ursprünglich ein Thrift-RPC-Framework war, weist sein Architekturdesign eine gute Skalierbarkeit auf. Wie in der Abbildung gezeigt, besteht die Kernarbeit beim Hinzufügen neuer Protokolle darin, einen entsprechenden Protokollcodec (Codec oder PayloadCodec) entsprechend der Codec-Schnittstelle zu implementieren:
Das Dubbo-Interoperabilitätsprojekt entstand aus den Bedürfnissen eines Unternehmensbenutzers. Sie haben einige periphere Dienste von Lieferanten implementiert, die Dubbo Java verwenden. Sie hoffen, diese Dienste mithilfe von Kitex anzufordern und die Projektmanagementkosten zu senken.
Dieses Projekt wurde von den Studenten der Gemeinde begeistert unterstützt und viele Studenten haben an diesem Projekt teilgenommen. Insbesondere @DMwangnima, der für eine der Kernaufgaben verantwortlich ist, ist auch ein Entwickler der Dubbo-Community. Da er mit Dubbo vertraut ist, konnte der Entwicklungsprozess viele Umwege vermeiden.
Bezüglich des konkreten Umsetzungsplans haben wir eine andere Idee übernommen als der Dubbo-Beamte. Gemäß der Analyse des Hessian2-Protokolls überschneidet sich sein grundlegendes Typsystem grundsätzlich mit Thrift. Daher haben wir das Kitex Dubbo-Hessian2-Projektgerüst basierend auf Thrift IDL generiert.
Um die Funktion in der ersten Phase schnell zu implementieren, haben wir uns direkt die hessian2-Bibliothek des Dubbo-go-Frameworks für die Serialisierung und Deserialisierung ausgeliehen und den Kitex-eigenen DubboCodec implementiert, indem wir auf die offizielle Dokumentation von Dubbo und den Dubbo-Go-Quellcode verwiesen haben.
Im Oktober haben wir die erste Version des Codes fertiggestellt. Die Projektadresse lautet
https://github.com/kitex-contrib/codec-dubbo
. In Bezug auf die spezifische Verwendung können interessierte Benutzer ihn ausprobieren. Es kann mit Kitex verglichen werden. Schreiben Sie wie bei Thrift die Thrift-IDL, generieren Sie mit der Kitex-Befehlszeile ein Gerüst (beachten Sie, dass das Protokoll als hessian2 angegeben werden muss) und geben Sie dann DubboCodec im Code an, in dem der Client und der Server initialisiert werden , und Sie können mit dem Schreiben von Geschäftscode beginnen.
Dadurch wird nicht nur die Benutzerschwelle gesenkt, sondern IDL wird auch zur Verwaltung schnittstellenbezogener Informationen verwendet, wodurch die Wartbarkeit verbessert wird.
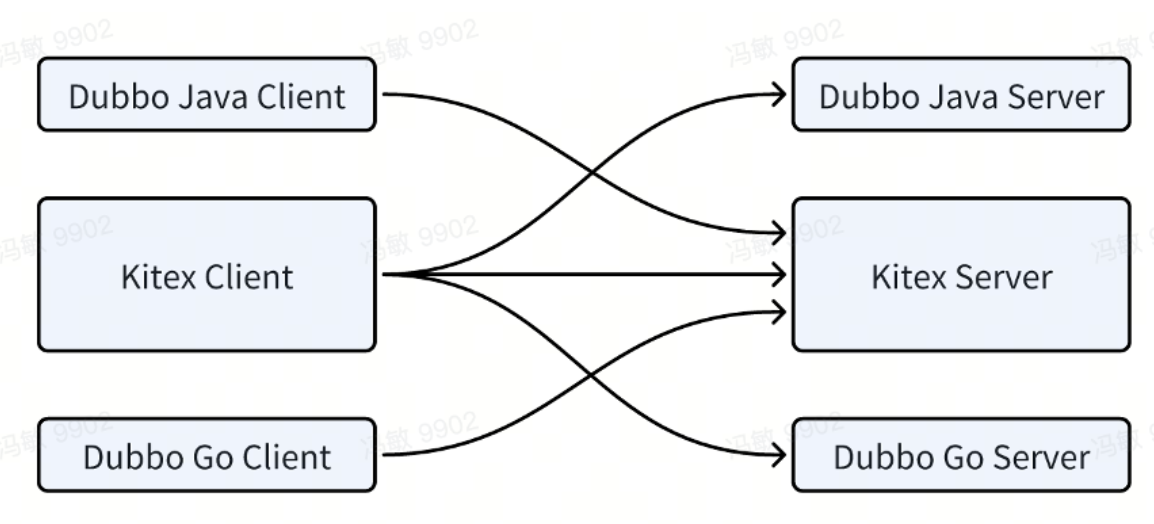
Derzeit konnten wir Interoperabilität zwischen Kitex und Dubbo-Java, Kitex und Dubbo-Go erreichen :
Zukunftsplan:
-
Die erste besteht darin, die Kompatibilität mit Dubbo-Java zu verbessern und Benutzern die Angabe des entsprechenden Java-Typs in IDL-Annotationen zu ermöglichen.
-
Der zweite ist die Verbindung mit dem Registrierungszentrum. Obwohl Kitex bereits über ein entsprechendes Registrierungscenter-Modul verfügt, stimmt das spezifische Datenformat nicht mit Dubbo überein. In diesem Bereich sind noch einige Änderungen erforderlich, und die entsprechenden Arbeiten stehen kurz vor dem Abschluss.
-
Schließlich gibt es noch eine große Lücke im Vergleich zu Kitex Thrift. Da die dubbo-go-hessian2-Bibliothek vollständig auf Reflexion basiert, gibt es noch viel Raum für Leistungsoptimierung. Es ist geplant, den FastCodec von Hessian2 zu implementieren, um den Leistungsengpass beim Kodieren und Dekodieren zu beheben.
Während der Weiterentwicklung dieses Projekts haben wir die positiven Auswirkungen der gemeinschaftsübergreifenden Zusammenarbeit erlebt und auch Bereiche entdeckt, in denen das Dubbo-go-Projekt verbessert werden könnte. Die oben genannten Kompatibilitäts- und Leistungslösungen Es wird auch erwartet, dass er der Dubbo-Community Feedback gibt.
Ich möchte auch den Community-Mitwirkenden an diesem Projekt, @DMwangnima, @Lvnszn, @ahaostudy, @jasondeng1997, @VaderKai und anderen Studenten, meinen besonderen Dank dafür aussprechen, dass sie einen Großteil ihrer Freizeit für die Fertigstellung dieses Projekts aufgewendet haben.
Config Center-Integration |. Config Center-Integration
Ein weiteres Schlüsselprojekt der Community-Kooperation ist „Configuration Center Integration“.
Kitex bietet dynamisch konfigurierbare Service-Management-Funktionen, einschließlich Client-Timeout, Wiederholung, Leistungsschalter und Serverstrombegrenzung.
Diese Service-Governance-Funktionen werden von Bytes selbst erstellter Service-Governance-Konfigurationsplattform intensiv genutzt und sind quasi in Echtzeit wirksam Sehr hilfreich, um das SLA von Microservices zu verbessern.
Wir haben jedoch mit Unternehmensbenutzern kommuniziert und festgestellt, dass diese Funktionen normalerweise nur sehr einfach zu verwenden sind, eine grobe Granularität aufweisen und nicht rechtzeitig verfügbar sind. Es handelt sich möglicherweise nur um fest codierte spezifizierte Konfigurationen oder um die Konfiguration über einfache Dateien, und um wirksam zu werden, ist ein Neustart erforderlich .
Damit Benutzer die Service-Governance-Funktionen von Kitex besser nutzen können, haben wir das Konfigurationscenter-Integrationsprojekt gestartet, damit Kitex
Service-Governance-Konfigurationen dynamisch vom Konfigurationscenter des Benutzers abrufen
und nahezu in Echtzeit wirksam werden kann.
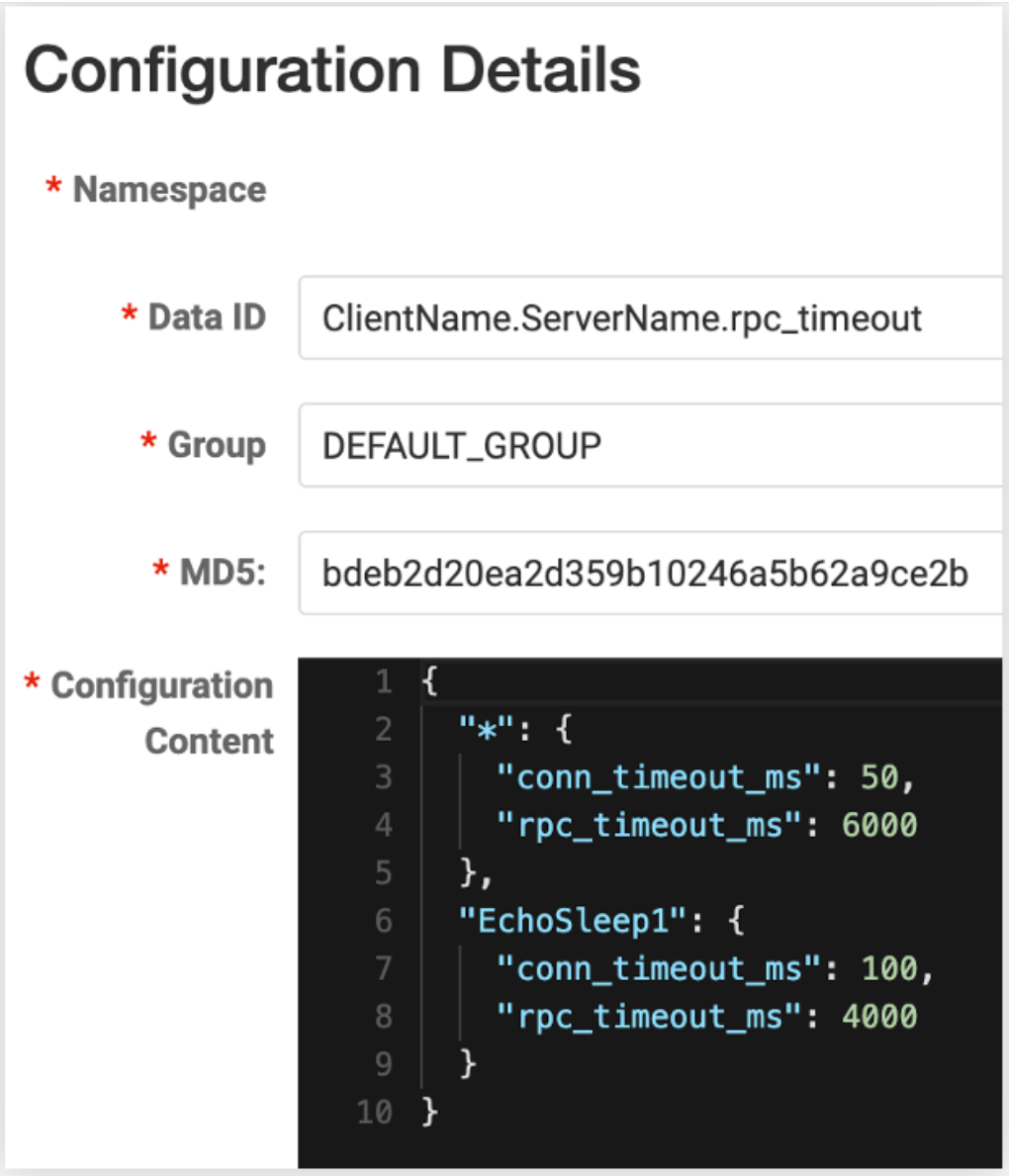
Wir haben die Version 0.1.1 von config-nacos veröffentlicht (Hinweis: Sie wurde zum Zeitpunkt der Veröffentlichung auf Version 0.3.0 aktualisiert, vielen Dank an @whalecold für seine kontinuierliche Investition durch das Hinzufügen des Clients zum bestehenden Kitex-Projekt)
NacosClientSuite
. kann einfach
vorgenommen werden, dass Kitex
die entsprechende Service-Governance-Konfiguration von
Nacos
lädt .

