

In diesem Artikel werden hauptsächlich verwandte Technologien der generativen KI vorgestellt, insbesondere die Anwendung von Convolutional Neural Network (CNN) im Bereich der Bilderkennung. Dieser Artikel ist der zweite in der Reihe,

Wenn Sie die Einführung in neuronale Netze und Deep Learning im vorherigen Artikel verstanden haben, sollte es relativ einfach sein, nach und nach ein tieferes Verständnis für KI-bezogene Konzepte und Prinzipien zu erlangen.
Ich hoffe, der letzte Artikel kann jedem einen Eindruck vermitteln: KI ist nicht so kompliziert, wie Sie denken. KI kann riesige Mengen an Informationen verarbeiten, verfügt jedoch nicht über einen äußerst komplexen Mechanismus, der für Menschen schwer zu verstehen ist. Denn nur wenn der Mechanismus relativ einfach ist, kann weniger Energie verbraucht, die Berechnungsgeschwindigkeit schnell sein und mehr Informationen verarbeitet werden. Dasselbe gilt auch in der Natur, wenn der Mechanismus des Gehirns komplizierter wäre als jetzt, würde das Gehirn wahrscheinlich ausgebrannt sein.
Ohne weitere Umschweife haben wir im letzten Artikel gesehen, dass das einfachste neuronale Netzwerk gleichzeitig zum Erkennen handgeschriebener Ziffern verwendet werden kann. Wir haben auch festgestellt, dass das neuronale Netzwerk nicht gut „lernt“ und kein abstraktes Verständnis hat Aufgrund der allgemeinen Gesetze des Problems treten häufig Probleme mit zwei Faktoren auf: Daten und Modell. In diesem Artikel werden wir über die Erfahrungen im Bereich der Bilderkennung im Umgang mit Überanpassung sprechen und auch darüber sprechen, wie neuronale Netze und Deep Learning auf andere Bereiche wie die Verarbeitung natürlicher Sprache ausgeweitet werden können.

Wie oben erwähnt, können neuronale Netze zur Bilderkennung eingesetzt werden. Können wir, da es sich um Bilderkennung handelt, die bekannten Methoden der Computergrafik kombinieren, um den Effekt von Deep Learning zu verbessern? Die Antwort ist ja. Das Convolutional Neural Network ist ein solches Netzwerk, das die Wirkung und Effizienz der Bilderkennung durch die Kombination grafischer Methoden erheblich optimiert.
▐Faltungsprinzip des neuronalen Netzwerks
-
Erfassungsfunktionen – Faltungsoperation (convolve): Die Faltungsschicht scannt das gesamte Bild, um grundlegende Merkmale wie die Kanten und die Textur des Objekts durch einen Filter hervorzuheben, der dem in der Bildverarbeitung ähnelt. Dies kann als Schritt des „Zeichnens von Linien“ betrachtet werden, um lokale Merkmale im Bild zur weiteren Erkennung zu erfassen. -
Vereinfachen und betonen – Pooling: Nachdem die Features durch Faltung extrahiert wurden, hilft die Pooling-Schicht dabei, die Größe der Feature-Daten zu reduzieren, was gleichzeitig die Komplexität des Bildes und die Rechenanforderungen vereinfacht. Das Zusammenfassen von Schichten wirkt so, als würde man bewusst einige der weniger wichtigen Details in einem Gemälde weglassen, um die Umrisse und die Gesamtstruktur hervorzuheben. -
Wiederholen Sie diesen Vorgang, um den Abstraktionsgrad zu erhöhen: Faltungs-Neuronale Netze verfügen häufig über mehr als eine Faltungs- und Pooling-Operation. Durch eine Reihe wiederholter Faltungen und Zusammenführungen filtert und kombiniert das Netzwerk nach und nach einfache Merkmale und kombiniert sie zu komplexeren Formen und Mustern, ähnlich dem Prozess, bei dem Kinder von Linien über Formen bis hin zu vollständigen Zeichen zeichnen. -
Merkmalssynthese – vollständig verbundene Schicht: So wie Kinder schließlich Kopf, Körper und Gliedmaßen in die richtige Position bringen, um ein Bild einer Person zu vervollständigen, verwendet das Faltungs-Neuronale Netzwerk vollständig verbundene Schichten, die auf den auf mehreren Ebenen abstrahierten Merkmalen basieren Konsolidierungs- und Klassifizierungsarbeiten. Die vollständig verbundene Ebene berücksichtigt die gesamten Merkmale auf Bildebene und lernt die komplexen Beziehungen zwischen ihnen, um den Prozess von den Merkmalen bis zur endgültigen Zielerkennung (z. B. der Identifizierung der Person im Bild) abzuschließen. Jeder ist mit der vollständigen Verbindungsschicht vertraut, bei der es sich um ein neuronales Netzwerk handelt, das aus der oben erwähnten dichten Schicht besteht.
-
Nach mehreren Runden von Faltungsoperationen haben sich die Objekte, die von der nachfolgenden vollständig verbundenen Schicht (das gleiche wie das oben erwähnte neuronale Netzwerk) verarbeitet werden müssen, von Pixeln und Farben ohne offensichtliche „realistische Semantik“ zu Kanten, Konturen, Texturen usw. geändert. usw., die über bestimmte „realistische Semantik“-Merkmale verfügen, was die Genauigkeit der Bilderkennung erheblich verbessert. -
Die Faltungsoperation erhöht die kleinste Einheit, die von der vollständig verbundenen Schicht verarbeitet werden soll, um eine Ebene (es ist, als würden Sie beim Schreiben von Code keine zeilenweisen Anweisungen schreiben, sondern Ketten verwenden, um atomare Fähigkeiten zu organisieren). Da der Pooling-Vorgang auch relativ auf die Verarbeitung von Bildern beschränkt ist, können diese beiden Methoden theoretisch die Effizienz verbessern (im Vergleich zu anderen Methoden mit ähnlicher Genauigkeit).
▐Grafik bedeutet in Faltungs-Neuronalen Netzen Filter
Welche Art von Grafikmethode kombiniert das Faltungs-Neuronale Netzwerk? Wir können uns den Faltungskern (Kernel) im Faltungs-Neuronalen Netzwerk ansehen, der in der Grafik als Filter bezeichnet wird. Schüler, die mit Photoshop oder GIMP vertraut sind, müssen beispielsweise die folgenden vier Filter kennen (3x3-Vektor im Bild):
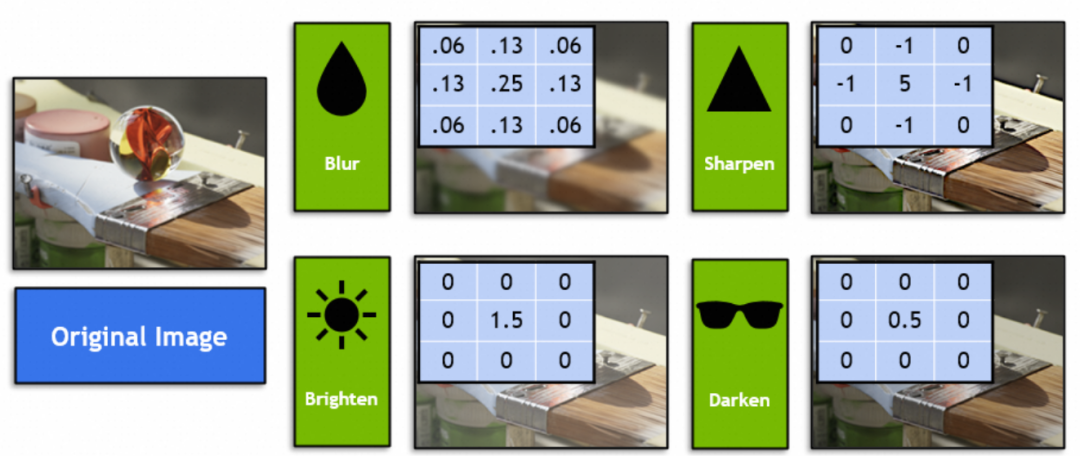
In der Mathematik sind Filter lineare algebraische Vektoroperationen: Jeder 3x3-Vektor im Originalbild wird mit dem 3x3-Vektor des Filters multipliziert und summiert. Dieser Filtervektor im Bild erreicht beispielsweise eine Unschärfe, indem 9 benachbarte Pixel zum Mittelpunkt gemischt werden:
Empirische Daten: In Faltungs-Neuronalen Netzen kann die Wahl eines Faltungskerns mit der Größe 3x3 gute Ergebnisse erzielen.
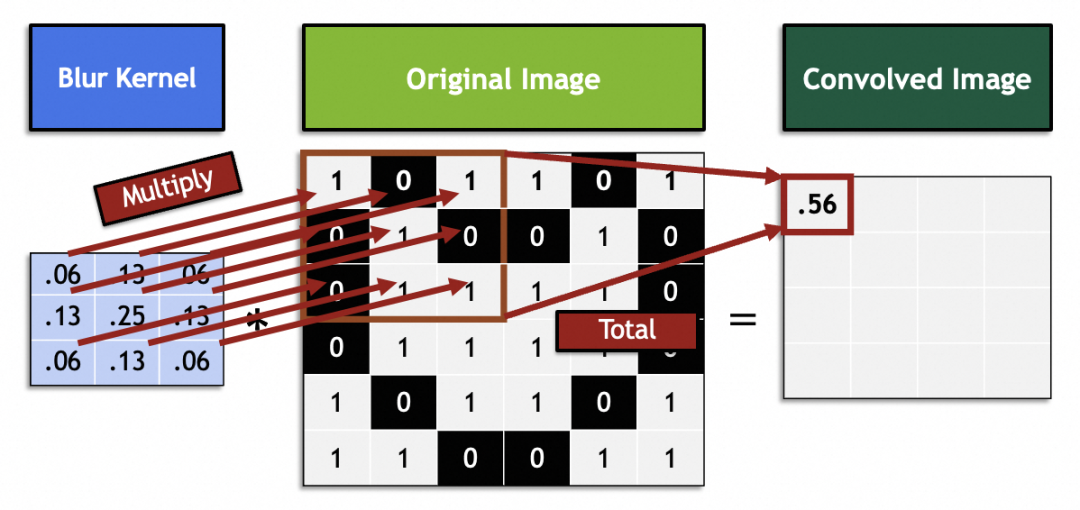
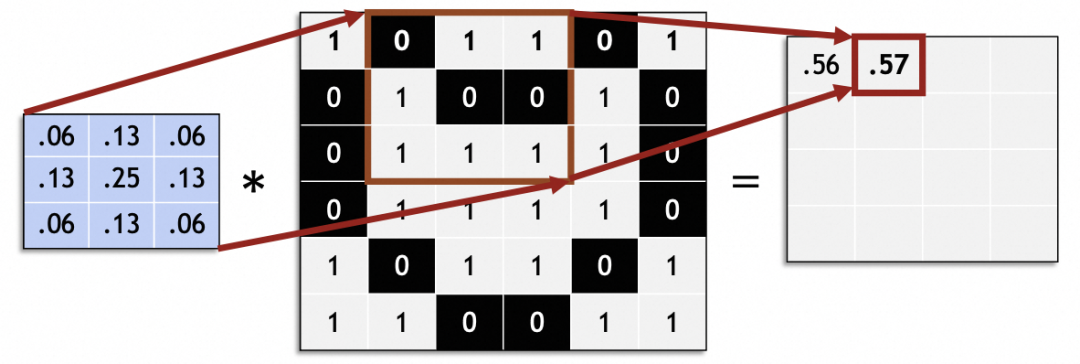
Verarbeiten Sie das gesamte Originalbild durch Schieben und generieren Sie ein neues Bild:
In einem Faltungs-Neuronalen Netzwerk beträgt die Gleitschrittgröße (Schrittweite) im Allgemeinen 1. Andere Werte als 1 können Probleme verursachen, z. B. wenn die Originalbildgröße nicht gleichmäßig durch die Schrittweite geteilt werden kann.
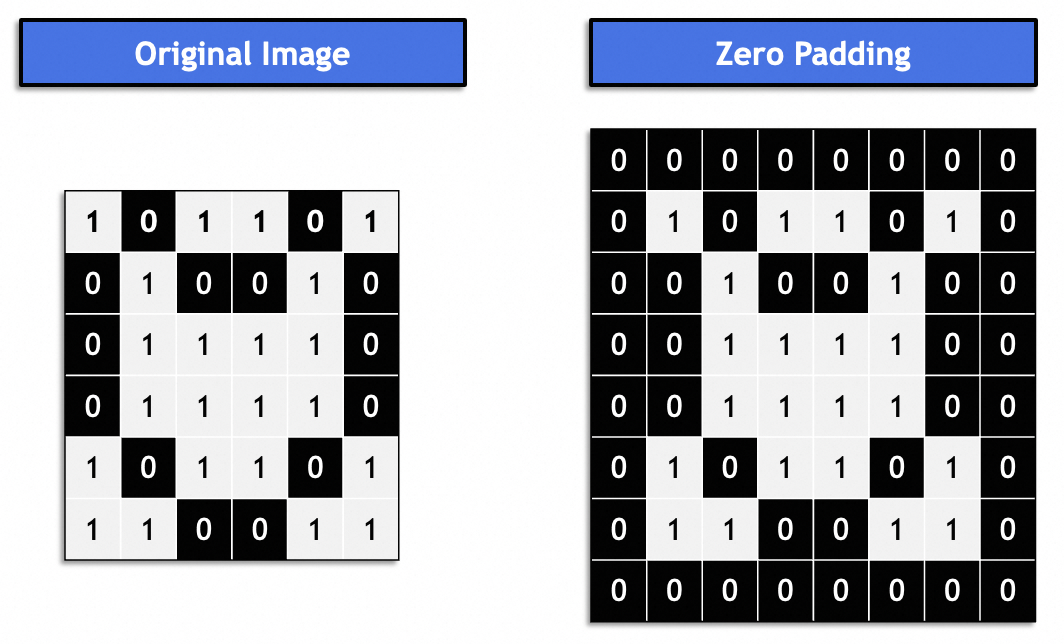
Im Allgemeinen handelt es sich um eine „gleiche Auffüllung“, und das resultierende Bild bleibt mit dem Originalbild konsistent. Normalerweise mit 0 gefüllt.
Welches Problem werden also durch Faltungskerne oder Filter gelöst? Wir können uns die folgenden Faltungskerne ansehen. Sie verwenden bestimmte Vektorwerte, um die vertikalen und horizontalen Kanten im Originalbild zu verbessern. Wie in der Abbildung gezeigt, kann der Faltungskern tatsächlich zum Extrahieren von Merkmalen aus dem Originalbild verwendet werden:

Wie werden schließlich Filter in Grafiken auf neuronale Netze angewendet?
Zunächst werden der Faltungskernvektor und der ursprüngliche Bildvektor multipliziert und summiert (reaktiviert), was den Neuronenparametern und der Eingabe ähnelt, die multipliziert, summiert und reaktiviert werden. Der Faltungskern kann durch Neuronen im neuronalen Netzwerk ausgedrückt werden.
Zweitens sind die Vektorwerte des Faltungskerns im Gegensatz zu den oben angegebenen bekannten Vektorwerten der Unschärfe-, Schärfungs- und horizontalen und vertikalen Kantenfilter trainierbar und werden zur dynamischen Erfassung von Eingabemerkmalen und Neuronenparametern verwendet. Die Verwendung ist konsistent.
