Segmented Log
Divide large files into multiple smaller files that are easier to handle.
Problem background
A single log file may grow to a large size and be read when the program starts, thus becoming a performance bottleneck. Old logs need to be cleaned up regularly, but cleaning up a large file is very laborious.
solution
Divide a single log into multiple, and when the log reaches a certain size, it will switch to a new file to continue writing.
//写入日志
public Long writeEntry(WALEntry entry) {
//判断是否需要另起新文件
maybeRoll();
//写入文件
return openSegment.writeEntry(entry);
}
private void maybeRoll() {
//如果当前文件大小超过最大日志文件大小
if (openSegment.
size() >= config.getMaxLogSize()) {
//强制刷盘
openSegment.flush();
//存入保存好的排序好的老日志文件列表
sortedSavedSegments.add(openSegment);
//获取文件最后一个日志id
long lastId = openSegment.getLastLogEntryId();
//根据日志id,另起一个新文件,打开
openSegment = WALSegment.open(lastId, config.getWalDir());
}
}If the log is segmented, then a mechanism for quickly locating a file with a log location (or log sequence number) is needed. It can be achieved in two ways:
- The name of each log split file contains a specific beginning and log position offset (or log sequence number)
- Each log sequence number contains the file name and transaction offset.
//创建文件名称
public static String createFileName(Long startIndex) {
//特定日志前缀_起始位置_日志后缀
return logPrefix + "_" + startIndex + "_" + logSuffix;
}
//从文件名称中提取日志偏移量
public static Long getBaseOffsetFromFileName(String fileName) {
String[] nameAndSuffix = fileName.split(logSuffix);
String[] prefixAndOffset = nameAndSuffix[0].split("_");
if (prefixAndOffset[0].equals(logPrefix))
return Long.parseLong(prefixAndOffset[1]);
return -1l;
}After the file name contains this information, the read operation is divided into two steps:
- Given an offset (or transaction id), get the file where the log is larger than this offset
- Read all logs larger than this offset from the file
//给定偏移量,读取所有日志
public List<WALEntry> readFrom(Long startIndex) {
List<WALSegment> segments = getAllSegmentsContainingLogGreaterThan(startIndex);
return readWalEntriesFrom(startIndex, segments);
}
//给定偏移量,获取所有包含大于这个偏移量的日志文件
private List<WALSegment> getAllSegmentsContainingLogGreaterThan(Long startIndex) {
List<WALSegment> segments = new ArrayList<>();
//Start from the last segment to the first segment with starting offset less than startIndex
//This will get all the segments which have log entries more than the startIndex
for (int i = sortedSavedSegments.size() - 1; i >= 0; i--) {
WALSegment walSegment = sortedSavedSegments.get(i);
segments.add(walSegment);
if (walSegment.getBaseOffset() <= startIndex) {
break; // break for the first segment with baseoffset less than startIndex
}
}
if (openSegment.getBaseOffset() <= startIndex) {
segments.add(openSegment);
}
return segments;
}For example
Basically all mainstream MQ storage, such as RocketMQ, Kafka and Pulsar's underlying storage BookKeeper, all use segmented logs.
RocketMQ: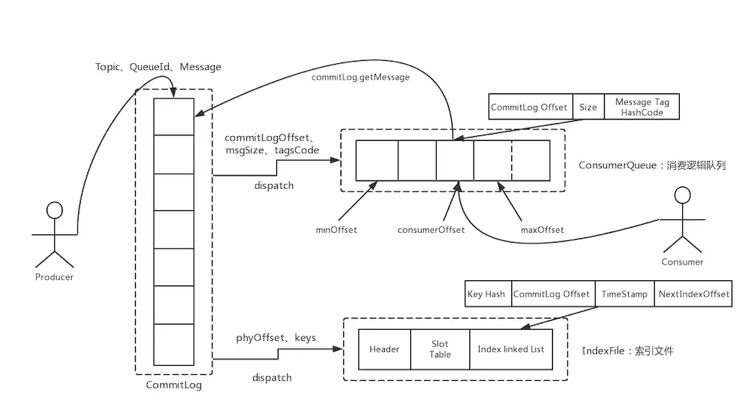
Kafka:
Pulsar storage implements BookKeeper: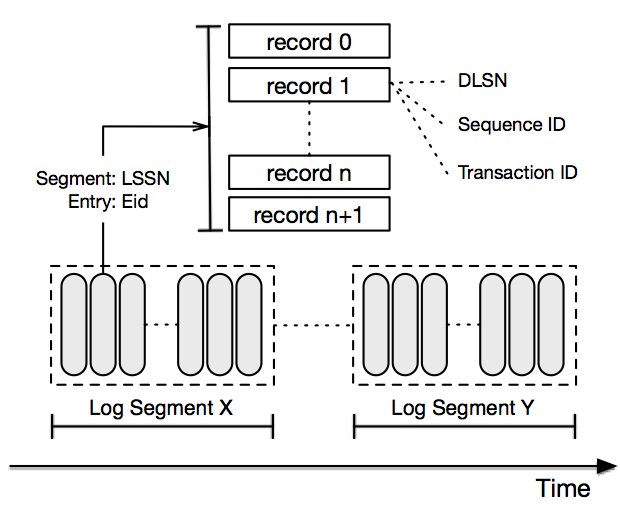
In addition, storage based on the consistency protocol Paxos or Raft generally uses segmented logs, such as Zookeeper and TiDB.
One swipe every day, you can easily upgrade your skills and get various offers:
