

Autor dieses Artikels:
Tarik Bennett, Beinan Wang, Hope Wang
In diesem Artikel werden die Herausforderungen beim Datenzugriff in der künstlichen Intelligenz (KI) erörtert und aufgezeigt, dass „häufig verwendete NAS/NFS möglicherweise nicht die beste Wahl sind “ .
1. Frühe Architektur für künstliche Intelligenz/maschinelles Lernen
Untersuchungen von Gartner zeigen, dass große Sprachmodelle (LLM) zwar große Aufmerksamkeit erregt haben, die meisten Organisationen sich jedoch noch im Anfangsstadium der Verwendung großer Modelle befinden und nur einige in die Produktionsphase eingetreten sind.
Der Schwerpunkt beim Aufbau einer KI-Plattform liegt in der Anfangsphase darauf, das System zum Laufen zu bringen, damit Projektpiloten und Proof-of-Concepts durchgeführt werden können. Diese frühen Architekturen oder Vorproduktionsarchitekturen sind darauf ausgelegt, die grundlegenden Anforderungen der Modellschulung und -bereitstellung zu erfüllen. Derzeit nutzen viele Unternehmen diese Art der frühen KI-Architektur bereits für Produktionsumgebungen.
Wenn Daten und Modelle wachsen, werden solche frühen KI-Architekturen oft ineffizient. Unternehmen trainieren Modelle in der Cloud, und mit der Ausweitung der Projekte wird erwartet, dass ihre Daten- und Cloud-Nutzung innerhalb von 12 Monaten erheblich zunehmen wird. Viele Unternehmen beginnen mit Datenmengen, die ihrer aktuellen Speichergröße entsprechen, sind sich jedoch der Notwendigkeit bewusst, sich auf größere Belastungen vorzubereiten.
Unternehmen können sich für die Nutzung eines vorhandenen Technologie-Stacks oder für die Bereitstellung auf der grünen Wiese entscheiden. Dieser Artikel konzentriert sich darauf, wie Sie Ihren vorhandenen Technologie-Stack nutzen oder zusätzliche Hardware kaufen, um einen skalierbareren, agileren und leistungsfähigeren Technologie-Stack zu entwerfen.
2. Herausforderungen beim Datenzugriff
Mit der Weiterentwicklung der KI/ML-Architektur nimmt die Größe der Modelltrainingsdatensätze weiterhin deutlich zu, und auch die Rechenleistung und der Umfang der GPUs nehmen rapide zu. Neben Computer, Speicher und Netzwerk glauben wir, dass der Datenzugriff ein weiteres Schlüsselelement beim Aufbau einer zukunftsweisenden KI-Plattform ist .

Datenzugriff bezieht sich auf Technologien wie Datendienste, Backup-Speicher (NFS, NAS) und Hochleistungs-Cache (wie Alluxio), die der Rechenmaschine helfen, Daten für das Modelltraining und die Bereitstellung zu erhalten.
Der Schwerpunkt des Datenzugriffs liegt auf dem Durchsatz und der Effizienz des Datenladens, was für KI/ML-Architekturen mit knappen GPU-Ressourcen immer wichtiger wird. Durch die Optimierung des Datenladens kann die Wartezeit im Leerlauf der GPU erheblich verkürzt und die GPU-Auslastung verbessert werden. Daher sollte ein leistungsstarker Datenzugriff das Hauptziel der Architekturbereitstellung sein.
Da Unternehmen ihre Modellschulungsaufgaben auf frühe KI-Architekturen ausweiten, sind einige häufige Herausforderungen beim Datenzugriff aufgetreten:
1
Die Effizienz des Modelltrainings ist geringer als erwartet: Aufgrund von Datenzugriffsengpässen ist die Trainingszeit länger als auf Basis der Rechenressourcen geschätzt. Datenströme mit geringem Durchsatz stellen der GPU nicht genügend Daten zur Verfügung.
2
Engpässe im Zusammenhang mit der Datensynchronisierung: Das manuelle Kopieren oder Synchronisieren von Daten vom Speicher auf einen lokalen GPU-Server führt zu Verzögerungen beim Aufbau der vorzubereitenden Datenwarteschlange.
3
Parallelitäts- und Metadatenprobleme: Wenn große Jobs parallel gestartet werden, kann es zu Konflikten im gemeinsam genutzten Speicher kommen. Die Latenz erhöht sich, wenn Metadatenvorgänge im Backend-Speicher langsam sind.
4
Geringe Leistung oder geringe GPU-Auslastung: Eine Hochleistungs-GPU-Infrastruktur erfordert enorme Investitionen, und sobald der Datenzugriff ineffizient ist, führt dies zu ungenutzten und nicht ausreichend genutzten GPU-Ressourcen.
Darüber hinaus werden diese Herausforderungen durch eine Vielzahl anderer Probleme verschärft, die Datenteams bewältigen müssen. Zu diesen Problemen gehören langsame Speicher-E/A-Geschwindigkeiten, die den Anforderungen leistungsstarker GPU-Cluster nicht gerecht werden. Das manuelle Kopieren und Synchronisieren von Daten erhöht die Latenz, während das Datenteam auf die Übermittlung der Daten an den GPU-Server wartet. Die Herausforderung beim Datenzugriff wird auch durch die architektonische Komplexität mehrerer Datensilos in hybriden Infrastrukturen oder Multi-Cloud-Umgebungen verschärft.
Diese Probleme führen letztendlich dazu, dass die Gesamteffizienz der Architektur hinter den Erwartungen zurückbleibt.
Für Herausforderungen im Zusammenhang mit dem Datenzugriff gibt es oft zwei gemeinsame Lösungen.
Erwerben Sie schnelleren Speicher: Viele Unternehmen versuchen, das Problem des langsamen Datenzugriffs durch den Einsatz schnellerer Speicheroptionen zu lösen. Cloud-Anbieter bieten Hochleistungsspeicher an, während professionelle Hardwareanbieter HPC-Speicher verkaufen, um die Leistung zu verbessern.
Fügen Sie NAS/NFS zusätzlich zum Objektspeicher hinzu: Das Hinzufügen zentraler NAS oder NFS als Backup zu Objektspeichern wie S3, MinIO oder Ceph ist eine gängige Praxis und hilft Teams, Daten in gemeinsam genutzten Dateisystemen zu konsolidieren, was die Zusammenarbeit und gemeinsame Nutzung von Benutzern und Arbeitslasten vereinfacht. Darüber hinaus können Sie auch die Vorteile verwandter Datenverwaltungsfunktionen wie Datenkonsistenz, Verfügbarkeit, Sicherung und Skalierbarkeit nutzen, die von etablierten NAS-Anbietern bereitgestellt werden.
Allerdings lösen diese beiden oben genannten allgemeinen Lösungen Ihr Problem möglicherweise nicht wirklich.
Obwohl durch schnelleren Speicher und zentralisiertes NFS/NAS nach und nach einige Leistungsverbesserungen erzielt werden können, gibt es auch Nachteile.
1
Eine schnellere Speicherung bedeutet eine Datenmigration, die leicht zu Problemen mit der Datenzuverlässigkeit führen kann
Um die hohe Leistung des dedizierten Speichers nutzen zu können, müssen Daten vom vorhandenen Speicher auf eine neue Hochleistungsspeicherebene migriert werden. Dies führt dazu, dass die Daten im Hintergrund migriert werden. Die Migration großer Datensätze kann zu längeren Übertragungszeiten und Problemen mit der Datenzuverlässigkeit wie Datenbeschädigung oder Datenverlust während der Migration führen. Während das Team auf den Abschluss der Datensynchronisierung wartet, kann eine Unterbrechung des Betriebs den Dienst unterbrechen und den Projektfortschritt verlangsamen.