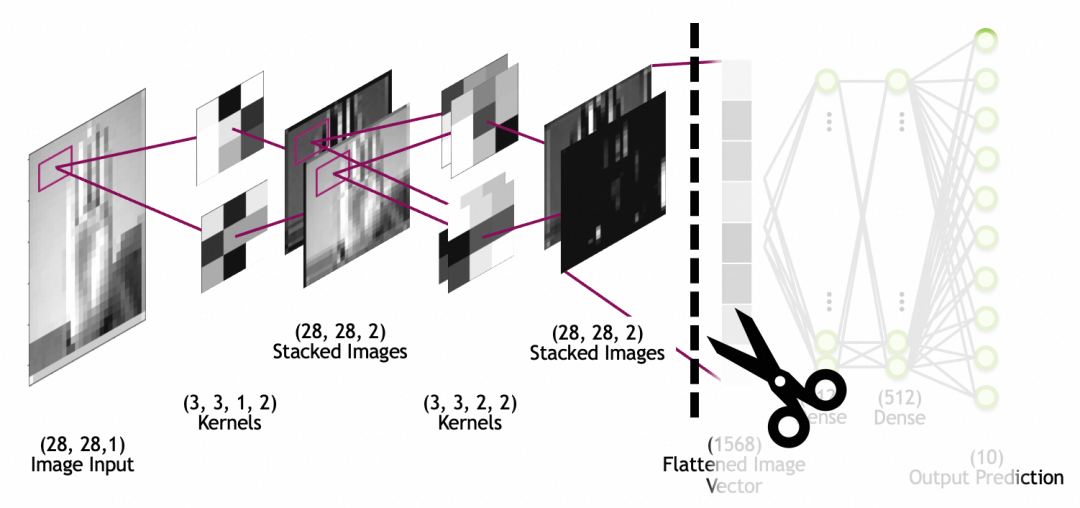
Tatsächlich ist ein Faltungskern ein Neuron in der Faltungsschicht. Ähnlich wie bei den vollständig verbundenen Schichtneuronen sind seine Parameter auch Eingabegewichte + Bias-Konstanten, wobei die Anzahl der Eingabegewichte gleich der Anzahl der Eingaben ist. Da es sich bei den Eingabebildern um gestapelte Bilder handelt, beträgt die Anzahl der Eingabegewichte x * y * ndie Bias-Konstante ist auf 1 festgelegt und es gibt x * y * n + 1insgesamt 1. Wie im Bild dieses 2-Stack-3x3-Kernels gezeigt, beträgt die Anzahl der Parameter 3 * 3 * 2 + 1 = 19.
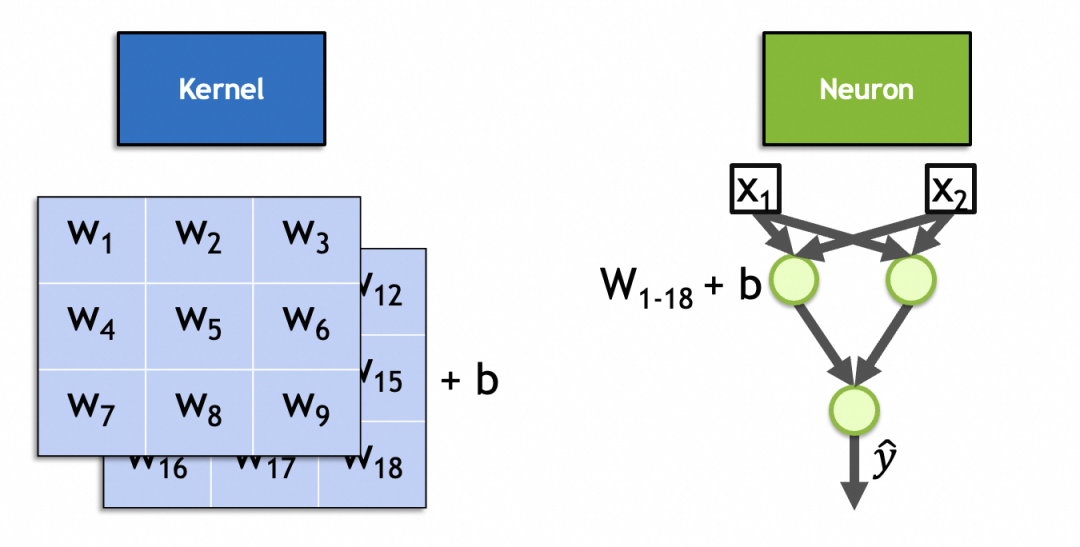
▐Berechnungsprozess für Faltungs-Neuronale Netze
Die Berechnung des Faltungs-Neuronalen Netzwerks ist dieselbe wie beim vorherigen Neuronalen Netzwerk, Vorwärtsausbreitung und Rückausbreitung, die nicht im Detail beschrieben werden.
Im Bild unten ist die Bildeingabe das Eingabebild, 28x28-Größe, 1 Stapel (1 Graustufenschicht); beachten Sie, dass gestapelte Bilder keine Netzwerkschichten sind, sondern die Ausgabe der letzten Faltungsschicht Bildbilder, die durch die Abflachungsschicht zu einem eindimensionalen Array (abgeflachter Bildvektor in der Abbildung) abgeflacht werden, um vom nachfolgenden vollständig verbundenen Schichtnetzwerk verwendet zu werden (die vollständig verbundene Schicht wurde oben besprochen).
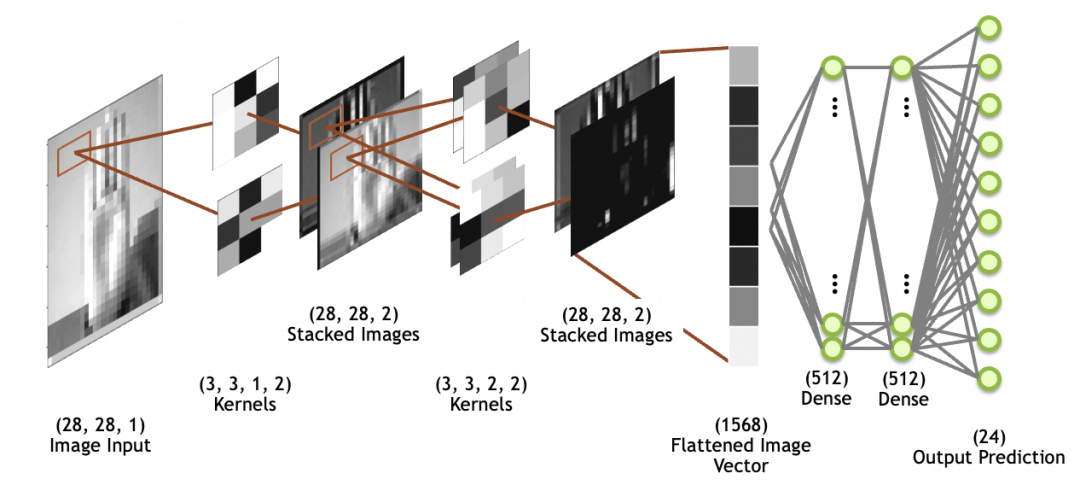
Faltung
Beachten Sie, dass im Gegensatz zur vorherigen vollständig verbundenen (dichten) Neuronenausgabe, bei der es sich um einen numerischen Wert handelt, das Faltungskernneuron jedes Mal multipliziert und aktiviert wird, um eine Zahl zu erhalten. Durch Kombinieren der beiden Richtungen und kontinuierliches Gleiten kann schließlich eine zweidimensionale Karte erstellt werden erhalten werden.
