Einführung : ArcGraph ist eine verteilte Diagrammdatenbank mit cloudnativer Architektur und integrierter Inventarisierung und Analyse. In diesem Artikel wird ausführlich erläutert, wie ArcGraph die Diagrammanalyse bei begrenztem Speicher flexibel bewältigen kann.
01 Einführung
Da die Technologie zur Diagrammanalyse inzwischen weit verbreitet ist, sind akademische Kreise und große Hersteller von Diagrammdatenbanken bestrebt, die Hochleistungsindikatoren der Technologie zur Diagrammanalyse zu verbessern. Bei der Verfolgung des Hochleistungsrechnens wird jedoch häufig die Methode des „Tauschs von Raum gegen Zeit“ angewendet, d. h. durch Erhöhung der Speichernutzung zur Beschleunigung der Berechnungen. Allerdings ist die Grafikberechnung mit externem Speicher zu diesem Zeitpunkt noch nicht ausgereift, und die Grafikanalyse ist immer noch auf die Berechnung mit vollem Speicher angewiesen. Dies führt dazu, dass leistungsstarke Grafikberechnungs-Engines stark auf großen Speicher angewiesen sind, wenn der Speicher nicht ausreicht wird nicht ausgeführt.
Bei vielen Kundenfällen in der Vergangenheit haben wir festgestellt, dass die Hardwareressourcen, die Kunden in die Diagrammanalyse investieren, normalerweise festgelegt und begrenzt sind und dass die Ressourcen der Testumgebung begrenzter sind als die der Produktionsumgebung. Die Aktualitätsanforderungen der Kunden für die Diagrammanalyse liegen normalerweise bei T+1, was eine typische Offline-Analyseanforderung darstellt. Daher erwarten Kunden, dass die Graph-Computing-Engine den Bedarf an Ressourcen wie CPU und Speicher reduziert, anstatt eine hohe Algorithmusleistung anzustreben, solange sie T+1 erfüllt. Dies stellt für die meisten Graph-Computing-Engines eine große Herausforderung dar. CPU-Anforderungen sind relativ einfach zu kontrollieren, während es schwierig ist, die Speicheranforderungen innerhalb eines kurzen Entwicklungszyklus signifikant zu optimieren.
ArcGraph steht ebenfalls vor den oben genannten Herausforderungen, aber durch kontinuierliche Zusammenfassung und Verfeinerung der Kundenlieferpraktiken verfügt unsere Graph-Computing-Engine über die Flexibilität, die Verarbeitung zeitlich und räumlich auszubalancieren. Derzeit ist die integrierte Graph-Computing-Engine von ArcGraph branchenweit führend in Bezug auf Leistungsindikatoren für die Graphanalyse und wird weiterhin optimiert und verbessert. Als nächstes erklären wir, wie ArcGraph geschickt Zeit gegen Platz eintauscht, um die Diagrammanalyse bei begrenztem Speicher aus mehreren Perspektiven zu bewältigen, einschließlich der zugrunde liegenden Datenstruktur der Engine und dem Aufruf von Algorithmen der oberen Ebene.
02 Auswahl des Punkt-ID-Typs
Die ArcGraph-Grafikberechnungs-Engine unterstützt drei Punkt-ID-Typen: string, int64 und int32. Die Unterstützung des String-Punkttyps kann die Kompatibilität mit Quelldaten verbessern, führt jedoch im Vergleich zu int64 zu einer höheren Speichernutzung, da eine Zuordnungstabelle für die Punkt-ID von String zu int64 im Speicher verwaltet werden muss. Wenn der angegebene Punkttyp int64 ist, generiert ArcGraph eine int64-Zuordnungstabelle aus der Zeichenfolgentyp-Punkt-ID in den Quelldaten und legt sie im externen Speicher ab. Nur die zugeordneten Punktkantendaten vom Typ int64 werden im Speicher beibehalten. Nach Abschluss der Berechnung wird die Zuordnungstabelle in den Speicher eingelesen und die String-ID wiederhergestellt. Daher erhöht die Verwendung der Punkt-ID vom Typ int64 den zusätzlichen Zeitaufwand für den Austausch der Zuordnungstabelle zwischen externem Speicher und Speicher, verringert jedoch auch die Gesamtspeichernutzung erheblich. Die eingesparte Speichergröße hängt von der Länge und dem Punkt des Originals ab ID. Datenvolumen.