2
NFS/NAS: Wartung und Engpässe
Da es sich um eine zusätzliche Speicherschicht handelt, bestehen weiterhin Herausforderungen bei der Wartung, Stabilität und Skalierbarkeit von NFS/NAS. Das manuelle Kopieren von Daten von NFS/NAS auf einen lokalen GPU-Server erhöht die Latenz und verschwendet Ressourcen, die durch wiederholte Sicherungen verursacht werden. Ein durch parallele Jobs verursachter Anstieg der Lesenachfrage kann zu Clustern von NFS/NAS-Servern und miteinander verbundenen Diensten führen. Darüber hinaus bestehen weiterhin Probleme bei der Datensynchronisierung in Remote-NFS/NAS-GPU-Clustern.
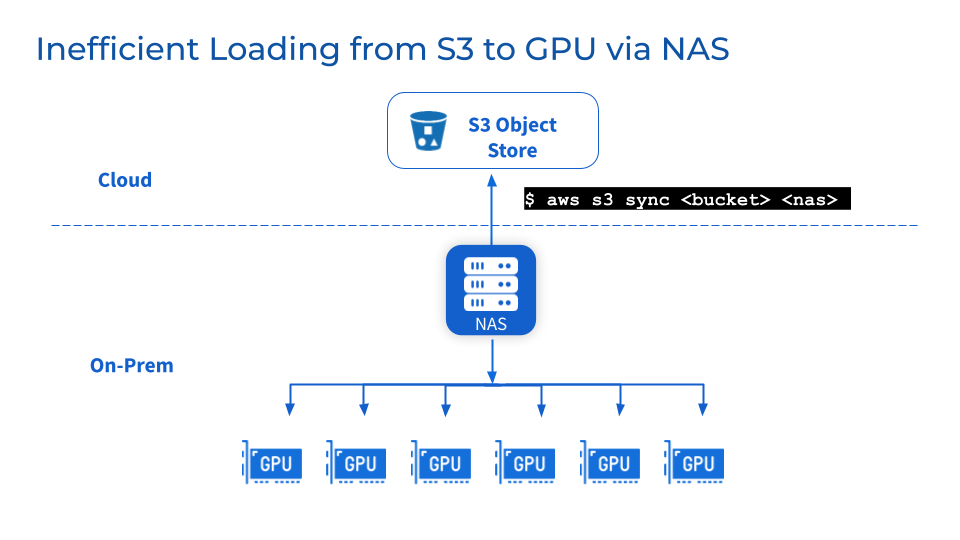
3
Was passiert, wenn ich aus geschäftlichen Gründen den Lieferanten wechseln muss?
Unternehmen können aus Kostenoptimierungs- oder Vertragsgründen den Lieferanten wechseln. Die Flexibilität von Multi-Cloud-Umgebungen erfordert die Möglichkeit, große Datenmengen problemlos zu portieren, ohne an einen Anbieter gebunden zu sein. Allerdings kann die Verlagerung von Datenspeichern im Petabyte-Bereich zu erheblichen Ausfallzeiten und Störungen bei der Modellentwicklung führen.
Kurz gesagt: Bestehende Lösungen sind zwar kurzfristig hilfreich, können jedoch keine skalierbare und optimierte Datenzugriffsarchitektur bieten, um dem exponentiellen Wachstum des Datenbedarfs von KI/ML gerecht zu werden.
3. Von Alluxio bereitgestellte Lösungen
Alluxio kann zwischen Rechen- und Datenquellen eingesetzt werden. Stellen Sie Datenabstraktion und verteiltes Caching bereit, um die Leistung und Skalierbarkeit der KI/ML-Architektur zu verbessern.