输入是
x * y * N
的堆叠图像。其中,x=28,y=28(
28 * 28 * N
)。卷积层每个神经元因为要和输入相乘,所以也是N叠,假设神经元采用
3 * 3
大小,则每个神经元是
3 * 3 * N
。输出经过padding,每叠大小和输入保持一致,
28 * 28
。输出堆叠图像的每一叠为输入堆叠图像x单个神经元的结果,所以叠数和卷积层神经元个数一致。假设卷积层有M个神经元,则输出堆叠图像为
28 * 28 * M
。这里强调一下,卷积层每个神经元的叠数=输入图像的叠数。输出图像的叠数=卷积层神经元的个数。
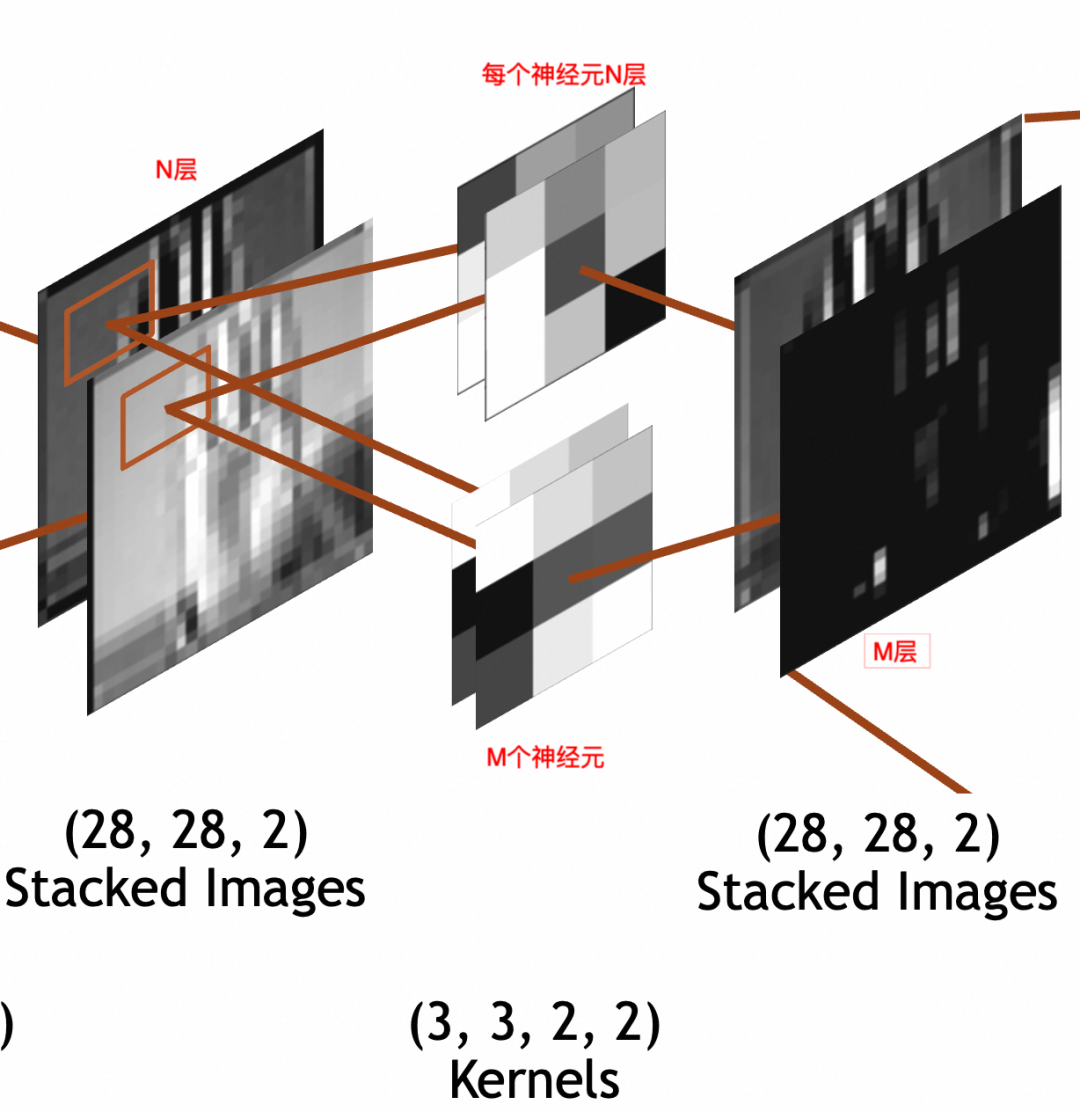
3 * 3 * N
的卷积核,每次要和N叠输入图像的
3 * 3
部分相乘,所以权重参数(weights)个数为
3 * 3 * N
,此外还通过一个偏置(bias)整体左右移。所以总参数个数为
3 * 3 * N + 1
,激活结果计算公式还是和上文普通神经元一样
output = activation_function(W * X + b)
。
为了神经网络整体处理方便,网络的输入图像、中间的堆叠图像都被统一成了 x * y * Z三维数组结构,但是两者关于叠/层的语义是不同的。输入图像的语义是图像的图层,不管是灰阶图像的1层,RGB的3层,还是RGBA的4层,是有现实关联性的。堆叠图像的各层分别是输入图像和单个神经元计算的结果,是一个特征,相互之间没有关联性,比如一层可能是纵边特征,另一层可能是横边特征。
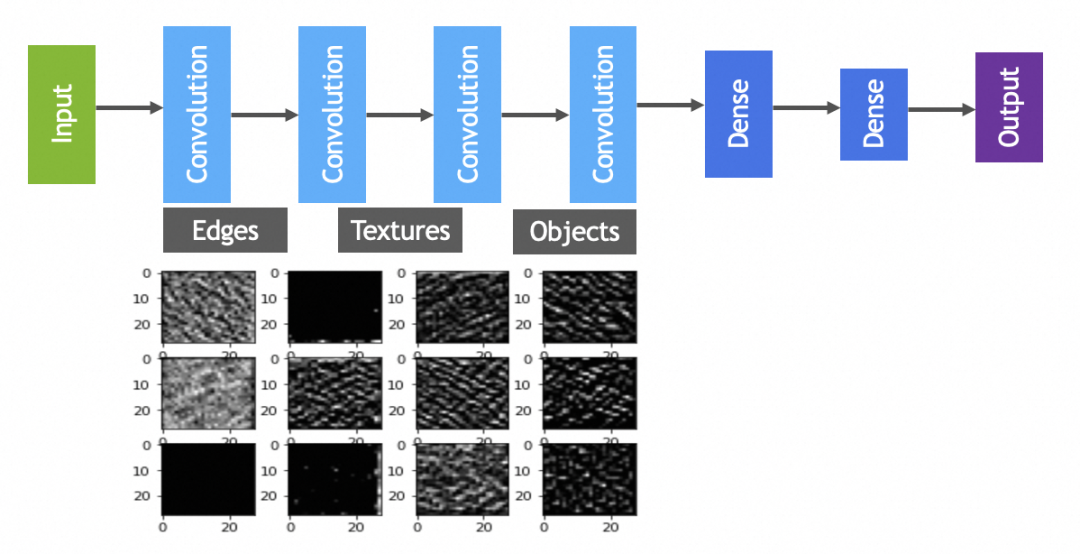
讲原理时已经提到过,一般会有多轮卷积,主要目的分别是从原图提取最小的特征,从最小特征中提取中等特征,……,如下图所示:
池化
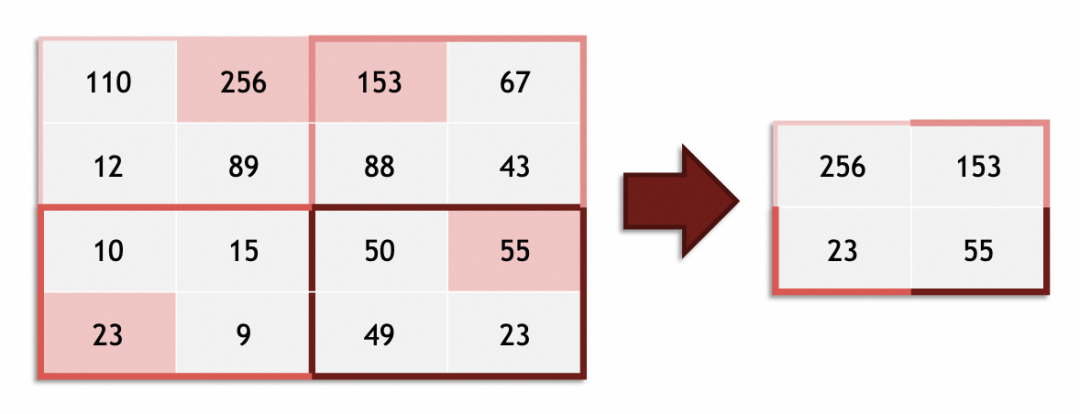
池化层的作用,主要是通过缩小图像,丢弃次要特征,保留主要特征:
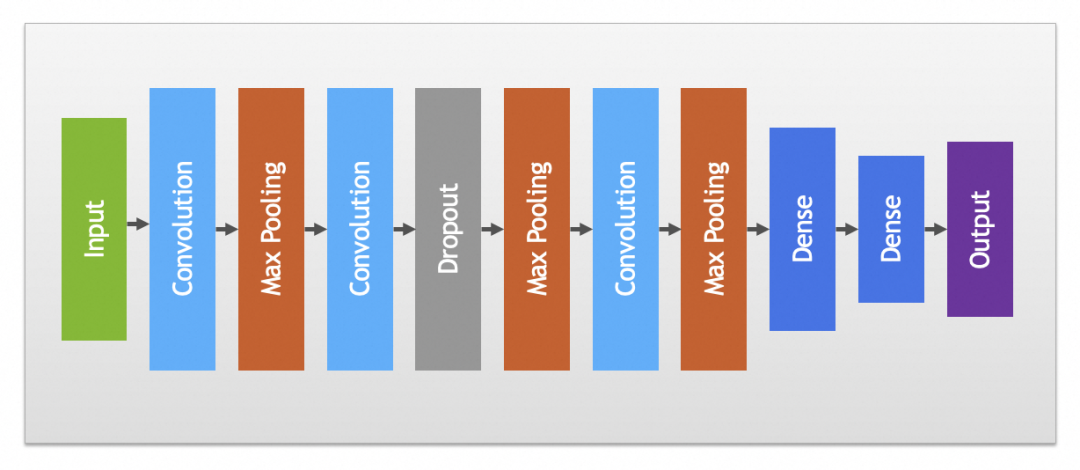
实践中卷积和池化层一般会搭配使用,完整卷积神经网络如下图:
其它
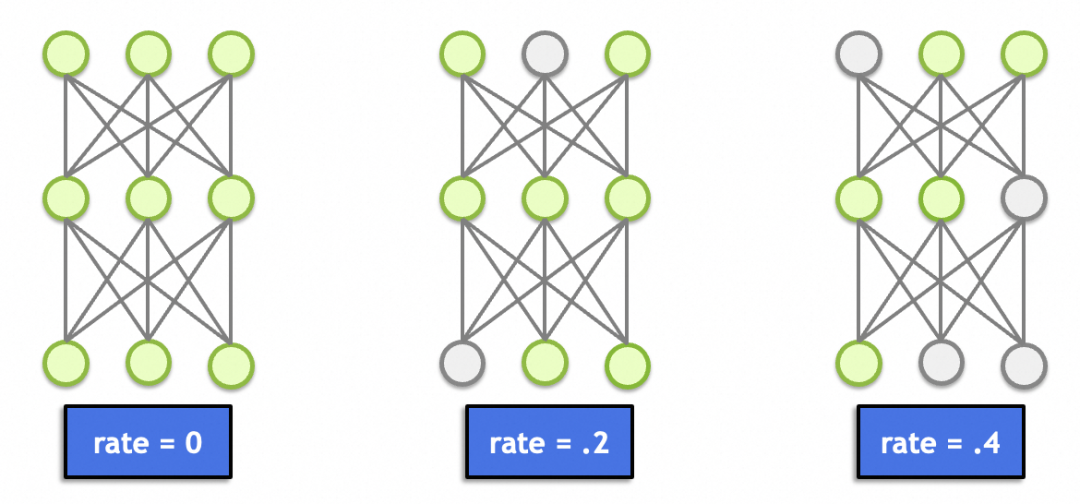
这里面还有一个丢弃层(Dropout),这个理论上跟图形学、图像处理没啥关系。主要作用是随机丢弃一定比例节点的输入(置0),避免因为节点过多(总参数过多、记忆能力太强)导致记忆效应,产生过拟合。
▐ 卷积神经网络实例讲解