Da wir die vom Nacos-Client selbst bereitgestellte Überwachungsfunktion nutzen, können wir Konfigurationsänderungsbenachrichtigungen quasi in Echtzeit erhalten, sodass die Aktualität ebenfalls sehr hoch ist und kein Neustart des Dienstes erforderlich ist.
Darüber hinaus haben wir uns auch die Möglichkeit vorbehalten, die Konfigurationsgranularität zu ändern. Die Standardkonfigurationsgranularität ist beispielsweise Client + Server. Geben Sie einfach die Daten-ID von Nacos ein. Benutzer können auch die Vorlage dieser Daten-ID angeben. Fügen Sie beispielsweise Computerräume, Cluster usw. hinzu, um diese Konfigurationen genauer anzupassen.
Wir planen, die Integration mit gängigen Konfigurationszentren abzuschließen. Detailliertere Anweisungen finden Sie in dieser Ausgabe https://github.com/cloudwego/kitex/issues/973.
Der aktuelle Fortschritt ist:
-
Module wie File, Apollo, etcd und Zookeeper haben PRs eingereicht und werden derzeit überprüft;
-
der Plan des Konsuls wurde vorgelegt;
Interessierte Studierende können auch mitmachen, um diese Erweiterungsmodule zu begutachten, zu testen und zu verifizieren.
Zukunftsausblick
Abschließend möchte ich Ihnen einige Spoiler zu einigen der Richtungen geben, die wir derzeit ausprobieren.
Merge-Bereitstellung
Affinitätsbereitstellung |. Affinitätsbereitstellung
Die meisten unserer bisherigen Optimierungen erfolgten innerhalb des Dienstes, aber als die Anzahl der Optimierungspunkte allmählich abnahm, begannen wir, andere Ziele in Betracht zu ziehen, beispielsweise die Optimierung des Netzwerkkommunikations-Overheads von RPC-Anfragen.
Die konkreten Pläne lauten wie folgt:
-
Die erste ist die Affinitätsplanung. Durch die Änderung des Containerplanungsmechanismus versuchen wir, den Client und den Server auf derselben physischen Maschine zu planen.
-
So können wir die Kommunikation auf derselben Maschine nutzen, um den Overhead zu reduzieren.
Derzeit umfasst die von uns implementierte Kommunikation mit derselben Maschine die folgenden drei Typen:
-
Unix Domain Socket bietet eine bessere Leistung als Standard-TCP-Socket, aber nicht viel;
-
ShmIPC (https://github.com/cloudwego/shmipc-go), eine auf gemeinsam genutztem Speicher basierende prozessübergreifende Kommunikation, kann die Übertragung serialisierter Daten direkt unterlassen und muss dem Empfänger lediglich die Speicheradresse mitteilen.
-
Schließlich gibt es noch die „schwarze Technologie“ RPAL , die Abkürzung für Run Process As Library. Wir arbeiten mit dem Kernel-Team von Byte zusammen, um zwei Prozesse über einen angepassten Kernel in denselben Adressraum zu bringen Möglicherweise muss nicht einmal eine Serialisierung durchgeführt werden.
Derzeit haben wir diese Funktion für mehr als 100 Dienste aktiviert und einige Leistungssteigerungen erzielt. Bei Diensten mit besseren Effekten kann sie natürlich etwa 5 bis 10 % der CPU einsparen und den Zeitverbrauch um 10 bis 70 % reduzieren Praxis: Die Leistung hängt von einigen Merkmalen des Dienstes ab, beispielsweise der Paketgröße.