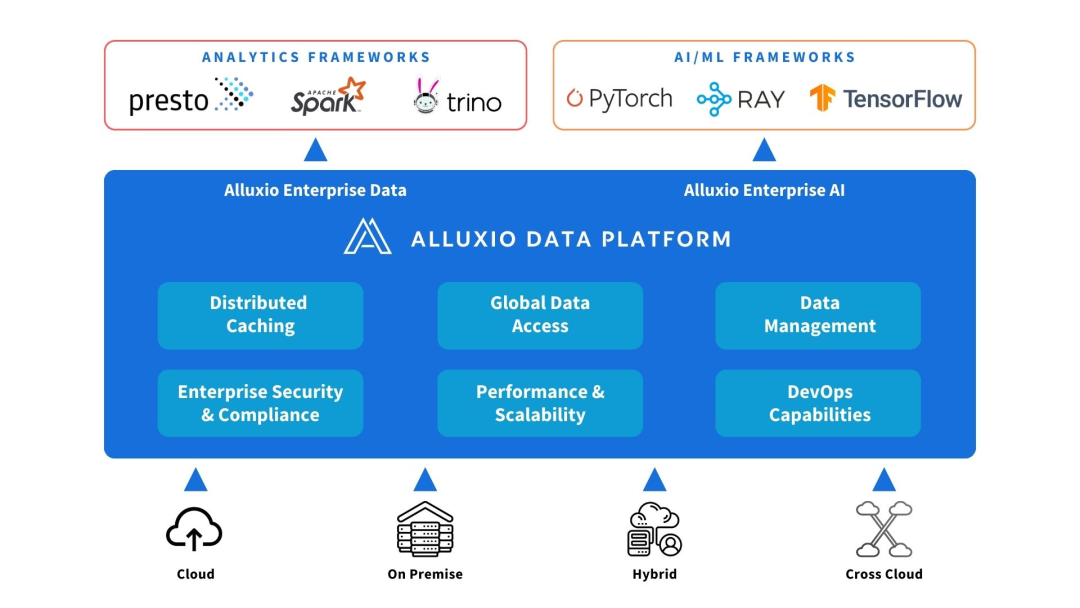
Alluxio hilft bei der Lösung der Herausforderungen, denen sich frühe KI-Architekturen in Bezug auf Skalierbarkeit, Leistung und Datenverwaltung gegenübersehen, wenn die Datenmenge, die Modellkomplexität zunimmt und GPU-Cluster größer werden.
1
Kapazität erhöhen
Alluxio lässt sich über die Grenzen eines einzelnen Knotens hinaus skalieren, um größere Trainingsdatensätze zu verarbeiten, als Clusterspeicher oder lokale SSDs aufnehmen können. Es verbindet verschiedene Speichersysteme und bietet eine einheitliche Datenzugriffsebene zum Aufbau von Data Lakes im Petabyte-Bereich. Alluxio speichert häufig verwendete Dateien und Metadaten auf intelligente Weise in Speicher- und SSD-Ebenen nahe der Recheneinheit zwischen, sodass nicht der gesamte Datensatz kopiert werden muss.
2
Reduzieren Sie die Datenverwaltung
Alluxio vereinfacht die Datenbewegung und -speicherung zwischen GPU-Clustern durch automatisiertes verteiltes Caching. Datenteams müssen Daten nicht manuell in lokale Staging-Dateien kopieren oder synchronisieren. Der Alluxio-Cluster kann automatisch heiße Dateien oder Objekte an einem Ort in der Nähe des Rechenknotens erfassen, ohne komplexe Workflow-Vorgänge durchführen zu müssen. Alluxio vereinfacht Arbeitsabläufe selbst bei 50 Millionen oder mehr Objekten pro Knoten.
3
Leistung verbessern
Alluxio wurde entwickelt, um Arbeitslasten zu beschleunigen und die I/O-Engpässe im herkömmlichen Speicher zu beseitigen, die den GPU-Durchsatz einschränken. Verteiltes Caching erhöht die Datenzugriffsgeschwindigkeit um Größenordnungen. Im Vergleich zum Zugriff auf Remote-Speicher über das Netzwerk bietet Alluxio lokalen Datenzugriff auf Speicher- und SSD-Ebene und verbessert so die GPU-Auslastung.
Kurz gesagt, Alluxio bietet eine leistungsstarke und skalierbare Datenzugriffsschicht, die die Nutzung von GPU-Ressourcen in KI/ML-Datenerweiterungsszenarien maximieren kann.