Darüber hinaus unterstützt die ArcGraph-Grafikberechnungs-Engine auch int32. In Szenarien, in denen die Gesamtzahl der Quelldatenpunkte weniger als 40 Millionen beträgt, kann die Speichernutzung im Vergleich zu int64 weiter um etwa 30 % reduziert werden.
Das Folgende ist ein Beispiel für die Angabe des Diagrammladepunkt-ID-Typs in der ArcGraph-API für den Ausführungsdiagrammalgorithmus:
curl -X 'POST' 'http://myhost:18000/graph-computing?reload=true&use_cache=true' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"algorithmName": "pagerank",
"graphName": "twitter2010",
"taskId": "pagerank",
"oid_type": "int64",
"subGraph": {
"edgeTypes": [
{
"edgeTypeName": "knows",
"props": [],
"vertexPairs": [
{
"fromName": "person",
"toName": "person"
}
]
}
],
"vertexTypes": [
{
"vertexTypeName": "person",
"props": []
}
]
},
"algorithmParams": {
}
}'
03 Aktivieren Sie die Varint-Kodierung
Die Varint-Kodierung wird zum Komprimieren und Kodieren von Ganzzahlen verwendet und ist eine Kodierungsmethode mit variabler Länge. Am Beispiel von int32 sind 4 Bytes erforderlich, um einen Wert normal zu speichern. Bei der herkömmlichen Varint-Codierung werden die letzten 7 Bits jedes Bytes zur Darstellung von Daten verwendet, und das höchste Bit ist das Flag-Bit.


- Wenn das höchste Bit 0 ist, bedeutet dies, dass die letzten 7 Bits des aktuellen Bytes alle Daten sind und die nachfolgenden Bytes nichts mit den Daten zu tun haben. Beispielsweise erfordert die Ganzzahl 1 in der obigen Abbildung nur ein Byte zur Darstellung von: 00000001, und die nachfolgenden Bytes gehören nicht zu den Daten der Ganzzahl 1.
- Wenn das höchste Bit 1 ist, bedeutet dies, dass nachfolgende Bytes immer noch Teil der Daten sind. Für die Ganzzahl 511 im Bild oben sind beispielsweise 2 Bytes erforderlich, um Folgendes darzustellen: 11111111 00000011, und die nachfolgenden Bytes sind die Daten von 131071.
Mit dieser Idee können 32-Bit-Ganzzahlen durch 1–5 Bytes dargestellt werden. Dementsprechend kann eine 64-Bit-Ganzzahl durch 1–10 Bytes dargestellt werden. In tatsächlichen Nutzungsszenarien ist die Nutzungsrate kleiner Zahlen viel höher als die großer Zahlen, insbesondere bei 64-Bit-Ganzzahlen. Daher kann die Varint-Kodierung in der Regel erhebliche Komprimierungseffekte erzielen. Es gibt viele Varianten der Varint-Codierung und es gibt viele Open-Source-Implementierungen.
Die ArcGraph-Grafikberechnungs-Engine unterstützt die Verwendung der Varint-Codierung zur Komprimierung der In-Memory-Edge-Datenspeicherung (hauptsächlich CSR/CSC). Wenn die Varint-Kodierung aktiviert ist, kann der von Kantendaten belegte Speicher erheblich reduziert werden, bei tatsächlichen Messungen bis zu etwa 50 %. Gleichzeitig beträgt der Leistungsverlust durch Kodierung und Dekodierung bis zu etwa 20 %. Daher müssen Sie vor dem Einschalten die Nutzungsszenarien und Kundenanforderungen genau verstehen, um sicherzustellen, dass der durch das Speichern von Speicher verursachte Leistungsverlust in einem akzeptablen Bereich liegt.
Im Folgenden finden Sie ein Varint-Codierungsbeispiel zum Aktivieren der Diagrammberechnung in der Diagrammlade-API von ArcGraph:
curl -X 'POST' 'http://localhost:18000/graph-computing/datasets/twitter2010/load' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"oid_type": "int64",
"delimeter": ",",
"with_header": "true",
"compact_edge": "true"
}'
04 Schalten Sie Perfect HashMap ein
Der Unterschied zwischen Perfect HashMap und anderen HashMap besteht darin, dass es die Perfect Hash Function (PHF) verwendet. Funktion H ordnet N Schlüsselwerte M Ganzzahlen zu, wobei M>=N ist und H(key1)≠H(key2)∀key1, key2 erfüllt, dann ist die Funktion eine perfekte Hash-Funktion. Wenn M=N, dann ist H die Minimal Perfect Hash Function (kurz MPHF). Zu diesem Zeitpunkt werden N Schlüsselwerte N aufeinanderfolgenden Ganzzahlen zugeordnet.