本文卷积神经网络讲解的实例是对美国手语的识别,因为是手语照片,相对上文手写文字的案例来讲干扰因素过多,比如背景、衣服、掌纹等,所以采用普通神经网络过拟合比较严重。后面可以看到,改用卷积神经网络后,结果提升了不少。
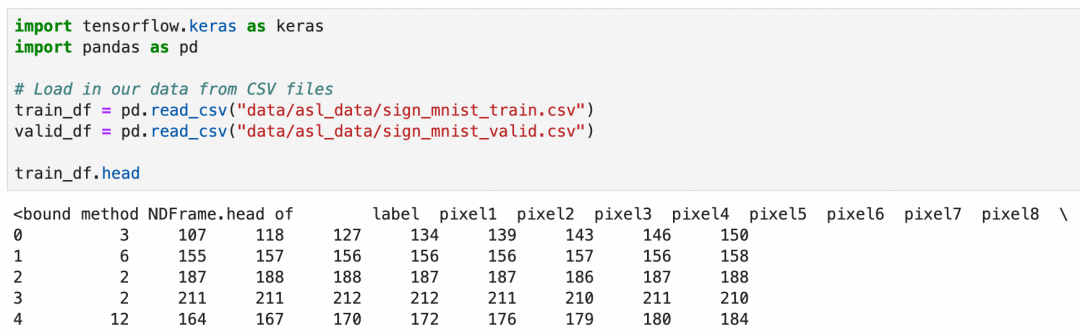
美国手语一共26个字母,其中2个字母带动作,这里只识别24个静止的字母。这次的数据集是使用csv文件存储的,可以加载后查看一下数据概貌:
csv文件一共785列,第一列是label,值是1-24,表示24种字母。第2到785列分别存放的灰阶值,值是0-255,表示从黑到白的颜色。
处理一下加载的值,将标签存入y_train和y_valid,784个像素值保留到x_train和x_valid:
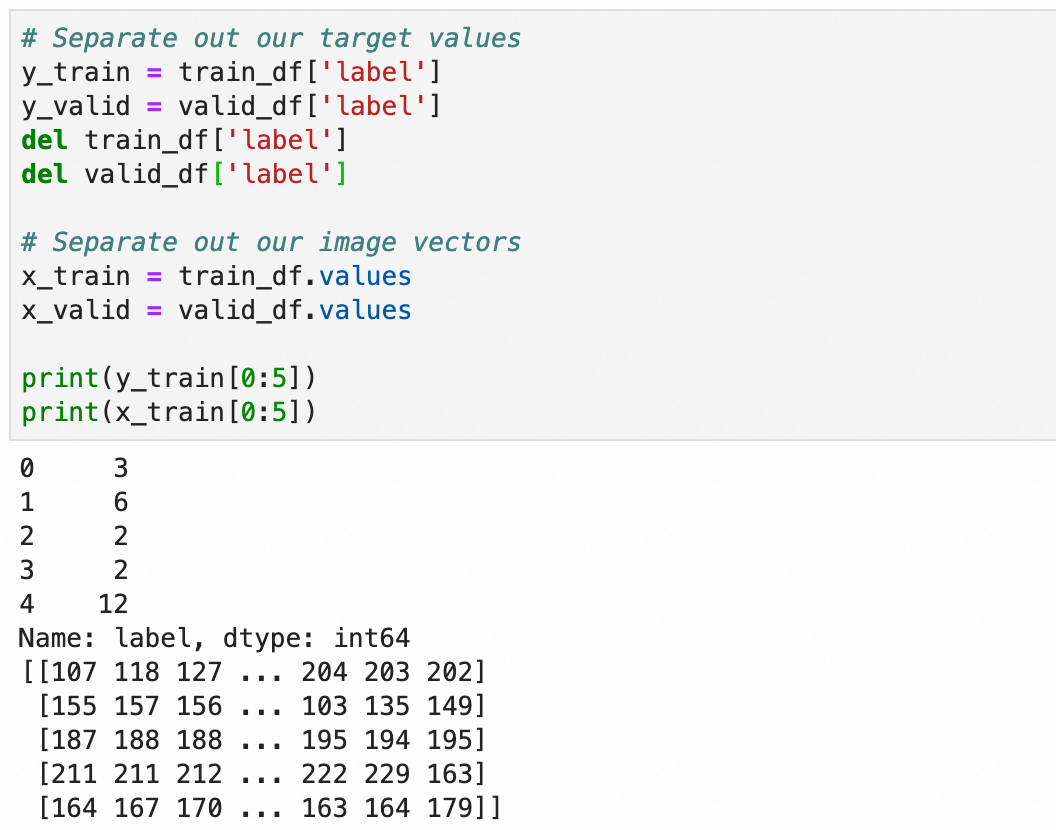
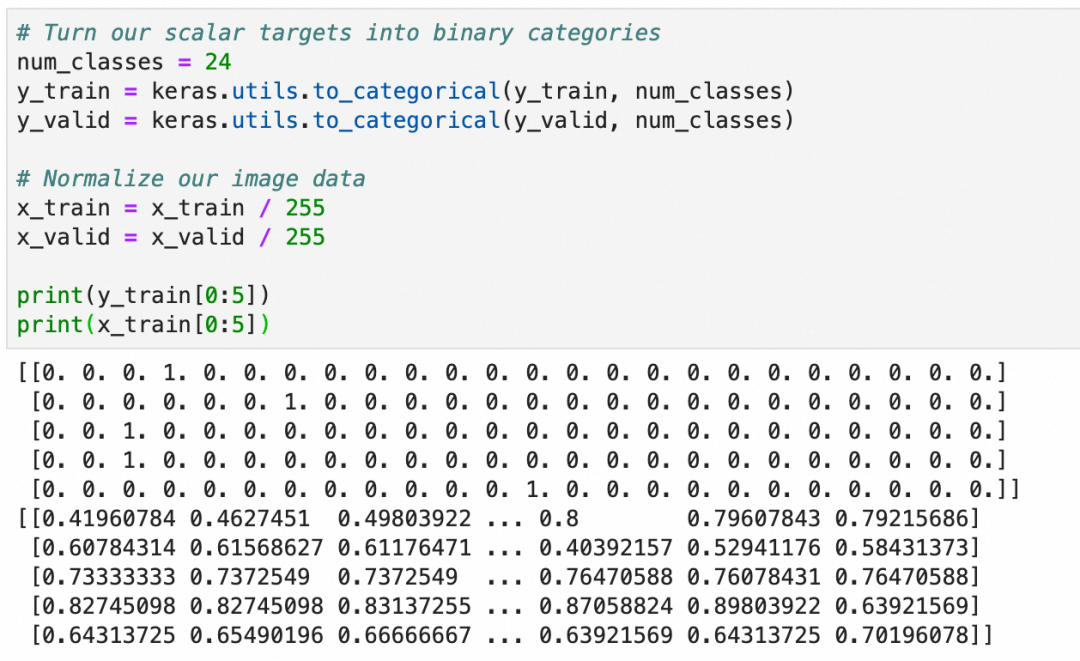
和上文一致,将y转成one-hot编码,用于分类算法,x转成0.0-1.0之间的浮点数:


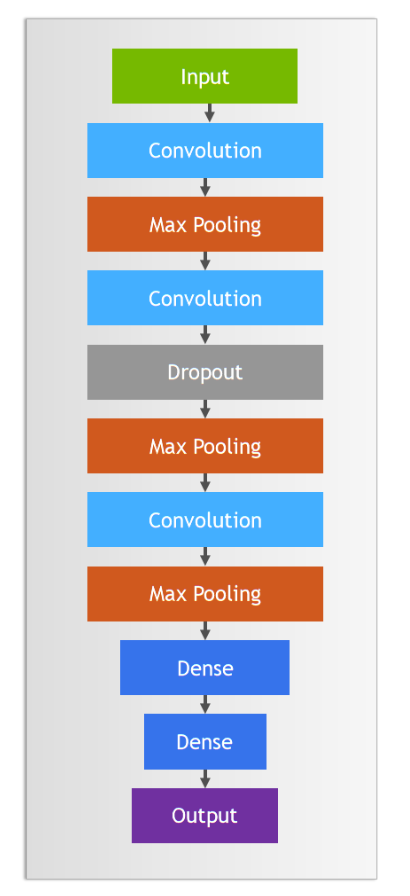
构建语句,其中:
Conv2D(75, (3, 3), stride=1, padding="same", activation="relu", input_shape=(28, 28, 1))创建一个卷积层,输入是28*28*1,75个神经元,每层大小3*3,因为输入是1层,所以每个神经元只有1层。BatchNormalization()创建一个批量标准化层,标准化上层输出平均激活值接近于0,激活值的标准差接近于1。MaxPool2D((2, 2), strides=2, padding="same")创建一个池化层,每2*2像素保留1像素,即长宽各缩小1倍。Dropout(0.2)创建一个丢弃层,丢弃20%输入。

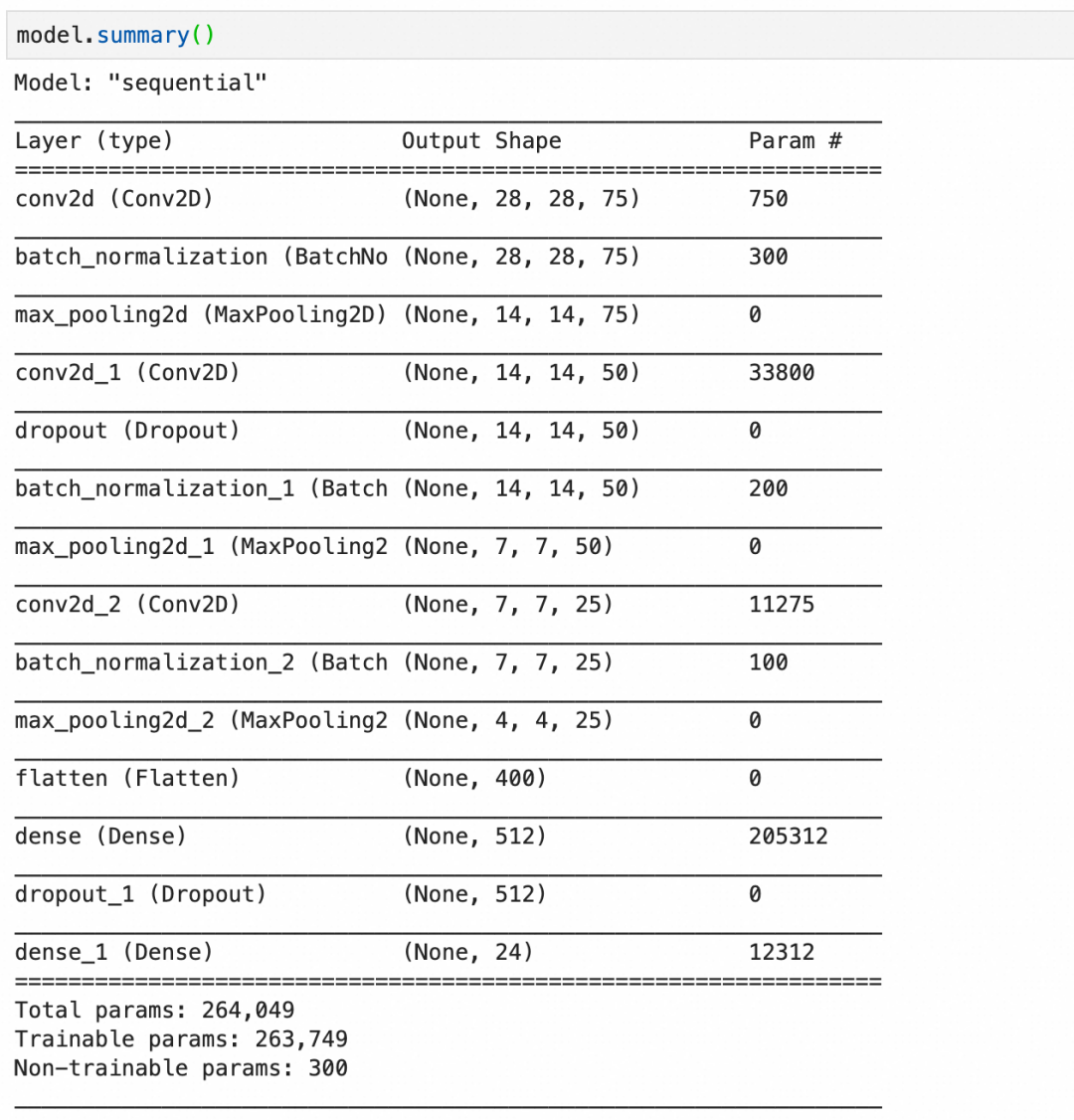
第1层,卷积层,75个神经元,每个神经元 3*3*1+1 个参数,一共750个参数。
第2层,批量标准化层,75层输入,每层4个参数,其中2个可训练参数:缩放和偏移,还有2个不可训练参数,存储本批数据的统计值。一共300个参数。
第3层,池化层,池化层都是运算,没有参数。
第4层,卷积层,50个神经元,每个神经元3*3*75+1个参数(每个神经元有75层,分别对应输入的75层),一共33800个参数。
第5层,丢弃层,丢弃层只有运算,没有参数。
第11层,flatten层,只有转化,没有参数。
最后,总的参数个数里,有300个不可训练参数,这是由3个批量标准化层的不可训练参数加在一起构成。