Zusammenführung zur Kompilierungszeit |. Service Inline
Eine weitere Idee ist das Zusammenführen zur Kompilierzeit.
Der Ausgangspunkt dieser Lösung ist, dass wir herausgefunden haben, dass Microservices zwar die Effizienz der Teamzusammenarbeit verbessern, aber auch die Gesamtkomplexität des Systems erhöhen, insbesondere im Hinblick auf Servicebereitstellung, Ressourcenbelegung, Kommunikationsaufwand usw.
Daher hoffen wir, eine Lösung implementieren zu können, die es dem Unternehmen ermöglicht, in Form von Microservices zu entwickeln und in Form einzelner Services bereitzustellen, was allgemein als „beides“ bezeichnet wird.
Dann haben wir diesen Plan entwickelt: Wir haben ein Tool entwickelt, das das Git-Repo zweier Microservices zusammenführen, potenziell widersprüchliche Ressourcen über den Namespace isolieren und es dann in ein ausführbares Programm für die Bereitstellung kompilieren kann.
Derzeit sind innerhalb von ByteDance Dutzende von Diensten verbunden. Der effektivste Dienst kann etwa 80 % der CPU einsparen und die Latenz um bis zu 67 % reduzieren. Natürlich hängt die tatsächliche Leistung auch von den Eigenschaften des Dienstes ab, z Taschengröße.
Das Obige ist unser Versuch einer Affinität.
Serialisierung
Im Hinblick auf die Serialisierung unternehmen wir noch einige Anstrengungen und Versuche.
Sparsam – SSA-Backend
Der erste ist Frugal. Wie bereits erwähnt, ist seine Leistung deutlich besser als die des herkömmlichen Thrift-Codierungs- und Decodierungscodes, es besteht jedoch noch Raum für Verbesserungen.
Die aktuelle Implementierung von Frugal verwendet Go, um den entsprechenden Assemblercode direkt zu generieren. Wir haben auch einige Optimierungsmethoden in der spezifischen Implementierung angewendet, z. B. das Generieren von kompakterem Code, das Reduzieren von Verzweigungen usw. Allerdings können wir die vorhandene Compiler-Optimierungstechnologie nicht vollständig nutzen, indem wir sie selbst schreiben.
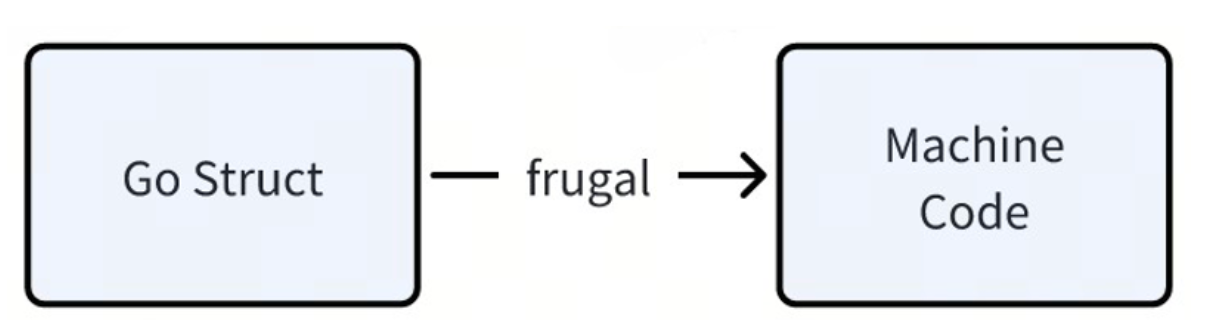
Wir planen, Frugal zu rekonstruieren, um eine SSA-kompatible LLVM-IR (Intermediate Representation) basierend auf der Go-Struktur zu generieren, damit wir die Kompilierungsoptimierungsfunktionen von LLVM vollständig nutzen können.