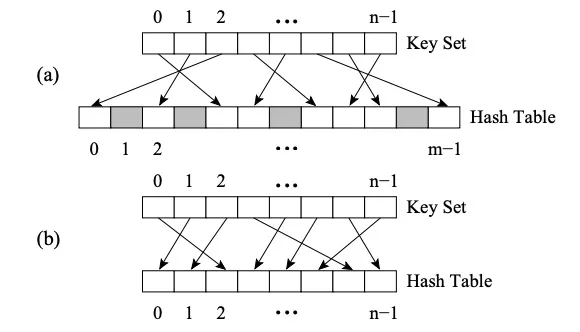 Bild (a) ist PHF, Bild (b) ist MPHF
Bild (a) ist PHF, Bild (b) ist MPHF
Das Bild oben zeigt die FKS-Strategie des zweistufigen Hashings. Zuerst werden die Daten über den Hash der ersten Ebene in den T-Raum abgebildet, und dann werden die widersprüchlichen Daten zufällig ausgewählt und mithilfe einer neuen Hash-Funktion dem S-Raum zugeordnet, und die Größe m des S-Raums ist das Quadrat des Konflikts Daten (zum Beispiel gibt es drei in T2. Wenn Zahlen in Konflikt stehen, werden sie dem S2-Raum zugeordnet, in dem m 9 ist. Zu diesem Zeitpunkt ist es einfach, eine Hash-Funktion zu finden, die Kollisionen vermeidet). Eine geeignete Auswahl der Hash-Funktion reduziert Kollisionen beim einstufigen Hashing, sodass der erwartete Speicherplatz O(n) sein kann.
Die ArcGraph-Grafikberechnungs-Engine verwaltet eine Zuordnung von der ursprünglichen Punkt-ID zur internen Punkt-ID im Speicher. Der interne Punkt ist ein kontinuierlicher langer Ganzzahltyp, der für die Datenkomprimierung und Vektorisierungsoptimierung geeignet ist. Die Zuordnung ist im Wesentlichen eine Hashmap, ArcGraph bietet jedoch zwei Methoden in Bezug auf die zugrunde liegende Implementierung:
- Flat HashMap – Der Vorteil besteht darin, dass die Konstruktionsgeschwindigkeit hoch ist, der Nachteil besteht jedoch darin, dass normalerweise mehr Speicherplatz erforderlich ist, um häufige Hash-Kollisionen zu reduzieren.
- Perfekte HashMap – Der Vorteil besteht darin, dass im schlimmsten Fall weniger Speicher verwendet werden kann, um eine Abfrage mit O(1)-Effizienz sicherzustellen. Der Nachteil besteht jedoch darin, dass alle Schlüssel im Voraus bekannt sein müssen und die Erstellungszeit lang ist.
Daher kann durch die Aktivierung von Perfect HashMap auch der Zweck des Austauschs von Zeit gegen Raum erreicht werden. Dem Test zufolge beträgt die Speichernutzung von Perfect HashMap für den Zuordnungssatz vom ursprünglichen Punkt zur internen Punkt-ID normalerweise nur etwa 1/5 der von Flat HashMap, die Erstellungszeit beträgt jedoch dementsprechend das 2-3-fache.