本卷积神经网络校验集的准确度最后能到92%左右,算是比较好的结果:
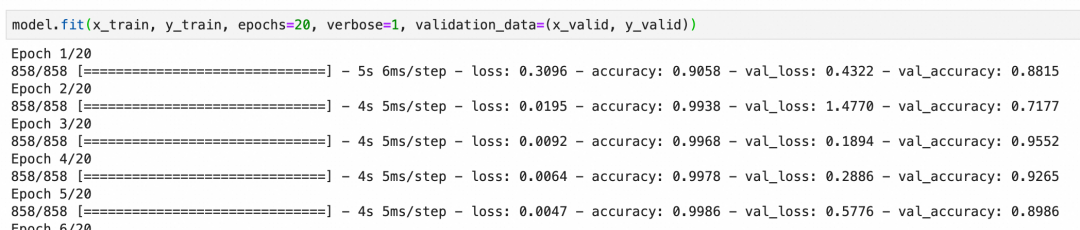

上面一章我们看了如何通过优化模型来降低过拟合,下面我们来看看如何通过数据增强来提升整体准确度。
数据增强通俗的理解就是通过丰富训练集数据、增加样本数量,减少模型对具体实例的“记忆”、增加模型抽象一般规律的能力。比如我们要训练识别狗的图片,能提供的训练样本当然是越全越好,即需要很多正例(比如金毛、边牧等不同品种的狗),也需要尽可能多的反例(比如猫、狼)。
道理很好理解,但是准备足够多样的训练样本是一件很费事的事情。数据增强是深度学习框架提供的一套工具,通过对现有训练集进行细微变化,比如(适度的)缩放、旋转、位移等等,来批量生产新的训练样本。
需要注意的是,需要根据数据集的特征来决定要进行怎样的变化,比如上一章的手语图片,样本是可以左右翻转的,因为左撇子的手势刚好左右翻转,但是垂直翻转则没有意义;同理,上文中的手写数字,则既不能垂直翻转,也不能左右翻转。
另外,样本的变化也要注意范围,因为网络接收的图片尺寸从一开始就是确定的,这些变化不会改变接收图片的尺寸。比如图片放大缩小,超出图片大小的部分会被裁剪,缺失的部分会被填充。所以,需要考虑变化后的图片是否还有意义,比如手语图片过分放大,放大到只剩一根手指,细节部分是清晰了,但是整体已经完全看不出所代表的手语字母了。
本章不涉及原理,因为这符合人们的一般理解。重点讲一下数据增强的过程:
第1步,还是上一章所用的训练集和模型不变。
train_df = pd.read_csv(...)...model = Sequential()model.add(...)...model.compile(...)
第2步,准备数据增强用的图像数据生成器:随机旋转10度、缩放10%、左右上下位移10%以内,随机水平翻转,但不垂直翻转。
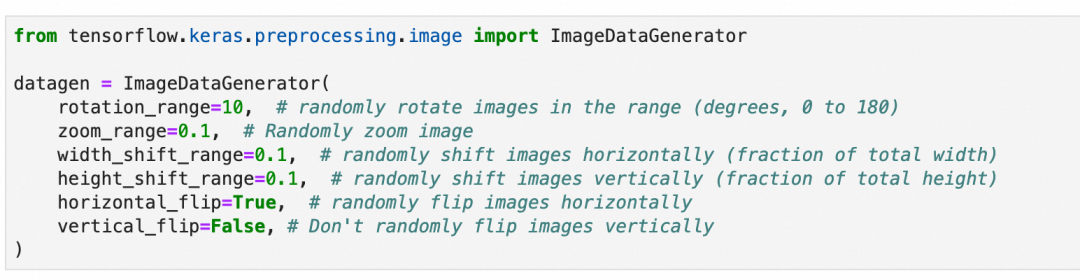
第3步,设置分批生成数据的大小:设置每批生成32张图片。

上面得到的是一个生成数据的迭代器,可以可视化一下第一批数据的样子:
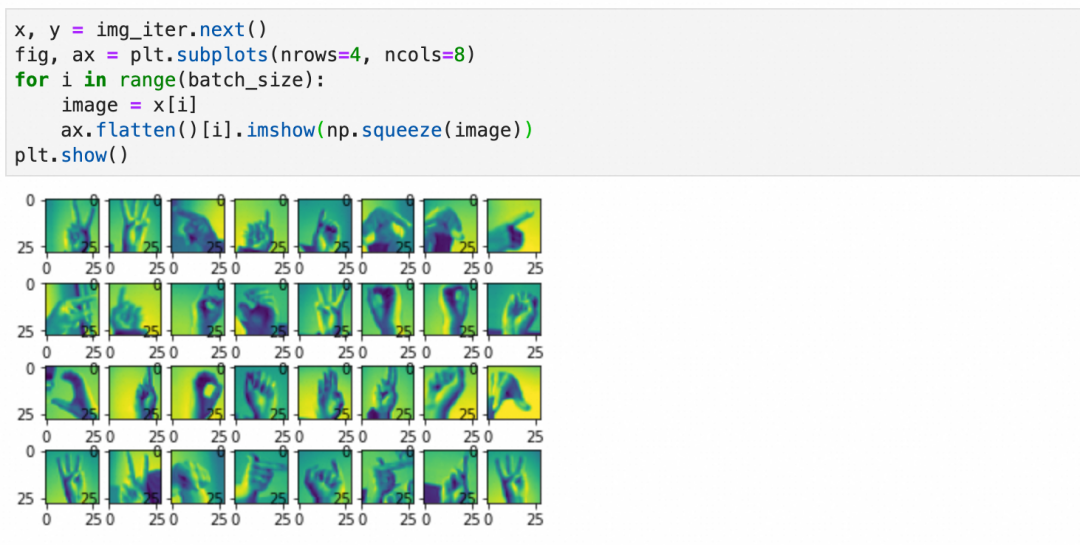
对训练样本的变化除了上面提到的旋转、缩放、位移等,还有基于原训练样本统计值的变化(本案例没用到)。
这一步是统计整个原训练样本,并记录必要的统计信息到数据生成器。

第5步,用数据生成器进行训练:
和上一章案例直接使用原始样本不同model.fit(x_train, y_train, epochs=20, verbose=1, validation_data=(x_valid, y_valid))。这里使用数据生成器生成的内容。