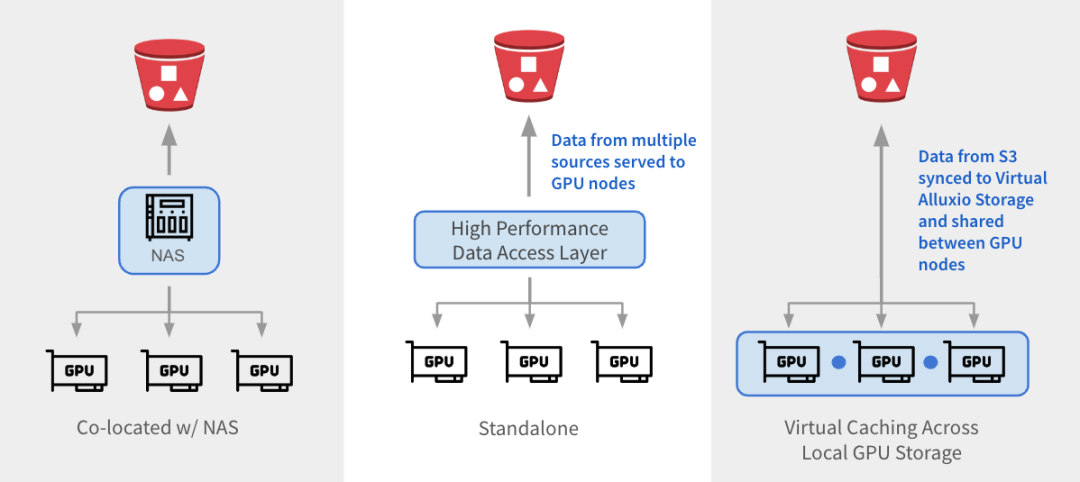
Alluxio kann auf drei Arten in bestehende Architekturen integriert werden.
1
与 NAS 并置:Alluxio 作为透明缓存层与现有 NAS并置部署,增强 I/O 性能。Alluxio将NAS中的活跃数据缓存在跨GPU节点的本地 SSD 中。作业将读取请求重新定向到Alluxio上的SSD缓存,绕过NAS,从而消除NAS瓶颈。写入操作通过 Alluxio 对 SSD 进行低延迟写入,然后异步持久化保存到 NAS中。
2
独立数据访问层:Alluxio 作为专用的高性能数据访问层,整合来自 S3、HDFS、NFS 或本地数据湖等多个数据源的数据,为GPU节点提供数据访问服务。Alluxio 将不同的数据孤岛统一在一个命名空间下,并将存储后端挂载为底层存储。经常访问的数据会被缓存在 Alluxio Worker节点的SSD中,从而加速GPU对数据的本地访问。
3
跨GPU存储的虚拟缓存:Alluxio充当跨本地GPU存储的虚拟缓存。S3中的数据会被同步到虚拟 Alluxio存储并在GPU节点之间共享,无需在节点之间手动拷贝数据。
1
参考架构
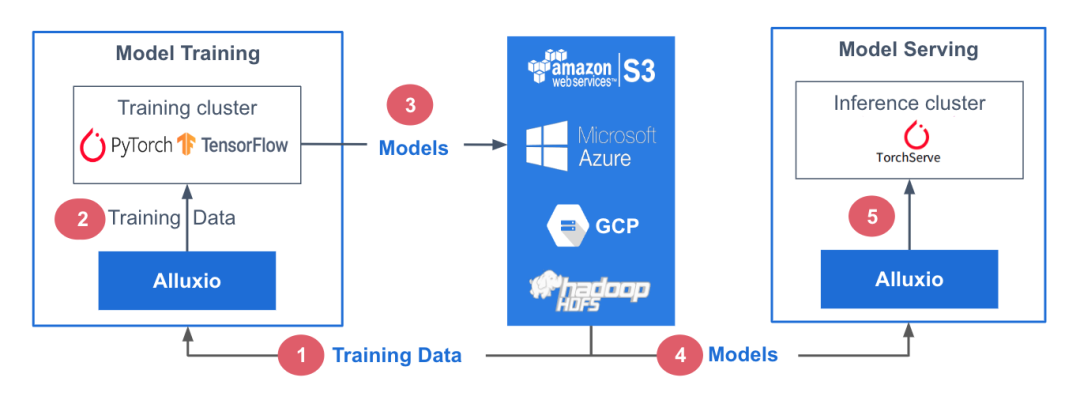