Das Folgende ist ein Perfect HashMap-Beispiel, das die Diagrammberechnung in der Diagrammlade-API von ArcGraph ermöglicht:
curl -X 'POST' 'http://localhost:18000/graph-computing/datasets/twitter2010/load' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"oid_type": "int64",
"delimeter": ",",
"with_header": "true",
"compact_edge": "true",
"use_perfect_hash": "true"
}'
05 Implementierung des Optimierungsalgorithmus und Ergebnisverarbeitung
Die Speichernutzung auf der Ebene der Algorithmusimplementierung hängt von der spezifischen Logik des Algorithmus ab. Wir haben die folgenden Punkte aus der Praxis zusammengefasst, die den Zweck des Austauschs von Zeit gegen Raum erreichen können:
Reduzieren Sie Multithreading und die Verwendung von ThreadLocal-Objekten im Algorithmus entsprechend. Algorithmen beinhalten häufig die Speicherung temporärer Point-Edge-Sammlungen. Wenn diese Speicherungen in Multithread-Logik auftreten, erhöht sich der Gesamtspeicher mit zunehmender Anzahl von Threads. Eine entsprechende Reduzierung der Anzahl gleichzeitiger Threads oder eine Reduzierung der Verwendung großer ThreadLocal-Objekte trägt zur Speicherreduzierung bei. Erhöhen Sie den Datenaustausch zwischen internem und externem Speicher entsprechend. Gemäß der spezifischen Logik des Algorithmus werden vorübergehend nicht verwendete große Objekte in den externen Speicher serialisiert. Wenn das Objekt verwendet wird, wird es in einem Streaming-Verfahren in den Speicher eingelesen, um zu vermeiden, dass mehrere große Objekte gleichzeitig viel Speicher belegen Zeit.
Das Folgende ist ein Beispiel für die Implementierung eines Algorithmus, das die beiden oben genannten Punkte verkörpert:
void IncEval(const fragment_t& frag, context_t& ctx,
message_manager_t& messages) {
...
...
if (ctx.stage == "Compute_Path"){
auto vertex_group = divide_vertex_by_type(frag);
//此处采用单线程for循环而非多线程并行处理,意在防止多个path_vector同时占内存导致OOM。
for(int i=0; i < vertex_group.size(); i++){
//此处path_vector是每个group中任意两点间的全路径,可理解为一个超大对象
auto path_vector = compute_all_paths(vertex_group[i]);
//拿到该对象后不会在当前stage使用,所以先序列化到外存中。
serialize_path_vector(path_vector, SERIALIZE_FOLDER);
}
...
...
}
...
...
if (ctx.stage == "Result_Collection"){
//在当前stage中,将之前stage生成的多个序列化文件合并为一个文件,并把文件路径返回。
auto result_file_path = merge_path_files(SERIALIZE_FOLDER);
ctx.set_result(result_file_path);
...
...
}
...
...
}
Nach Abschluss der Berechnung werden die Ergebnisse in den externen Speicher geschrieben und der entsprechende Speicher der Grafikberechnungs-Engine freigegeben. In einigen Szenarien wird das Ergebnisverarbeitungsprogramm auf dem Graph-Computing-Cluster-Server ausgeführt, um die Graph-Computing-Ergebnisse zu lesen und sie weiter zu verarbeiten. Wenn der Speicher der Grafikberechnungs-Engine die Berechnungsergebnisse nicht freigegeben hat, befinden sich im schlimmsten Fall zwei Kopien der Ergebnisdaten im aktuellen Serverspeicher. In Szenarien mit großen Datenmengen belegt eine Kopie der Ergebnisdaten sehr viel Speicher. Daher muss in einem solchen Szenario Priorität darauf gelegt werden, die Berechnungsergebnisse in den externen Speicher zu schreiben und den Speicher der Graph-Computing-Engine rechtzeitig freizugeben.
Gleichzeitig wird das ArcGraph-Team weiterhin die „Notwendigkeit und Notwendigkeit“ von hoher Leistung und geringem Ressourcenverbrauch in Frage stellen und mit akademischen und industriellen Partnern zusammenarbeiten, um den graphtragenden Speicher und die Recheneffizienz weiter zu verbessern, um weitere technologische Durchbrüche zu erzielen.
Google: Der Übergang zu Rust hat die Schwachstellen von Android erheblich reduziert. Huawei kündigt an, dass Open UBMC, der alte klassische Musikplayer Winamp, am 2024.2.3 veröffentlicht wird es ist ein Markenzeichen von Oracle geworden? Open Source Daily |. Wie chinesische KI-Unternehmen das US-Chip-Verbot umgehen; Wer kann den Durst der KI-Entwickler stillen? Das Startup-Unternehmen „Zhihuijun“ veröffentlichte Open-Source-AimRT, ein Laufzeit-Entwicklungsframework für den modernen Robotikbereich, Tcl/Tk 9.0, veröffentlichte das multimodale KI-Modell Meta und Llama 3.2