还是20个周期,但是每个周期里训练的样本数等于steps_per_epoch * batch_size,基于丰富度和训练时长兼顾考虑,这里采用steps_per_epoch=len(x_train)/batch_size,每周期样本数和原训练集差不多(但是都是经过数据生成器,随机变化过后的新样本)。
最后结果可以看出,准确度很快就上去了,数据增强有非常明显的效果。


▐ 迁移学习
迁移学习就是通过将已经训练好的模型的一部分摘出来,重新和其它网络层组成新的网络,从而复用网络能力和提升网络效果的过程。
比如,我们可以拿google已经训练好的,进行动物分类的模型,拿来识别自家的猫主子,做一个自动猫门。
为什么要这么做?简单的说就是你自己的训练集不够,你给自家猫拍一千张照片来从头训练一个模型,也可能把外面的流浪猫放进来,因为你缺少足够的正负样本。
因为篇幅原因,这里不详细展开,只讲一下关键步骤。细节可以参考Transfer learning and fine-tuning官方教程:
第1步,摘取预训练模型的前半段(卷积层+池化层),去掉后半部分(include_top=False)。
第2步,拼接模型的后半段为新的、未经训练的全连接层。
第3步,设置前半部分参数不动(trainable=False),拿新的正负样本训练模型的后半段。
你会发现,有了预训练模型的前半段,很快就可以取得不错的结果。
这里我们也可以得出结论,网络前半段的参数,包含了比较通用的特征,比如一般的猫狗,网络后半段则包含了比较具体的特征,比如你家的猫主子。
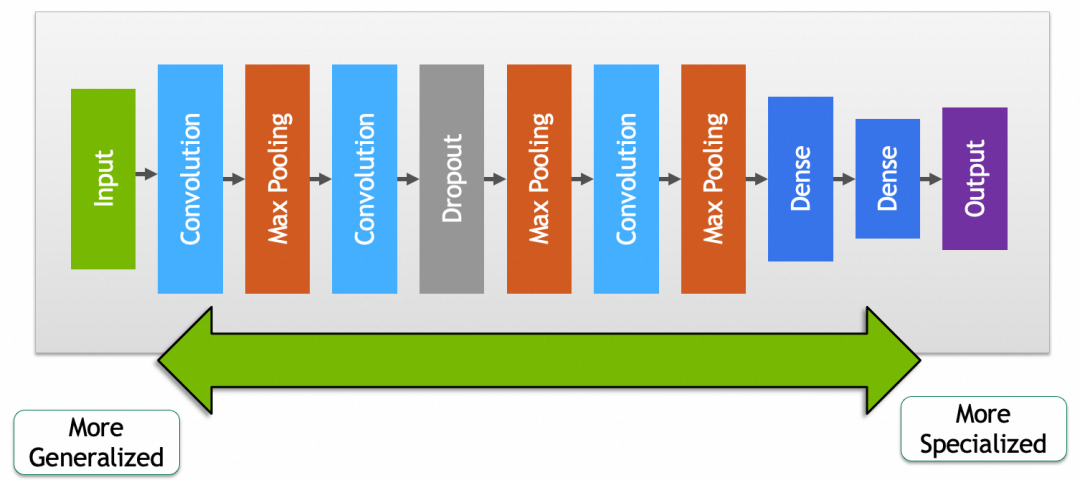
▐ 微调
如果复用网络后,发现效果没有特别满意,可能是因为预训练模型和你要求解的问题没有完全匹配,或者现有模型参数里缺少一些针对性的特征。微调就是通过稍微调整一下预训练模型部分的参数,提升被复用网络效果的过程。
微调的过程很简单,前面3步保持不变,增加下面的步骤:
第4步,设置前半部分参数可训练(trainable=True),同时设置训练步长为一个非常小的值。
第5步,继续训练几个周期,这样整个网络的参数,包括预训练的前半段,和你新加入的后半段,都会按新的数据进行调整,针对特定问题的结果也会更好。
这里要注意两点:
第4步训练步长一定要小,这样每次参数的变化非常小,尽可能的保持预训练模型中的参数(一般特征)。