在此参考架构中,训练数据存储在中心化数据存储平台AWS S3中。Alluxio可帮助实现模型训练集群对训练数据的无缝访问。PyTorch、TensorFlow、scikit-learn和XGBoost等ML训练框架都在CPU/GPU/TPU集群上层执行。这些框架利用训练数据生成机器学习模型,模型生成后被存储在中心化模型库中。
在模型服务阶段,使用专用服务/推理集群,并采用TorchServe、TensorFlow Serving、Triton 和 KFServing等框架。这些服务集群利用Alluxio从模型存储库中获取模型。模型加载后,服务集群会处理输入的查询、执行必要的推理作业并返回计算结果。
训练和服务环境都基于Kubernetes,有助于增强基础设施的可扩展性和可重复性。
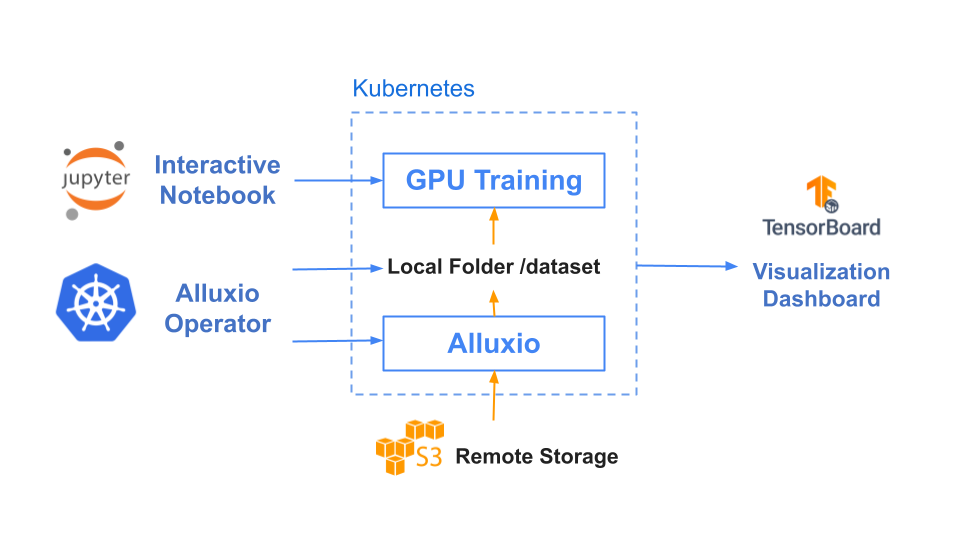
2
基准测试结果
在本基准测试中,我们用计算机视觉领域的典型应用场景之一——图片分类任务作为示例,其中我们以ImageNet的数据集作为训练集,通过ResNet来训练图片分类模型。
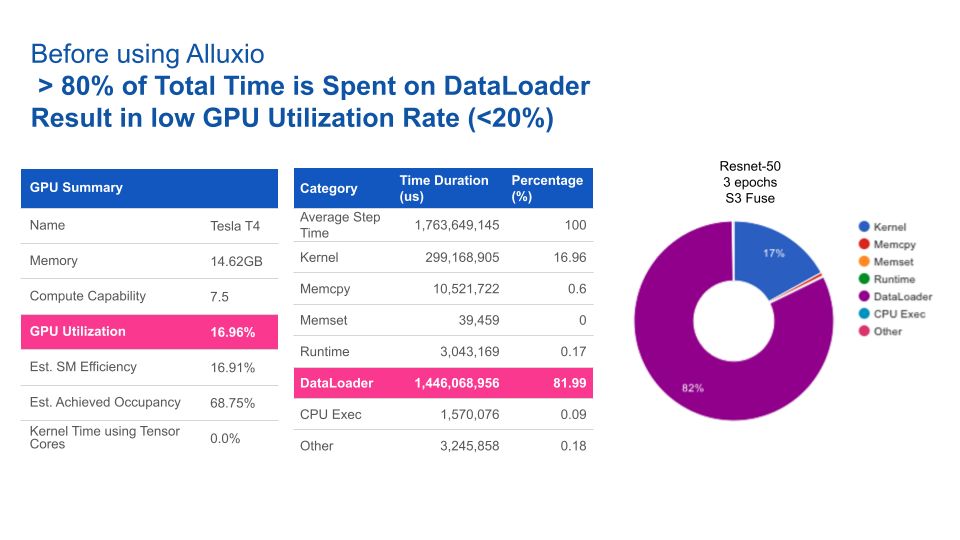
基于Resnet-50上3个epochs性能基准测试的结果,使用Alluxio比使用S3-FUSE的速度快5倍。一般来说,提高数据访问性能可缩短模型训练的总时间。
|
|
Alluxio |
S3 - FUSE |
|
Total training time (3 epochs) |
17 minutes |
85 minutes |
使用Alluxio后,GPU利用率得到大幅提升。Alluxio将数据加载时间由82%缩短至1%,从而将GPU利用率由17%提升至93%。