Es wird erwartet, dass nach dieser Transformation die Leistung um mindestens 30 % verbessert werden kann.
On-Demand-Serialisierung |. On-Demand-Serialisierung
Eine weitere Forschungsrichtung ist die On-Demand-Serialisierung, die in drei Teile unterteilt werden kann.
Der erste ist vor der Kompilierung. Wir haben derzeit ein IDL-Clipping-Tool veröffentlicht, das Typen identifizieren kann, auf die nicht verwiesen wird. Die referenzierten Typen sind jedoch möglicherweise nicht erforderlich. Beispielsweise hängen zwei Dienste A und B vom gleichen Typ ab, aber eines der Felder kann A sein. Erforderlich, B nicht erforderlich. Wir erwägen, diesem Tool Benutzeranmerkungsfunktionen hinzuzufügen, die es Benutzern ermöglichen, unnötige Felder anzugeben und so den Serialisierungsaufwand weiter zu reduzieren.
Die zweite ist die Kompilierung. Die Idee besteht darin, die Felder abzurufen, die tatsächlich gegen die Geschäftscode-Referenz verstoßen, und sie basierend auf dem Kompilierungsbericht des Compilers zu bereinigen. Das konkrete Schema und die Richtigkeit bedürfen noch einiger Überprüfung.
Schließlich kann das Unternehmen nach der Kompilierung zur Laufzeit auch unnötige Felder angeben, wodurch Codierungs- und Decodierungsaufwand eingespart wird.
Zusammenfassung |. Zusammenfassung
Schauen wir uns abschließend die Gesamtsituation an:
Im Hinblick auf die Leistungserweiterung
-
Kitex hat die Leistung von Generalisierungsaufrufen durch DynamicGo optimiert, und der leistungsstarke Frugal-Codec wurde stabilisiert und kann in Produktionsumgebungen verwendet werden;
-
Im vergangenen Jahr wurde ein Fallback hinzugefügt, um Unternehmen die Implementierung individueller Downgrade-Strategien zu erleichtern, und die unbekannten Felder und Sitzungsbereitstellungsmechanismen wurden verwendet, um das Problem der Transformation langer Links zu lösen.
-
Wir haben auch die Benutzerfreundlichkeit von Kitex durch Dokumentenoptimierung, Demoprojekte, Effizienzsteigerungen bei der Fehlerbehebung und verbesserte Befehlszeilentools verbessert;
Was die gemeinschaftliche Zusammenarbeit betrifft,
-
Wir unterstützen Dubbos hessian2-Protokoll durch das Kitex-Dubbo-Interoperabilitätsprojekt, das mit den Dubbo-Java- und Dubbo-Go-Frameworks zusammenarbeiten kann, und es gibt nachfolgende Optimierungen, die auch Rückmeldungen an die Dubbo-Community liefern können;
-
Im Rahmen des Konfigurationscenter-Integrationsprojekts haben wir die Nacos-Erweiterung veröffentlicht, um die Benutzerintegration zu erleichtern, und fördern derzeit weiterhin das Andocken anderer Konfigurationscenter.
Es gibt noch einige Richtungen, die in der Zukunft erkundet werden müssen.
-
In Bezug auf die zusammengeführte Bereitstellung können wir durch Affinitätsbereitstellung sowie Kompilierung und Zusammenführung nicht nur die Vorteile von Microservices beibehalten, sondern auch die Vorteile einiger Monolithen nutzen, die keine Dienste bereitstellen.
-
Im Hinblick auf die Serialisierung optimieren wir Frugal weiter und erreichen On-Demand-Serialisierungsfunktionen in allen Aspekten der Kompilierung vor, während und nach der Kompilierung.
Das Obige ist ein Rückblick und Ausblick auf Kitex anlässlich des zweiten Jubiläums von CloudWeGo. Ich hoffe, es wird für alle hilfreich sein, vielen Dank.
{{o.name}}
{{m.name}}