第3步一定要训练完成,即后半部分已经基于新数据训练过。否则,如果后半部分参数很随机,反向传播时,就算训练步长非常小,前半部分的参数也会发生非常大的波动,导致模型的基础特征被破坏。

高级神经网络不仅包括卷积神经网络,还涵盖了循环神经网络。卷积神经网络主要应用于图像识别的领域,而循环神经网络则广泛用于处理自然语言。随着Transformer模型的出现,自然语言处理的技术有了新的发展。关于自然语言处理的更多细节,将在后续关于Transformer原理的文章中详细介绍,故在此不作过多阐述。
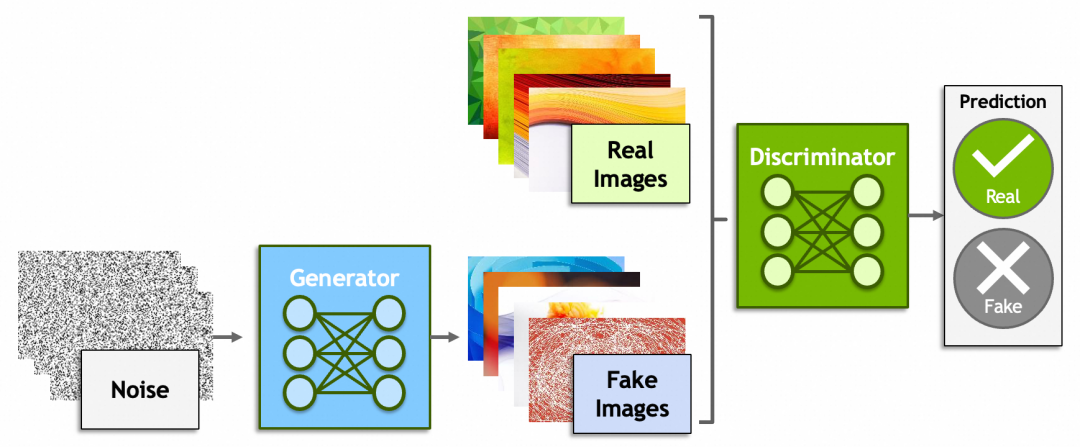
除了神经网络,深度学习里还有一些概念比较有意思,比如生成式对抗网络(Generative Adversarial Networks)、强化学习(Reinforcement Learning)。
生成式对抗网络一方是生成器(Generator)从一堆噪音里生成出假的图片,企图骗过鉴别器(Discriminator);而另一方鉴别器则尽可能的识别出真假图片。原理上还是脱离不了之前讲过的内容,鉴别器会给出一个分数,生成器会根据这个分数反向传播,修改由噪音生成图片的参数。
还记得“前GPT时代”,2022年Google研究员Blake Lemoine爆料AI有自我意识,被公司开除的新闻吗[捂脸哭]?谁说ChatGPT、MidJourney、Sora不是一些骗过了研究员、非常成功的生成式对抗网络呢?然而另一方面,就像【中文房间】描述的问题一样,哪里才是生成式对抗和真正理解的边界?大模型究竟能不能走向通用人工智能?
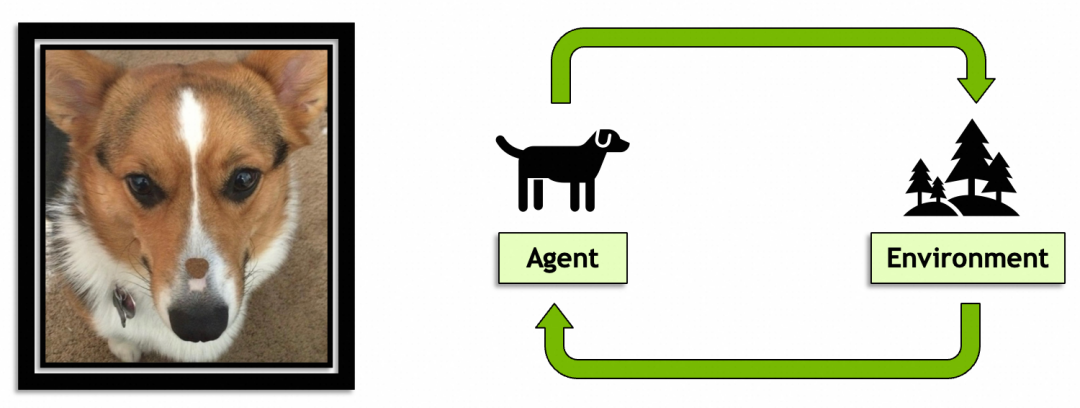
后一个概念,强化学习就是AI从环境中学习的过程和能力,目前机器人领域用得比较多。个人认为这个概念有意思是因为它是通向通用人工智能的必经之路,预计未来会扮演比较重要的角色。
本系列头两篇文章到这里就结束了,希望能激起大家学习AI原理的好奇心和勇气。个人水平有限,如果文章有什么问题,欢迎留言探讨。

团队介绍
天猫国际是中国领先的进口电商平台, 也是阿里巴巴-淘天集团电商技术体系中链路最完整且最为复杂的技术产品之一,也是淘天集团拥有最完整业务形态(平台+直营、跨境、大贸、免税等多业务模式)的业务。在这里我们参与到阿里电商体系的绝大部分核心系统(导购、商家、商品、交易、营销、履约等),同时借助区块链、大数据、AI算法等前沿技术助力业务高速增长。作为贴近业务前沿的技术团队,我们对于电商行业特性、跨境市场研究、未来交易趋势以及未来技术布局等都有着深度的理解。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。