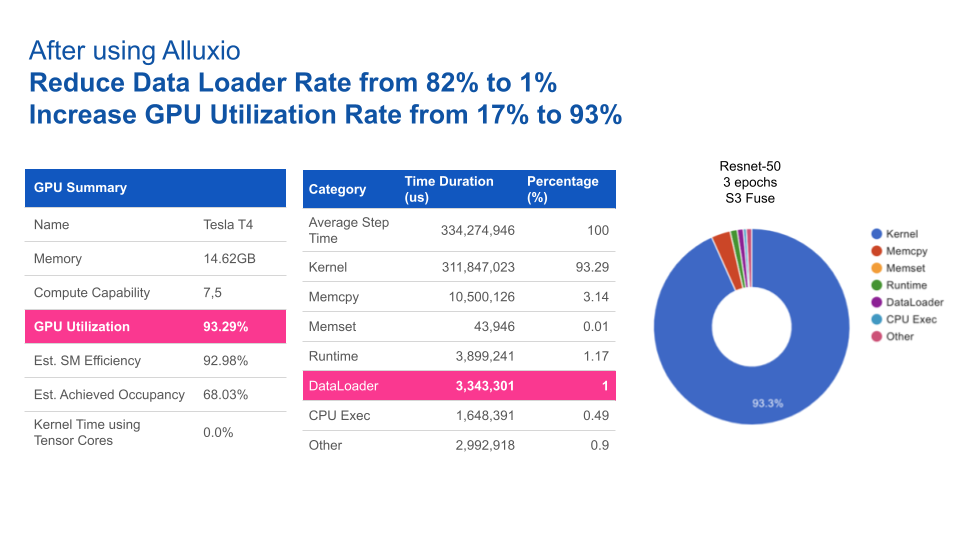
四、结论
随着AI/ML学习架构从早期的预生产架构向着可扩展架构发展,数据访问始终是瓶颈。仅靠添加更快的存储硬件或中心化NAS/NFS无法完全消除性能不达标以及影响系统操作的管理问题。
Alluxio提供了一种专为优化AI/ML任务数据流而设计的软件解决方案。与传统存储方案相比,其优势包括:
1
优化数据加载:Alluxio智能地加速训练任务和模型服务的数据访问,从而将GPU利用率最大化。
2
维护需求低:无需在节点或集群之间手动拷贝数据。Alluxio通过其分布式缓存层处理热文件传输。
3
支持扩展:当数据量大到需要扩展更多节点的情况下,Alluxio也能维持性能稳定。Alluxio通过使用SSD扩展内存,可缓存任何大小的文件,避免拷贝全部文件。
4
更快的切换:Alluxio将底层存储抽象化,使得数据团队能够轻松地在云厂商、本地或多云环境中迁移数据。数据迁移无需替换硬件,也不会导致停机。
部署Alluxio后,企业通过针对数据访问进行优化的数据架构,可以构建出性能卓越、可扩展的数据平台,从而加速模型开发,满足不断增长的数据需求。
✦
【近期热门】
✦

✦
【宝典集市】
✦






本文分享自微信公众号 - Alluxio(Alluxio_China)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。